
스마트농업 AI 경진대회
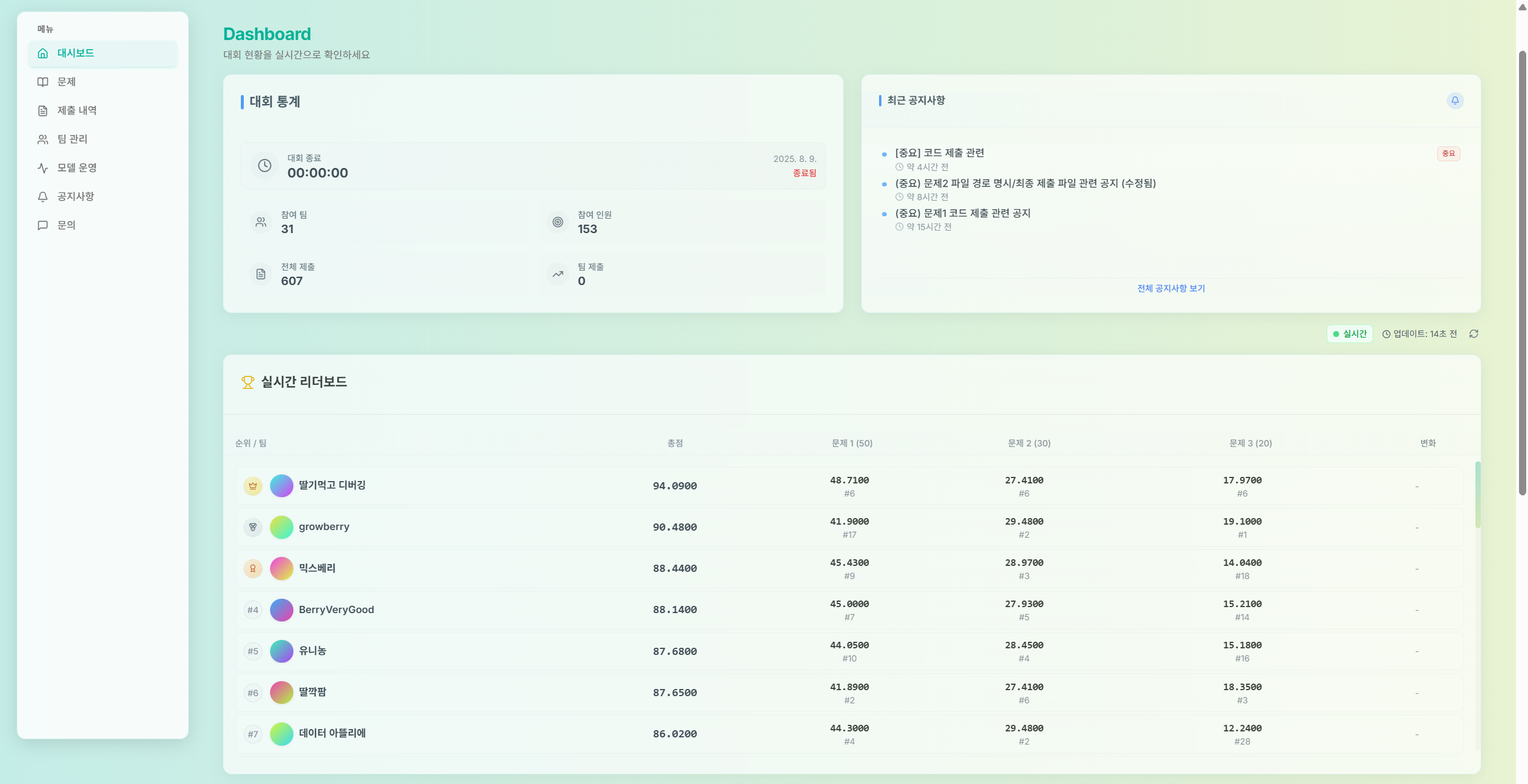
결과부터 말하자면 15위로 밀려 예선 2차로 진출하지 못 했다. 예상 순위 7위에서 15위로 떨어진 이유는 다음과 같다. 파일 제출에서 문제가 있었다. 변명을 하자면 AI CAMP에서 실습하고 프로젝트를 진행할 때는 train, inference, pkl 파일을 따로 만들지 않았다. 하지만 해당 대회에서는 하나의 .py(ipynb)가 아닌 rain, inference, pkl 파일로 나누는 것을 요구했고, 우리 팀은 해당 요구에 충족하지 못 한 채로 파일을 제출했기 때문에 문제2번에서 2위를 했음에도 0점 처리 됐다.
사실 이전에 이런 식으로 파일을 제출한 적이 있어서 나는 쉬웠지만 몇몇 팀원들에게는 어려운 일이었다. 물론 대회 현장에서 3시간 전부터 파일 제출 양식을 미리 준비하라고 팀원들에게 강조했지만 잘 전달되지 않은 거 같다. 지난 일이기 때문에 깔끔하게 서로 잘못을 인정하고, 다음 대회에서는 똑같은 실수를 하지 않기 위해 서로 개개인이 자체 피드백을 내렸다. 다음에 비슷한 대회가 있다면 똑같은 팀으로 정말 월등한 성적을 낼 수 있을 거 같다.
그래도 스마트팜에 대한 부분은 여기서 끝나지 않고, 대회동안 같이 고민했던 농장주님과 연락을 해서 추후에 농장주님 농장에서 IoT 시스템을 구축해 데이터 수집 및 자동화 환경을 만들어 볼 것이다.
2차 프로젝트
당원 이탈 예측 프로젝트를 진행했다. 정당 내부 데이터를 얻어내는 것은 쉽지 않기 때문에 당원 이탈에 영향을 줄 수 있는 요소들을 찾아 feature로 정했다.
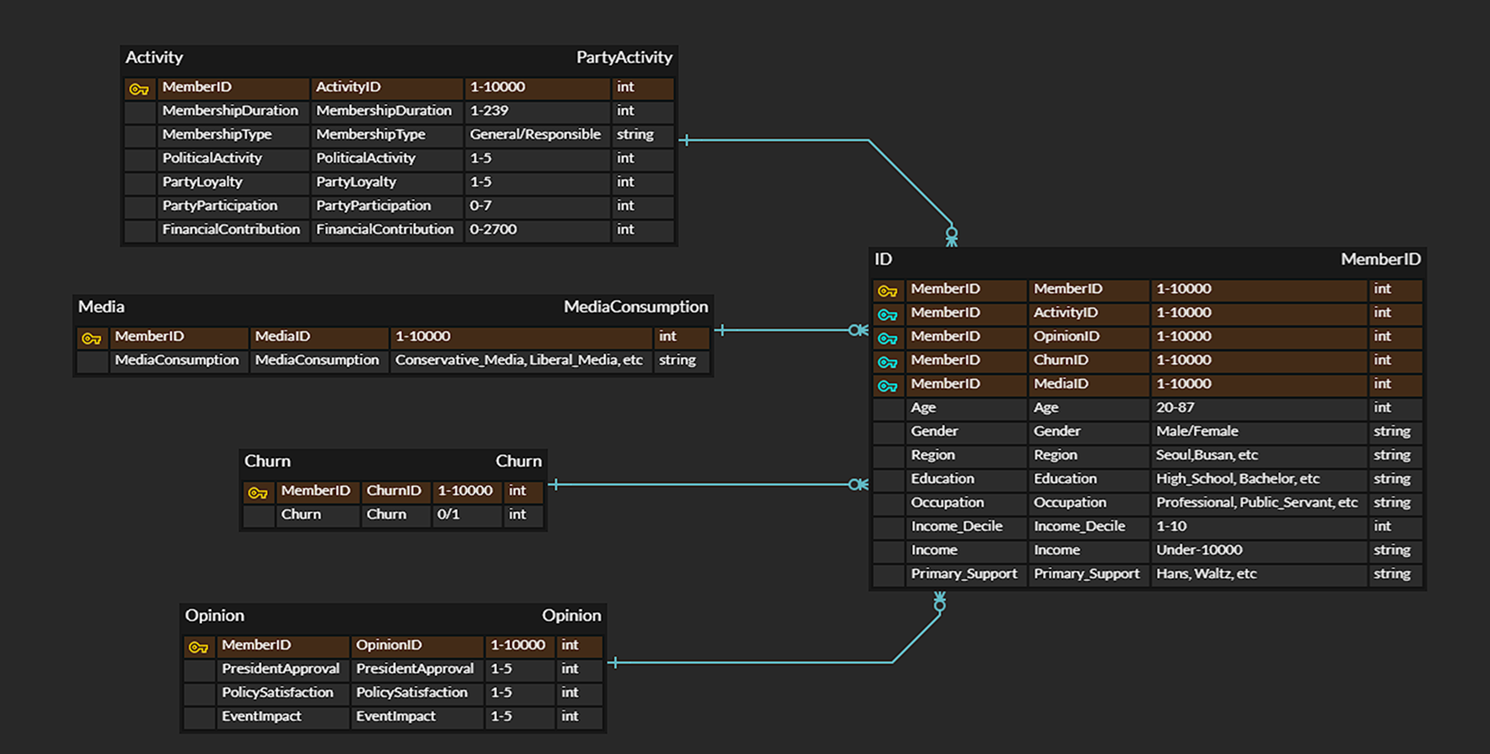
크게 Activity, Media, Churn, Opinion, ID 데이터로 나눠서 10000명의 회원 데이터를 만들었다. 이탈을 민감하게 예측하기 위해 이탈 비율을 거의 50:50으로 정했다.
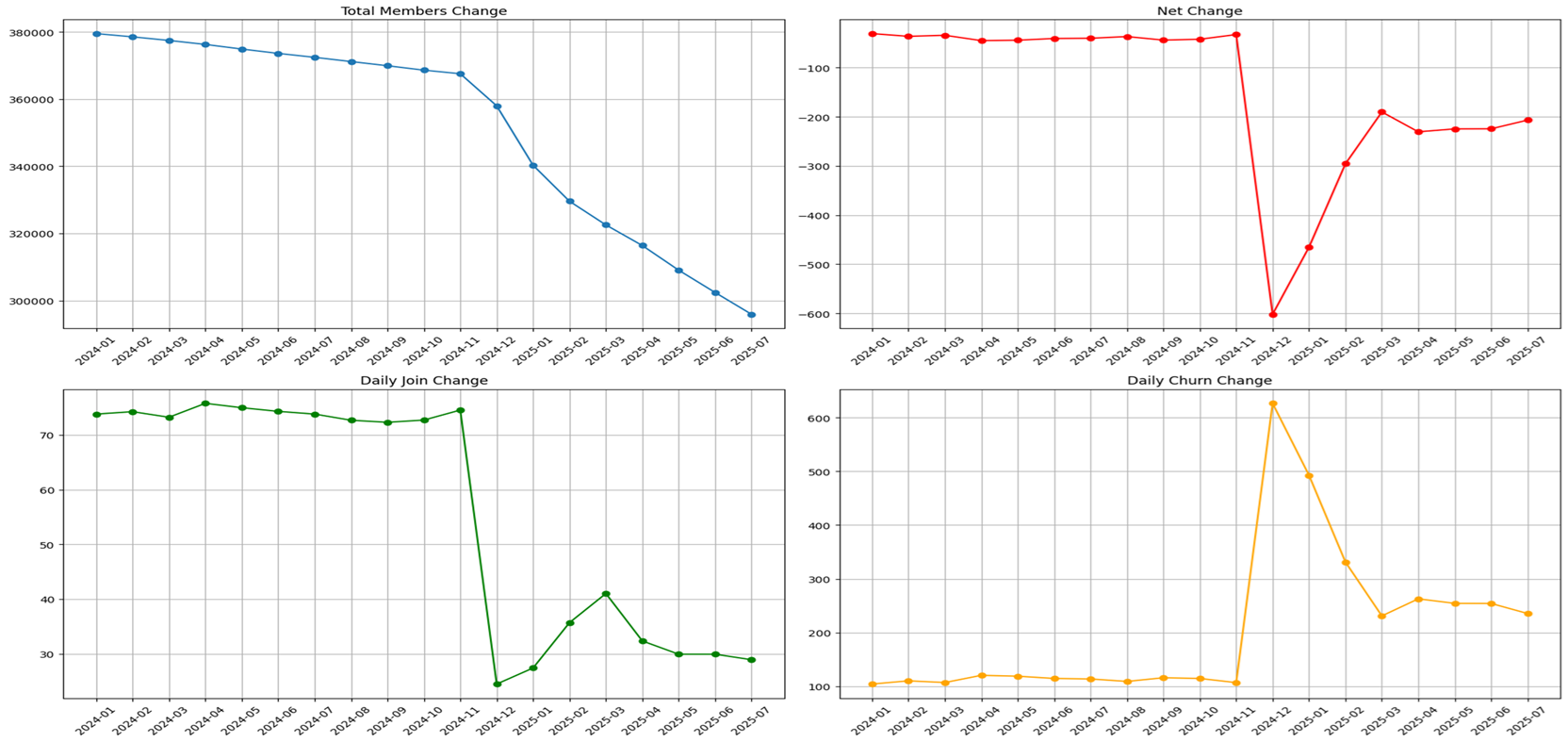
GPT로 정당 기사를 정리해서 Net Change 데이터도 만들었고, 해당 자료로 EDA를 진행했다.
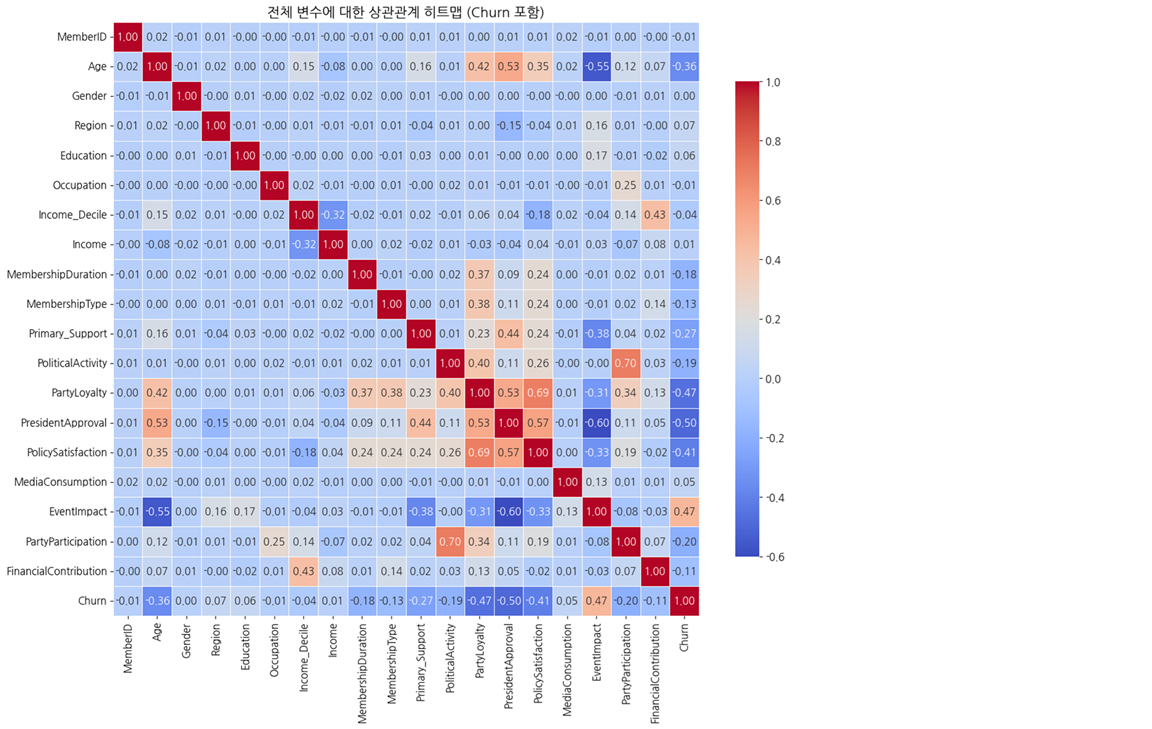
Feature들과 Churn과의 상관관계를 분석했고
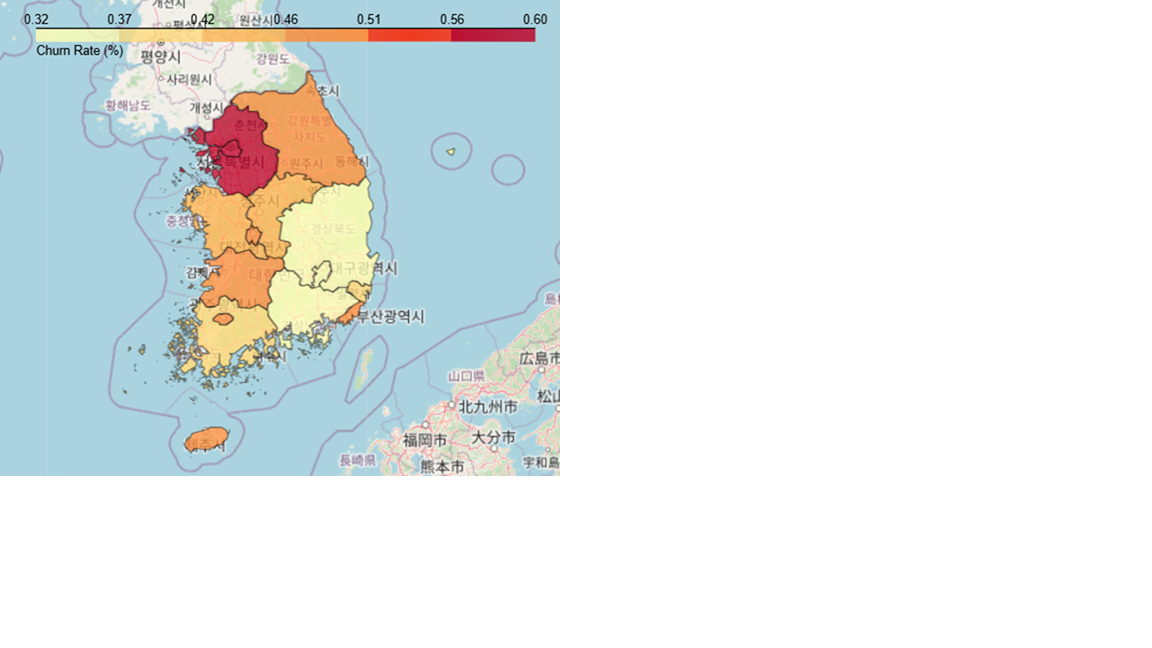
지역별로도 이탈분석을 했다.
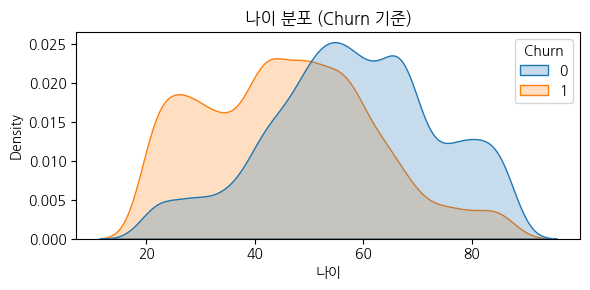
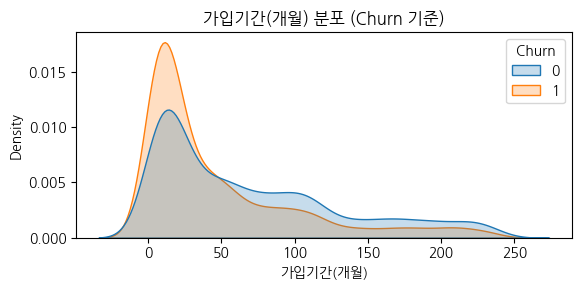
그 외 다양한 각도로 EDA를 진행했다.
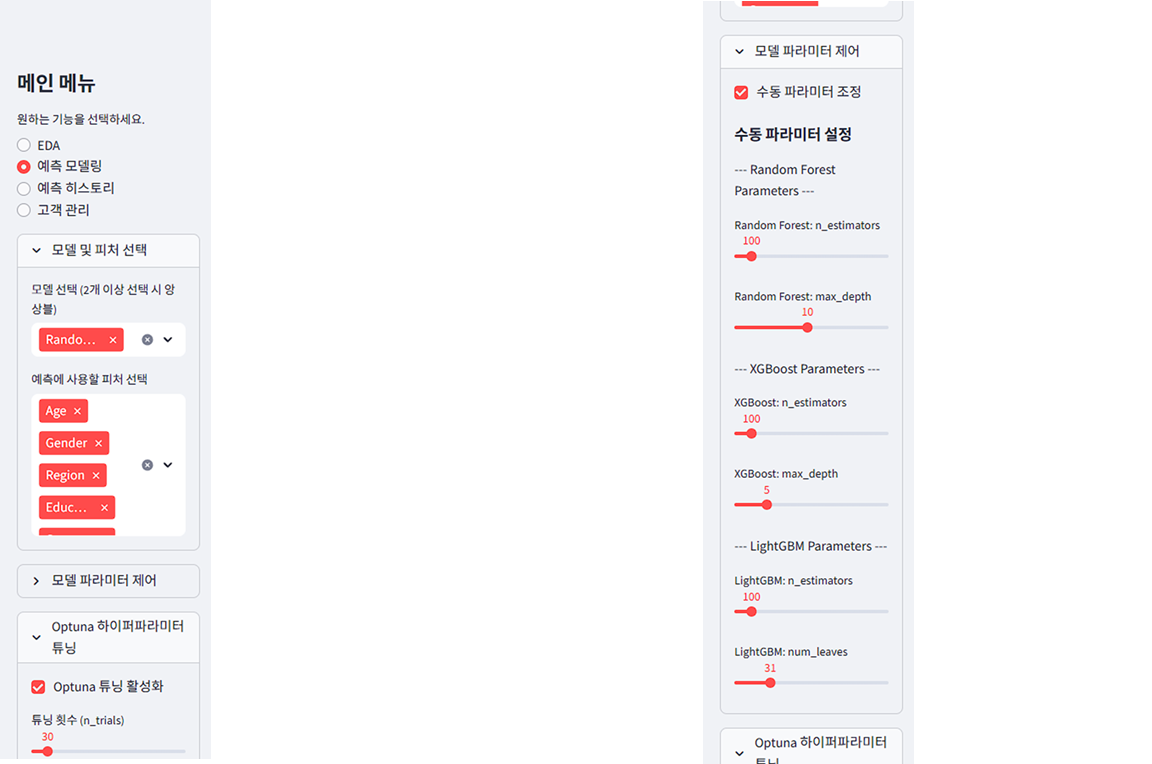
스트림릿 내부에서 ML/DL Model을 돌릴 수 있는 동적 시각화도 구현했다.
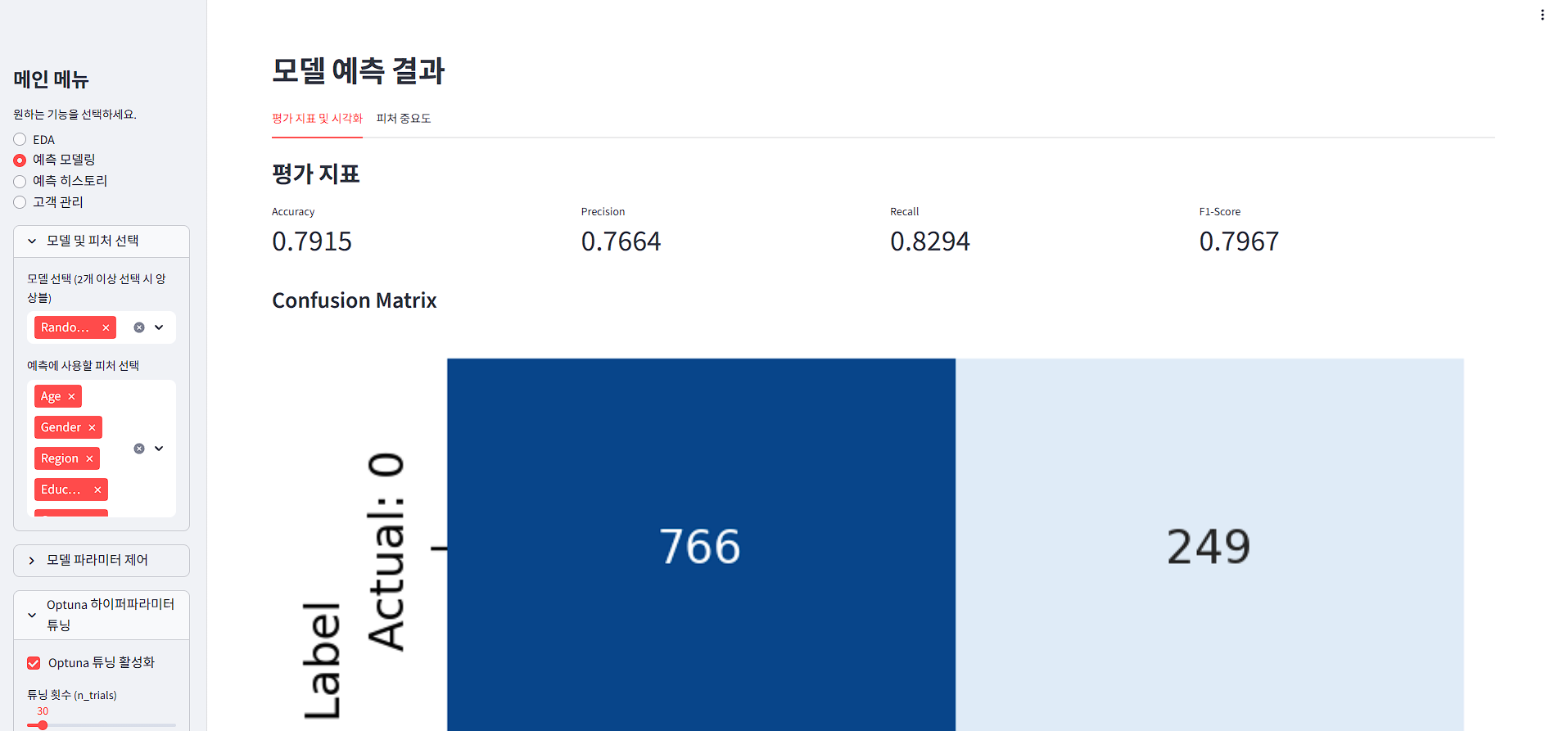

평가지표와 히스토리를 조회할 수 있는 기능도 넣었다.
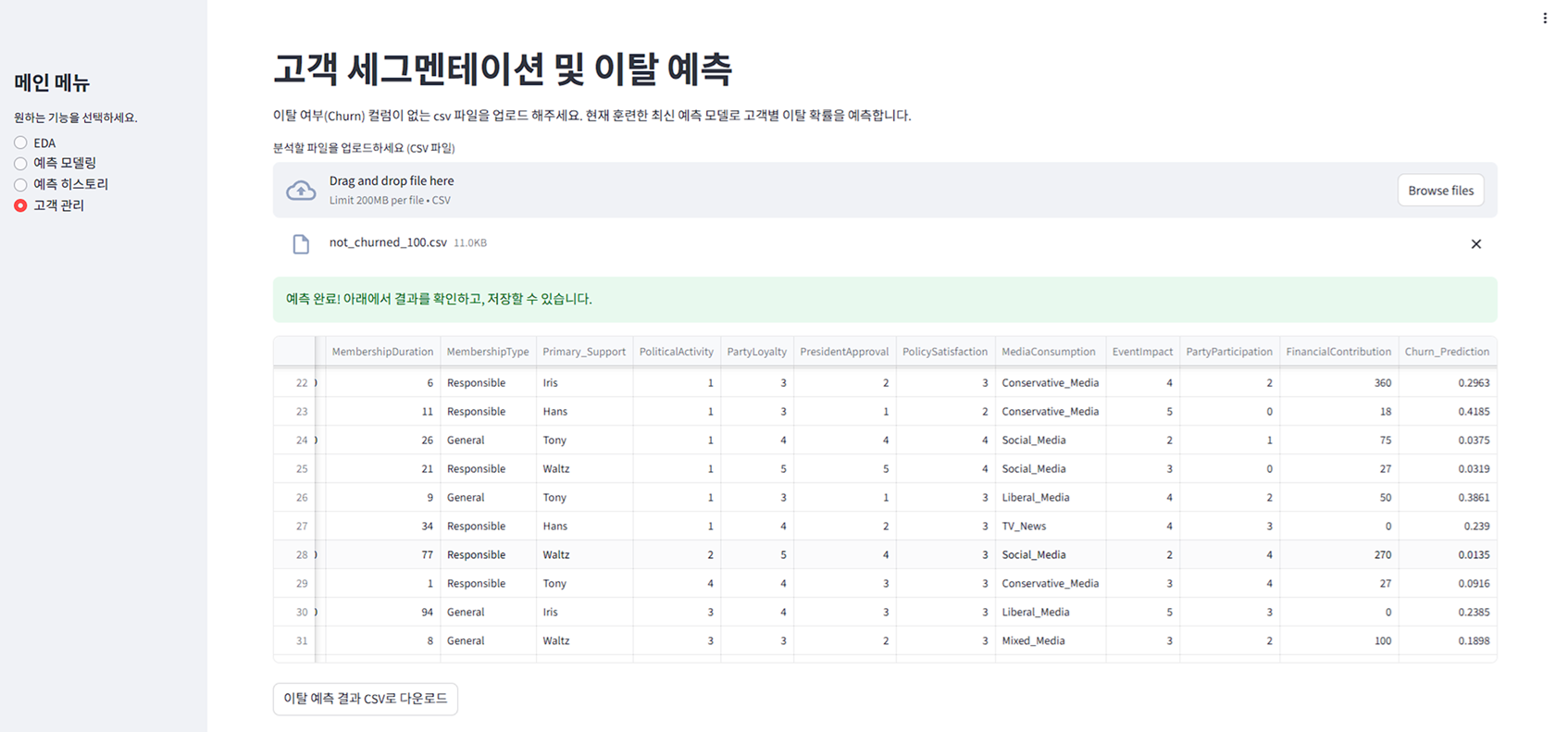
성능이 어느정도 뒷받침이 되면 기존에 있는 고객을 관리할 수 있는 세그멘테이션 및 이탈 예측 기능도 넣었다. 이 부분은 고객 이탈률을 예측해서 사전에 고객을 관리할 수 있게 하는 주요 지표를 제공한다.
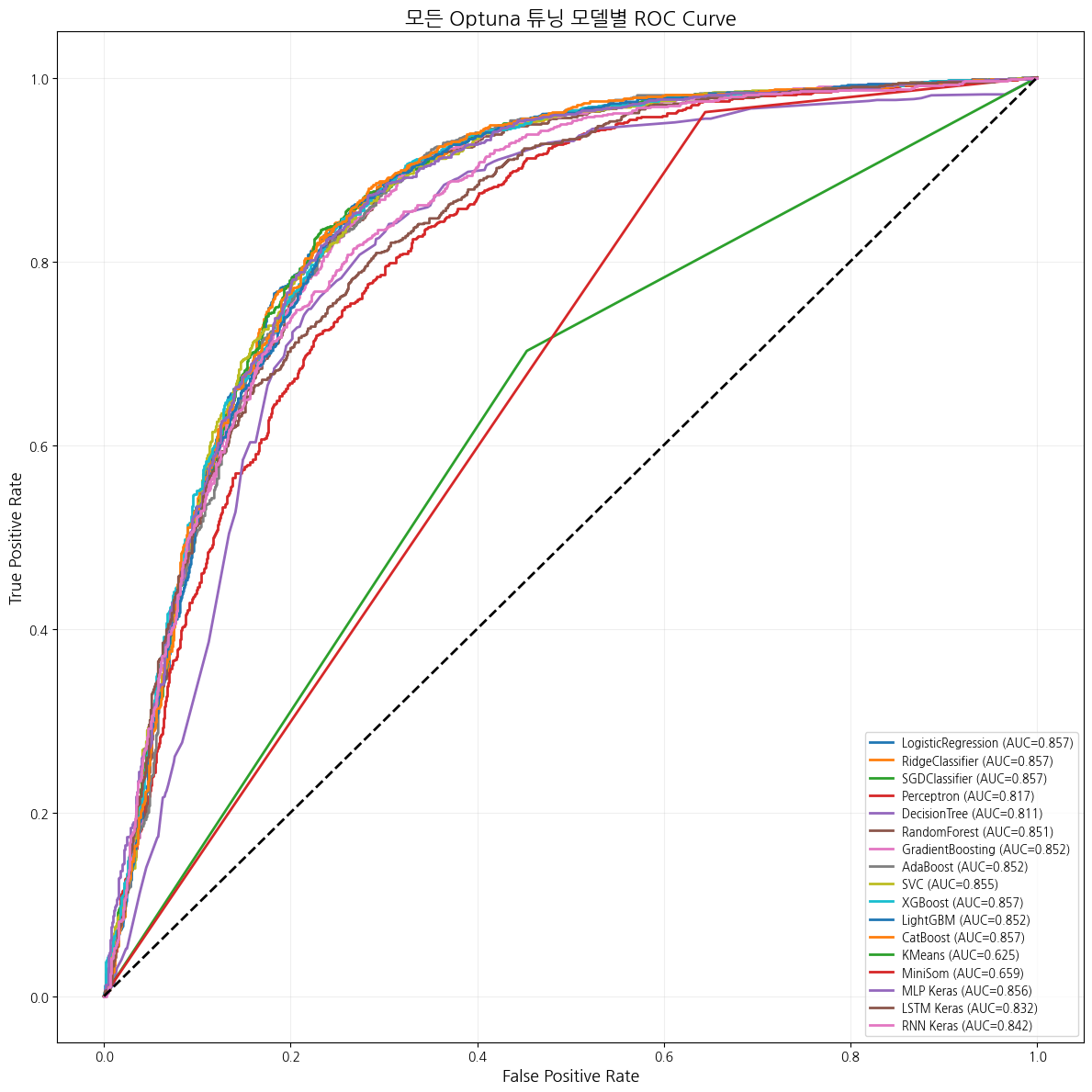
다양한 모델을 돌렸고, MiniSom과 KMeans와 같은 KMeans 이외에는 성능이 잘 나왔다.
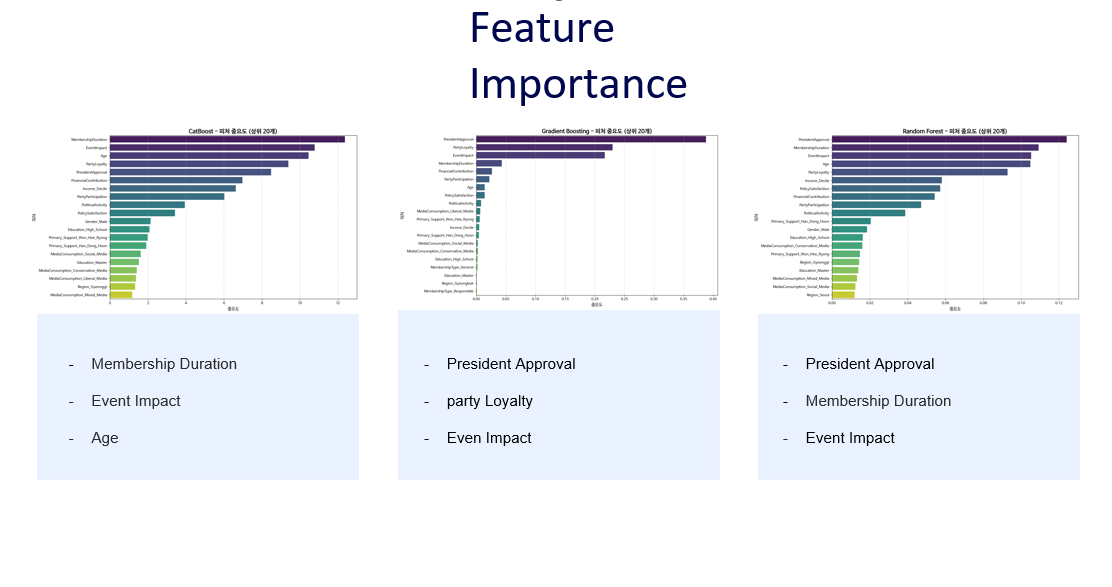
모델에 따라 Feature Importance가 다르다는 점도 알게 되었다.
이번 프로젝트는 꽤 짜임새 있게 잘 수행했다고 생각한다. 도메인 분석을 통해 고객 이탈에 영향을 주는 피처를 조사했고, 해당 피처를 통해 시뮬레이션을 했다. 프로젝트 고객을 당원 매니저로 정해서 어떻게 하면 업무 자동화를 해줄 수 있을까 고민을 했다. 동적 시각화를 통해 EDA를 확인할 수 있고, 예측 모델을 돌려 히스토리를 확인해서 모델 성능을 빠르게 평가할 수 있게 했다. 그리고 현재 남아 있는 당원을 위험도 높은 순서로 관리할 수 있게 고객 세그멘테이션 기능도 넣었다. 모델을 통해 예측한 것 뿐만아니라 산출물을 통해 솔루션을 제공했다는 점에서 공학적인 측면에서 높은 자체 평가를 내렸다. 아쉬운 점은 시간이 부족해 모델을 돌리면 돌릴 수록 streamlit이 무거워지는 현상이 발생했는데, 세션 초기화를 할 수 있는 기능을 넣었으면 좋았겠다 라는 생각을 했다. 그래도 끝까지 열심히 해준 팀원들에게 너무 감사하다.
