API와 웹 크롤링을 활용한 데이터 수집 방법
📌 DATA 수집 방법
- 공식 API를 활용한 데이터 수집
- 웹 스크롤링 또는 자동화된 데이터 수집
📌 공식 API 활용하여 데이터 수집
- LinkedIn API: 기업 및 프로페셔널 데이터 제공
- OpenCorporates API: 전 세계 기업 데이터 제공
- Clearbit API: 기업 및 직원 정보를 가져올 수 있는 API
- 공공데이터 포털 (data.go.kr): 국내 기업 및 기관 데이터를 무료로 제공
- LinkedIn Talent API: 채용 및 인재 매칭 관련 데이터 제공
📌 웹 크롤링 활용하기
- 기업 데이터가 포함된 사이트 (ex. 뉴스, 기업 홈페이지, 구인 사이트 등)
- 검색 결과에서 기업 정보를 노출하는 사이트 (ex. Google, LinkedIn, Indeed 등)
크롤링 방식 선정
정적 웹사이트 크롤링 (HTML 기반)
- Requests + BeautifulSoup (Python)
- 기업명, 주소, 연락처 등 HTML에서 추출 가능
동적 웹사이트 크롤링(JavaScript 렌더링 필요)
- Selenium (Python) 활용
📌 브라우저에서 직접 API 데이터 수집하는 방법
1. Postman 또는 Thunder Client 사용하기
- 공식 API가 있다면 API 키를 발급받은 후 Postman 또는 Thunder Client(Visual Studio Code 확장 프로그램)로 API 테스트
- API 요청 후, JSON 데이터가 정상적으로 불러오는지 확인 가능함
2. 크롤링 없이 웹페이지에서 데이터 가져오기 (JavaScript DOM 활용)
공식 API가 없다면 직접 웹사이트의 데이터 가져오기 (개발자 도구 활용 가능)
⭐️ 단순한 웹 데이터 수집용으로 활용 가능
✅ 네이버 기사 제목 가져오기
const titles = [...document.querySelectorAll(".cc_text_item")].map(el => el.innerText);
console.log(titles);✅ 결과 화면
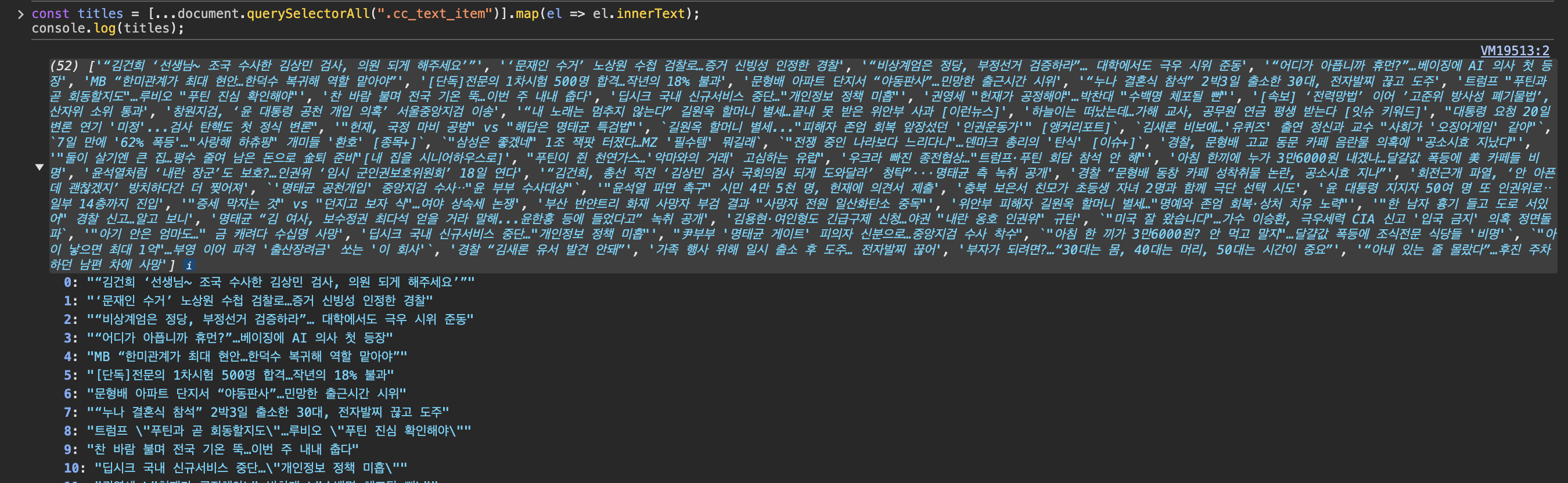
→ 기사 제목이 배열 형태로 출력
3. Puppeteer 활용
Puppeteer : Node.js 기반 자동화 도구, 프론트엔드 개발자가 크롤링을 하고 싶다면 Python 대신 Puppeteer 사용 가능
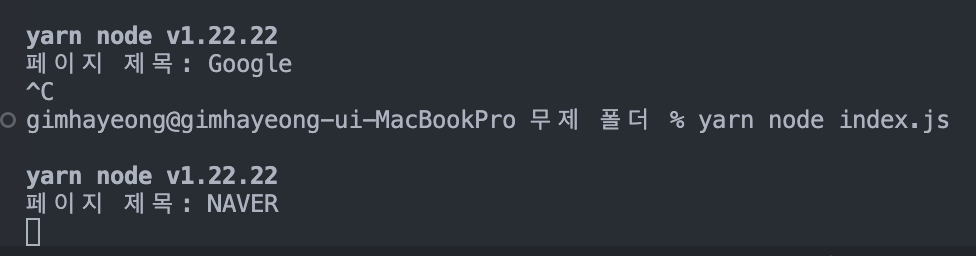
✏️ 웹사이트 페이지 제목 불러오기
const puppeteer = require("puppeteer");
(async () => {
// 브라우저 실행
const browser = await puppeteer.launch({ headless: false }); // headless: false → 브라우저 화면 보이게 함
const page = await browser.newPage();
// 구글 검색 페이지 방문
await page.goto("https://www.google.com");
// 페이지 제목 가져오기
const title = await page.title();
console.log("페이지 제목:", title);
// 브라우저 종료
await browser.close();
})();✅ 결과 화면
✏️ 기본적인 기업 정보 크롤링 예제
https://www.crunchbase.com/ 사이트에서 기업명 가져오기 (사진확인)
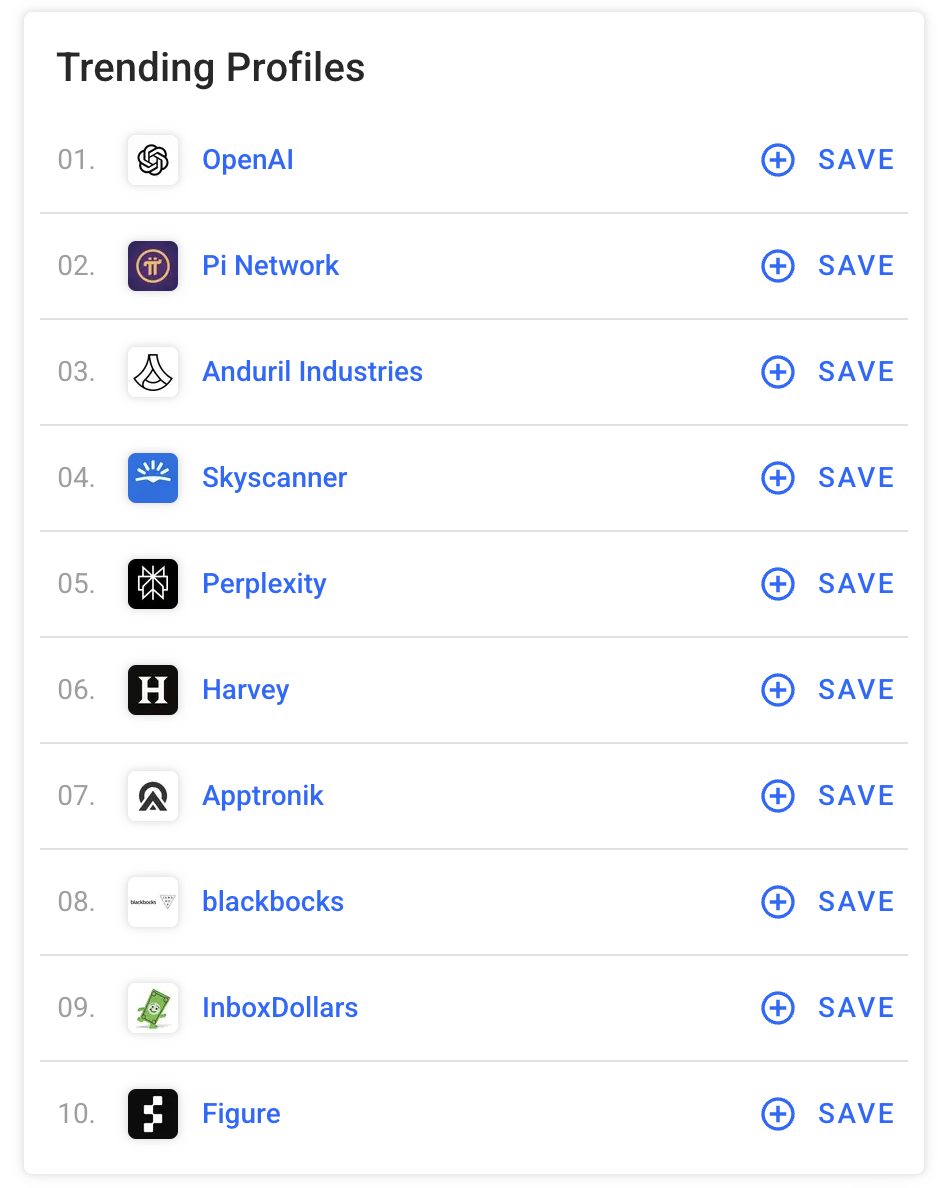
const puppeteer = require("puppeteer");
(async () => {
const browser = await puppeteer.launch({ headless: false });
const page = await browser.newPage();
// Crunchbase 메인 페이지 방문
await page.goto("https://www.crunchbase.com/", { waitUntil: "networkidle2" });
// 데이터가 로딩될 때까지 기다리기 (identifier-value가 포함된 요소)
await page.waitForSelector("div.identifier-value", { timeout: 10000 });
// 기업 리스트 크롤링
const companies = await page.evaluate(() => {
// identifier-value 클래스를 가진 모든 div 요소 찾기
const companyElements = document.querySelectorAll("div.identifier-value");
return [...companyElements].map((el) => el.innerText.trim()); // 기업명만 가져오기
});
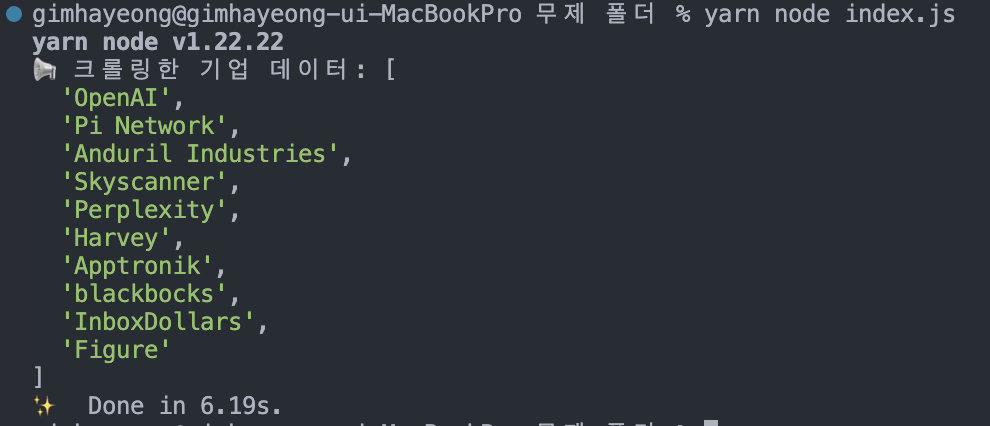
console.log("📢 크롤링한 기업 데이터:", companies);
// 브라우저 종료
await browser.close();
})();위 사이트는 비동기적으로 로딩하기 때문에, waitForSelector()를 사용하여 원하는 요소가 로드될 때까지 기다려야 한다.
✅ 결과확인
방법 및 설명 총 정리
| 방법 | 설명 | 사용 예시 |
|---|---|---|
| Postman / Thunder Client | API 요청 테스트하는 도구 | 공식 API 가 있는 경우 |
| Fetch API (브라우저 콘솔) | API 데이터를 직접 호출하여 확인 | 빠르게 API 데이터를 확인하고 싶을 때 |
| DOM 이용하여 데이터 추출 | 웹사이트에서 특정 요소 불러오기 | API 없고 간단한 데이터 필요 시 사용 |
| Puppeteer (Node.js 기반 크롤링) | 브라우저 자동화 및 데이터 수집 | 데이터 수집 자동화 필요 시 사용 |
📌 크롤링 시 주의사항
1. robots.txt 확인 (크롤링 허용 여부 확인)
https://example.com/robots.txt에 Disallow 항목이 있는지 확인
- User-agent: * : 모든 웹 크롤러(예: Googlebot, Bingbot, Puppeteer 등)에 적용된다는 의미
- Disallow: (크롤링 금지 경로) ⚠️ 해당 페이지를 크롤링하면 법적 문제 발생할 수 있음
- Allow: (크롤링 허용 경로)
2. 사이트가 크롤링 방어하는 경우 우회하여 크롤링
- User-Agent 변경
await page.setUserAgent("Mozilla/5.0 (Windows NT 10.0; Win64; x64)");- 랜덤 딜레이 추가
await page.waitForTimeout(Math.random() * 3000 + 1000); // 1~4초 랜덤 대기📚 참고 자료

왕쪼랩 탈출 목표자의 코딩 공부기록