
요즘의 근황
요즘 A1 Factory의 현석님을 통해 'Zen of Python' 활동을 하고 있다. (줄여서 Z.O.P.라고 하자!) Z.O.P.는 파이썬의 기초부터 고급까지 여러 함수와 기능들을 알아보면서 활용을 해보는 스터디이다. Z.O.P. 첫 시간엔 데이터 처리를 위한 속도 향상에 대한 것을 배울 수 있었다. 덕분에 tuple의 이점, boolean index의 이점 등을 더 명확히 알 수 있었던 것 같다. 그런데 배우면서 생각해보니 리스트를 사용했을 때, remove를 사용하거나 index를 사용하는 등의 작업들이 얼마나 많은 시간을 소요하는지 궁금해졌다. 추가로 더 효율적인 문제 처리 방법이 없을지 고민해보기로 하였다.
알고리즘에서의 시간 초과
처음 파이썬으로 코딩을 시작했을 때, 대부분 알고리즘을 리스트를 이용해 풀곤 했다. 그런데 몇몇 문제들에서 시간 초과 오류를 굉장히 접하게 되면서 방법들을 변경하게 되었다. 그럼에도 리스트는 여전히 자주 사용되는 자료구조 중 하나이다. 오늘은 리스트를 사용하면서 궁금했던 여러 메서드들의 소요시간을 알아보고자 한다.
리스트와 Append
리스트는 어떤 결과를 만들어 담아낼 수 있는 아주 편한 자료구조이다. 하지만, 시간적인 문제에서는 꽤나 비효율적인 면이 있다. 데이터가 적은 경우에는 크게 경향을 미치지 않지만, 양이 방대해질수록 그 효과는 크게 나타난다.
그럼 얼마나 시간이 걸리는지 time을 통해 알아보자.
import time
times = [1, 10, 100, 1000, 10000, 100000, 1000000, 10000000, 100000000]
def list_append(times):
start = time.time()
a = []
for i in range(times):
a.append(i)
end = time.time()
return end-start
append_t = [list_append(t) for t in times]실행시간을 알아보기 위해서는 두 가지 방법이 있는데 첫 번째는 time 라이브러리를 사용하여 작업의 끝 시간에서 시작 시간을 빼주는 방법이다. 두 번째는 timeit을 사용하는 방법이다. timeit을 import하여 불러온 뒤, %timeit 함수()를 사용하여 같이 돌려주면 함수를 여러 번 실행 후, 평균적인 실행 시간과 오차 값을 돌려준다.
append의 결과는 ??
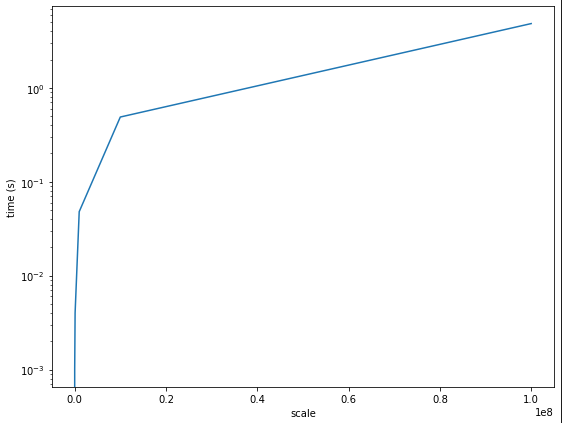
1000번 까지의 append는 크게 영향이 없지만, 그 이후부터는 빅오가 선형적으로 증가하는 것을 볼 수 있었다. 즉, 데이터가 많을수록 큰 영향을 미치는데, time을 돌려본 결과, append를 1억 번 실행했을 때에는 약 5초 정도가 소요됐다. 이 시간은 컴퓨터의 성능에 따라 크게 달라질 수 있다. 성능이 좋은 컴퓨터일수록 계산 시간은 줄어든다.
더 효율적인 방법?
리스트를 사용해 데이터를 저장한다면, 더 효율적인 방법이 존재한다. 바로 리스트 컴프리헨션(list comprehension)이다. 물론 리스트 컴프리헨션도 빅오 문제에 있어서는 O(n)의 시간을 따른다. 하지만, 리스트보다는 조금 더 시간을 절약할 수 있다는 장점이 있다. 그 이유는 리스트를 불러오고 값을 append하는 일련의 작업 과정이 빠져있어 task가 줄어든다는 현석님의 명쾌한 설명이 있었다..!
times = [1, 10, 100, 1000, 10000, 100000, 1000000, 10000000, 100000000]
def list_comprehension(times):
start = time.time()
a = [i for i in range(times)]
end = time.time()
return end-start
comprehension_t = [list_comprehension(t) for t in times]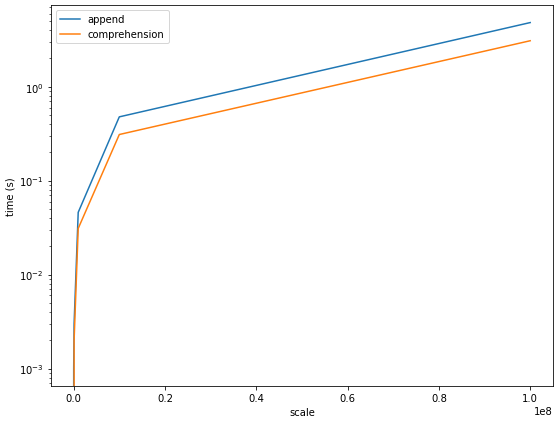
결과를 보자면, 리스트의 append와 comprehension의 빅오는 똑같지만, comprehension의 실행 시간이 append보다 조금 덜 걸린다는 것을 확인할 수 있다. 실제로, comprehension의 1억 번 실행 시간은 약 3.1초 정도로 append보다 40% 정도 빨랐다.
가능하다면, 이제는 append보다 comprehension을 더 더 더 사용해보자!!
remove와 pop, del의 시간 차이는 얼마나 날까?
-
remove 사용
리스트.remove(value)의 형태로 사용한다. -
pop 사용
리스트.pop(index)의 형태로 사용한다. -
del 사용
del(리스트[index])의 형태로 사용한다.
remove, pop, del의 경우는 for문을 사용시 IndexError가 발생할 수 있기 때문에 주의해야 한다!
여튼, 효율적으로 시간을 계산해보기 위해서 1억 개의 수를 리스트에 담아 10번 제거 작업을 거치면서 평균적인 실행시간을 계산해보았다.
(여기서 remove의 경우 해당 값이 지워지는 경우에 Error를 발생시켜 모든 값을 0으로 통일하였고, remove(list[0])을 사용했을 때에는 좀 더 긴 실행 시간이 소요되었다!)
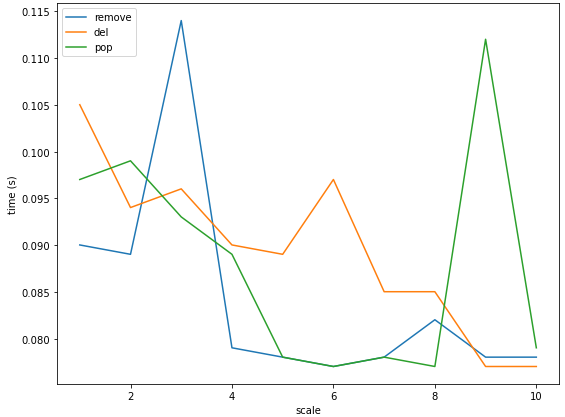
결과적으로 remove, pop, del 모두 작업을 처리하는데 소요되는 평균적인 시간은 크게 차이나지 않았다. 편한 걸로 사용하는 것으로 하자 . . !
index의 소요시간
리스트의 자료구조에서 index 또한 O(n)의 소요시간이 걸린다고 알고 있다. 얼마나 오랜 시간이 걸리는지 알아보자.
find_num = [0, 9, 99, 999, 9999, 99999, 999999, 9999999, 99999999]
def list_index(n):
start = time.time()
numbers.index(n)
end = time.time()
return end - start
index_t = [list_index(i) for i in find_num]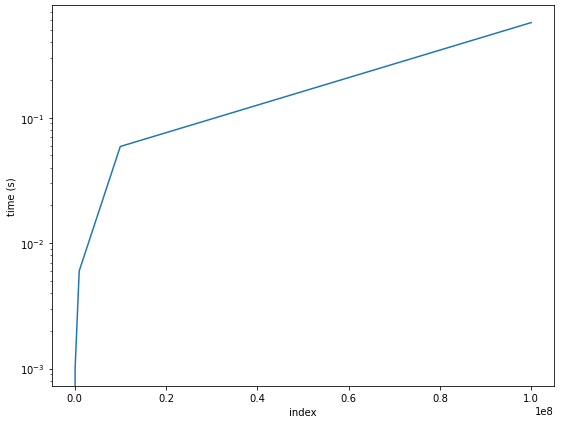
역시나 append, comprehension의 결과가 유사한 그래프가 그려졌다. 하지만, 실행 시간은 비교적 짧았는데, 극단적인 결과를 확인해보고자 가장 뒤에 있는 숫자를 찾아보고자 하였고 99,999,999를 찾는데 걸리는 시간은 약 0.57초가 소요되었으며 append보다 거의 9배 빠르기였다.
sort & reverse
sort와 reverse에 대해서도 결과가 궁금했다. 굉장히 많은 시간이 걸릴 것이라고 생각한 것과는 다르게 정렬된 리스트에 대해 reverse의 경우, 1억 개의 데이터가 있음에도 불구하고 약 0.057초라는 아주 빠른 결과를 보여주었다. 처음부터 정렬된 데이터라서 그런 것인지 확인해보기 위해 random을 import하여 임의의 숫자를 리스트에 담아 시험해보기로 하였다.
import random
num = [random.random() for i in range(100000000)]
def sort_time():
start = time.time()
num.sort()
end = time.time()
return end - start
sort_time()1억 개의 임의의 수를 섞어놓은 리스트에 sort를 사용했더니 34초라는 어마무시한 실행 시간이 소요되었다... 데이터가 방대할 수록 sort는 조심해서 써야겠다. (참고로, 실행 시간이 오래 걸릴 것 같아 여러 번 시도하지는 않았다.)
len
len의 경우는 얼마나 소요 시간이 걸릴까? timeit을 통해 돌려보았더니 놀랍게도 sort와는 다르게 10,000,000번의 평균 실행 시간은 44ns(1ns는 10억 분의 1초)로 굉장히 짧다는 것을 확인할 수 있었다. (len은 마음껏 써야겠다~)
count
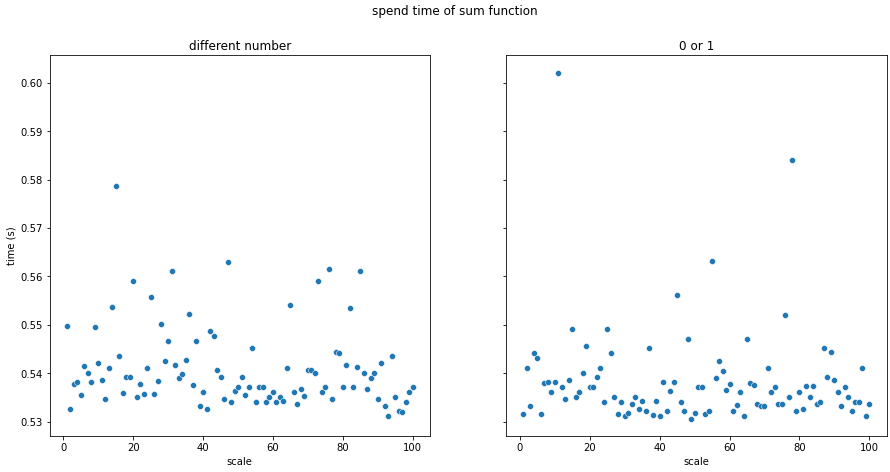
갯수를 찾아주는 count의 경우는 1억 개의 데이터가 담긴 리스트에 대해 100번의 실행 결과, 평균적인 실행 시간은 약 0.6초였다. (찾는 요소의 개수에 따라 달라질까 하여 0과 1로 도배된 리스트를 따로 만들어 실행해보았지만, 실행시간은 거의 비슷하였다. 오히려 0.54초로 짧았다..) count는 그렇게 크게 시간이 걸리는 것 같지는 않다.
max와 min
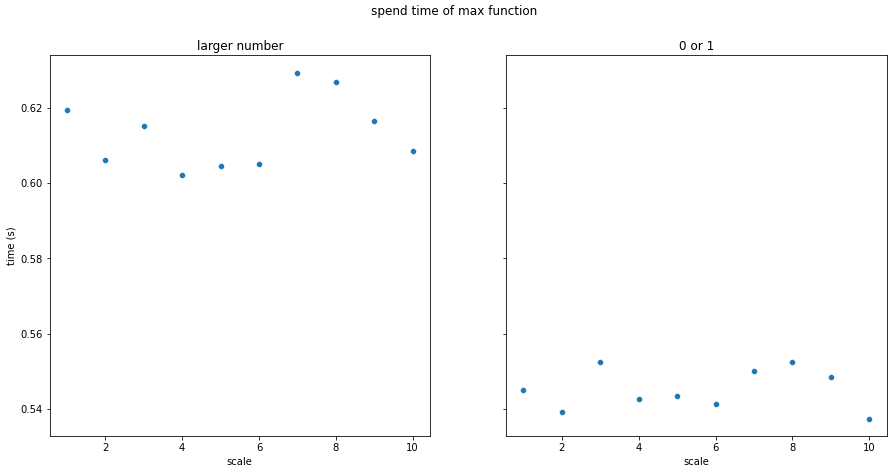
count의 결과를 보며 max와 min도 결과가 비슷하지 않을까 생각하며, 실험해 본 결과, 생각과 일치하게 약 0.55초로 비슷한 결과를 보여주었다. 하지만, count와는 다르게 0과 1로 도배된 리스트의 경우보다 index에 따라 증가하는 값을 가진 리스트의 경우 약 0.65초로 조금 더 시간이 걸리는 것을 확인할 수 있었다.
sum
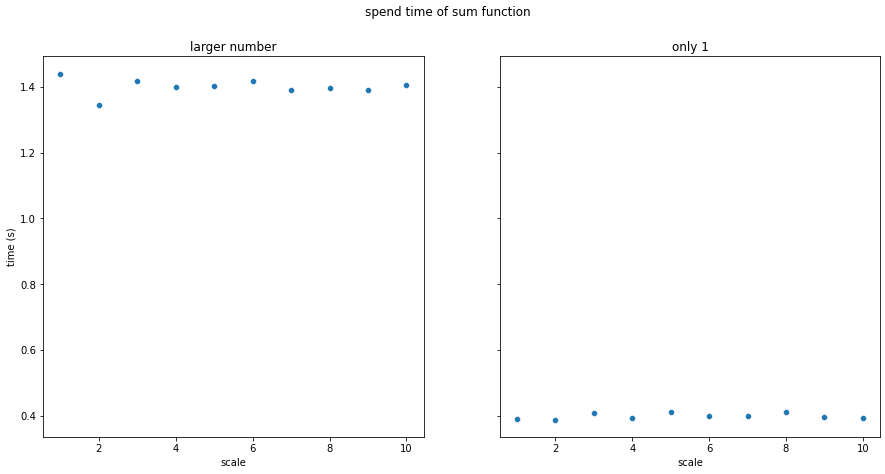
sum의 경우도 실행 시간이 궁금해서 두 가지 실험을 해보았다. 하나는 크기가 1억이고 값이 모두 1인 리스트이고, 하나는 크기가 1억이며, 값이 1부터 index에 따라 1씩 증가하는 리스트이다.
실험 결과, 전자의 경우 평균 소요 시간은 약 0.4초였으며, 후자의 경우 약 1.4초로 더 길었다. 즉, sum을 해야하는 value의 값이 클수록 sum의 실행 시간은 길어진다는 것을 확인할 수 있었다.
글을 마치며
이렇게 리스트에 사용할 수 있는 메서드의 소요 시간에 대해서 알아보았다. 오랜만에 연구하는 느낌도 들었고, 자료구조에 대해 좀 더 깊게 알 수 있었던 좋은 기회였다. 앞으로 공부하면서 이렇게 하나씩 자세히 파보는 것도 프로그래밍을 배워가면서 느끼는 하나의 소소한 재미가 될 것 같다.
