흔히 자바의 특징 중 하나를 설명하라 하면 Garbage Collector(GC)를 말할것이다. 그만큼 편리하고 중요한 기능 중 하나를 자세히 알아보겠다.
인스턴스를 만들때 우리는 new키워드를 사용하여 생성한다. 하지만 생성 후 삭제 해주지 않으면 메모리에 쌓이게 되고 결국 더이상 객체 생성을 하지못하게 될거다
ex)
Person p = new Person();생성 된 객체는 JVM 메모리 구조 중 Heap영역에 쌓이게 되는데 개발자가 직접 해제하지 않고, 시스템이 자동으로 해제해주기 때문에 서비스 로직에만 신경쓰게 도와주는 기능이다
우선 JVM의 메모리 구조를 살펴보자
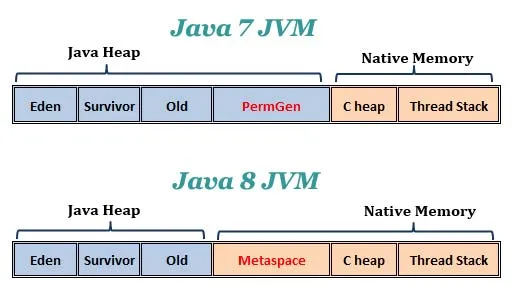
※ java8 이후 Heap 영역안에 있던 Permgen이 사라지고 Heap영역 밖으로 Metaspace로 변경 되었다.
Heap: 모든 쓰레드에서 공유하며, 객체와 모든 인스턴스 변수가 저장 되는곳 GC가 관리 한다.
Stack: 각 쓰레드마다 개별적으로 존재하며, 메서드 호출 시 생성된다. 지역 변수, 메서드 호출 정보, 복귀 주소 등을 포함한다. LIFO(Last In First Out) 구조로, 메소드가 종료되면 해당 스택 프레임이 제거된다.
Metaspace: 클래스의 메타데이터, 메서드 정보, 상수 풀, 클래스의 구조 정보 등이 저장. 이곳에 저장된 클래스 메타데이터는 클래스가 언로드될 때까지 유지.
C heap(Native Method Stack): 자바 외의 C/C++로 작성된 네이티브 라이브러리 호출에 사용된다. JVM이 제공되는 표준 자바 메소드가 아닌 OS가 제공하는 네이티브 코드를 실행할 때 사용.
PC 레지스터: 각 쓰레드마다 고유하게 존재하며, 현재 실행 중인 JVM 명령의 주소를 저장한다. 쓰레드가 컨텍스트 스위칭될 때 실행 위치를 기록하여, 쓰레드 간 문맥 교환이 원할하게 이루어지게 돕는 역할.
대부분의 이미지나 설명에서는 PC레지스터를 스택 영역의 일부로 취급하는 경우가 많아 생략 되어있다
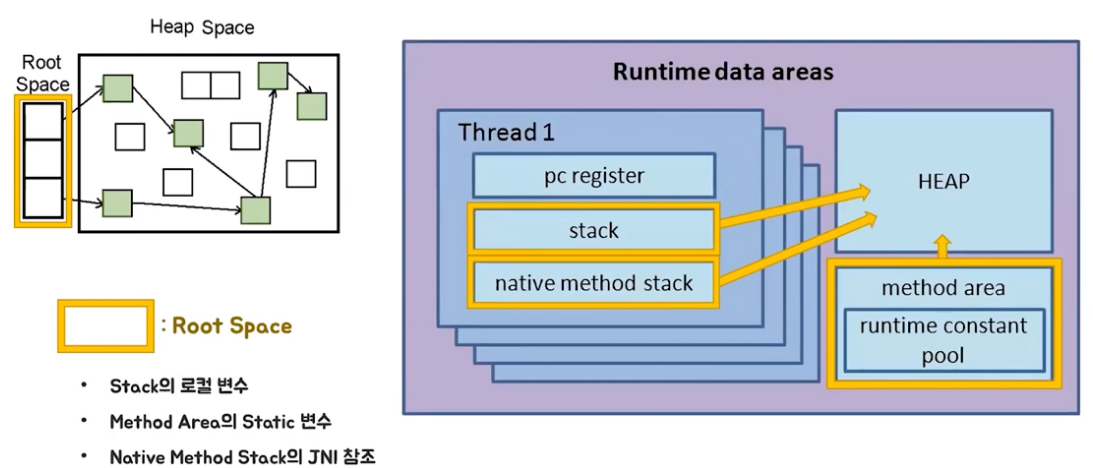
JVM 방식은 기본적으로 Mark-and-Sweep 방식으로 이루어져 있는데, Root Space부터 해당 객체에 접근 가능한지가 해제의 기준이다 그래서 JVM의 메모리 구조에 대해 설명한것이다.
Mark-and-Sweep 방식
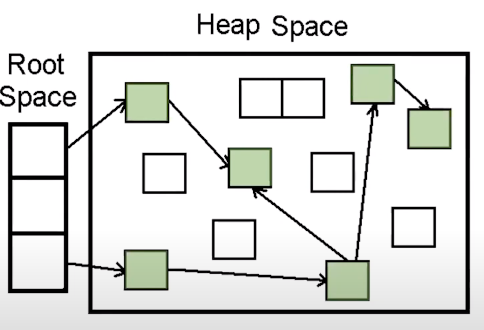
Mark란 Root Space로 부터 연결된 객체를 찾는다
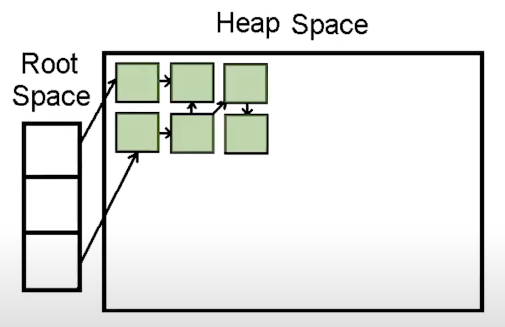
Sweep이란 연결이 끊어진 객체들을 지우는 방식이다
그럼이제 어떻게 Heap 영역에서 GC가 이루어지는지 자세하게 보자
Heap 영역에는 크게 Eden, Survival0, Survival1, Old Generation 영역이 존재 한다.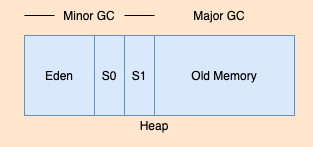
Minor GC: Eden, Survival0, Survival1 영역에서 GC가 발생함
Major GC: Old Generation 영역에서 GC가 발생함
- 객체가 생성이 되면 Eden영역에 존재하게 됨
- Eden영역에 객체가 가득차면 Minor GC가 발생하고 S0 or S1으로 이동하게 됨
- 위의 1번이 반복되면 S0에 있던 객체는 S1으로 이동하게 됨 S1에 있었으면 S0으로 이동
즉 S0 및 S1은 항상 비워져 있음두 영역 중 하나를 비워두는 이유는 살아남은 객체를 그곳으로 쉽게 이동 가능하고 객체 복사 과정이 단순해져 메모리 관리가 효율적으로 이루어진다.
- 1~3 과정이 반복하다가 일정한 age-bit(survivor영역에서 살아남은 횟수)가 넘어가면 Old Generation 영역으로 넘어간다.
- 어느순간 Old Generation이 가득 찰때가 있을거다 그때 Major GC가 발생하면서 Mark-and-Sweep방식으로 객체를 지워준다.
GC를 실행하기 위해 나머지 쓰레드는 모두 작업을 멈춘다.
그게 Stop-The-World(STW)이다. 어느 GC 알고리즘을 사용해도 STW가 발생한다 대부분의 튜닝이나 새로운 알고리즘은 STW의 최소한의 시간을 줄이는 것이다.
또한 그러한 이유 중 하나로 Young, Old가 나누는 이유이다. 대부분의 객체는 생성된 후 바로 사용 후 빠르게 소멸한다. 이러한 이유로 나누어 GC 빈도를 감소 시킨다
다양 한 GC알고리즘이 있지만 대표적인 알고리즘만 소개 하겠다.
1.CMS GC
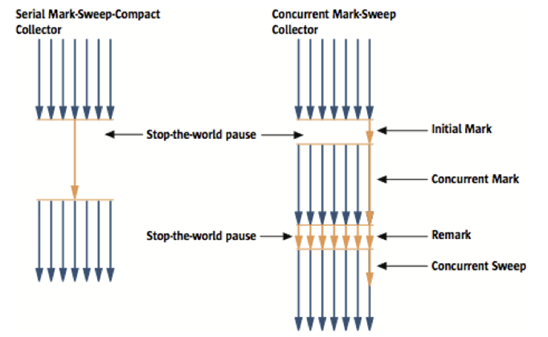
왼쪽 이미지가 위의 설명한 GC 방법이고, 오른쪽 이미지가 CMS GC이다.
CMS GC는 Old Generation을 대상으로 작동하며, 4단계가 추가 되었다.
1. Initial Mark: GC 루트에서 직접 참조되는 객체만 마크한다.
2. Concurrent Mark: 살아있다고 확인한 객체에서 참조하고 있는 객체들을 따라가면서 확인한다.
1,2 특징으로는 다른 스레드가 실행 중인 상태에서 동시에 진행한다.
3. Remark: Concurrent Mark 단계에서 새로 추가되거나 참조가 끊긴 객체를 확인한다.
4. Concurrent Sweep: 마크되지 않은 객체들을 청소한다.
이 단계도 애플리케이션 스레드와 병행하여 실행되며, 가용한 메모리 영역을 확보
G1GC 등장에 따라 Deprecated
단점
높은 CPU 사용량: 애플리케이션 스레드와 병행하여 GC 작업을 수행하기 때문에, CPU 사용량이 높아질 수 있다. 특히, Concurrent Mark와 Concurrent Sweep 단계에서 CPU 리소스를 많이 소모
메모리 단편화: Mark-And-Sweep 알고리즘은 메모리를 압축(compaction)하지 않기 때문에, 메모리 단편화가 발생할 수 있다. 이로 인해 충분한 연속된 공간을 찾지 못하면 Full GC가 발생할 수 있다.
Full GC는 JVM에서 모든 메모리 영역을 대상으로 가비지 수집을 수행하는 과정으로, Young Generation과 Old Generation을 포함하여 메소드 영역(Permanent Generation, 메타스페이스)까지 모두 검사
내부 단편화
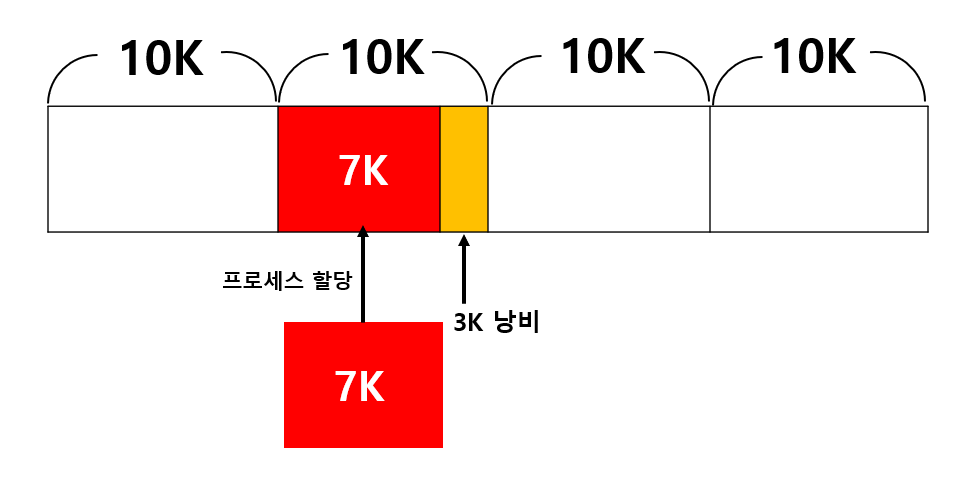
외부 단편화
2.G1 GC
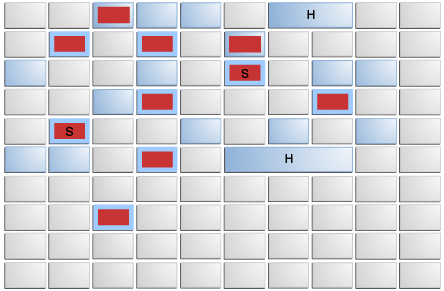
G1(Garbage First)란 회수 가능한 Region을 우선적으로 수집하는 전략이다.
또한 Minor, Major GC 단계에서 메모리 압축을 수행하여 메모리 단편화를 줄일 수 있다.
Heap 메모리를 여러 영역으로 나누어 관리(하나의 바둑판), CMS GC의 단점을 개선하고 Full GC를 최소화 하는데 주력한다.
Initial Mark, Concurrent Mark, Remark,Live Data Counting And Cleanup, Garbage Collection and Compaction 단계로 이루어져 있다.
CMS방식과 Mark까지는 똑같다
Live Data Counting and Cleanup: 살아있는 객체의 크기를 계산하고, 가장 많은 가비지를 포함하는 Region을 식별 후 선택된 Region을 정리하여 메모리 공간을 확보.
Garbage Collection and Compaction: 선택된 Region에서 살아있는 객체를 다른 Region으로 이동시키고, 메모리를 압축한다.
이 단계에서는 메모리 단편화를 줄이기 위해 객체를 모아서 연속된 공간에 배치.
참조 : https://velog.io/@hanhs4544/%EB%A9%94%EB%AA%A8%EB%A6%AC-%EB%8B%A8%ED%8E%B8%ED%99%94Memory-Fragmentation
https://d2.naver.com/helloworld/1329
Humongous Objects
Object >= region 크기의 50% 이상인 큰 객체를 말합니다.
이러한 경우 Old Generation으로 취급 받는이유
Young Generation은 일반적으로 작은 객체들이 빠르게 할당되고 제거되기 때문에, 이 공간에서 큰 객체를 처리하면 효율이 떨어집니다.
-
Young Generation에 적합하지 않은 이유
2.1 Young GC의 빈번한 실행
Young GC는 짧은 생명 주기를 가진 객체를 빠르게 회수하기 위해 자주 실행됩니다.
Humongous Objects는 일반적으로 오래 살아남을 가능성이 높은 객체입니다.
Young GC에서 큰 객체를 계속 검사하고 이동하는 것은 불필요한 성능 오버헤드를 초래합니다.
크기가 큰 객체를 자주 이동하면 GC의 비용(복사 및 메모리 관리 비용)이 크게 증가합니다.
2.2 Young Generation의 메모리 특성
Young Generation은 작은 Region으로 구성되며, 대부분 짧은 생명 주기를 가지는 객체들을 수용합니다.
Humongous Objects는 크기 때문에 여러 Region에 걸쳐 저장되며, Young Generation에 저장할 경우 메모리 단편화와 Region 낭비 문제가 발생할 수 있습니다.
2.3 GC 효율성 저하
Young GC는 객체를 Eden → Survivor → Old로 이동시키며, 주로 작은 객체를 처리하는 데 최적화되어 있습니다.
Humongous Objects는 매우 크기 때문에 Survivor 영역으로의 이동 또는 Promotion(승격) 과정에서 GC 비용이 매우 높아집니다.
예를 들어, 5MB 크기의 객체를 Survivor로 복사하면 여러 Region 간 복사가 필요해지고, 이는 GC 성능을 크게 저하시킵니다. -
Old Generation에 바로 저장되는 이유
3.1 오래 살아남을 가능성
Humongous Objects는 일반적으로 애플리케이션에서 장기간 유지될 가능성이 높은 객체입니다.
G1GC는 이러한 객체를 바로 Old Generation에 저장함으로써, Young GC의 부담을 줄이고 전체 GC 효율성을 높입니다.
3.2 Mixed GC를 통한 효율적 관리
G1GC의 Mixed GC는 Old Generation의 Region을 선택적으로 청소하며, Humongous Objects가 저장된 Region도 Mixed GC의 대상이 될 수 있습니다.
Humongous Objects가 대부분 살아있다면 GC에서 제외되고, 그렇지 않다면 효율적으로 회수됩니다.
3.3 메모리 단편화 문제 완화
Humongous Objects는 Old Generation의 Humongous Region에 저장되므로, Young Generation의 메모리 단편화를 방지할 수 있습니다.
Old Generation은 큰 객체를 수용하기 위해 설계되었으므로, Humongous Objects를 처리하는 데 더 적합합니다. -
성능 최적화를 위한 설계
G1GC는 크기가 작은 객체는 Young Generation, 크기가 큰 객체는 Old Generation으로 나눔으로써 메모리 관리를 최적화합니다.
Humongous Objects를 Young Generation에서 처리하지 않음으로써:
GC 지연 시간을 줄이고,
메모리 단편화 문제를 방지하며,
큰 객체를 더 효율적으로 관리할 수 있습니다.
Collection Set
기본적으로 여러 영역의 집합(CSet)
모든 Young Generation을 통합 합니다.
Cset during a mixed collection - Young Generation & 일부 Old 영역이 같이 있을 수 있다
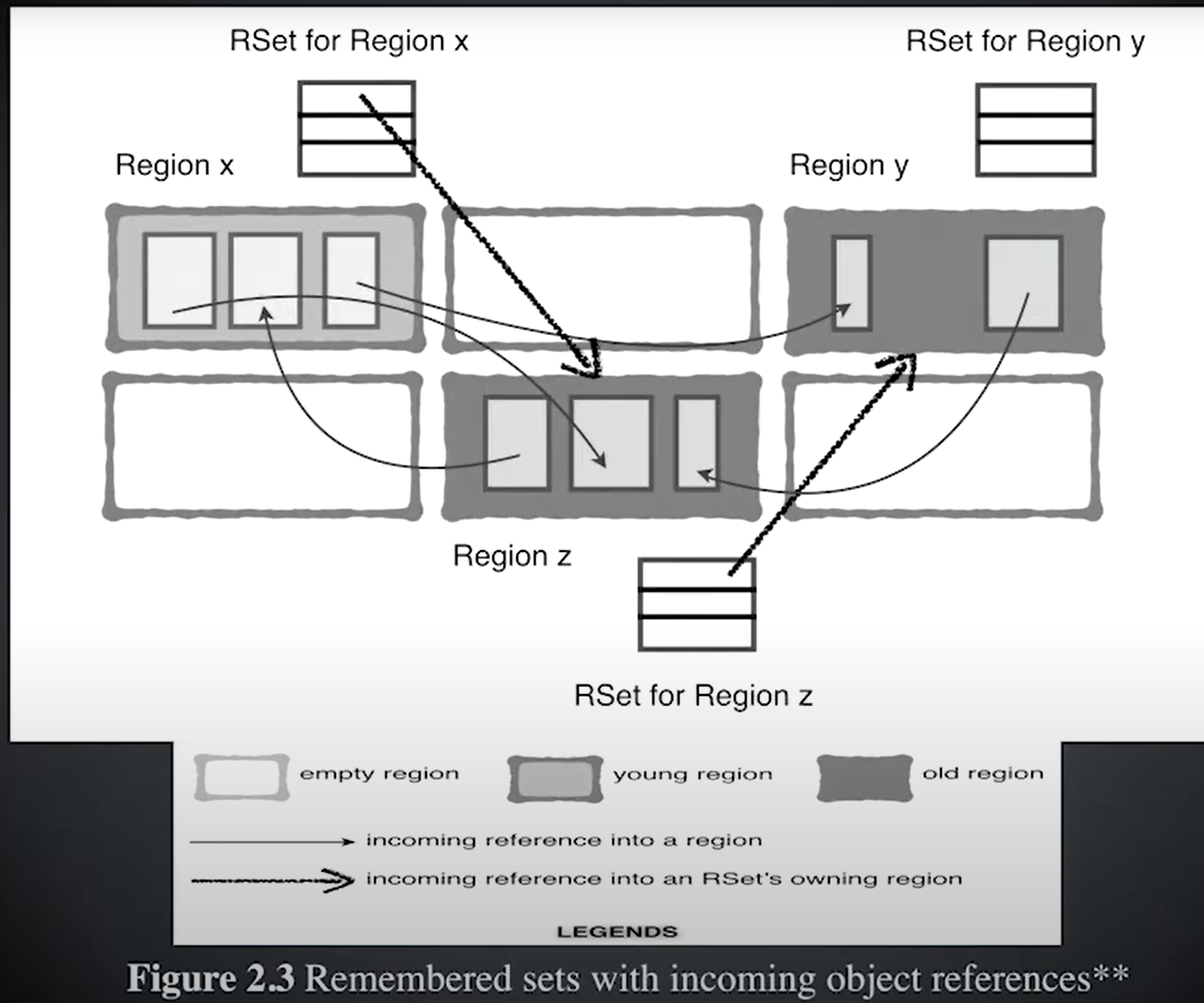
네, G1GC(가비지 컬렉터)에서 Remembered Set은 별도의 공간에 저장됩니다. Remembered Set은 G1GC의 중요한 데이터 구조 중 하나로, 가비지 수집 프로세스에서 효율성을 유지하는 데 필수적입니다.
Remembered Set이란?
Region 간 참조를 추적하는 데 사용되는 데이터 구조입니다.
Java 힙 영역에서 각 Region(메모리 블록)은 서로 참조를 할 수 있는데, Remembered Set은 특정 Region 외부에서 해당 Region으로의 참조를 기록하여 가비지 수집 시 이러한 참조를 빠르게 파악할 수 있도록 돕습니다.
예를 들어, 한 Region이 다른 Region을 참조하고 있는 경우, 이 정보를 Remembered Set에 저장해 둠으로써 GC가 전체 힙을 탐색하지 않아도 참조 관계를 효율적으로 확인할 수 있습니다.
저장 위치
각 Region에 대해 개별적으로 유지됩니다. 즉, 각 Region은 자신의 Remembered Set을 가지고 있으며, 이는 힙 외부의 메타데이터 공간에 저장됩니다.
Remembered Set은 일반적으로 Card Table과 같은 구조를 기반으로 구현되며, 특정 메모리 블록의 참조 여부를 관리합니다.
CSet 선정과 Remembered Set의 관계
Region 간 참조 추적
G1GC는 Region 단위로 힙을 관리하기 때문에, 특정 Region 내부의 객체들이 다른 Region에서 참조될 수 있습니다.
Remembered Set은 이러한 Region 간의 참조 관계를 관리하며, 특정 Region을 CSet에 포함할 때 해당 Region이 다른 Region으로부터 참조되고 있는지 확인하는 데 사용됩니다.
외부 참조 객체 처리
가비지 수집 과정에서, CSet에 포함된 Region 안에 있는 객체가 외부 Region으로부터 참조되고 있다면 그 객체는 살아 있는 것으로 간주되어야 합니다.
Remembered Set은 외부 참조를 추적하므로, CSet 선정 시 "외부로부터의 참조 상태"를 확인하고 필요한 객체를 보호(복사 또는 이동)합니다.
Mixed GC에서의 Old Region 수집
Mixed GC 단계에서 Old Region도 가비지 비율에 따라 CSet에 포함되는데, 이때도 Remembered Set이 중요합니다.
Old Region을 선택할 때, 외부 참조를 분석하여 해당 Region을 수집해도 괜찮은지(효율적인지) 판단할 수 있습니다.
Remembered Set이 CSet 선정에 기여하는 방식
객체 생존 여부 판별
CSet에 포함된 Region 내의 객체가 다른 Region에서 참조되고 있다면 그 객체는 생존 객체로 간주됩니다.
Remembered Set은 이러한 외부 참조를 확인하는 데 사용됩니다.
GC 효율성 향상
G1GC는 CSet을 효율적으로 구성하기 위해 Region의 가비지 비율을 계산합니다.
이때 Remembered Set을 사용하여 외부 참조가 많은 Region을 분석하고, 수집 비용이 높은 Region을 제외하거나 우선순위를 낮춥니다.
Region의 독립적인 수집 가능성 평가
G1GC는 Region을 독립적으로 수집하려 하기 때문에, 특정 Region이 외부 참조를 많이 받을수록 수집 비용이 올라갑니다.
Remembered Set은 이런 정보를 제공함으로써 어떤 Region을 CSet에 포함할지 결정하는 데 도움을 줍니다.
G1GC의 Region 선택 과정
Region의 메타데이터 활용
G1GC는 힙에 있는 각 Region에 대해 객체의 생존 상태와 가비지 비율을 나타내는 메타데이터를 유지합니다.
이 메타데이터에는 다음과 같은 정보가 포함됩니다:
Region의 총 용량
사용 중인 메모리 크기
Region 안의 살아 있는 객체 크기
가비지(쓰레기) 크기: 가비지 크기 = 총 크기 - 살아 있는 객체 크기
G1GC는 이러한 메타데이터를 바탕으로 Region 간 우선순위를 평가합니다. 모든 Region을 직접 조회하지 않고도, 가비지 비율이 높은 Region을 빠르게 식별할 수 있습니다.
Region 우선순위 계산
G1GC는 각 Region에 대해 가비지 효율 점수를 계산합니다.
효율 점수는 다음을 기반으로 합니다:
Region의 가비지 크기
가비지를 수집하는 데 드는 비용 (GC 비용)
수집 효율: (가비지 크기) / (수집 비용)
이렇게 계산된 점수를 기준으로, 가장 효율적인 Region부터 CSet에 포함시킵니다.
Remembered Set 활용
G1GC는 Remembered Set을 Region을 직접 선택하는 데 사용하기보다는, 선택된 Region의 외부 참조를 추적하는 데 사용합니다.
예를 들어, 특정 Region이 CSet에 포함되었을 때, Remembered Set을 조회하여:
해당 Region의 객체가 다른 Region에서 참조되고 있는지 확인합니다.
외부 참조된 객체는 생존 객체로 간주하고, GC에서 적절히 처리합니다.
Remembered Set은 객체의 생존 여부를 판별하고, GC 프로세스의 정확성을 보장하는 데 활용됩니다.
Young GC와 Mixed GC의 차이
Young GC: Eden Region 전체와 일부 Survivor Region이 기본적으로 CSet에 포함되며, 가비지 비율 계산은 주로 Young Generation에 국한됩니다.
Mixed GC: Young Generation과 함께 Old Generation의 Region도 포함됩니다. 이때, Old Region의 가비지 비율 계산과 우선순위 평가가 중요하며, 효율이 낮은 Region은 제외됩니다.