비트(Bit)
- 정의: 비트는 정보의 가장 작은 단위로 0또는 1의 값을 가진다
- 용도: 컴퓨터의 모든 데이터는 비트로 변환되어 처리된다. 여러 비트가 모여 복잡한 데이터를 형성한다
바이트(Byte)
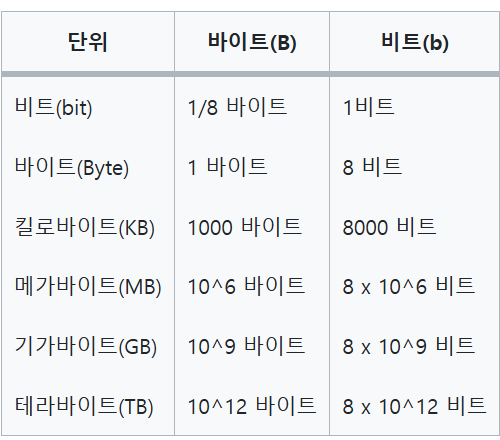
- 정의: 바이트는 보통 8개의 비트로 구성된 데이터 단위이다. 8bit=1Byte
예) 문자 'A'는 ASCII 코드로 8비트, 즉 1바이트로 표현 - 용도: 바이트는 컴퓨터 메모리에서 데이터 크기를 측정하는 기본 단위로 사용된다. 1KB는 1024 바이트를 의미한다(2^10)
문자 인코딩(Text Encoding)
- 정의: 문자 인코딩은 문자를 비트로 변환하는 방법. 서로 다른 인코딩 방식이 있으며, 각기 다른 문자 집합을 지원한다
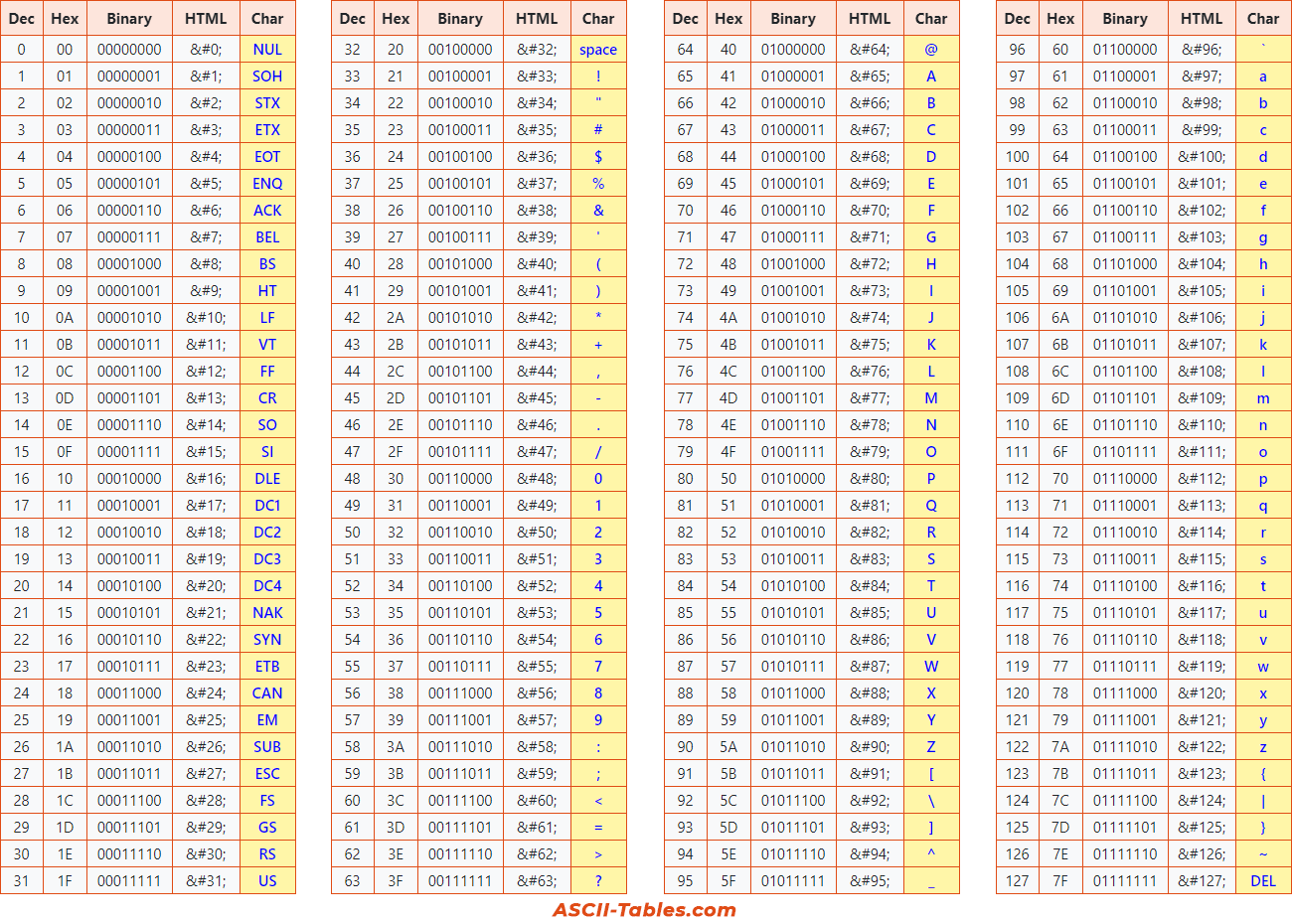
ASCII: 기본 127개의 문자를 지원하는 고전적인 인코딩 방식
정의
컴퓨터를 다루는 세상에서 숫자를 알파벳 문자에 대응시키는 표준을 채택
- 컴퓨터는 문자를 비롯한 다양한 형태의 정보를 저장한다. 하지만 컴퓨터는 0과 1로된 데이터만 저장할 수 있기 때문에, 0과 1만을 이용하여 문자를 나타내야 함
- ASCII 코드는 문자를 컴퓨터가 이해할 수 있는 이진 데이터(0,1)로 변환하는 표준 방법이다.
한계
- 우리가 사용할 수 있는 문자들을 ASCII 코드에 모두 담아낼 수 없음
- 이 때문에 훨씬 더 많은 문자들을 포함할 수 있는 유니코드가 생기게 됐다
- 유니코드는 100만개 이상의 문자들을 나타낼 수 있는 문자 인코딩 표준이다.
유니코드의 첫 128개 문자는 ASCII의 128개의 문자와 동일하여, 서로 호환 가능하다
유니코드(UniCode)
정의
전 세계 모든 문자를 컴퓨터에서 일관되게 표현하고 다룰 수 있도록 설계된 산업 표준
- 유니코드는 ASCII를 확장한 형태
- 유니코드의 목적은 현존하는 문자 인코딩 방법을 모두 유니코드로 교체하는 것
부호화(Encoding)
- 인코딩이란 어떤 문자나 기호를 컴퓨터가 이용할 수 있는 신호로 만드는 것
- 신호를 입력하는 인코딩과 문자를 해독하는 디코딩을 위해서는 미리 정해진 기준을 바탕으로 입력과 해독이 처리되어야 한다.
- 인코딩과 디코딩의 기준을 문자열 세트 또는 문자셋(charset)이라고 한다.
- 문자셋의 국제 표준: 유니코드
인코딩 방식
UTF-8
- 고정 길이와 가변 길이 인코딩을 사용하는 방식, ASCII와 호환되며, 최대 4바이트로 하나의 문자를 인코딩
특징
- 1바이트로 ASCII 문자(0-127)를 표현
- 2바이트, 3바이트, 4바이트를 사용하여 다양한 국제 문자를 인코딩
- 각 문자에 따라 필요한 만큼의 바이트를 사용하기 때문에, 파일 크기를 작게 유지 가능
- 유연하고 메모리 효율적이며, ASCII와 완벽하게 호환되어 웹 환경에서 가장 널리 사용됨
UTF-16
- 대부분의 문자를 2바이트(16비트)로 인코딩하며, 필요한 경우 4바이트(32비트)를 사용하여 표현
특징:
- 윈도우와 자바의 기본 문자 인코딩으로 사용된다.
- 메모리를 더 많이 사용할 수 있지만, 특정 문자에 대해 더 빨리 처리할 수 있다.
- 많은 국제 문자를 효율적으로 처리하며, 특정 환경(자바, 윈도우)에서 유용
UTF-32
- 모든 문자를 고정적으로 4바이트(32비트)로 인코딩
특징
- 모든 문자가 동일한 크기로 표현되기 때문에, 각 문자에 대한 접근 용이
- 단, 모든 문자를 4바이트로 표현하기 때문에, 매우 많은 메모리 소모
- 내부 처리나 데이터베이스에서 사용되며, 문자를 자주 읽고 쓸 때 유리
결론
비트와 바이트는 데이터의 기본 단위이며, 텍스트 인코딩은 이 데이터를 효과적으로 처리하기 위해 문자를 비트로 변환하는 방식이다. 텍스트를 다양한 형식으로 저장하고 전송하기 위해 적절한 인코딩 방식을 선택하는 것이 중요.

주니어개발자(?)