컬렉션 프레임워크와 해시맵 정리
컬렉션 프레임워크를 왜제공하는가
다수의 객체를 저장해둘공간, 필요할떄마다 사용하고 검색,삭제, 추가를 효율적으로 하고싶다.
배열을 사용할수있다.
그러나 배열은 크기가 고정되기때문에 자바에서는 java.util패키지에 컬렉션과 관련된 인터페이스, 클래스들을 포함해놓았다.
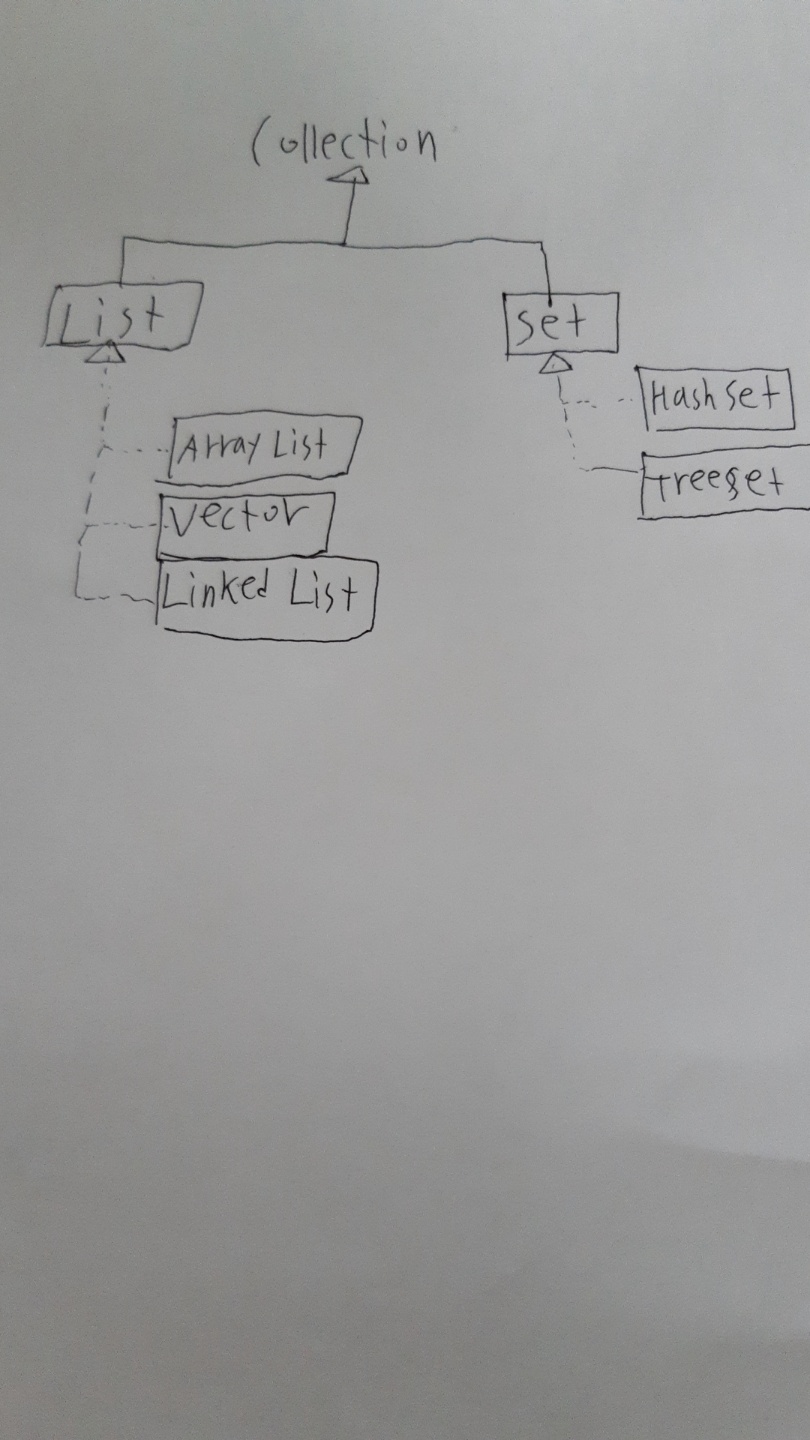
List(ArrayList, Vector, LinkedList)
중복을 허용하면서 저장순서가 유지되는 컬렉션을 구현하는데 사용한다.
- 객체를 인덱스로 관리한다
- 검색, 삭제할수있는 기능이존재한다
- 객체 자체를 저장하는것이 아니라 객체의 번지를 참조한다. ( 동일한 객체 저장이 가능하나, 같은 번지가 참조된다)
List<String> list = ...;
list.add("123");
list.add("456");
list.add("123");
list.get(0);
print(list.get(0) == list.get(2)) // true ArrayList
- List인터페이스의 구현클래스
- 기본생성자로 생성시, 10개의 초기용량이 생성된다.
vs배열
크기가 고정되냐 안되냐의 차이 배열은 크기가 고정되고, 사용중 변경이 불가능하다
저장공간이 부족하다면?

newCapacity만큼의 용량을 새로생성하고 elementData에 넘겨준다
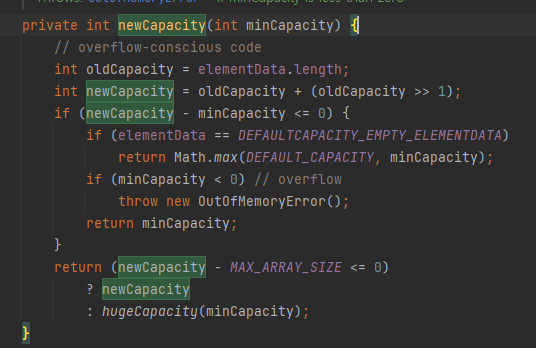
새용량 = 기존용량 + (기존용량>>1 => /2)
기존용량+ 기존용량/2 = 1.5기존용량
배열과 다르게 저장공간이 고정되어있지않은이유가
이로직이 실행되기때문이다.
새로운크기의 ArrayList를 생성하고 데이터를 복사하는일이 발생된다.
객체의 삽입,삭제시
삽입
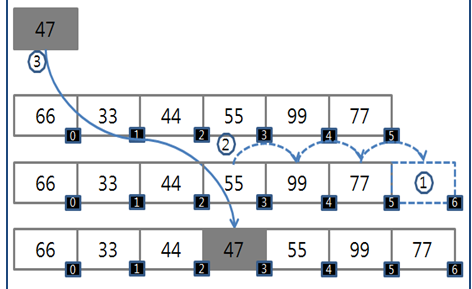
- 삽입될자료만큼 크기를 늘리는연산
- 삽입될자료를 기준으로 기존데이터들을 앞,뒤로 이동하는연산
- 해당위치에 자료입력
삭제

- 삭제될 자료가위치한 인덱스의 자료삭제
- 삭제한자료의 인덱스기준으로 자료들을 이동하는연산
- 마지막데이터를null로 변경
즉, 빈번한 객체의 삭제,삽입이 일어난다면 바람직하지않다.
인덱스 검색이나, 맨마지막에 객체를 추가하는경우 바람직하다.
LinkedList
객체의 삽입, 삭제가 발생해도 참조자만 바꾸면서 빠른시간안에 수행할수있다.
번번한 삭제,삽입이 일어난다면 LinkedList가 좋은성능을 발휘한다.
삭제시 :삭제 + 참조값변경? 하기때문에
순차적으로 추가/삭제하는경우 ArrayList가 더빠르다.
SET
중복을 허용하지않고 저장순서도 유지되지않는다. (구슬주머니)
인덱스의 개념이 없다
HashSet
객체를 저장하기전에 hashCode()메소드를 호출해서 해시코드를 얻어내고, 저장되어있는 객체들의 해시코드와 비교한다
동일한 해시코드가있다면 equals()메소드로 객체를비교해서 true가나오면 동일객체로 판단하고 중복저장을 하지않는다.
Map
키,값 쌍으로 저장, 키는 중복저장안됨
HashMap
HashSet 과 결이 같다.
hash collision 발생시
hashcode()메소드는 반환값이 int인데, int형은 32비트 정수자료형이고 객체의수가 2^32보다 많을수도 있으며, 32비트정수자료형으로는 완벽한 해시함수를 만들수가없다.
int index = X.hascode() % M;HashMap을비롯한 많은 해시함수들은 실제로 이런식으로 사용한다.
해시코드의 나머지값을 받아서 해시버킷 인덱스라는 값으로 사용하게되며, 같은객체가 아니더라도 동일한 해시코드를 가질수있게된다.
Open Addressing
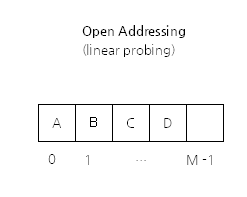
해시충돌이 발생하면 다른해시버킷에 해당자료를 삽입한다.
데이터개수가 적은경우 Separate chaining보다 성능이 좋다.
Separate chaining
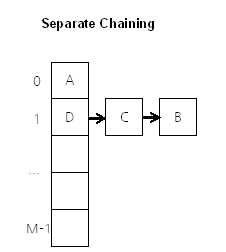
충돌시 해당버킷값을 첫부분으로 하는 LinkedList로 해결한다.
자바8에서는 쌓인 링크드리스트의 데이터가 키-값쌍으로 8개가모이면 LinkedList가 아닌 Red-black-Tree를 사용한다.
HashTable
HashMap과 동일한 내부구조, 동기화(synchronzied)된 메소드로 구성되어있다.
Vector, Hashtable, Stack 안쓰는이유
Vector,Hashtabel, Stack 동기화된 컬렉클래스
한번에 한스레드만 사용할수있게제어하고, thread-safe를 확보한다.

synchronized로 동기화 해논 Vector,Stack
10개의 요청이 들어오면 1개의요청만 실행하고 9개의요청은 기다리게되는, 병렬프로그램의 장점이 사라지게된다.
한스레드가 객체를 iterating하고있는경우 다른스레드가 동일한객체에 액세스하려고하면 CouncurrentModificationException이 발생한다.
fail-fast , fail-safe iterators
https://velog.io/@dudwls0505/fail-fast-fail-safe-iterators
ConcurrentHashMap 이 스레드동시성을 보장하는 방식
ConcurrentHashMap => thread-safe한 Hashmap
Map을 Segmant로 분할하여 thread-safe를 달성한다.
하나의스레드는 하나의 segmant의 잠금이 필요하다
-> 전체잠금은 컬렉션에 10개의 요소가 저장되어있을경우 1개를 처리할동안 전체 요소를 다른스레드가 처리하지못하게하는것
부분잠금은 처리하는요소가 포함된 부분만 잠금하고 나머지부분은 다른스레드가 변경할수있도록 하는개념이다.
