
JPA 연관관계
One-to-One
정의
- 두 엔티티가 각각 하나씩의 서로에 대한 참조를 가지는 경우
예시
User
@Entity
public class User {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long userId; // 사용자의 고유 ID
private String username; // 사용자 이름
@OneToOne(mappedBy = "user") // 필드가 반대측 프로필 클래스의 'user' 필드를 참조
private Profile profile; // 사용자와 연결된 프로필
}Profile
@Entity
public class Profile {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long profileId; // 프로필의 고유 ID
private String bio; // 프로필의 정보
@OneToOne // 각각의 프로필은 하나의 사용자에 연결됨
@JoinColumn(name = "user_id") // 외래 키를 설정하여 사용자와 연결
private User user; // 이 프로필과 연결된 사용자
}- User 클래스
- @OneToOne(mappedBy = "user"): 이 필드가 Profile 클래스의 user 필드를 통해 매핑되었음을 나타낸다.
- Profile 클래스
- @JoinColumn(name = "user_id"): 외래 키를 설정하여 프로필과 사용자를 연결.
One-to-Many
정의
- 한 엔티티가 다수의 다른 엔티티와 연관을 가지는 경우
- 예를들어, 하나의 수업에 여러명의 학생이 수강중인 경우
- 수업 클래스에 @One-to-Many 어노테이션을 사용하여 정의하고 반대쪽인 학생 클래스에도 @Many-to-One을 사용해야 한다.
예시
Course
@Entity
public class Course {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long courseId; // 수업의 고유 ID
private String title; // 수업 제목
@OneToMany(mappedBy = "course") // 반대측 학생 클래스의 'course' 필드로 매핑
private List<Student> students; // 이 수업을 수강하는 학생 목록
}Student
@Entity
public class Student {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long studentId; // 학생의 고유 ID
private String name; // 학생 이름
@ManyToOne // 여러 학생이 하나의 수업에 속할 수 있는 관계
@JoinColumn(name = "course_id") // 외래 키를 설정하여 수업과 연결
private Course course; // 학생이 속한 수업
}- Course
- @OneToMany(mappedBy = "course"): course 필드를 통해 매핑
- Student
- @JoinColumn(name = "course_id"): course_id를 외래키로 등록
Many-to-One
- 여러 엔티티가 하나의 엔티티에 연관될 때 사용한다.
- 예를들어, 여러 주문(Order)이 하나의 고객(Customer)에 속할 수 있다.
- @Many-to-One으로 어노테이션을 사용하여 표현한다.
Many-to-Many
- 여러 엔티티가 다른 여러 엔티티와 연관될 수 있는 경우
- 예를들어 여러 학생(Student)이 여러 수업(Course)을 수강할 수 있는 경우
- @ManyToMany 애노테이션으로 정의하며, 종종 중간 테이블을 사용하여 구현한다.
mappedBy, Join
연관관계는 단방향이거나 양방향일 수 있으며 동작을 명확히 하기 위해 mappedBy나 조인 테이블 설정을 통해 관계를 구체적으로 설정할 수 있다.
mappedBy
양방향 관계에서 외래 키가 위치하는 N측의 필드를 지정하는 역할
@OneToMany(mappedBy = "customer")
private List<Order> orders;예를 들어, Customer와 Order의 관계에서 Order 클래스의 customer 필드가 이 관계의 주체라는 것을 의미한다.
즉, Customer 클래스는 여러 Order를 참조할 수 있지만, customer_id 필드를 통해서만 참조 가능함
Join 테이블
join 테이블은 다대다 관계를 구현할 때 중간 테이블을 생성하여 관련된 투 테이블의 관계를 관리하는 방법이다.
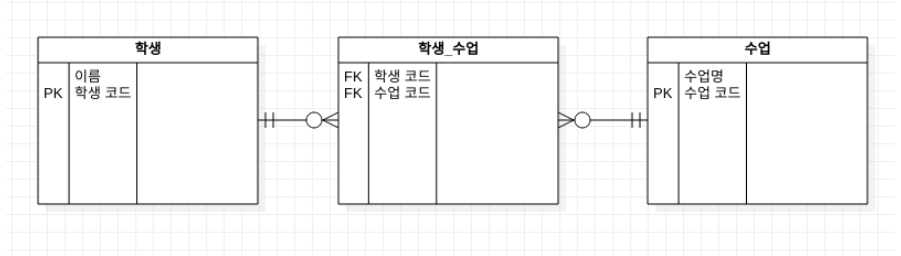
Student
@Entity
public class Student {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long studentId;
private String name;
@ManyToMany
@JoinTable(
name = "student_course",
joinColumns = @JoinColumn(name = "student_id"), // 학생 외래 키
inverseJoinColumns = @JoinColumn(name = "course_id") // 수업 외래 키
)
private List<Course> courses;
}Course
@Entity
public class Course {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long courseId;
private String title;
@ManyToMany(mappedBy = "courses")
private List<Student> students;
}- 학생과 수업간의 다대다 관계를 관리하기 위한 조인 테이블은, 하나의 수업도 여러 학생이 수강하며/ 한명의 학생이 여러 수업을 수강할 수 있도록 연결해준다.
- mappedBy 를 사용하여 양방향 접근이 가능해짐
최적화
1. Fetch 유형 설정
EAGER
- 연관된 객체를 즉시 로드
- 주 엔티티를 조회할 때, 관련된 모든 연관 엔티티를 가져온다.
- 연관된 데이터가 많을 경우 성능 저하가 발생할 가능성
- 연관된 객체가 항상 필요할 때 유용
@ManyToOne(fetch = FetchType.EAGER) // 즉시 로드
@JoinColumn(name = "department_id")
LAZY
- 연관된 객체를 지연 로딩(필요할 때만 로드) 한다.
- 관련 객체는 쿼리하지 않는다.
- 연관된 객체가 필요하지 않거나, 데이터 양이 방대하여 선능에 영향을 미칠 경우 유용하다.
@OneToMany(mappedBy = "department", fetch = FetchType.LAZY) // 지연 로드
private List<Employee> employees;선택
일반적으로 LAZY 로딩이 성능 측면에서 유리하지만 필요한 경우에 따라 EAGER 로딩을 고려할 수 있다.
2. N+1 문제 해결
정의
JPA나 하이버네이트를 사용할 때 발생하는 성능 문제로, 주로 LAZY 로딩에서 발생
시나리오
- 예를들어 하나의 부서 엔티티에 여러 직원 엔티티가 연결된 경우
- 부서 리스트를 조회할 때, 각 부서에 속한 직원들을 조회하기 위해 JPA가 추가쿼리를 실행
- 각각의 부서에 연관된 직원을 가져오는 N개의 쿼리 + 모든 부서를 가져온 1개의 쿼리 즉, N+1개의 쿼리가 실행된다.
문제 해결
1. JOIN FETCH 사용
데이터를 여러 부분으로 나누어 필요한 부분만 조인하여 전체 성능을 향상
SELECT d FROM Department d JOIN FETCH d.employees단일 쿼리로 필요한 모든 데이터를 가져온다
2. Entity Graph 사용
필요한 연관관계를 미리 정의하고 로드
@EntityGraph(attributePaths = {"employees"})
List<Department> findAll();Batch Size 설정
한 번에 데이터 세트를 얼마나 로드할지 설정하여 성능개선
@OneToMany(mappedBy = "department")
@BatchSize(size = 10) // 한 번에 10개씩 로드
private List<Employee> employees;3. Batch Size 설정
위에서 설명함
4. Projections 사용
정의
필요한 데이터만 선택적으로 가져오는 방법
전체 엔티리를 불러오는 대신 DTO(Data Transfer Object)를 사용하여 필요한 필드만 로드한다.
public class CourseDTO {
private String title;
public CourseDTO(String title) {
this.title = title;
}
}
쿼리
SELECT new CourseDTO(c.title) FROM Course c5. Cascade 설정
정의
연관관계에서 부모 엔티티의 상태변화를 자식 엔티티에 전이되도록 설정
문제
- 무한루프: 양방향 연관관계가 있을 경우 부모 자식간에 서로를 참조하면서 무한이 반복연산이 발생 가능성
- 불필요한 데이터 삭제: 부모 엔티티 삭제 시 관련된 모든 자식 엔티티도 삭제되는데, 이때 원하지 않는 데이터 손실이 발생 할 가능성
- 데이터 무결성 오류: 부모 엔티티 삭제 후 자식 엔티티에 대한 캐스캐이드가 잘못 작동하여 DB에 남는 경우 참조무결성을 위배할 수 있다.
해결
- 정확한 캐스캐이드 사용
- 양방향 관계 주의
그럼 왜 씀?
- 코드 간소화
- 데이터 무결성 유지
- 유지 보수 용이
- 일관된 데이터 상태 관리
- 트랜잭션 관리 단순화: 연관된 모든 엔티티가 자동으로 동일한 트랜잭션 내에서 처리되므로 간편함 즉, 커밋과 롤백을 한번에 할 수 있음
결론
정답은 없고, 적재적소에 최적의 방식을 채택하여 성능향상을 하는것이 중요

주니어개발자(?)
안녕하세요! 개발자 준비하시는 분이나 현업에 종사하고 계신 분들만 할 수 있는 시급 25달러~51달러 LLM 평가 부업 공유합니다~ 제 블로그에 자세하게 써놓았으니 관심있으시면 한 번 읽어봐주세요 :)