인덱스
인덱스는 데이터를 좀 더 빨리 찾을 수 있도록 도와주는 도구이다.
찾아보기가 있는 책은 찾아보기에 주요 용어가 가나다순, 알파벳순으로 정렬되어 있고 용어 옆에 쪽수가 적혀 있어 해당 페이지를 펼치면 원하는 내용을 바로 찾을 수 있다. MySQL의 인덱스는 바로 이와 같은 찾아보기와 상당히 비슷한 개념이다.
인덱스의 문제점
책이 거의 모든 페이지에 나오는 단어를 찾아보기에 모두 표시하면 찾아보기의 분량이 엄청나게 많아져서 본문보다 두꺼워지는 것처럼 필요 없는 인덱스를 만들면 데이터베이스가 차지하는 공간만 늘어나고, 인덱스를 이용하여 데이터를 찾는 것이 전체 테이블을 찾아 보는 것보다 훨씬 느려진다.
인덱스의 장단점
장점
- 검색 속도가 매우 빨리진다. (항상 그런 것은 X)
- 그 결과 해당 쿼리의 부하가 줄어즐어 결국 시스템 전체의 성능이 향상된다.
장점
- 인덱스를 저장할 공긴이 필요하다. (대략 데이터베이스 크기의 10% 정도 추가 공간이 필요)
- 처음 인덱스를 생성하는 데 많은 시간이 소요된다.
- 데이터의 변경(삽입, 수정, 삭제) 작업이 자주 일어날 경우 오히려 성능이 나빠질 수 있다.
인덱스의 종류
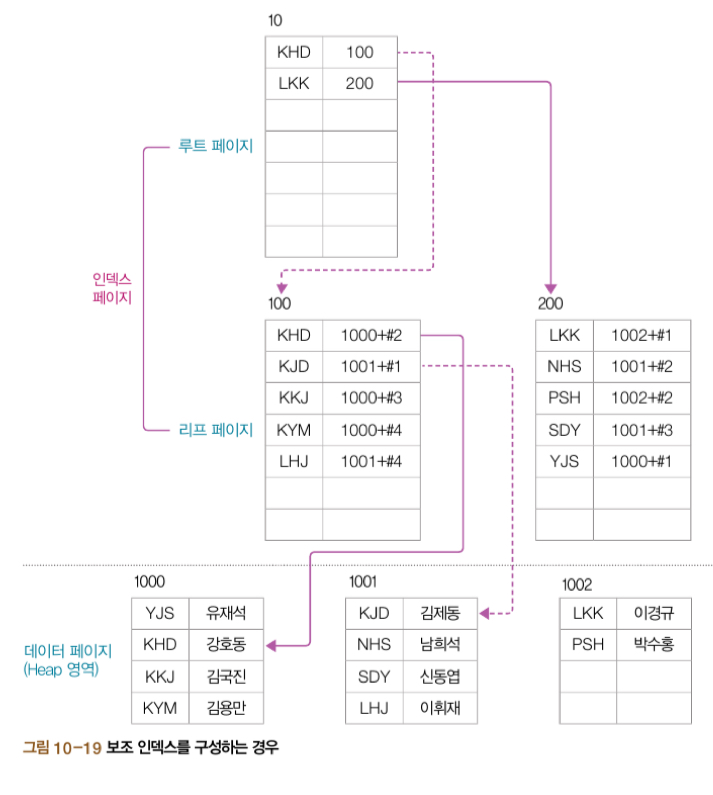
MySQL에서 사용하는 인덱스에는 클러스터형 인덱스(clustered index)와 보조 인덱스(secondary index)가 있다.
클러스터형 인덱스
- 영어 사전처럼 책의 내용 자체가 순서대로 정렬되어 있어 인덱스가 책의 내용과 같다.
- 테이블당 하나만 생성할 수 있다.
- 행 데이터를 인덱스로 지정한 열에 맞춰서 자동으로 정렬한다.
- 기본키를 설정하면 자동으로 해당 열(아이디)에 클러스터형 인덱스가 생성된다.
보조형 인덱스
- 찾아보기에서 먼저 단어를 찾은 후 그 옆에 표시된 페이지로 이동하여 원하는 내용을 찾는 것과 같은 개념
- 테이블당 여러 개를 생성할 수 있다.
제약 조건으로 자동 생성되는 인덱스
- PRIMARY KEY로 지정한 열에 클러스터형 인덱스가 생성
- UNIQUE 또는 UNIQUE NULL로 지정한 열에 보조 인덱스가 생성
- PRIMARY KEY와 UNIQUE NOT NULL이 같이 있으면 PRIMARY KEY로 지정한 열에 우선 클러스터형 인덱스가 생성 (동치 <=>) PRIMARY KEY가 존재하지 않으면 UNIQUE NOT NULL 열로 클러스터형 인덱스 생성
- PRIMARY KEY로 지정한 열을 기준으로 데이터가 오름차순 정렬
(참고)
SHOW INDEX FROM 테이블명을 통해 테이블 생성 시 제약 조건으로 자동 새성된 인덱스를 확인할 수 있다.SELECT * FROM 테이블명수행 시 PK로 인해 생성된 클러스터형 인덱스를 통해 자동 정렬된 결과가 나온다.
B-Tree
자료 구조에 나오는, 범용적으로 사용되는 데이터 구조로 균형이 잡힌 트리이다.
트리 구조에서 데이터가 존재하는 공간을 노드라고 한다.
- 루트 노드: 가장 상위에 있는 노드, 모든 출발은 루트 노드에서 시작
- 리프 노드: 가장 밑단에 있는 노드
- 중간 수준 노드: 루트 노드와 리프 노드의 중간에 끼인 노드
MySQL에서는 노드를 페이지라고 한다. 페이지에는 최소한의 저장 단위로 크기가 16KB이며, 아무리 작은 데이터를 저장하더라도 1개의 페이지(16KB)를 사용한다.
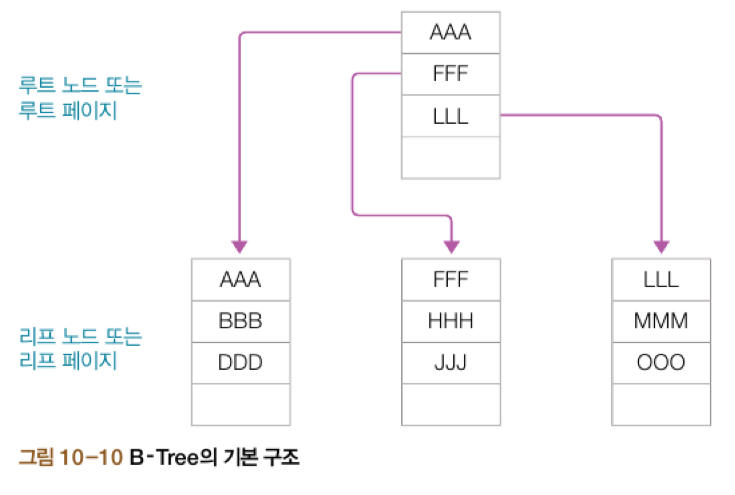
B-Tree의 특성
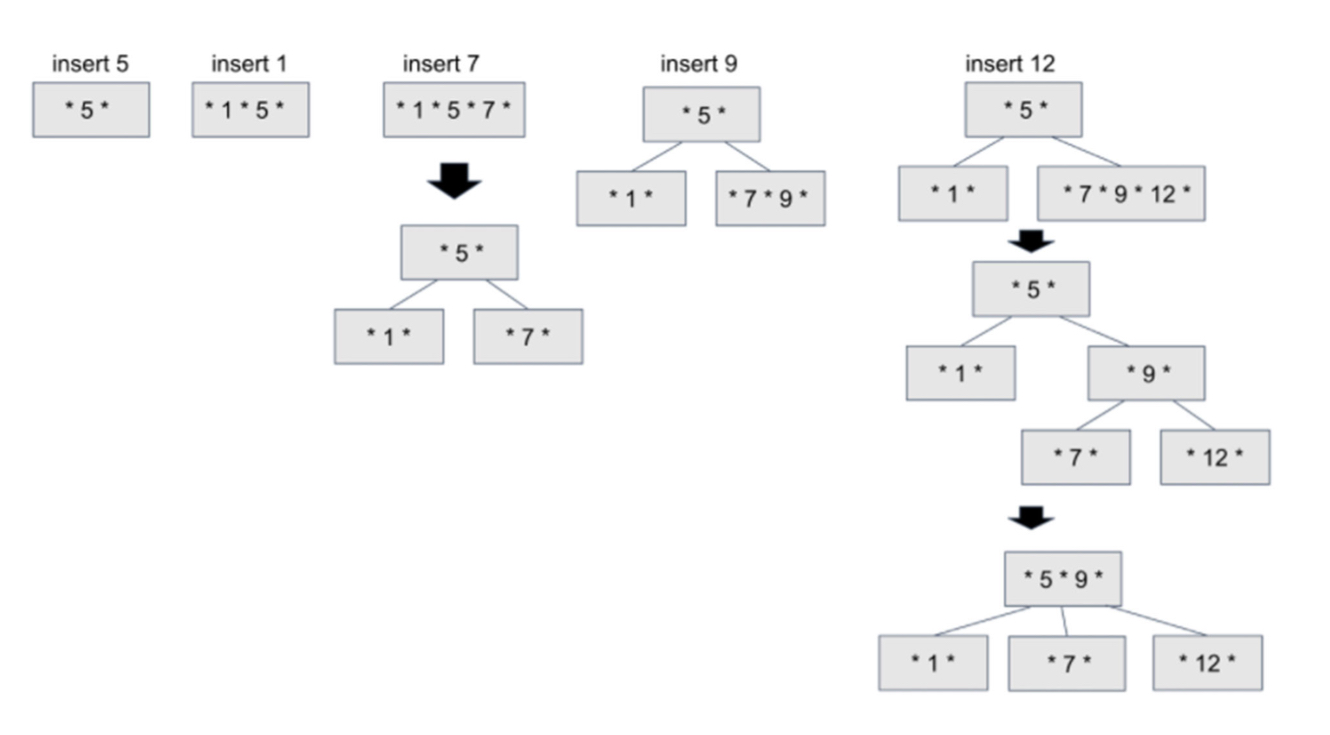
- 자식 노드의 개수가 2개 이상이며, 노드 내의 데이터가 1개 이상이다.
- 노드의 데이터 수가 n개라면 n+1개의 자식 노드를 가리키는 포인터로 구성된다.
- 노드의 자식노드의 데이터들은 노드 데이터를 기준으로 데이터보다 작은 값은 왼쪽 서브 트리에, 큰값들은 오른쪽 서브 트리에 이루어져야 한다.
- 루트 노드를 제외한 모든 노드는 적어도 M/2개의 데이터를 가지고 있어야 한다.
B-Tree의 데이터 삽입
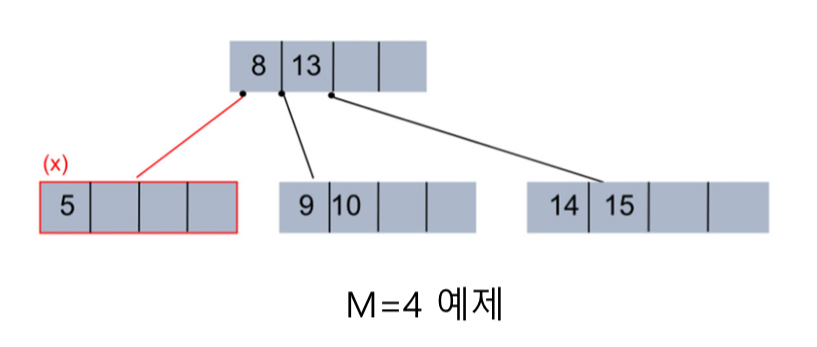
[예제]
- MMM이라는 데이터를 검색하는 경우
ㅤ
MMM은 LLL 다음에 나오므로 AAA, FFF, LLL이라는 데이터를 읽은 후 세 번째 리프 페이지로 이동하고 리프 페이지에서 LLL, MMM이라는 데이터를 읽어 찾을 수 있다. 총 5건 데이터를 검색하고 2개의 페이지를 읽어 원하는 결과를 얻을 수 있다.
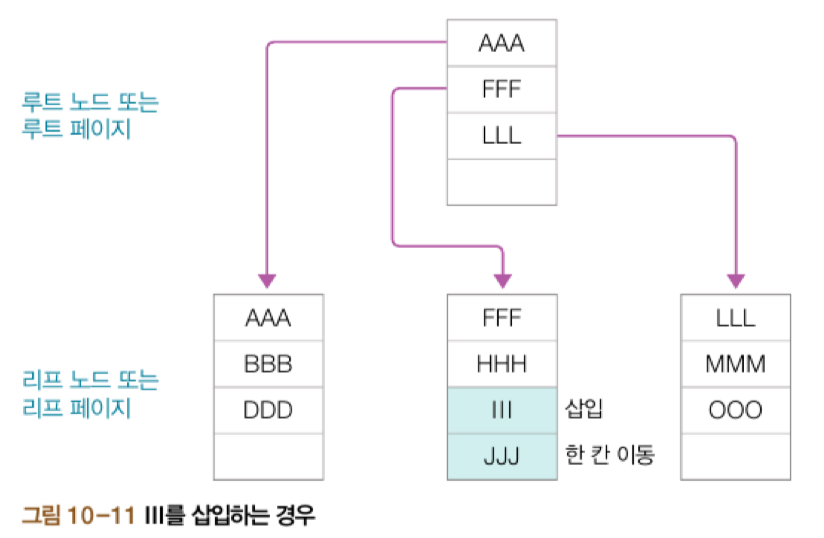
ㅤ - III라는 새로운 데이터를 삽입하는 경우
ㅤ
B-Tree의 특성에 따라 정렬 순서에 맞추어 JJJ를 한 칸 뒤로 이동하고 그 앞에 III를 삽입했다.
ㅤ - GGG라는 새로운 데이터 삽입
ㅤ
한 페이지당 최대 데이터 개수 M이 넘어가므로 새 페이지 확부 후 데이터 분할(페이지 분할)해주었다. (데이터 분할 시 모든 노드는 적어도 M/2개의 데이터를 가져야 한다.) 새 페이지를 루트 노드에 등록해주고 위치에 맞게 새 데이터를 삽입했다.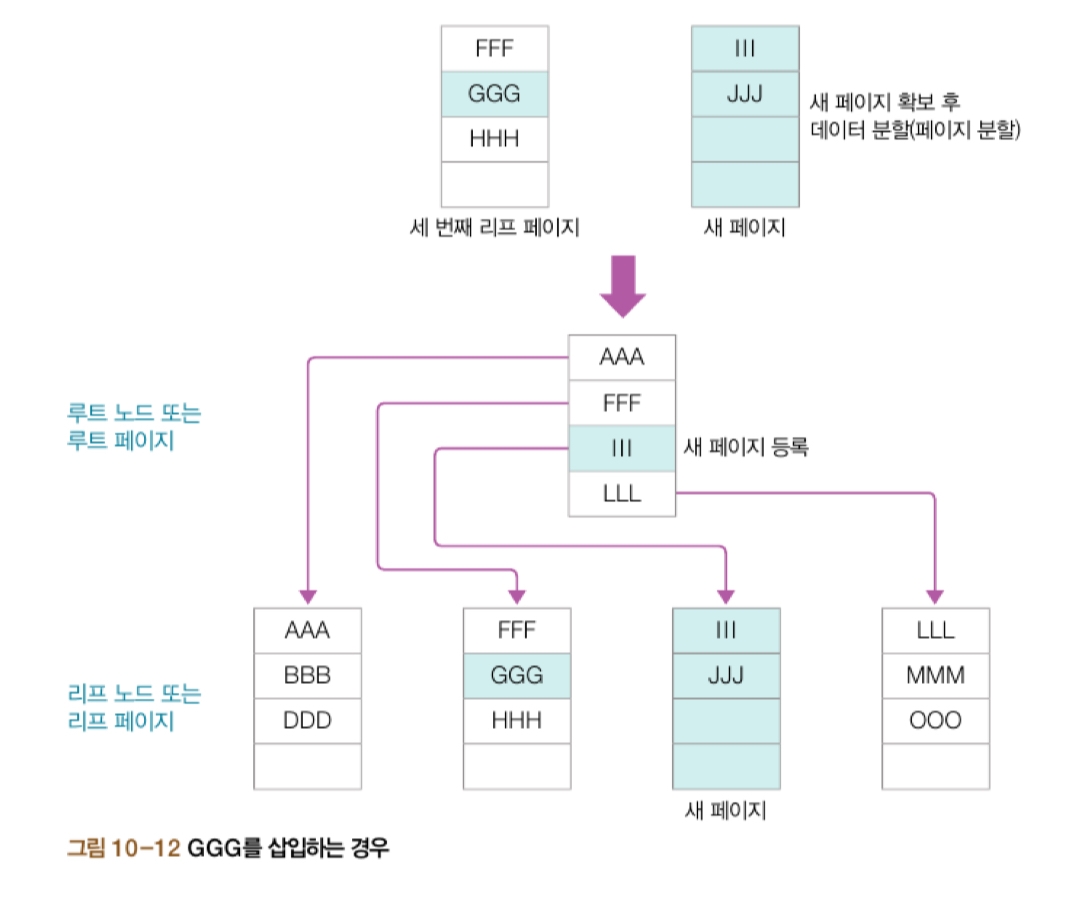 ㅤ
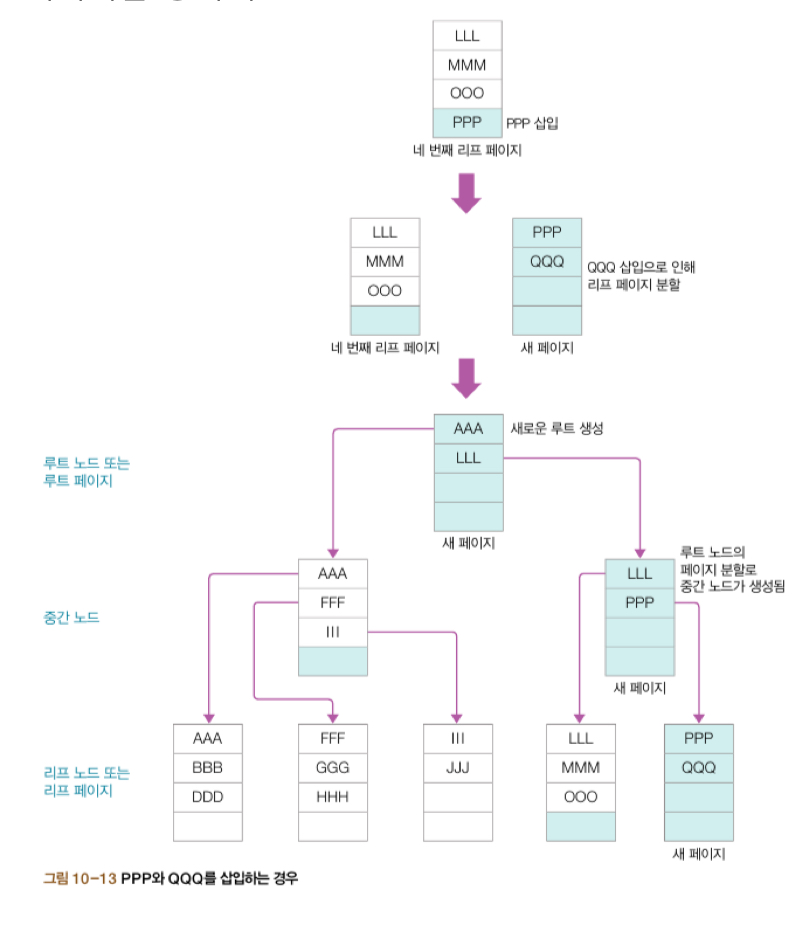
ㅤ - PPP와 QQQ라는 데이터 동시 삽입
ㅤ
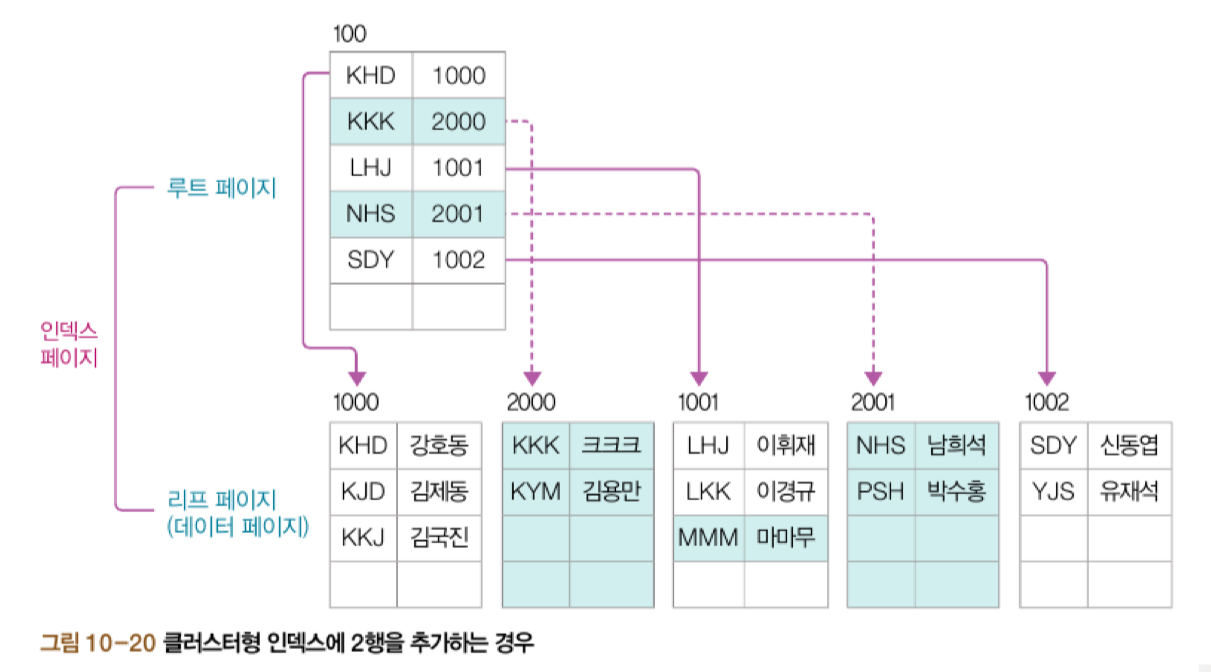
클러스터형 인덱스 vs 보조 인덱스
구조
클러스터형 인덱스
다음 쿼리문을 사용해 인덱스 없이 테이블을 생성하고 데이터를 조회하면 정렬되지 않은 것을 확인할 수 있다.
CREATE DATABASE IF NOT EXISTS testDB;
USE testDB;
DROP TABLE IF EXISTS clusterTBL;
CREATE TABLE clusterTBL (
userID CHAR(8),
userName VARCHAR(10)
);
INSERT INTO clusterTBL (userID, userName) VALUES
('YJS', '유재석'),
('KHD', '강호동'),
('KKJ', '김국진'),
('KYM', '김용만'),
('KJD', '김제동'),
('NHS', '남희석'),
('SDY', '신동엽'),
('LHJ', '이휘재'),
('LKK', '이경규'),
('PSH', '박수홍');
SELECT * FROM clusterTBL;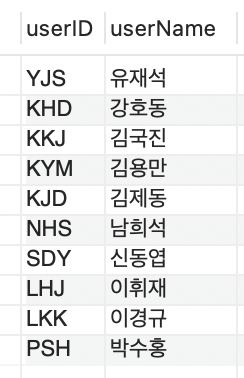
userID에 클러스터형 인덱스를 구성하고 다시 데이터를 다음과 같다.
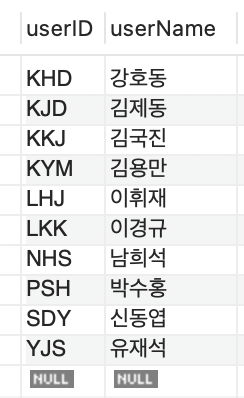
이는 다음과 같이 클러스터형 인덱스가 내부 구조를 가지기 때문이다.
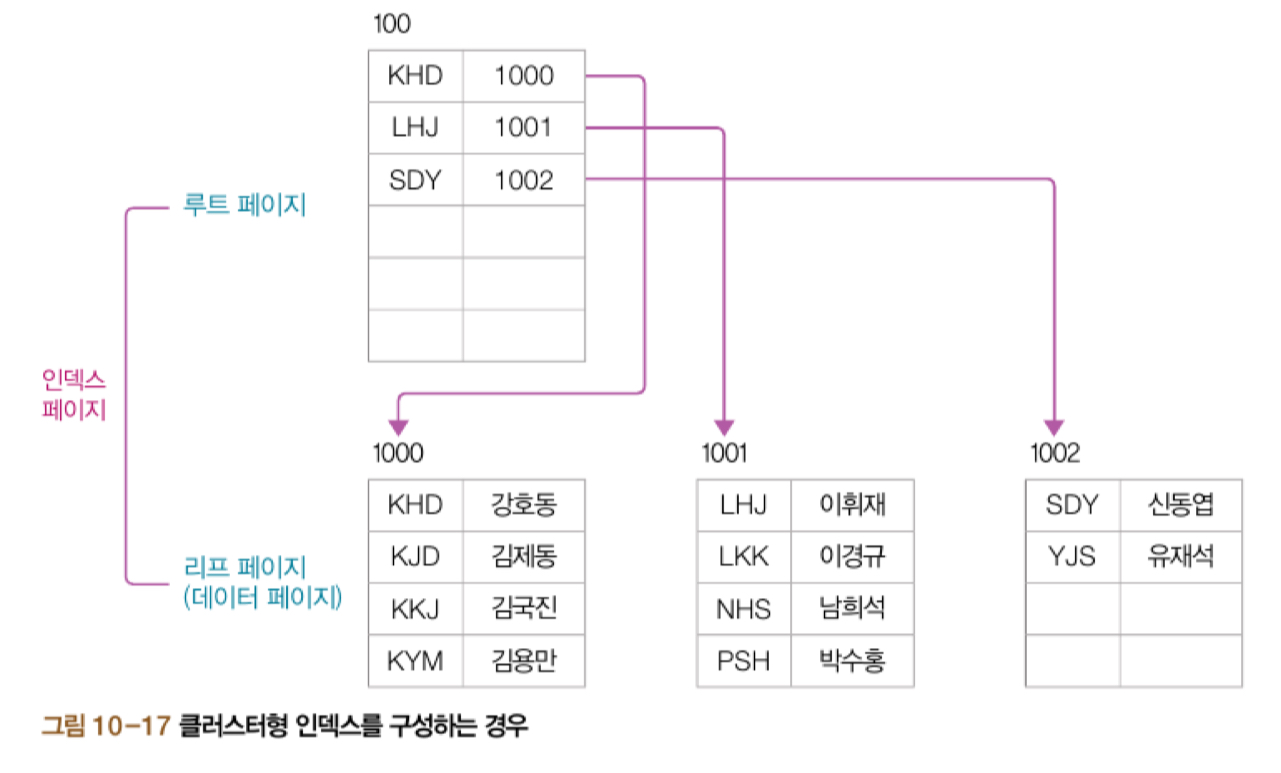
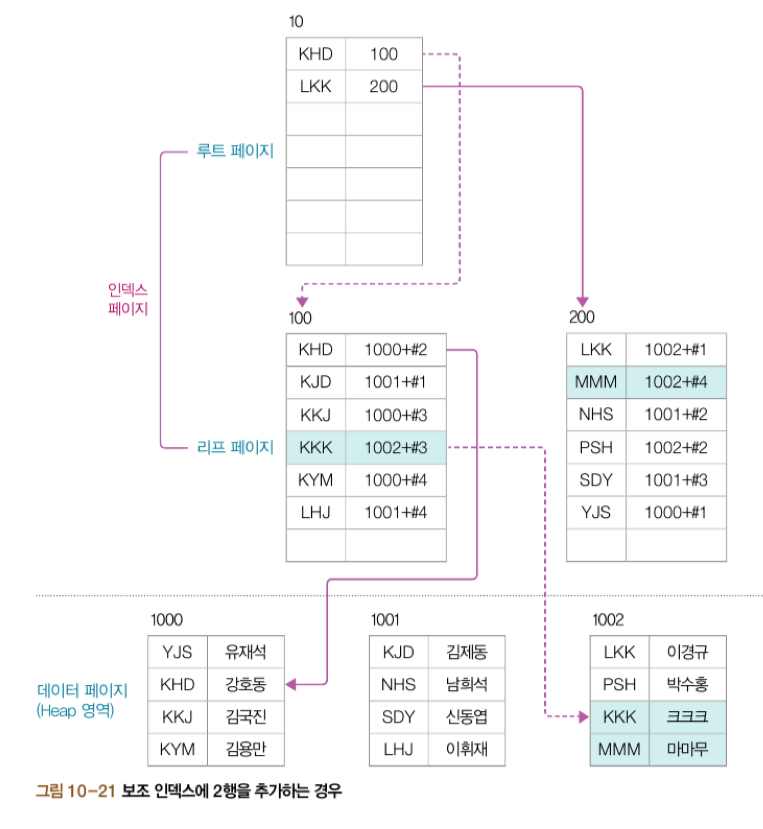
보조 인덱스
userID 열에 UNIQE 제약 조건을 설정하여 보조 인덱스를 만들고 데이터를 확인하면 다음과 같다.
CREATE DATABASE IF NOT EXISTS testDB;
USE testDB;
DROP TABLE IF EXISTS secondaryTBL;
CREATE TABLE secondaryTBL (
userID CHAR(8),
userName VARCHAR(10)
);
INSERT INTO secondaryTBL (userID, userName) VALUES
('YJS', '유재석'),
('KHD', '강호동'),
('KKJ', '김국진'),
('KYM', '김용만'),
('KJD', '김제동'),
('NHS', '남희석'),
('SDY', '신동엽'),
('LHJ', '이휘재'),
('LKK', '이경규'),
('PSH', '박수홍');
ALTER TABLE secondaryTBL ADD CONSTRAINT UK_secondary_TBL_userID UNIQUE (userID);
SELECT * FROM secondaryTBL;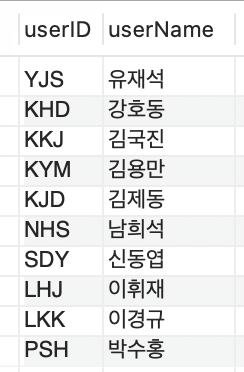
보조 인덱스는 다음과 같이 내부적으로 저장된다.
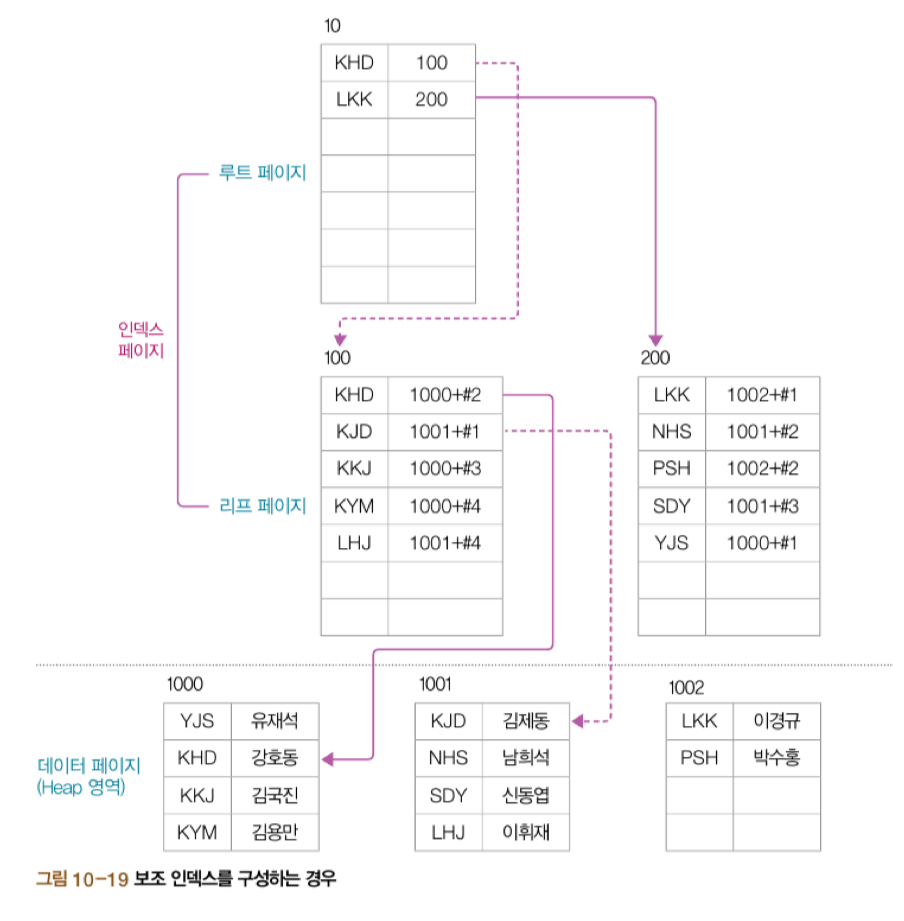
검색
클러스터형 인덱스는 데이터 검색 속도가 보조 인덱스보다 빠르다.
예: NHS를 검색하는 경우, 클러스터형 인덱스에서는 루트 페이지와 리프 페이지 총 2개의 페이지만 읽지만 보조 인덱스에서는 인덱스 페이지의 루트 페이지, 리프 페이지, 데이터 페이지 총 3개의 페이지를 읽어야 한다.
 |
 |
삽입
보조 인덱스의 성능 부하가 클러스터형 인덱스보다 적다. 하지만 전체적인 성능 부하는 보조 인덱스가 클러스터형 인덱스보다 많다.
 |
 |
특징
클러스터형 인덱스의 특징
- 인덱스를 생성할 때 데이터 페이지 전체가 다시 정렬된다. 이미 대용량 데이터가 입력된 상태에서 중간에 클러스터형 인덱스를 생성하면 시스템에 심각한 부하를 줄 수 있다.
- 리프 페이지가 곧 데이터 페이지이다. 인덱스 자체에 데이터가 포함되어 있다.
- 보조 인덱스보다 검색 속도가 빠르고, 데이터 변경(삽입, 수정, 삭제) 속도는 느리다.
- 클러스터형 인덱스는 테이블에 하나만 생성할 수 있다. 어느 열에 클러스터형 인덱스를 생성하는지에 따라 시스템의 성능이 달라진다.
보조 인덱스의 특징
- 인덱스를 생성할 때 데이터 페이지는 그대로 둔 상태에서 별도의 페이지에 인덱스를 구성한다.
- 리프 페이지에 데이터가 아니라 데이터가 위치하는 주소 값(RID)이 들어 있다.
- 데이터 변경(삽입, 수정, 삭제) 시 클러스터형 인덱스보다 성능 부하가 적다.
- 보조 인덱스는 한 테이블에 여러 개를 생성할 수 있다. 하지만 함부로 남용하면 오히려 시스템의 성능을 떨어뜨리는 결과를 초래할 수 있으므로 필요한 열에만 생성해야 한다.
인덱스 생성
인덱스 생성 형식
CREATE [UNIQUE | FULLTEXT | SPATIAL] INDEX index_name
[index_type]
ON TBL_userName (index_col_userName, )
[index_option]
[algorithm_option | lock_option]
index_col_userName:
col_userName [(length)] [ASC | DESC]
index_type:
USING {BTREE | HASH}
index_option:
KEY_BLOCK_SIZE [=] value
| index_type
| WITH PARSER parser_userName
| COMMENT 'string'
algorithm_option:
ALGORITHM [=] {DEFAULT | INPLACE | COPY}
lock_option:
LOCK [=] {DEFAULT | NONE | SHARED | EXCLUSIVE}
CREATE INDEX문으로 인덱스를 만들면 보조 인덱스가 생성된다.CREATE INDEX문으로는 클러스터형 인덱스를 만들 수 없으며, 클러스터형 인덱스를 만들려면 앞에서 배운ALTER TABLE문을 사용해야 한다.CREATE INDEX문의UNIQUE옵션은 고유한 인덱스를 만들 때 사용한다.- UNIQUE로 설정된 인덱스에는 동일한 데이터 값이 입력될 수 없다.
- ASC, DESC는 정렬 방식을 지정하는데, ASC가 기본값이고 오름차순으로 정렬된 인덱스가 생성된다.
index_type은 생략 가능하며, 생략할 경우 기본 값인 B-Tree 형식이 사용된다.
인덱스 생성 기준
- 인덱스는 열 단위에 생성된다.
- 인덱스는 WHERE 절에서 사용되는 열에 생성된다.
- WHERE 절에 사용되는 열이라도 자주 사용해야 가치가 있다.
- 데이터 중복도가 높은 열에는 인덱스를 만들어도 효과가 없다.
- 외래키를 설정한 열에는 자동으로 외래키 인덱스가 생성된다.
- 조인에 자주 사용되는 열에는 인덱스를 생성하는 것이 좋다.
- 데이터 변경(삽입, 수정, 삭제) 작업이 얼마나 자주 일어나는지 고려해야 한다.
- 클러스터형 인덱스는 테이블당 하나만 생성할 수 있다.
- 테이블에 클러스터형 인덱스가 아예 없는 것이 좋은 경우도 있다.
- 사용하지 않는 인덱스는 제거한다.
인덱스 삭제
인덱스 삭제 형식
DROP INDEX index_name ON TBL_userName
[algorithm_option | lock_option]
algorithm_option:
ALGORITHM [=] {DEFAULT | INPLACE | COPY}
lock_option:
LOCK [=] {DEFAULT | NONE | SHARED | EXCLUSIVE}
DROP INDEX 인덱스이름 ON 테이블이름;- 클러스터형 인덱스를 삭제하려면 위 구문의 인덱스 이름 부분에
PRIMARY를 넣는다. - 인덱스를 모두 삭제할 때는 보조 인덱스부터 삭제한다.
- 인덱스를 많이 생성해놓은 테이블의 경우 각 인덱스의 용도를 확인한 후 활용도가 떨어지는 인덱스를 삭제한다.
인덱스 활용
다음과 같은 테이블이 있다.
CREATE DATABASE IF NOT EXISTS testDB;
USE testDB;
DROP TABLE IF EXISTS yeongu;
CREATE TABLE yeongu (
userID CHAR(8) PRIMARY KEY,
userName VARCHAR(10),
birthYear INT,
addr CHAR(8)
);
INSERT INTO yeongu (userID, userName, birthYear, addr) VALUES
('SYW', '서영우', 2003, '광주'),
('KDY', '김다영', 2003, '여수'),
('KKY', '김가연', 2001, '광주'),
('JBG', '조배경', 2001, '익산'),
('JSI', '정수인', 2001, '광주'),
('KMD', '강명덕', 2001, '제주'),
('SMB', '심민보', 2000, '광주'),
('KJM', '김종민', 2001, '광주'),
('BGH', '백경환', 2000, '여수');
SELECT * FROM yeongu;
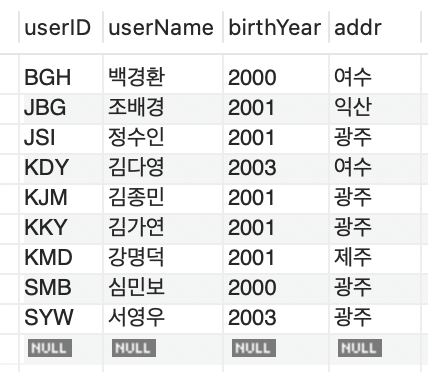
어떤 인덱스가 생성되어 있는지 확인해보자.
SHOW INDEX FROM yeongu;
주소(addr) 열에 단순 보조 인덱스를 생성해보자. 다음처럼 생성된 보조 인덱스를 확인할 수 있다. Non_unique도 1로 표시됐다.
CREATE INDEX yeongu_addr ON yeongu (addr);
출생 연도(birthYear) 열에 고유 보조 인덱스를 생성해보자. 중복값이 있어 에러가 발생하고 생성되지 못하였다.
CREATE UNIQUE INDEX yeongu_birthYear ON yeongu (birthYear);
이름(userName) 열에 고유 보조 인덱스를 생성하면 문제없이 생성된다. 이름(userName) 열과 출생 연도(birthYear) 열을 조합하여 인덱스를 생성할 수도 있다.
CREATE UNIQUE INDEX yeongu_userName ON yeongu (userName);
CREATE INDEX yeongu_userName_birthYear ON yeongu (userName, birthYear);
DROP INDEX yeongu_userName ON yeongu;
SELECT * FROM yeongu WHERE userName = '서영우' and birthYear = 2003;다음은 두 열이 조합된 조건문의 쿼리에 인덱스가 사용된 결과이다.
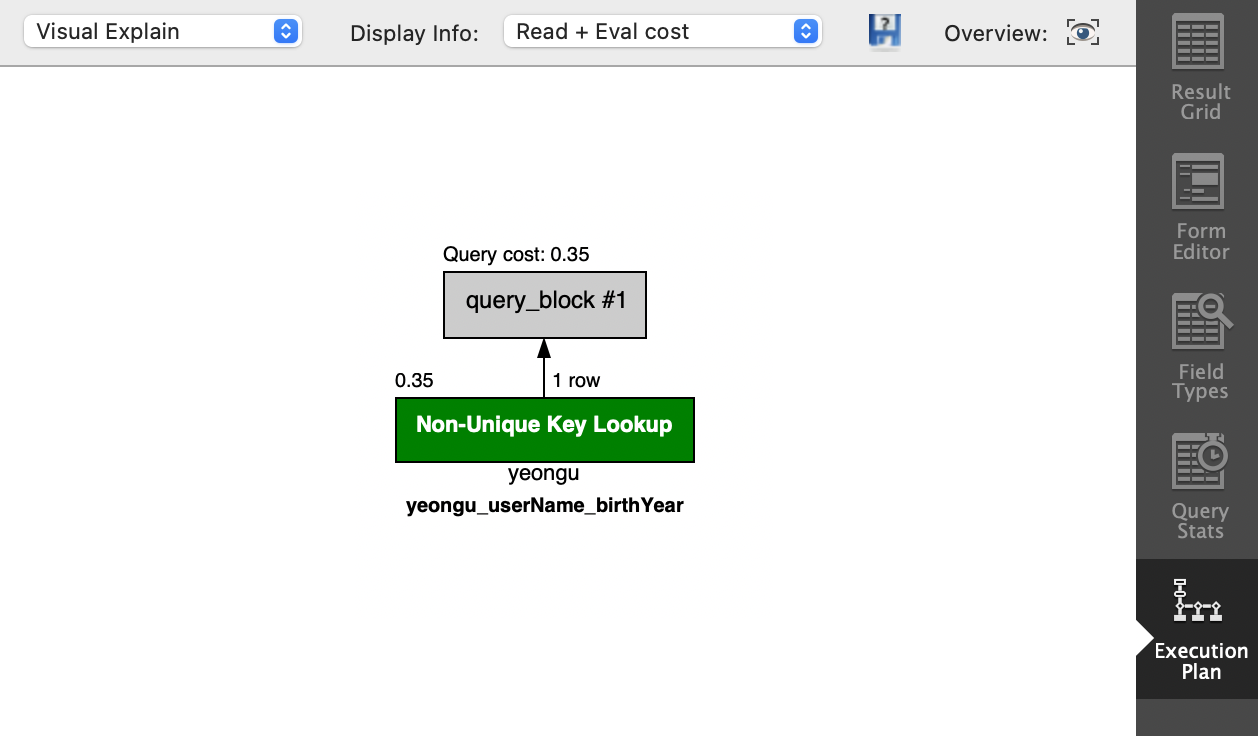
동일한 데이터를 구성한 테이블에서 인덱스를 사용하지 않았을 때 쿼리 결과이다. 쿼리 속도가 차이 나는 것을 확인할 수 있다.
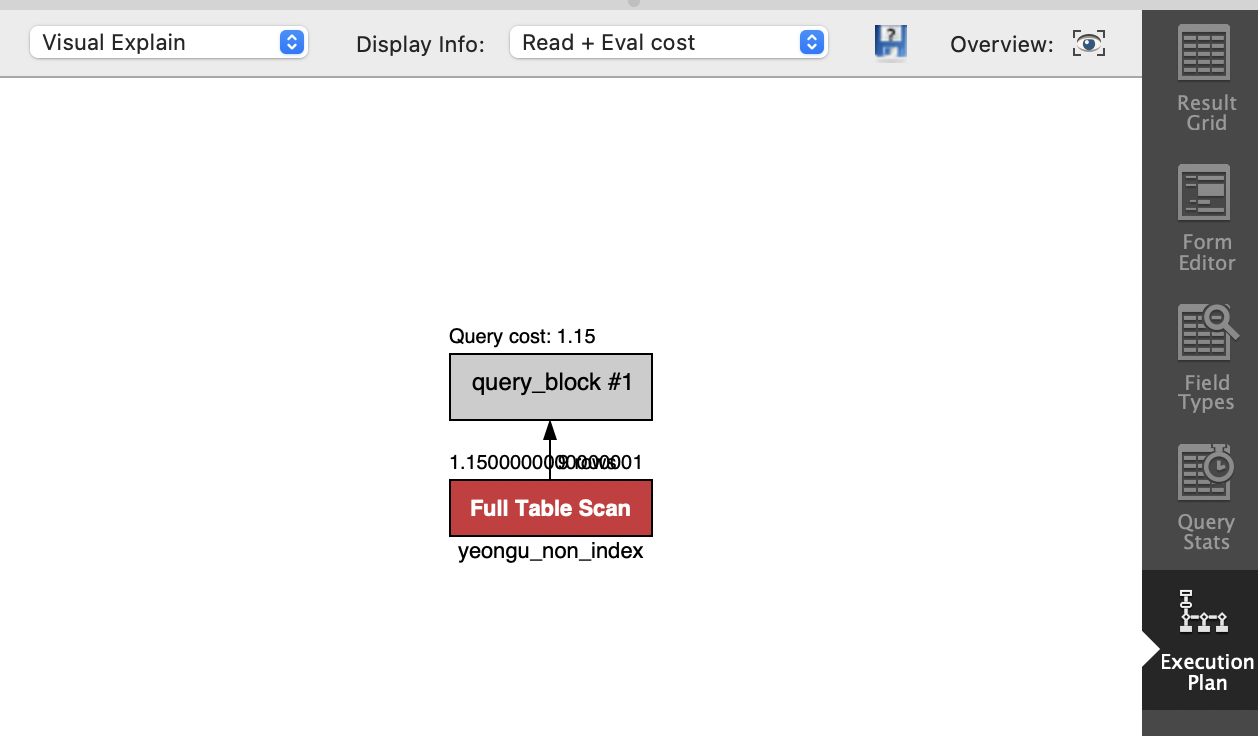
인덱스 삽입은 어엄청 많은 데이터로 실험해야 하니까 pass..
이제 인덱스를 삭제해보자. 순서에 맞게 삭제해주는 것이 중요하다. 보조 인덱스를 먼저 삭제하고 이후에 자동으로 생성된 클러스터형 인덱스를 삭제한다.
DROP INDEX yeongu_addr ON yeongu;
DROP INDEX yeongu_userName_birthYear ON yeongu;
ALTER TABLE yeongu DROP PRIMARY KEY;