
SQL 응용 - 데이터베이스 기본, 응용 SQL 작성하기, 절차형 SQL 활용하기, 데이터 조작 프로시저 최적화
1. 데이터베이스 기본
트랜잭션
트랜잭션
- 트랜잭션의 개념
인가받지 않은 사용자로부터 데이터를 보호하기 위해 DBMS가 가져야 하는 특성이자, 데이터베이스 시스템에서 하나의 논리적 기능을 정상적으로 수행하기 위한 작업의 기본 단위
트랜잭션 특성
- 원자성(Atomicity): 분해가 불가능한 작업의 최소 단위
- 일관성(Consistency): 트랜잭션이 성공 후 항상 일관된 데이터베이스 상태를 보존해야하는 특성
- 격리성(Isolation): 트랜잭션 실행 중 생성하는 연산의 중간 결과를 다른 트랜잭션이 접근 불가능한 특성
- 영속성(Durability): 성공이 완료된 트랜잭션의 결과는 영속적으로 데이터베이스에 저장하는 특성
ACID
트랜잭션의 상태
- 활동 상태: 초기 상태, 트랜잭션이 실행중 일때 가지는 상태
- 부분 완료 상태: 마지막 명령문이 실행된 후에 가지는 상태
- 완료 상태: 트랜잭션이 성공적으로 완료된 후에 가지는 상태
- 실패 상태: 정상적인 실행이 더 이상 진행될 수 없을 때 가지는 상태
- 철회 상태: 트랜잭션이 취소되고 데이터베이스가 트랜잭션 시작 전 상태로 환원된 상태
활부완실철
트랜잭션 제어
- 커밋: 트랜잭션 확정
- 롤백: 트랜잭션 취소
- 체크포인트: 저장 시기 설정
커롤체
병행 제어 기법의 종류
- 로킹: 트랜잭션이 접근하려는 데이터를 다른 트랜잭션이 접근하지 못하도록 잠그는 병행제어 기법
- 낙관적 병행 제어: 트랜잭션 수행 동안 어떠한 검사를 하지않고, 트랜잭션이 종료된 이후에 일괄적으로 검사하는 방식
- 타임스탬프 순서: 비직렬 트랜잭션을 타임스탬프 순서에 따라 직렬화 시키는 방법(타임스탬프를 미리 정해두어 부여된 시간 순서대로 데이터에 접근, 교착상태 발생x)
- 다중버전 동시성 제어: 한 데이터에 대해 여러 버전의 값을 유지하며 관리하는 방식. 여러 버전의 타임스탬프를 비교하여 직렬 가능성이 보장되는 타임스탬프 선택
로 낙타다
회복 기법의 종류
- 로그 기반 회복 기법
- 지연 갱신 회복 기법: 트랜잭션이 완료되기 전까지 데이터베이스에 기록하지 않는 기법
- 즉각 갱신 회복 기법: 트랜잭션 수행 중 갱신 결과를 바로 DB에 반영하는 기법
- 체크포인트 회복 기법: 장애 발생시 검사지점 이후에 처리된 트랜잭션만 장애 발생 이전의 상태로 복원
- 그림자 페이징 회복기법: 데이터베이스 트랜잭션 수행 시 복제본을 생성하여 복구
회로체크
DDL
DDL 개념
데이터를 정의하는 언어
DDL 대상
- 도메인: 하나의 속성이 가질 수 있는 원자값들의 집합
- 스키마: 데이터베이스의 구조, 제약조건 등을 담고 있는 기본적인 구조
- 외부 스키마: 사용자나 개발자의 관점에서 필요로 하는 DB의 논리적 구조 / 사용자 뷰
- 개념 스키마: DB의 전체적인 논리 구조 / 전체적인 뷰
- 내부 스키마: 물리적 저장장치의 관점에서 보는 DB의 구조 / 레코드 형식 정의
- 테이블: 데이터의 저장 공간
- 뷰: 하나 이상의 물리 테이블에서 유도되는 가상 테이블
- 인덱스: 검색을 빠르게 하기 위한 데이터 구조
테이블 용어
- 튜플, 행, 레코드, 릴레이션, 카디널리티: 가로
- 애트리뷰트, 열, 디그리, 차수: 세로
도메인: 애트리뷰트가 취할 수 있는 같은 타입의 원자값들의 집합
인덱스의 종류
- 순서 인덱스: 데이터가 정렬된 순서로 생성되는 인덱스
- 해시 인덱스: 해시 함수에 의해 직접 데이터에 키 값으로 접근하는 인덱스
- 비트맵 인덱스: 컬럼에 적은 개수 값이 저장될 경우 선택하는 인덱스
- 함수기반 인덱스: 수식이나 함수를 적용하여 만든 인덱스
- 단일 인덱스: 하나의 컬럼으로만 구성한 인덱스
- 결합 인덱스: 두개 이상의 컬럼으로만 구성한 인덱스
- 클러스터드 인덱스: 기본 키 기준으로 레코드를 묶어서 저장하는 인덱스
DDL 명령어
CREATE
ALTER
DROP
TURNCATE
CADT
DML
DML의 개념
데이터 조작어
DML 명령어
SELECT
INSERT
UPDATE
DELETE
SIUD
WHERE 절
- 패턴 : LIKE
- %: 0개 이상의 문자열과 일치
SELECT * FROM employees WHERE name LIKE "%A";
// A로 시작하는 문자열- []: 1개 이상의 문자와 일치
SELECT * FROM product WHERE code LIKE '[A-C]123';
// 코드가 A123, B123, C123 처럼 A,B,C중 하나로 시작하는 제품들 검색- [^]: 1개의 문자와 불일치
SELECT * FROM users WHERE email LIKE '%[^g]mail.com';
// gmail은 안됨, amail.com bmail.com 등 g만 아니면 ㄱㅊ- _: 특정 위치의 1개의 문자와 일치
SELECT * FROM accounts WHERE number LIKE '123_56;
// 123으로 시작하고 56으로 끝나는 문자열 다 검색(123@56,123a56, 123456, 등등)Join
테이블 구조
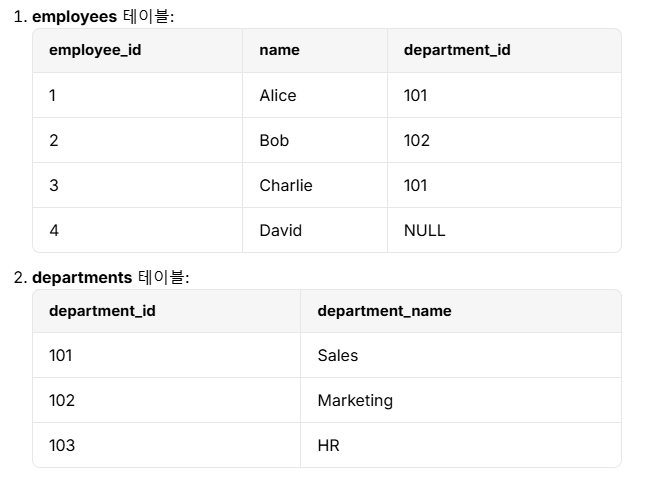
내부 조인
SELECT e.name, e.department_id, d.department_name
FROM employees e
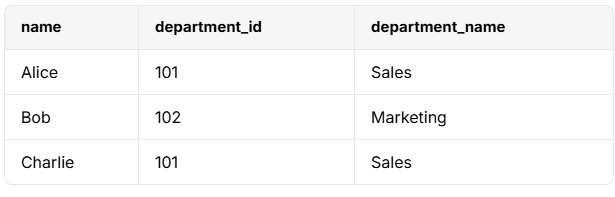
INNER JOIN departments d ON e.department_id = d.department_id;- 결과
LEFT 조인
SELECT e.name, e.department_id, d.department_name
FROM employees e
LEFT JOIN departments d ON e.department_id = d.department_id;- 결과
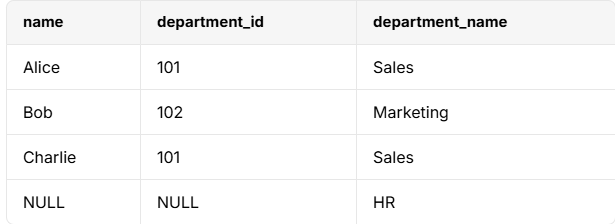
RIGHT 조인
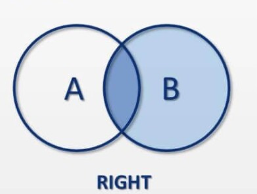
SELECT e.name, e.department_id, d.department_name
FROM employees e
RIGHT JOIN departments d ON e.department_id = d.department_id;- 결과
집합 연산자
- UNION: 중복 행이 제거된 쿼리 결과를 갖는 집합 연산자
SELECT name FROM employees
UNION
SELECT name FROM contractors;- UNION ALL: 중복 행이 제거되지 않은 결과를 갖는 집합 연산자
SELECT name FROM employees
UNION ALL
SELECT name FROM contractors;- INTERSECT: 두 쿼리 결과에 공통적으로 존재하는 결과를 갖는 집합 연산자(교집합)
SELECT name FROM employees
INTERSECT
SELECT name FROM contractors;- MINUS: 첫 쿼리에만 있고 두 번째 쿼리에는 없는 결과를 반환하는 집합 연산자
SELECT name FROM employees
MINUS
SELECT name FROM contractors;DCL
DCL의 개념
데이터 제어어
DCL 명령어
- GRANT: 권한 부여
GRANT 권한 목록 ON 테이블 TO 사용자;
GRANT UPDATE ON 학생 TO 장길산;
// 장길산 사용자에게 학생 테이블에 대한 업데이트 권한 부여- REVOKE: 권한 회수
REVOKE 권한 목록 ON 테이블 FROM 사용자;
REVOKE UPDATE ON 학생 FROM 장길산;
// 장길산 사용자에게서 학생 테이블에 대한 업데이트 권한 회수2. 응용 SQL 작성하기
집계성 SQL 작성
GROUP BY
데이터 집계를 수행할 때 사용하는 명령어로, 특정 컬럼을 기준으로 데이터 그룹을 만들고 집계함수를 사용하여 각 그룹에 대한 요약 정보를 생성
SELECT 컬럼1, 집계함수(컬럼2)
FROM 테이블명
WHERE 조건
GROUP BY 컬럼1;- 예시
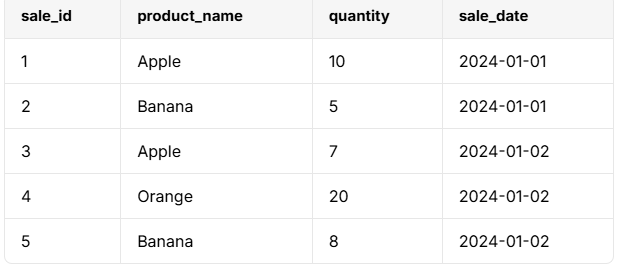
SELECT product_name, SUM(quantity) AS total_quantity
FROM sales
GROUP BY product_name;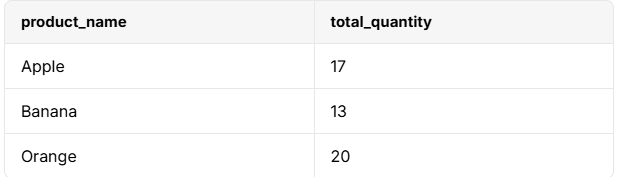
GROUP BY product_name; 구문에 의해 동일한 제품 이름이 그룹화되고, 집계 함수sum(quantity)이 총 판매 수량(total_quantity)을 계산한다.
- HAVING 절
SELECT product_name, SUM(quantity) AS total_quantity
FROM sales
GROUP BY product_name
HAVING SUM(quantity) > 15; -- 판매 수량이 10개 초과인 제품만 표시
HAVING절은 GROUP BY의 집계 결과에 조건을 추가하여 필터링한다.
데이터 분석 함수의 개념
총합, 평균 등의 데이터 분석을 위해 복수 행 기준의 데이터를 모아서 처리하는 것을 목적으로 하는 다중 행 함수
그룹 함수
- ROLLUP: 다차원 집계를 생성하는데 사용된다.
SELECT department_id, employee_id, COUNT(*)
FROM employees
GROUP BY ROLLUP(department_id, employee_id);ROLLUP 을 사용함으로써 부서와 직원의 총합계도 표시
- CUBE: 결합 가능한 모든 값에 대해 다차원 집계를 생성하는 그룹 함수
- GROUP SETS 함수: 집계 대상 컬럼들에 대한 개별 집계를 구하고 순서와 무관한 결과 도출 가능
vs CUBE: CUBE는 모든 조합, GROUPING SETS는 필요한 조합만 명시
윈도 함수
- 윈도 함수 개념
데이터베이스를 사용한 온라인 분석 처리 용도로 사용하기 위해 표준 SQL에 추가된 함수
OLAP 함수라고 부른다 - 윈도 함수 분류
- 순위함수
- 행 순서 함수
- 그룹내 비율 함수
순행비
순위 함수
- RANK: 동일 순위의 레코드 존재 시 후순위는 넘어감
- 1 2 2 4
- DENSE_RANK: 동일 순위 시 후순위를 넘어가지 않음
- 1 2 2 3
- ROW_NUMBER: 동일 순위가 존재해도 무관하게 연속 번호 부여
- 1 2 3 4
절차형 SQL 활용하기
절차형 SQL
절차형 SQL 종류
- 프로시저: 일련의 쿼리들을 마치 하나의 함수처럼 실행하기 위한 쿼리의 집합
- 사용자 정의함수: 일련의 SQL을 수행하고 수행 결과를 단일 값으로 반환가능한 SQL
- 트리거: DB에서 이벤트가 발생할 때마다 관련 작업이 자동으로 수행되는 SQL
프로시저
구성
선언부(DECLARE)
시작/종료부(BEGIN/END)
제어부(CONTROL)
SQL
예외부(EXCEPTION)
실행부(TRANSACTION)
DBC SET
=DB컨닝세트
사용자 정의함수
사용자 정의함수 구성
선언부(DECLARE)
시작/종료부(BEGIN/END)
제어부(CONTROL)
SQL
예외부(EXCEPTION)
반환부(RETURN)
DBC SER
=DB컨설팅
트리거
트리거 구성
선언부
이벤트부
시작/종료부
제어부
SQL
예외부
DEBCSE
4. 데이터 조작 프로시저 최적화
데이터 조작 프로시저 성능개선
옵티마이저 통계 확인
- 옵티마이저 개념
옵티마이저는 SQL을 가장 빠르고 효율적으로 수행할 최적의 처리 경로를 생성해주는 DBMS의 핵심 내부 엔진 - 옵티마이저 유형
규칙기반 옵티마이저(RBO) + 비용기반 옵티마이저(CBO) - 힌트 사용
옵티마이저가 항상 최선의 실행 계획을 수립할 수 없어 명시적인 힌트를 제공한다.
정리
트랜잭션
- ACID(원자성,일관성, 고립성, 영속성)
- 상태(활부완실철)
- 활동
- 부분완료
- 완료
- 실패
- 철회
- 제어(커롤체)
- 커밋
- 롤백
- 체크포인트
- 병행제어(로낙타다)
- 로킹
- 낙관적 병행제어
- 타임스탬프 순서
- 다중버전 동시성 제어
- 회복기법(회로체크)
- 로그기반(지연갱신,즉시갱신)
- 체크포인트
- 그림자 페이징
DDL(데이터 정의)
- CREATE ALTER DROP TURNCATE
DML(데이터 조작)
- SELCET INSERT UPDATE DELETE
- JOIN
- WHERE 절
- UNION, UNION ALL, INTERSECT, MINUS
DCL(데이터 제어)
- GRANT ON TO, REVOKE ON FROM
집계 SQL
- GROUP BY
- HAVING
윈도함수
- RANK, DENSE_RANK, ROW_NUMBER
절차형 SQL
- 프로시저(DBC SET)
- 선언, 시작/종료, 제어, SQL, 예외, 실행
- 사용자 정의함수(DBC SER)
- 선언, 시작/종료, 제어, SQL, 예외, 반환
- 트리거(DBC SEE)
- 선언, 시작/종료, 제어, SQL, 예외, 이벤트

주니어개발자(?)