
데이터 중복을 줄이고, 무결성을 향상시킬 수 있는 정규화 ~!
Normalization
가장 큰 목표는 테이블 간 중복된 데이터를 허용하지 않는 것
중복된 데이터를 만들지 않으면, 무결성을 유지할 수 있고, DB 저장 용량 또한 효율적으로 관리할 수 있음
목적
- 데이터의 중복을 없애면서 불필요한 데이터를 최소화시킴
- 무결성을 지키고, 이상 현상을 방지함
- 테이블 구성을 논리적이고 직관적으로 할 수 있음
- 데이터베이스 구조 확장이 용이해짐
정규화에는 여러가지 단계가 있지만, 대체적으로 1~3단계 정규화까지의 과정을 거침
정규화 종류
- 제 1정규형(1NF, 원자성, 완전함수종속성 제거)
- 모든 속성은 반드시 하나의 값을 가져야 함
- 중복 인스턴스 X
- 제 2정규형(2NF, 부분함수종속성 제거)
- 엔터티의 일반속성은 주식별자 전체에 종속이어야 함
- 제 3정규형(3NF, 이행함수종속성 제거)
- 엔터티의 일반속성 간에는 서로 종속적이지 X
- 이행종속성X: A → B, B → C의 관계 제거
*함수적 종속성
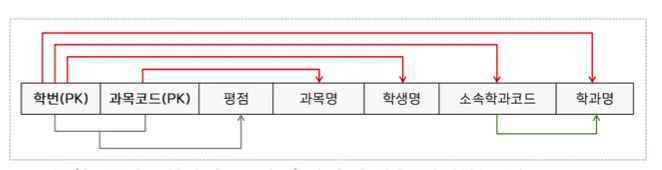
1. 부분함수종속: 하나의 PK가 혼자서 속성을 결정하는 것(학번 하나로 학생명과 소속학과코드, 학과명이 결정됨)
2. 이행함수종속: PK가 아닌 애가 속성을 결정하는 것(소속학과코드가 학과명을 결정함)
→ 정규화를 통해 부분함수종속과 이행함수종속을 없애면, 식별자 전체에 의해 결정되는 것만 남게 됨
→ 식별자가 아닌 속성이 결정자 역할을 하는 함수 종속을 제거하면 제 3정규형을 얻을 수 있음
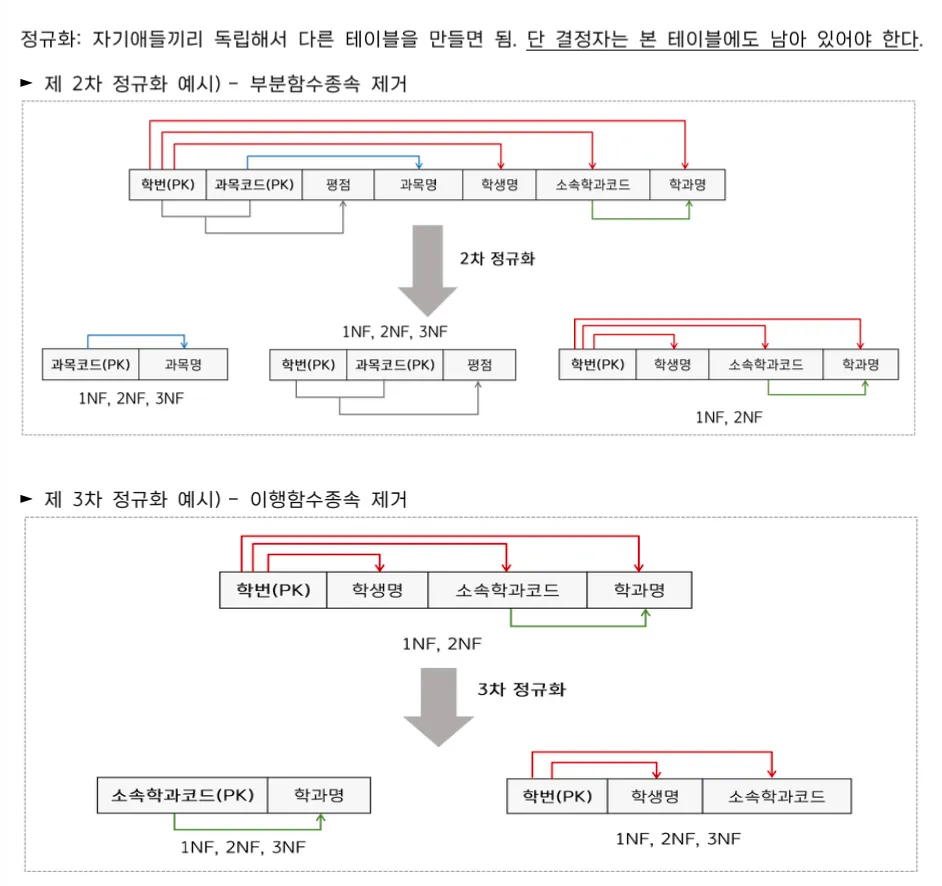
제 1정규화(1NF)
원자성
테이블 컬럼이 원자값(하나의 값)을 갖도록 테이블을 분리시키는 것
[만족해야 할 조건]
- 어떤 릴레이션에 속한 모든 도메인이 원자값만으로 되어 있어야 함
- 모든 속성에 반복되는 그룹이 나타나지 않음
- 기본키를 사용하여 관련 데이터의 각 집합을 고유하게 식별할 수 있어야 함
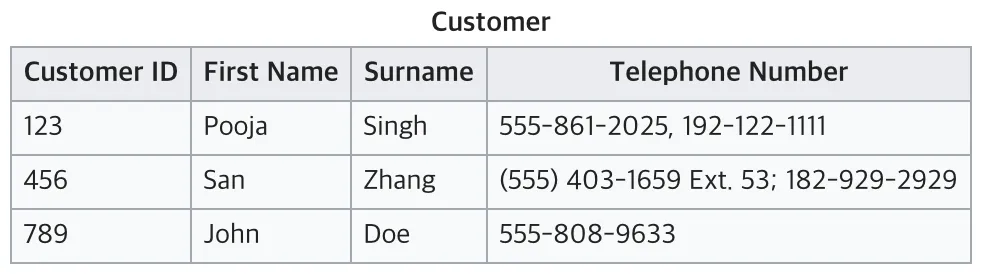
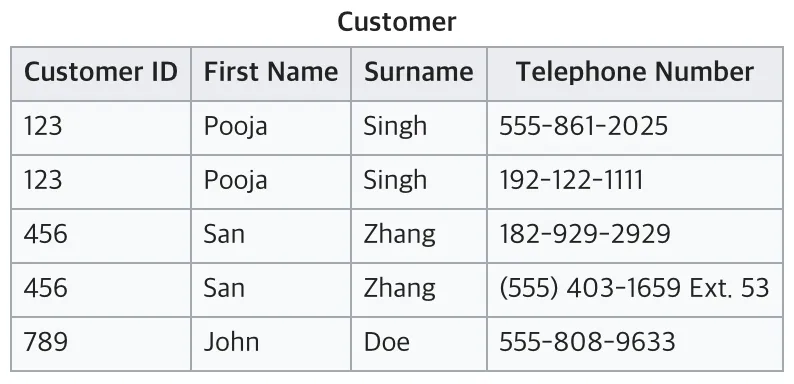
현재 테이블은 전화번호를 여러개 가지고 있어 원자값이 아님 ! 따라서 1NF에 맞추기 위해서는 아래와 같이 분리할 수 있음
제2정규화(2NF)
테이블의 모든 컬럼이 완전 함수적 종속을 만족해야 함
조금 쉽게 말하자면 !! 테이블에서 기본키가 복합키(키1, 키2)로 묶여 있을 때, 두 키 중 하나의 키만으로 다른 칼럼을 결정지을 수 있으면 안 됨 !!
→ 기본키의 부분집합 키가 결정자가 되어서 X
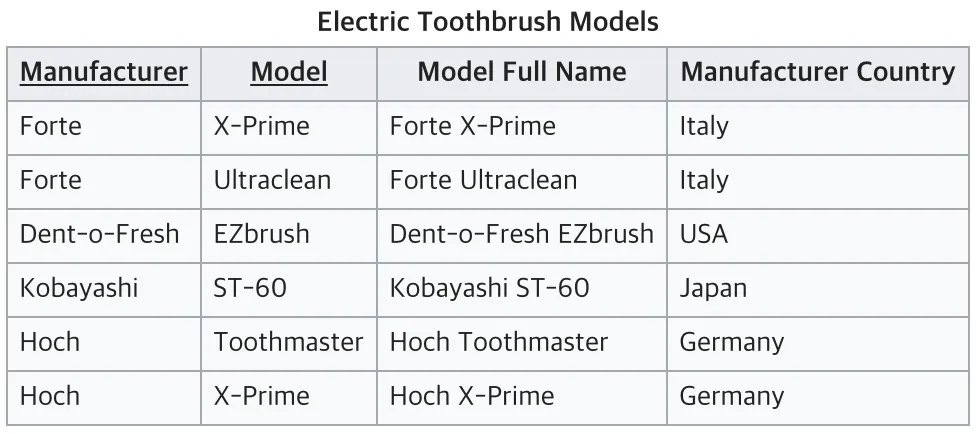
Manufacture과 Model이 키가 되어, Model Full Name을 알 수 있음
Manufacture Country는 Manufacturer로 인해 결정됨 (부분 함수 종속)
따라서, Model과 Manufacturer Country는 아무런 연관관계가 없는 상황이 됨 !!
⇒ 완전 함수적 종속을 충족시키지 못하고 있는 테이블임. 부분 함수 종속을 해결하기 위해 테이블을 아래와 같이 나눠서 2NF를 만족시킬 수 있음
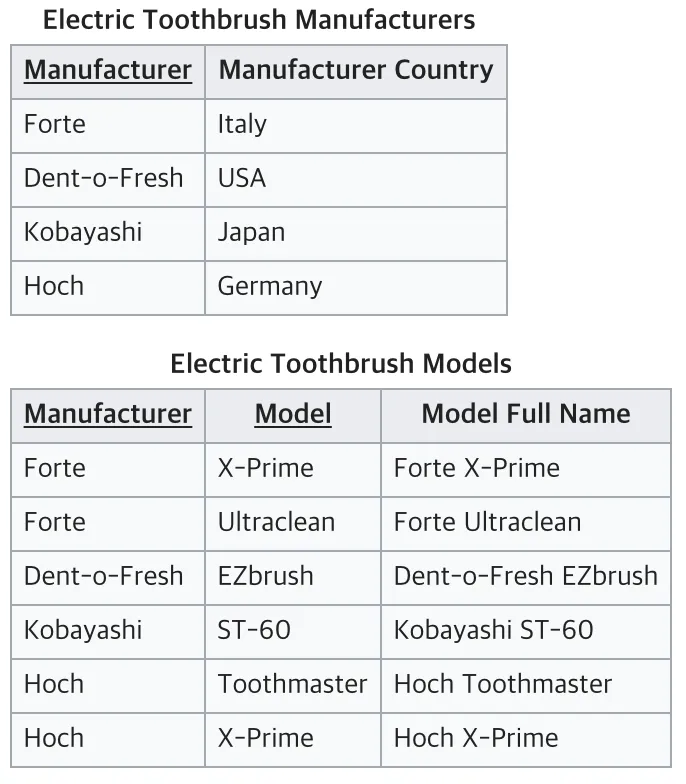
제 3정규화(3NF)
2NF가 진행된 테이블에서 이행적 종속을 없애기 위해 테이블을 분리하는 것
이행적 종속: A → B, B → C이면 A → C가 성립된다
아래 두 가지 조건 만족
- 릴레이션이 2NF에 만족
- 기본키가 아닌 속성들은 기본키에 의존
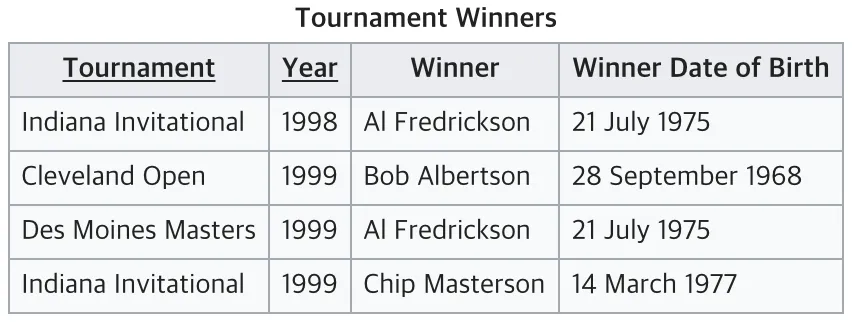
현재 테이블에서는 Tournament와 Year이 기본키임
Winner은 이 두 복합키를 통해 결정됨
하지만 Winner Date Of Birth는 기본키가 아닌 Winner에 의해 결정되고 있음
→ 따라서 이는 3NF를 위반하고 있으므로 아래와 같이 분리 실시 !
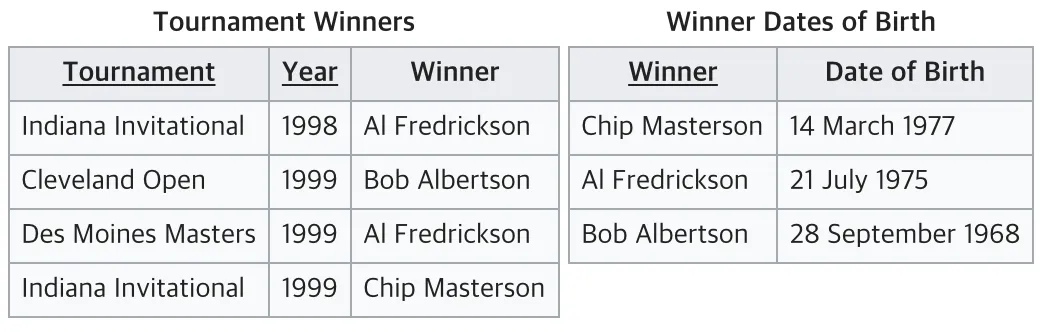
🔗 참고 링크
Jang 데이터베이스 정규화 개념 설명 및 예제

우와 ~~ !!