MySQL을 선택하는 이유
1. MySQL을 사용하는 Big Tech
2. Transaction
1. 작업의 완전성을 보장해주는 것
2. 작업셋을
1. 모두 완벽하게 처리하거나
2. 처리하지 못하면 원상태로 복구해주는 것3. MySQL 스토리지 엔진
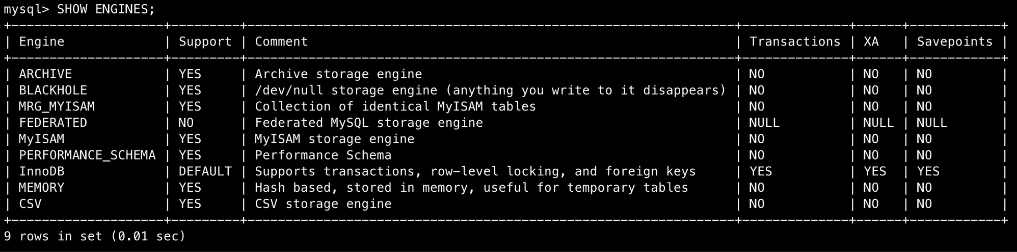
- 데이터 읽기/쓰기를 담당함
- 어떤 스토리지 엔진을 사용하느냐에 따라서 MySQL에 데이터를 읽고 쓰는 방법이 다름
1. 유명한(?) 스토리지 엔진들
1. MyISAM
2. MEMORY
3. INNODB
1. innoDB가 디폴트이다.
2. create table을 할 때 별도로 지정해주지 않는다면 디폴트 엔진이 사용됨
- 알아두면 좋은 명령어
- `SHOW CREATE TABLE`
- 테이블이 어떻게 생성되었는지를 보여줌
- ORM으로 생성하면 실제 SQL에서 테이블을 어떻게 생성하는지 알기 어렵기 때문에 도움됨
- 특히 회사에 갔을 때 기존에 생성된 테이블들이 어떤식으로 만들어졌는지 궁금하다면?!? 매우 유용함
- ORM으로 테이블을 생성했을 때 본인의 의도와 다르다면 추가 학습이 필요
- charset - 어떤 character(문자열)의 데이터를 저장할지
- collate - 저장된 데이터를 어떤식으로 비교, 정렬 할지
- 다시 transaction으로
- 간단한 테이블에서는 문제가 되지 않는다4. Database Lock
1. 동시성을 제어하기 위한 기능
2. 동시성은 무엇인가?
1. 하나의 데이터를 동시에 여러명이 조작할 수 없도록 방어함
2. 여러명이 같은 데이터를 요청할 경우, 한 시점에는 하나의 커넥션만 변경할 수 있도록
3. 동시성이 제어되지 않을 때 발생할 수 있는 문제
1. [데이터베이스 동시성을 보장받지 못하는 경우 발생하는 에러↗️](https://jasonkang14.github.io/database/what-are-database-concurrency-problems)
2. 과거에 작성한 블로그
4. MySQL에서 지원하는 lock의 종류
1. 글로벌 락
- 범위가 가장 넓음
- `SELECT`를 제외한 모든 쿼리들이 대기상태로 남음
- 서버 전체에 영향을 미침
- 작업 대상이나 테이블이 다르더라도 동일하게 영향
- `mysqldump` 등
- 데이터베이스를 전반적으로 업데이트 한다면 다른 작업들이 종료되어야 함
2. 테이블 락
- 특정 테이블에 대한 lock
- 해당 명령어를 사용할 일은 거의 없음
- 특별한 상황이 아니라면 다른 작업에 영향을 미치기 때문
- 테이블에 데이터를 변경하는 쿼리를 실행하면 자동으로 lock이 발생함
- 데이터 추가 시 lock 설정
- 데이터 변경
- 데이터 변경 commit 시 lock release
- InnoDB의 경우에는 DML 쿼리에서는 lock이 작동하지 않과 DDL의 경우에만 영향을 미침
- 스토리지 엔진의 구조 차이라는 정도만 알아두면 충분함
3. 네임드 락
- `GET_LOCK()`이라는 명령어로 임의의 문자열에 대해 잠금을 설정
- 자주 안씀
- 여러 클라이언트가 상호 동기화를 처리해야할 때 사용할 수 있음
- 많은 레코드에 대해 복잡한 요건으로 변경하는 트랜잭션에 유용함
4. 메타데이터 락
- 데이터베이스 객체의 이름이나 구조를 변경하는 경우에 획득
- 테이블 락처럼 별도의 명령어를 사용할 수는 없고, 테이블을 변경하는 등의 작업을 할 때 자동으로 가져왔다가 release함
5. 레코드락
- record / row에 lock을 거는 것5. Isolation Level(격리수준)
1. 여러 트랜잭션이 동시에 처리될 때 특정 트랜잭션이 다른 트랜잭션에서 변경하거나 조회하는 데이터를 볼 수 있게 허용할지 말지 결정함
2. 격리 수준의 종류
1. read uncommitted == dirty read
- 거의 사용되지 않음
- 트랜잭션의 변경 내용이 commit이나 rollback 여부에 상관 없이 보임
- 에러가 발생해서 rollback된 항목을 commit 전에 접근해서 에러가 발생할 수 있음
2. read committed
- 트랜젝션이 완료된 데이터만 다른 트랜잭션에서 조회 가능
- 커밋되기 전에는 언두로그에 있는 곳의 데이터를 읽어옴
- 언두로그 → 뭔가 잘못되면 돌려야돼서 임시로 저장하는 공간
- unrepeatable read
- 커밋 전에 불러오면 가져오는 값이 없고,
- 커밋 후에 불러오면 가져오는 값이 있음
- 문제 없어 보이지만 정합성에 어긋남
- 만약 핀테크라면?
- 트랜잭션 내의 SELECT와 트랜잭션 없이 실행되는 SELECT를 구분할 수 있어야 한다
- read committed에서는 문제가 안됨
- 그런데 repeatable read에서는 문제가 될수도 있음 .. 왜?
- 아래에서 설명예정
3. repeatable read
- 언두 영역에 백업된 이전 데이터를 이용해서 동일 트랜잭션에서는 같은 내용을 보여줄 수 있도록 함
- phantom read
- 언두 레코드에는 lock을 걸 수 없어서 같은 트랜잭션에서 조회 가능
- 왔다갔다 해서 phantom read(유령)이라고 함
4. serializable
- 동시성이 중요한 데이터베이스의 경우 거의 사용되지 않음
- read도 lock을 획득해야만 가능함
- read가 lock을 가지고 있기 때문에, write나 update, delete등을 실행할 수 없음
공부하자!