
https://viewership.softc.one
12,000명. 그리고 89,000뷰.
소프트콘 뷰어십은 대한민국 인터넷 방송을 수집하고 기록하여 사용자들에게 시각화한 데이터를 제공해주는 서비스입니다.
100명, 500명, 1000명, 3000명, 6000명, 그리고 12,000명 까지 중요 포인트마다 발생했던 문제점과 이를 해결하기 위해 노력했었던 이야기를 적어보려고 합니다.
이 이야기는 2023년 9월 23일. 첫번째 고비였던 시점에서 시작됩니다.
2023년 9월 23일. 하루에 500명이나 들어왔다!
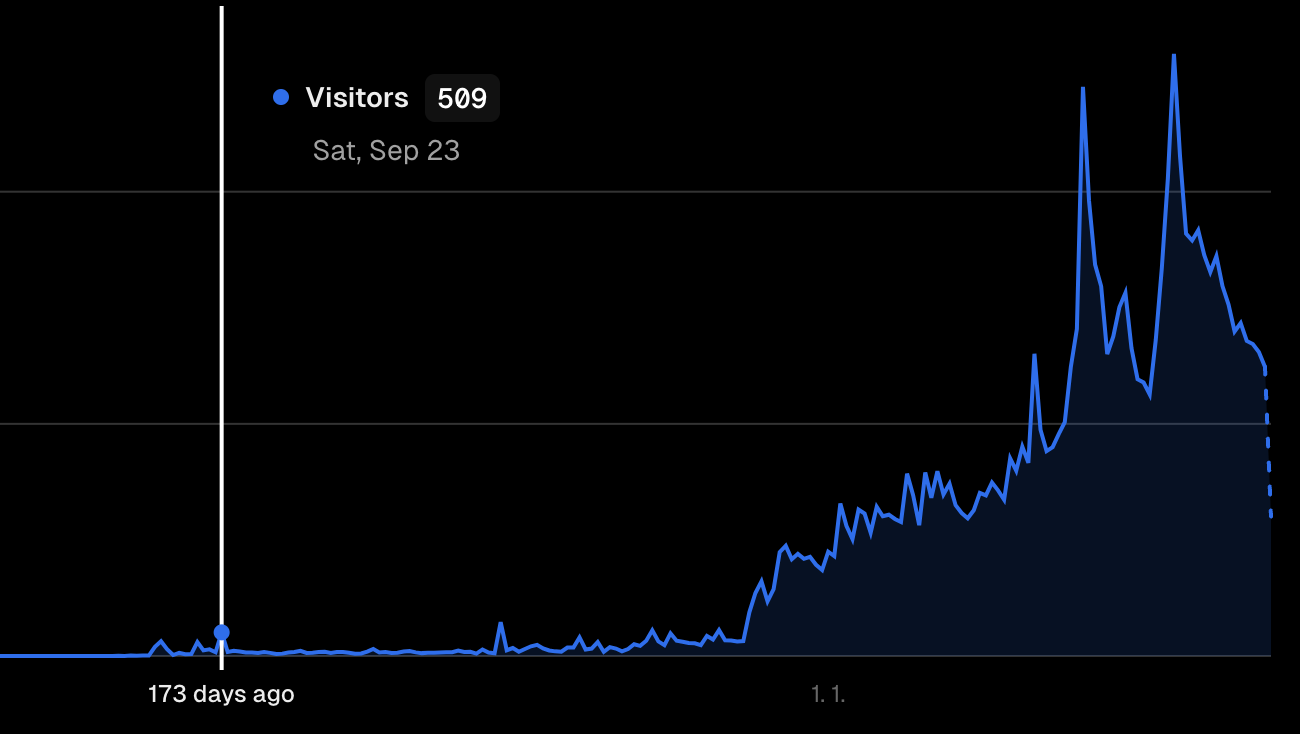
지금으로부터 약 6달 전.
프론트엔드 개발자였던 제가 서버, DB 이런것에 대한 이해도가 많이 부족하던 시절이였습니다.
서비스를 본격적으로 시작한지 일주일도 채 안되었고 데이터 수집도 아프리카, 트위치 각각 상위 200명씩 수집하던 많이 부족했던 시절이였죠.
( 지금은 보기 힘든 트위치 로고가 박혀있습니다 )
현재 사이트와 비교하면 초라하기 그지 없지만, 기본적인 틀은 지금과 크게 차이나지 않았던 시절입니다. 소소하게 운영하던 이 시절, 저는 서버리스 펑션을 이용하여 서비스를 구축하자는 마음을 먹고 야심차게 서비스를 만들어 나갔습니다. 이때 당시 펨코, 루리웹, 디시인사이드 등 어디를 가리지 않고 열심히 홍보하며 사이트를 알리기 시작했죠.
제가 자신있는 부분은 깔끔한 UI, 사용자 중심의 UX를 만들고 프론트엔드는 자유로이 만들수 있었지만 백엔드, DB와 관련된 지식은 수박 겉핥기도 못되는 수준으로 많이 부족한 상황이였습니다.
그렇기에 서버 코드 작성을 줄이고자 Next.js의 서버리스 펑션을 이용해 직접 DB와 통신하는 서비스를 준비하고 있었죠.
서버리스 펑션으로 구축, 하지만?
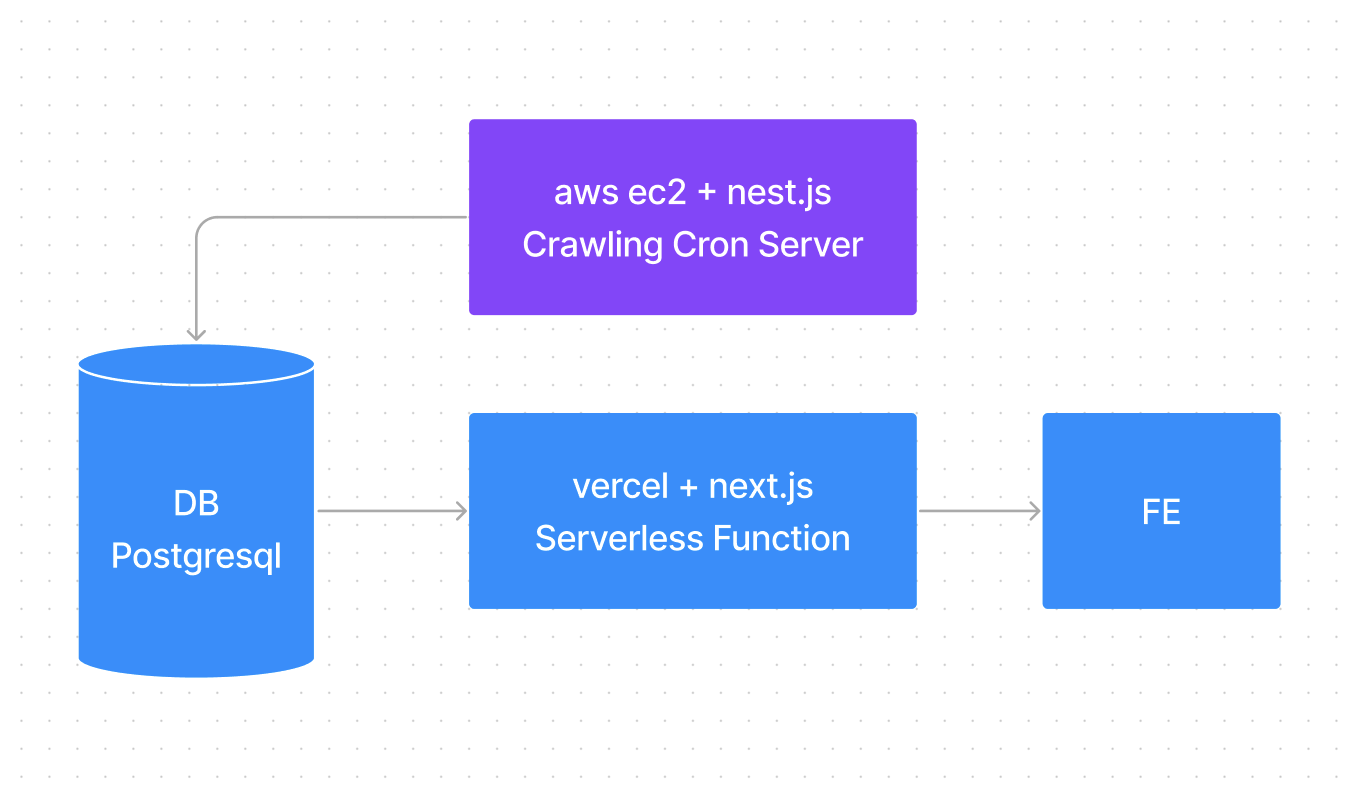
기본적으로 AWS EC2에 크롤링용 서버를 두고, AWS RDS의 postgresql DB를 이용하여 데이터를 쌓은 후 Vercel의 Serverless Function을 이용해서 데이터를 가져오자! 라는 계획이였습니다.
하지만 DB에 무언가 거치치 않고 수많은 요청이 들어간다는 것이 얼마나 큰 문제인지 예측하지 못했습니다. 9월 23일 저는 동시 접속자 100명이 보내는 초당 10개 이상의 요청을 DB에서 바로바로 처리할수 없다는것을 서버 셧다운과 함께 지켜볼 수 밖에 없었죠.
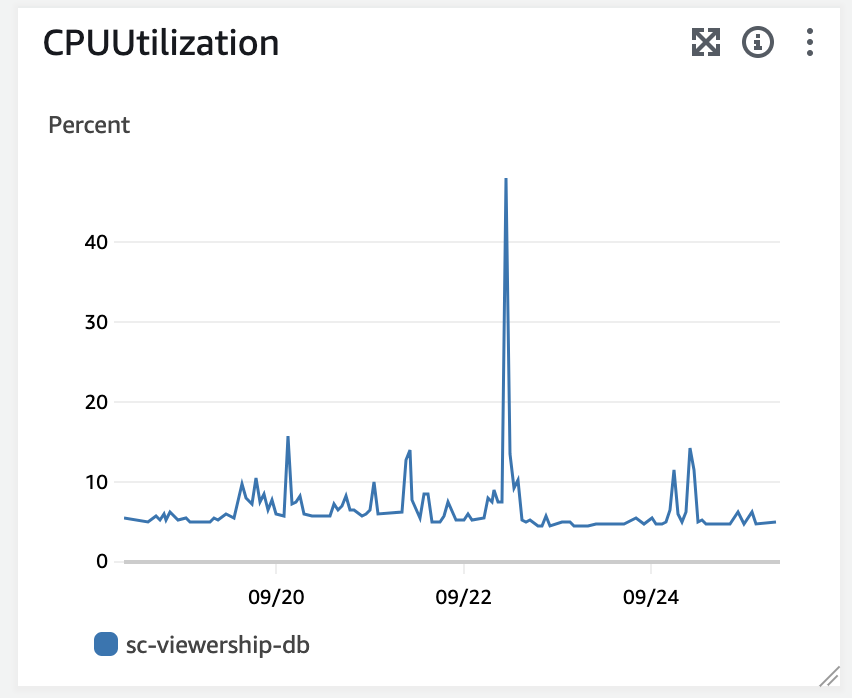
당시 RDS는 수많은 요청을 견디지 못했고, 들어온 모든 처리를 연산하다 견디지 못해 CPU 100%를 찍고 장렬히 전사해버렸습니다. DB를 재시작하고, 스케일업을 통해 t4g.micro에서 t4g.medium까지 스케일업을 했지만 결국 해결책은 이부분이 아니라는것을 깨달았습니다.
서버리스 펑션을 고도화 vs Vercel Data Cache 이용
서버리스 펑션을 이용했을때 발생한 문제는 바로 Connection Pooler가 없었다는 점이였습니다.
즉, DB로 들어가는 수많은 요청들을 순서 없이 마구잡이로 보내버리니 결국 한번에 모든 요청을 처리하지 못하고 CPU 처리에 과부하가 걸려버리는 것이였죠.
그렇다면 이 Connection Pooler를 도입해야 하지만, 생각보다 도입이 어려웠습니다. 그리고 제가 눈을 돌린것은 Vercel Data Cache를 더 적극적으로 활용하는 방안이였습니다.
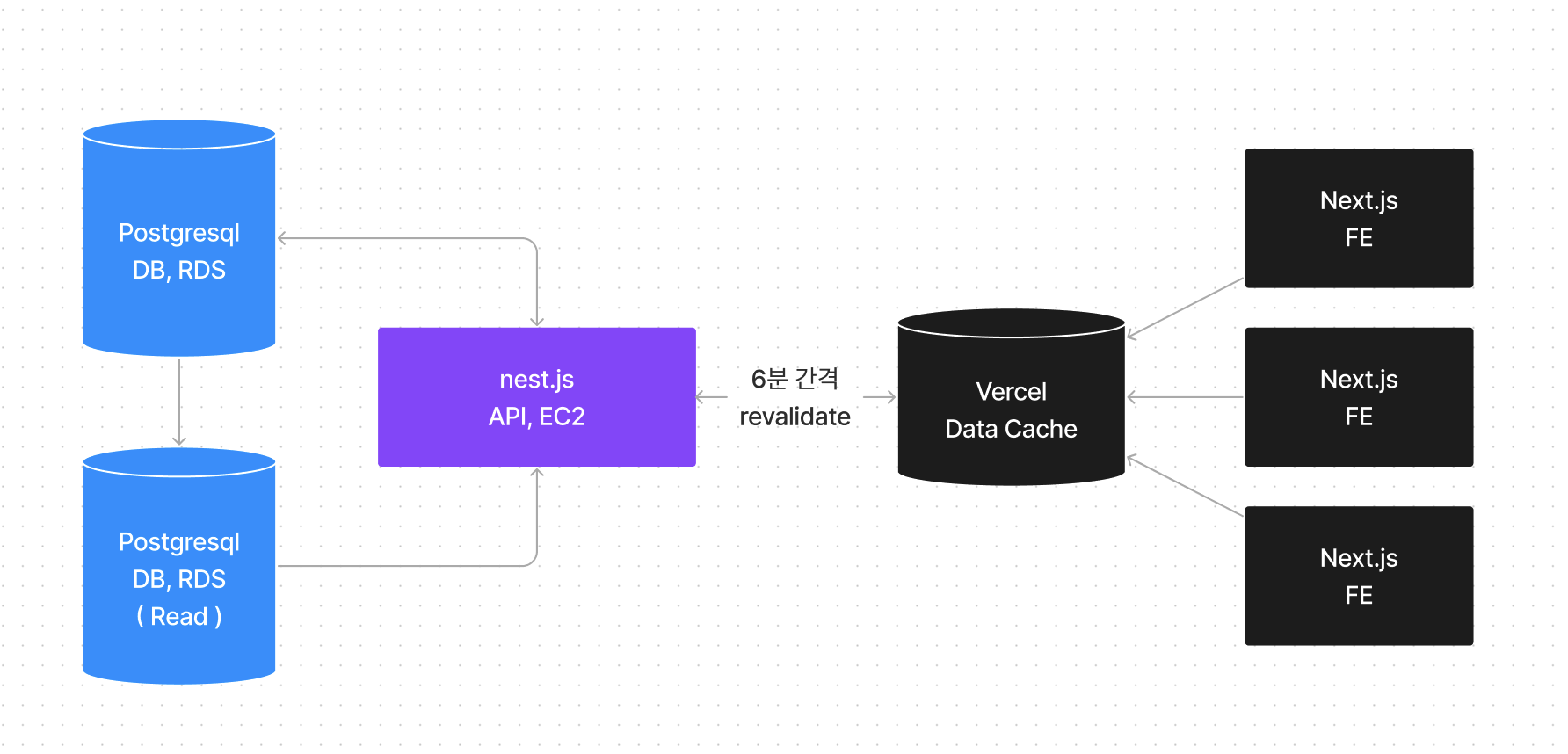
그리고 최종적으로 결정한 흐름도는 다음과 같았습니다.
국밥같은 DB, SERVER, FE 라는 구조를 만들고 여기서 FE의 Vercel Data Cache에 API 요청을 저장하여 페이지를 구성하는 App Router를 적극적으로 이용하는 방법이였죠.
서버 수집이 끝나면 Vercel에 무효화 요청을 보내 기존 캐시를 전부 날리고, 새롭게 데이터를 만들어 주면 될것이다! 라고 생각을 했습니다.
2023년 12월 19일, 스트리밍이 시작됩니다.
2023년 12월.
너무나 많은 일들이 벌어지기 시작했습니다.
12월 중순, 네이버가 새로운 스트리밍 서비스인 치지직을 개시한다는 공지를 올리고 이와 비슷한 시기 트위치가 한국 시장 철수를 선언했습니다.
굉장히 시장이 급박하게 돌아가기 시작했고, 저는 이 타이밍이 굉장히 큰 기회가 될수 있겠다라고 판단했죠.
치지직이 오픈하는 시점인 12월 19일 오후 12시. 이 시간동안 모든 감각을 네이버 판교 그린팩토리(공사중) 1784로 곤두세우고 열리는 순간만을 기다리고 있었습니다.
그리고 열리는 순간부터 바로 수집을 시작했죠.
1000..명? 괜찮을까?
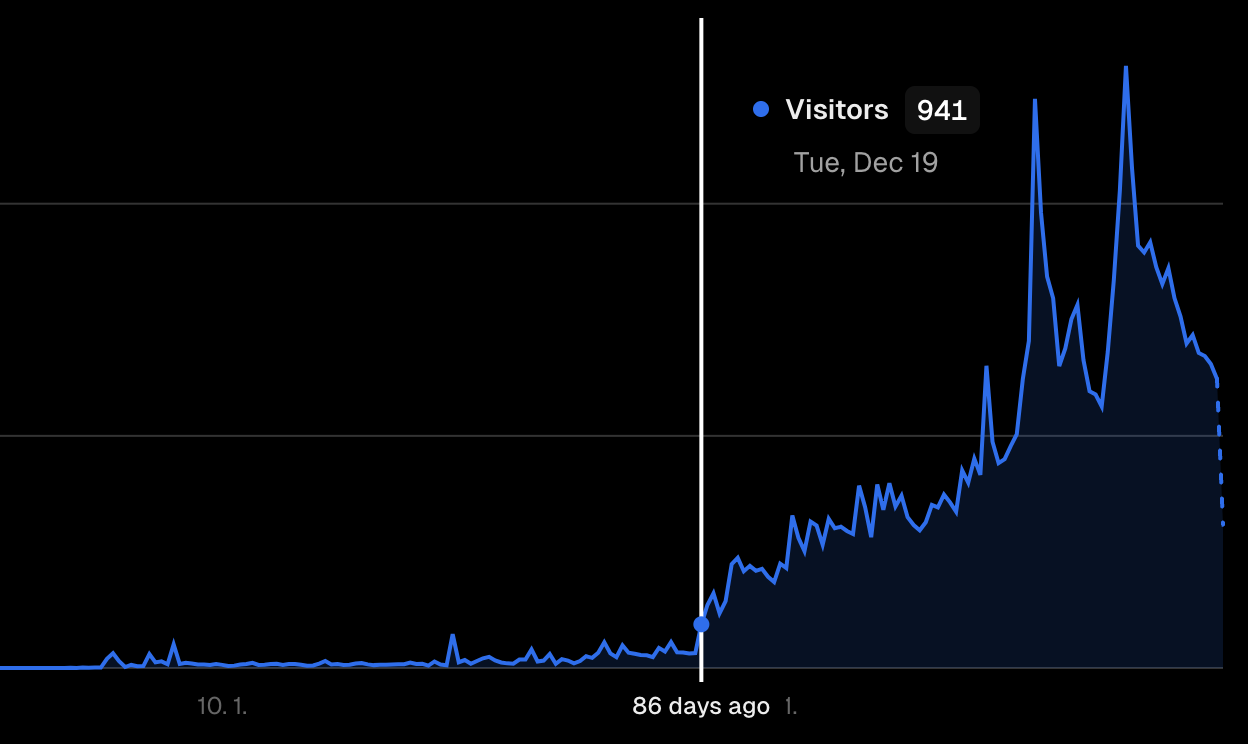
이제 하루에 1,000명씩 들어오기 시작합니다.
이제 본격적인 동시송출의 시기가 다가올것으로 예상하고 이와 관련해 모아보기 서비스를 런칭했습니다. 수집되고 있는 아프리카, 트위치, 치지직, 유튜브등 다양한 플랫폼의 방송을 한곳에서 모아볼수 있는 서비스였죠.
프론트에서 할것이 있겠지만 백엔드에선 이미 구현되어 있는 코드를 재활용할 뿐이니 최소 개발로 최고의 효율을 뽑아낼수 있는 좋은 서비스였습니다.
이와 같이 멀티뷰 서비스를 추가하고, 사용자들이 여러 방송을 한눈에 모아볼수 있도록 깔끔한 UI/UX를 구현해놓았습니다. 이부분은 다양한 고민과 여러 시도 끝에 나온 굉장히 신선한 UX로 만들었죠!
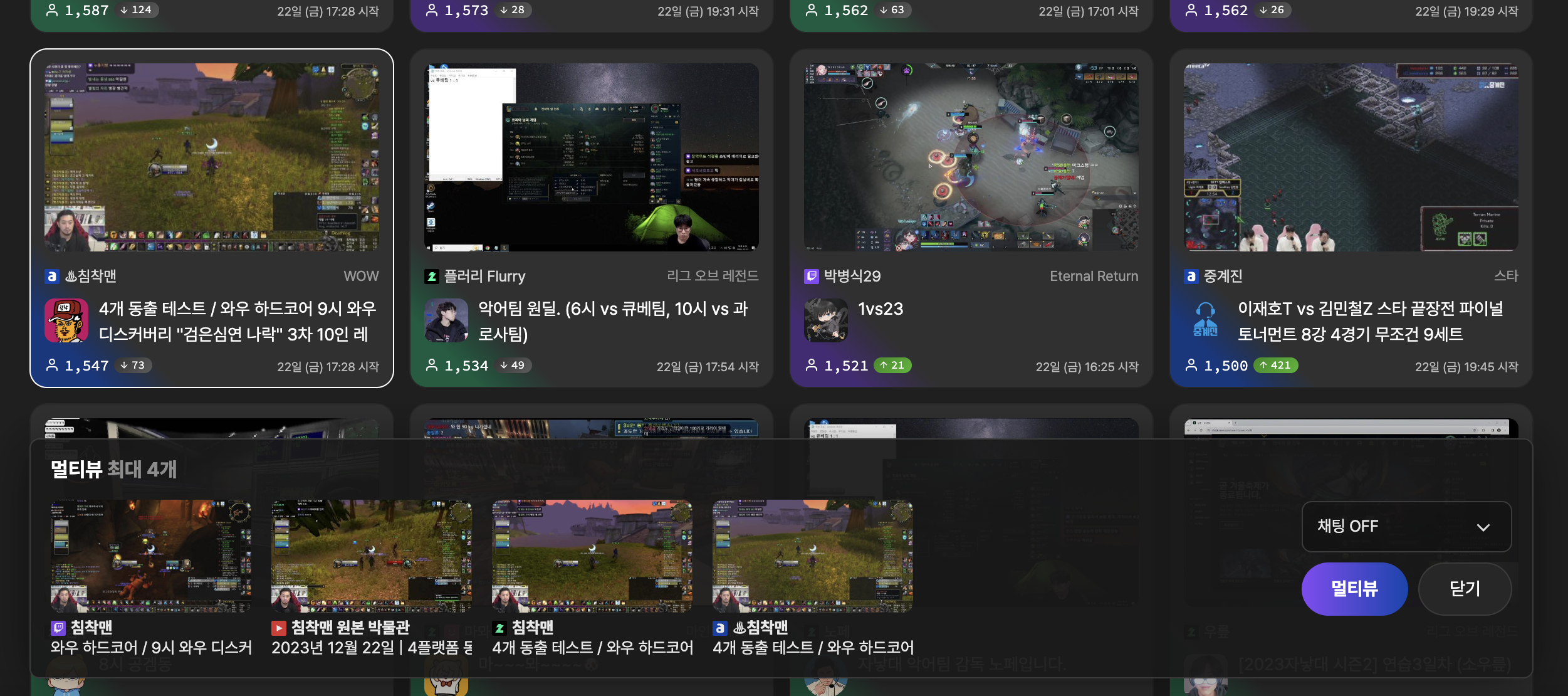
( 멀티뷰로 보기 버튼을 누르면 장바구니처럼 담을수 있도록 UI가 전개됩니다 )
생각보다 모아보기 서비스 인기가 좋았습니다. 그리고 그만큼 사용자도 많이 늘었죠.
2023년 12월 29일, 어.. 왜?
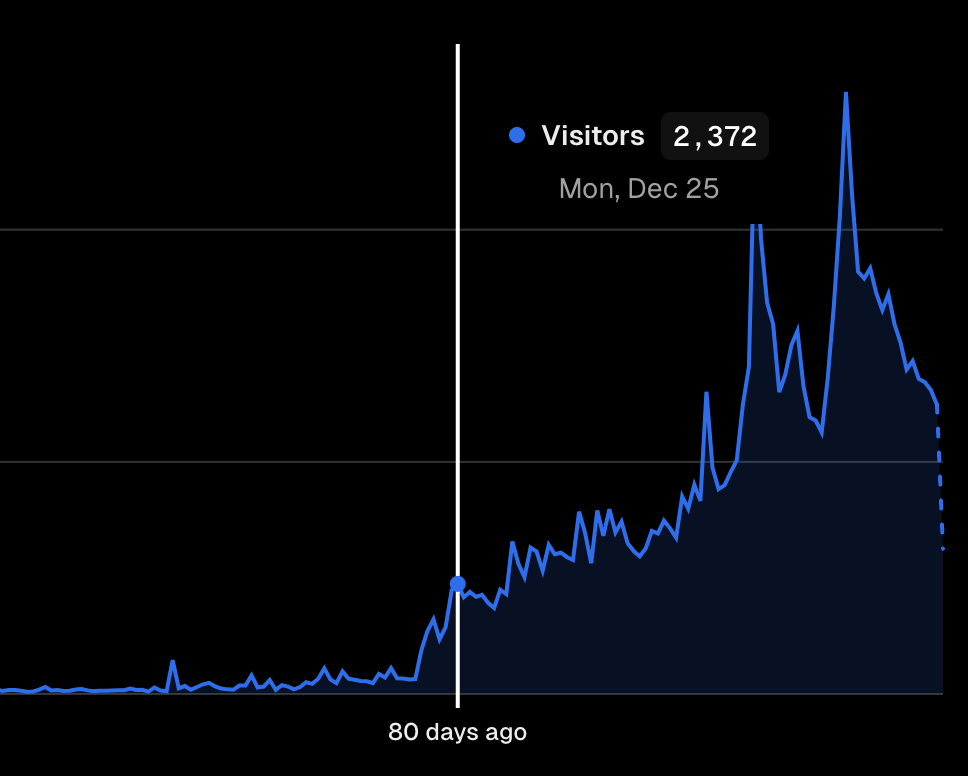
봉준님의 방문, 그리고 갑자기 들어온 200명 이상의 접속자.
서비스가 굉장히 불안정합니다.
많이 들어오긴 했는데.. 한번 곰곰히 생각을 해봤습니다.
12월 29일까지 쌓인 총 DB 레코드는 2천만개가 넘어가는 상황이였고, 가장 최근 시간대를 가지고 조회 하는 API의 요청시간이 600ms 정도 나오는것이 당연하다고 생각했습니다.
created_at = '2023-12-25T00:00:00Z'이 조건 검색이 600ms라..
뭔가 이상하다고 눈치챘어야 하는데.. 그땐 전혀 몰랐죠.
읽기 전용 복제본 추가
DB를 증설하는것이 해법이라고 생각했습니다. 여러 지표를 확인했을때 EC2는 CPU 사용률이 10%는 커녕 5~8%사이를 유지하고 있었고 이 반면 RDS는 CPU 사용률이 더 높고 Slow Query가 꽤 많았거든요.
여기서 여러가지 질문들이 생겼지만, 일단 눈앞에 보이는 문제를 해결하자 라는 생각으로 t4g.medium의 인스턴스를 1개 더 추가해 Read Replica를 하나더 만들고 서버에서 사용하는 ORM에 추가해 고가용성을 확보했습니다.
그런데 아무리 생각해봐도 이상합니다. 분명 제가 유튜브에서 배운건 인덱스만 잘 걸면 1억개든 10억개든 전혀 문제 없어야 하는데.. 왜 단순한 조건 검색이 600ms나 나오는걸까요?
2024년 1월 9일, 인덱싱.

Prisma의 스키마 파일을 다시한번 살펴봤습니다.
인덱싱을 저렇게 거는것이 맞지 않나 라고 생각했고, DBeaver의 인덱스 내역을 살펴봤죠. 그런데 인덱싱이 이상합니다.
멀티 컬럼 인덱싱을 걸어놨네요!
( 멀티 컬럼 인덱싱, 지금 화면에 보이는 모든 조건을 동시에 검색 할때 만 사용되는 인덱싱. 저렇게 다같이 사용하는 경우는 단 한곳도 없음 )
🤪
인덱싱을 수정. 사실상 인덱싱을 처음 걸은..
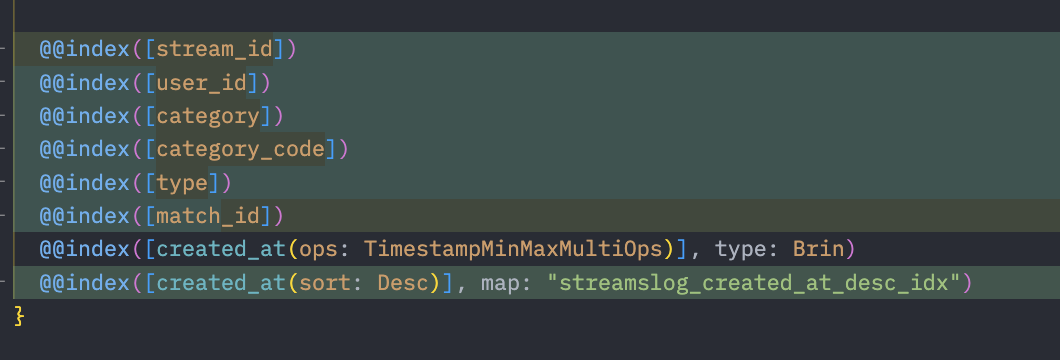
Prisma 스키마를 수정하고, 인덱싱을 새로 걸었습니다.
인덱싱을 새로 거는데만 5분 이상이 걸린것 같은데 걸고 나니 모든 DB 요청의 속도가 극적으로 상승했습니다.
특히 created_at = '2023-12-25T00:00:00Z'같은 요청은 기존 600ms에서 20ms로 줄었죠.
너무 기본적인 내용이였지만 오히려 기본적이였기에 의심하지 못했던것 같습니다. 이때 기준으로 서버와 DB 관련된 내용을 다시한번 점검하고 필요 없는 부분을 다시 교정했습니다.
다시 DB 축소
인덱싱을 수정하고 나니 발생했던 여러 문제들이 감쪽같이 사라졌습니다. 인스턴스 1대당 비용이 한달에 120$였기 때문에 다시 Read Replica는 삭제하고 단일 인스턴스로 돌아갔습니다. 인덱싱의 중요성을 몸소 체감했지만 너무 부끄러운 상황이였죠.
지금이라도 알게되서.. 정말 다행입니다 ㅠ
2024년 1월 18일. 돈내 돈!
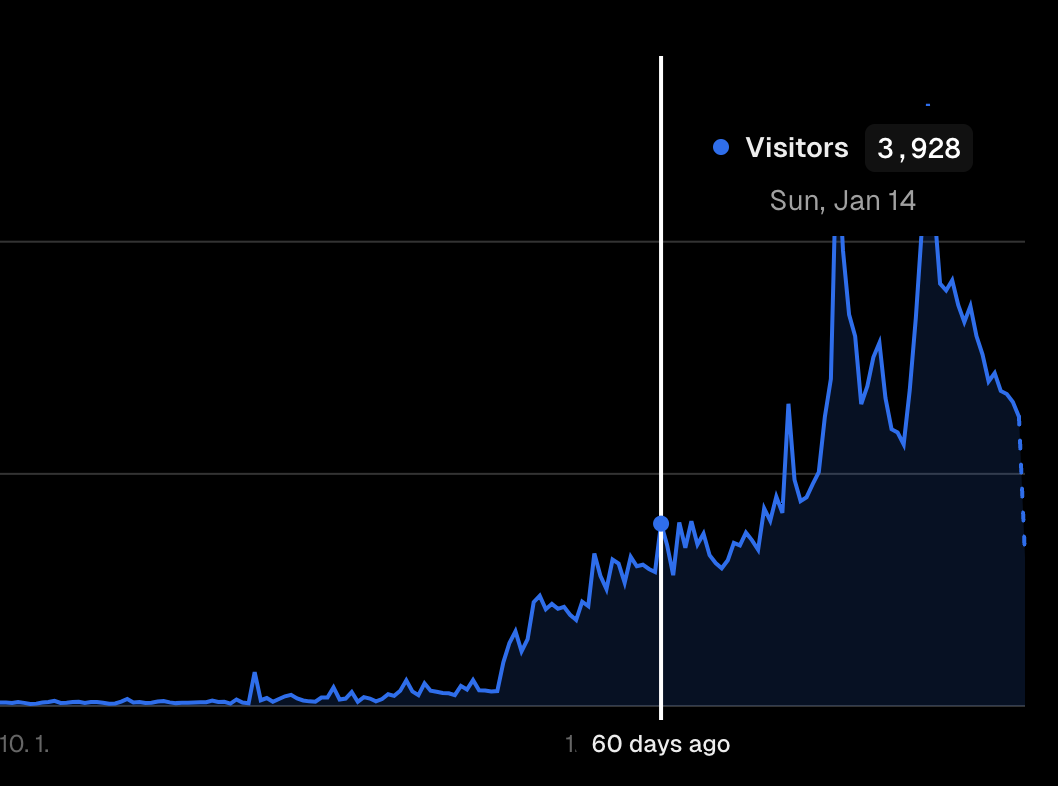
하루 4,000명씩 들어옵니다.
하루에 100명씩 들어오던 사람들이 이제는 1시간에 200명씩은 들어오는 상황이죠.
RDS의 떨어질것 같지 않던 지표중 하나가 떨어지기 시작합니다.
CPU Credit의 고갈
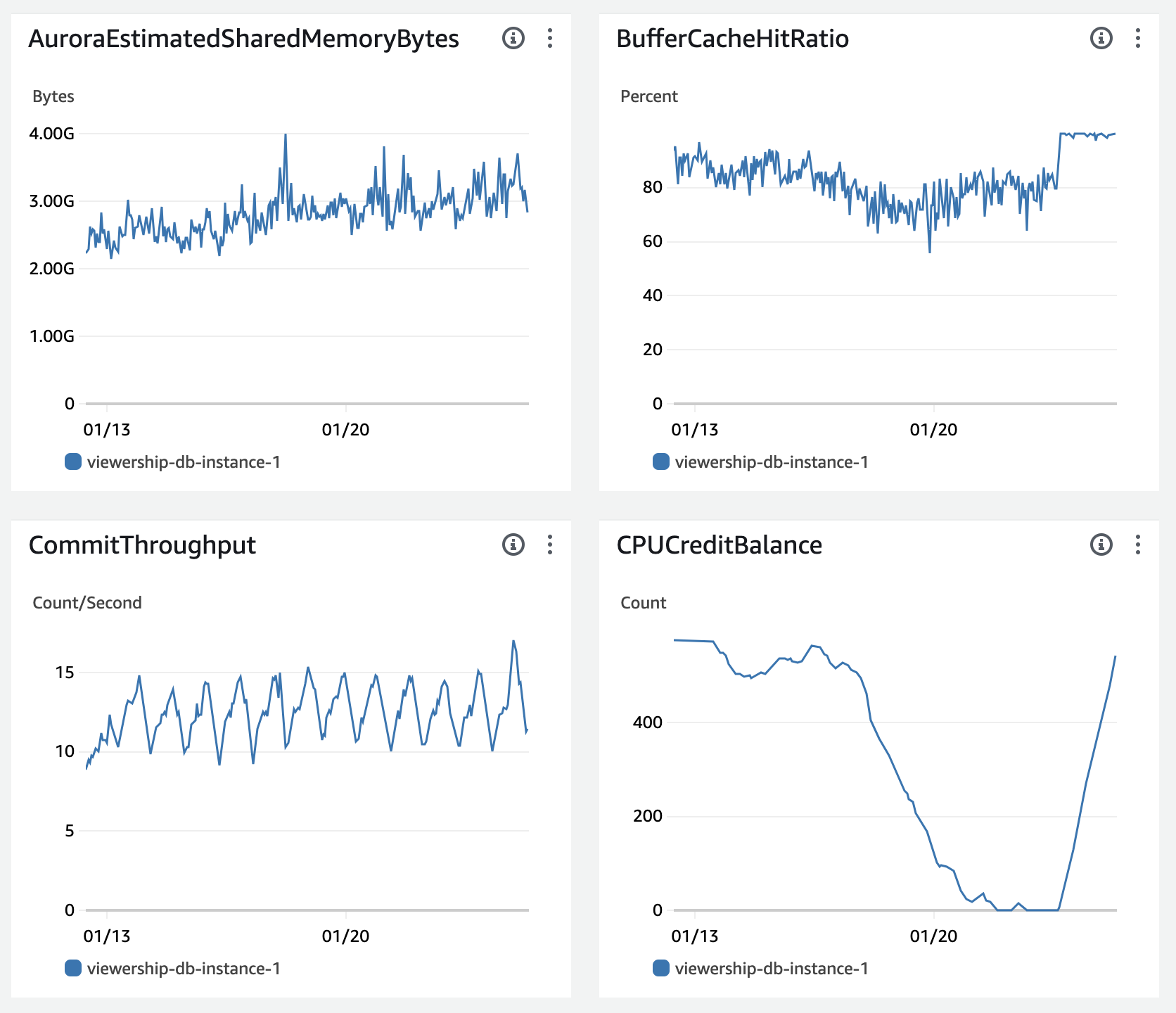
와!
CPU Credit이 고갈되고 있어요~
현재 사용중인 t4g.medium은, CPU 사용률이 20%가 넘으면 CPU Credit 고갈이 발생합니다. 사용자가 그리 많지 않던 시절 고갈될 일이 없었고 연속적으로 사용되는것이 아니기 때문에 괜찮았겠지만 이제는 상황이 다릅니다.
이젠 거의 대부분 상황에서 20%는 넘게 사용하게 되었죠.
이건 뭐 최적화고 뭐고 자시고 따질 필요가 없었습니다. t4g.medium으로 버틴것도 정말 대단했습니다. 떨어지는 그래프를 3일간 바라보다 결국 t4g.large로 스케일업을 진행했습니다.
성능 체감폭은 큰 변화가 없었지만, 서비스 자체는 더 안정적으로 운영할수 있었습니다.
2024년 2월 12일. 총체적 난국
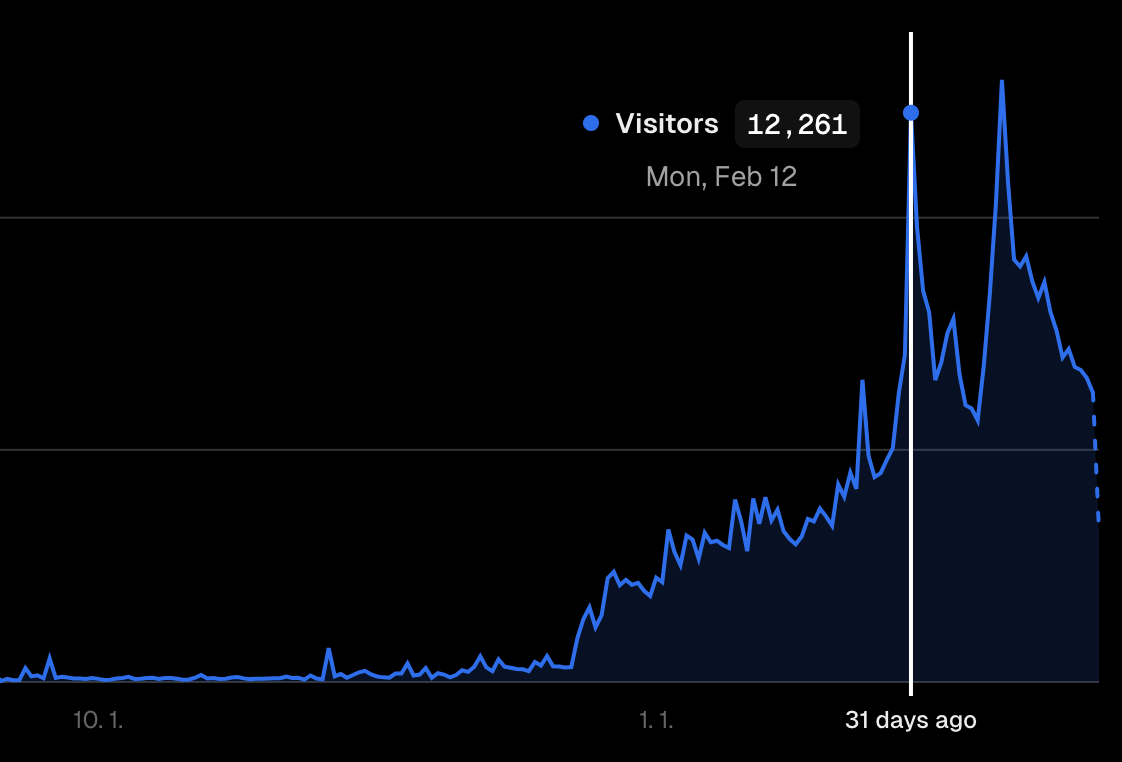
2월 12일, 13일.
하루 4,000명씩 들어오던 사이트에 12,000명이 들어왔습니다.
이세계 아이돌 첫방송 + 양띵님의 띵타이쿤 이 2가지가 이틀 연속으로 겹치며 인터넷 방송 최고의 트래픽을 기록했던 날이기도 합니다.
보통.. 사이트가 어느정도 대응하려면.. 20~30% 이렇게 상승해야 하지 않을까요?
300% 상승 같은건 어떻게 대응하죠?!
후..
뭐 사이트는 터졌고 커뮤니티에선 "망했다" "디도스다" 등등 다양한 이야기가 들어왔습니다.
2월 12일 사이트 대응은 완전히 포기했고, 데이터는 일부 날라갔고, 손쓸 방도는 없고 뭐 그랬죠!
Vercel에 기록된 그날의 기록
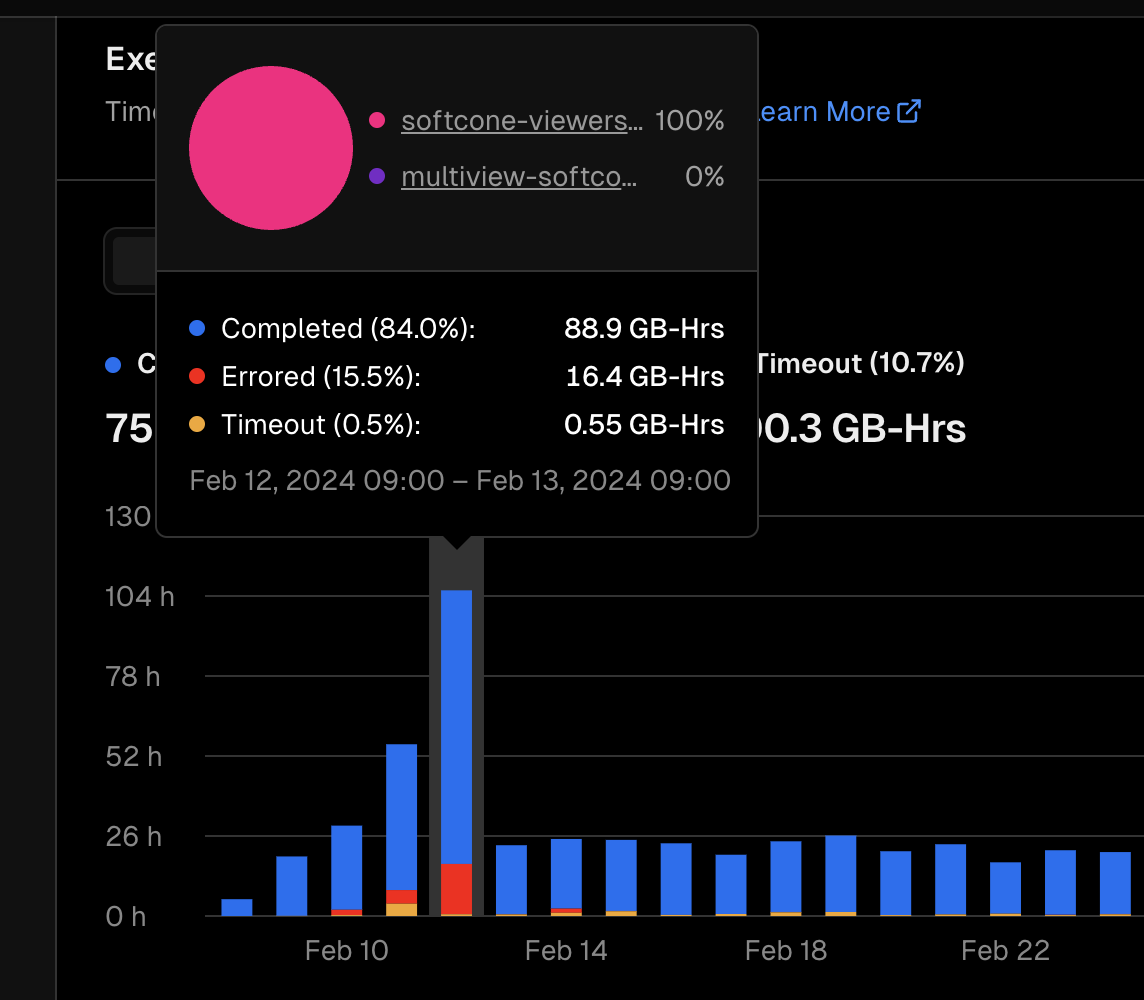
해당 일자의 기록들을 살펴보면 다음과 같습니다.
- 총 요청수 : 1,801,770 요청
- 서버로 간 요청 ( Data Cahce 제외 ) : 352,707 요청
- 사용된 서버시간 : 105.8GB-h
Vercel PRO에서 제공되는 한달 서버 시간이 1TB-h인데, 이중 105GB를 하루에 다 사용했습니다. 이중 오류 비율만 15%라는것도 굉장히 놀라운 사실이였죠.
2월 13일. 이제 문제를 해결해 봅시다.
실시간을 고집하지 말자
기존 뷰어십 서비스에서 사용되는 시간은, "최근 7일, 최근 30일"과 같은 실시간 데이터였습니다. 6분마다 새롭게 데이터가 추가되면 해당 데이터를 다시 연산하고 랭킹화 시켜 사용자들에게 보여주는 것이였죠.
2월 12일 발생했던 문제에서 가장 오래걸렸던 쿼리는 랭킹의 최근 30일 이였습니다. 무려 30초 이상의 소요시간을 보여주며 최악의 상황을 연출시킨 장본인이였습니다.
왜 기존엔 괜찮았고, 지금은 문제가 났을까요?
데이터 수집 범위 확대, 계산식의 변경
기존 사이트는 트위치, 치지직, 아프리카 각각 상위 300명씩을 수집하고 있었습니다.
하지만 이 수치로 대한민국 인방을 자세히 보는것은 불가능했고, 점차 수집 범위를 확대하기 시작했죠.
문제가 되었던 2월 13일, 수집되는 범위는 각 플랫폼별 상위 1,000명씩으로 기존 수집에 비해 3배 이상 증가한 수치였고 당연하게도 쿼리 계산 시간 역시 기하급수적으로 늘어났습니다.
기존
900개 X 10개 (1시간) X 24 (1일) X 30 (1달) = 6,480,000 레코드
2월 13일
3000개 X 10개 (1시간) X 24 (1일) X 30 (1달) = 21,600,000 레코드
SQL Explain을 이용해 확인해보니, 33s 정도의 시간이 소요되었고 초당 72만개의 레코드를 처리한다는 어마무시한 연산 속도였지만 그럼에도 굉장히 느렸습니다.
이 연산을 6분마다 모든 조건에 맞춰 처리하는 상황에선 개선의 여지가 보이기 힘들었죠.
최근에서 지난으로!
랭킹의 모든 필터를 변경하여, 실시간 성 데이터를 전부 어제 까지의 데이터로 변경하고 더 오랜기간 캐싱이 될수 있도록 변경했습니다. 가령 "최근 30일"이였다면, 이제 "지난 30일"로 변경되는 사항이였죠.
사용자들의 니즈는 어제든 오늘인든 최신 아님? 이였고, 이런 변경점에 대하여 불만 혹은 이의를 제기하는 사람은 아무도 없었습니다! 정말 다행이였죠..
2024년 2월 27일. 트위치 서비스 종료.
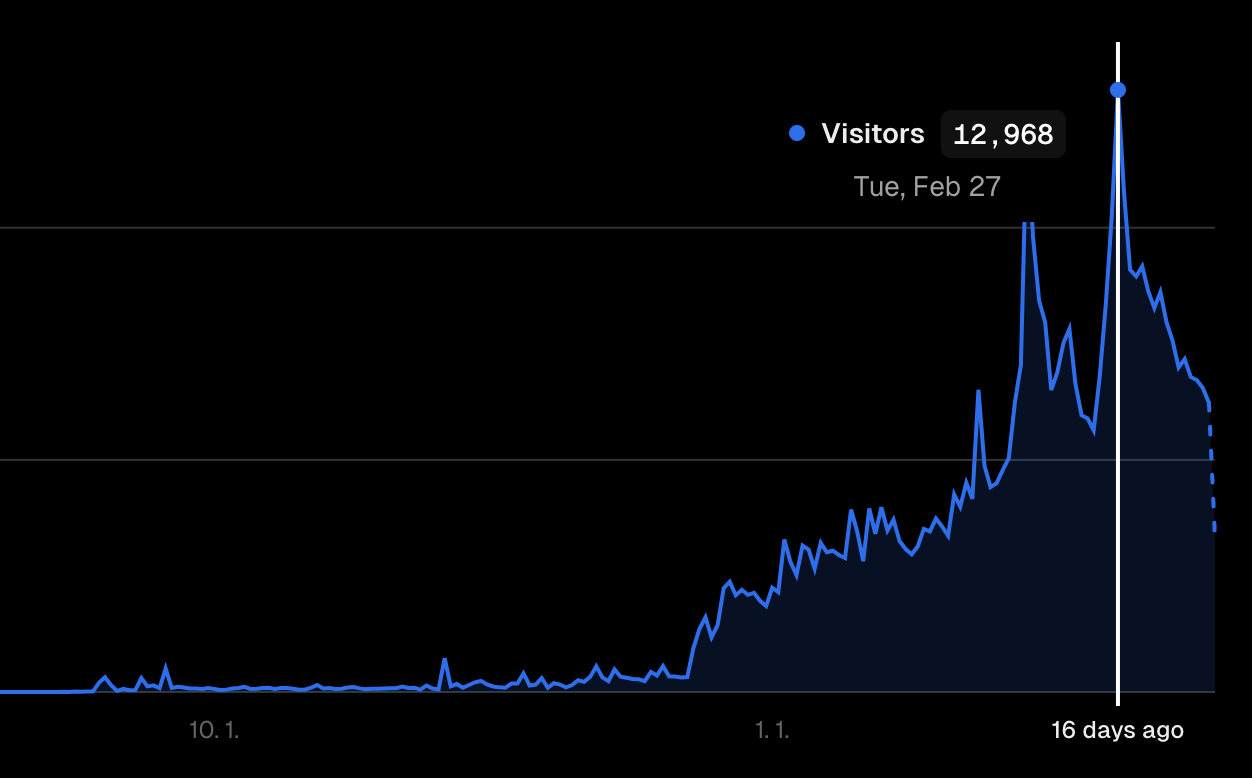
12,968명. 현재까지 최고의 기록입니다.
트위치의 서비스 종료 날이기도 했죠.
이미 26일날부터 트래픽이 많아 1만명 이상 접속하고 있었고 서비스가 매우 불안정한 상황이였습니다. 그리고 이때를 기점으로 한주간 서비스가 매우 불안정하기 시작했습니다.
지난 데이터를 불러오는데도 너무 느립니다.. 캐싱이 제대로 된다면 이런 문제가 없을텐데요?
Vercel Data Cache, 한순간 쏟아지는 트래픽
현재 서비스는 도커? 쿠버네티스? 어림도 없죠! pm2를 이용해 돌아가고 있는데요, 해당 로그를 살펴보니 뭔가 신기한점이 있습니다. 바로 매 6분마다 한순간에 트래픽이 쏟아진다는 점이죠.
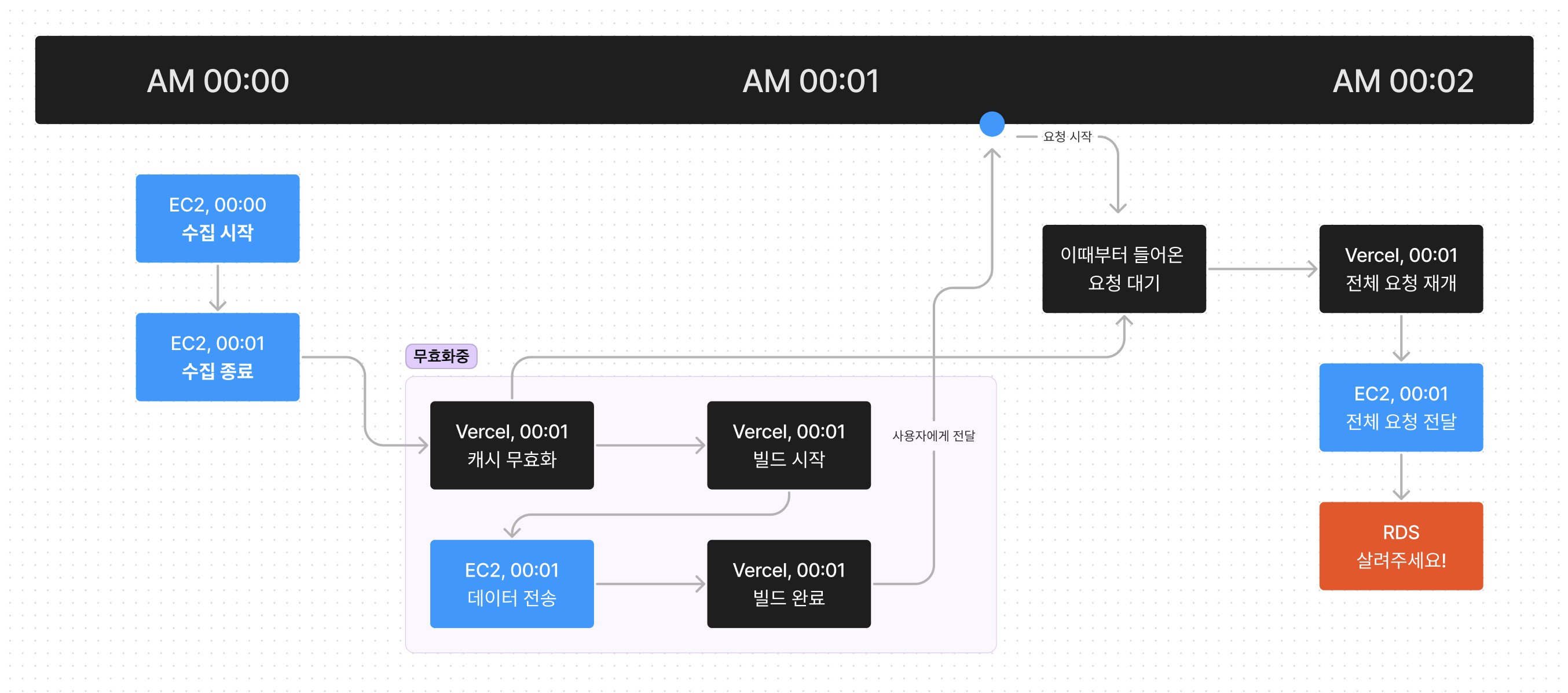
가령 오전 00:00에 수집을 시작한다고 생각해봅시다.
00시 01분, 수집이 종료되고 Vercel에 캐시 무효화 요청을 보내면, Vercel은 이때부터 들어온 모든 요청을 대기하고 캐시를 무효화합니다.
사이트 내의 모든 API는 무효화 tags로 엮어있고, 무효화 요청시 사이트 내의 모든 캐시가 날라가는 구조였습니다. 이로 인해 무효화 요청 이후 첫 페이지가 빌드되는 과정과 빌드가 완료되어 사이트가 보여지는 상태의 모든 요청이 대기가 되었고 대략 10초 ~ 20초간의 쏟아지는 요청수를 RDS와 EC2의 서버가 버티지 못할 정도로 쏟아진것이 문제였죠.
이는 제가 크게 2가지 실수를 했는데,
- Vercel Data Cache에 모든 데이터를 하나의 태그로 엮음. 무효화시 모든 페이지가 정지
- Vercel Data Cache는 용량이 무한하지 않음.
나눠 놓으라고 만들어진 next 무효화 태그를 단 하나만 사용함으로써 이점을 홀라당 날려먹었습니다. 이런 문제를 겪은 이후, 엮어있는 API들의 무효화 tag를 정비하고 나눌 계획을 세우기 시작했습니다.
요약 테이블의 제작
앞으로 점진적인 수집 범위 확대가 예상되어 있는 현재 시점에서, 더이상 미룰수는 없었습니다.
1년 이상의 데이터가 모이게 된다면, 해당 데이터를 계산하기 위해서라도 요약 테이블은 반드시 필요했고, 매일 특정시간에 예약 실행이 되도록 만들고 해당 시간마다 하루치 데이터를 요약해 정리하는 테이블을 만들었습니다.
이 시점, 트위치는 수집량을 100개로 줄이고 치지직과 아프리카는 각각 1,800개까지 올린 상황이였습니다. 이제 최신 데이터가 아닌 지난 데이터는 다음과 같이 검색량이 줄었죠.
기존
1900 X 10개 (1시간) X 24 (1일) X 30 (1달) = 13,680,000 레코드
2월 13일
30,000개 (1일) X 30 (1달) = 900,000 레코드
이제 해당 API는 아무리 느려도 3~5초 이내면 계산이 끝났습니다. 이제 요약테이블도 만들었겠다, 더 이상 문제가 발생할일은 없을것이라고 생각했습니다.
2024월 3월 5일. 대규모 트래픽 발생
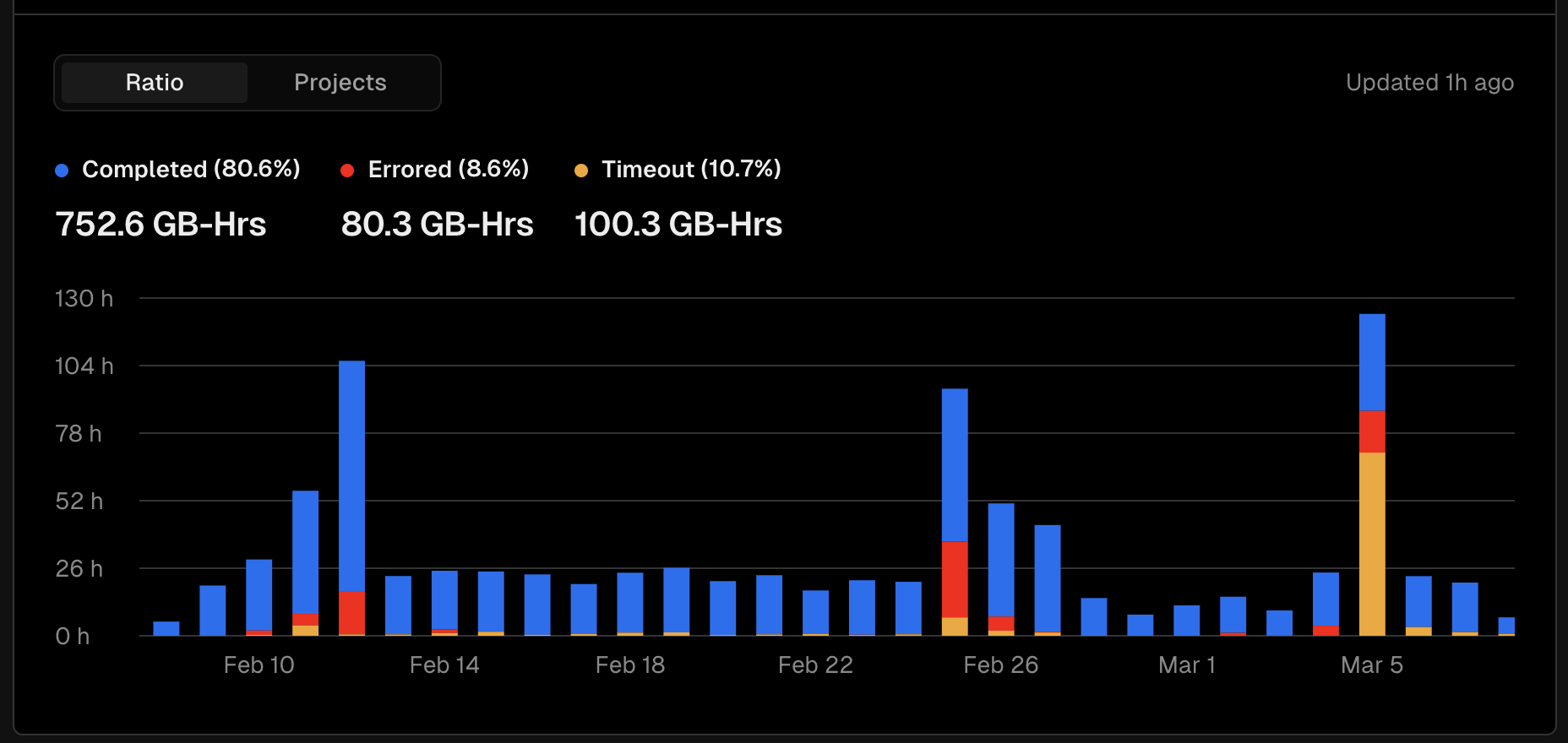
이날 들어온 사용자는 총 8,000명 수준으로 분명 12,000명이 들어오던 시점보다 확연하게 줄었지만 서버는 최악의 상황에 도달하기 시작했습니다.
분명 Vercel 방문 사용자수와 최대 동시 사용자수는 100~200명 대로 버틸수 있는 수준이였지만 당시 들어왔던 API 요청 자체는 믿기 힘들정도의 숫자가 들어오고 있었죠.
정말 오랜만에, 서버를 종료하고 잠시 사이트 운영을 중단했습니다.
약 10분 후, 다시 사이트를 재개했고 트래픽이 정상적으로 돌아왔습니다. 저도 놀라울 정도였는데, 더이상의 분석은 힘들고 제 실수 일수도 있기 때문에 DDOS 공격이다 라고 단정짓기는 어려웠습니다.
대규모 트래픽이 감지되었다.. 정도가 제가 할수 있는 최대였구요.
여튼, 해당 대규모 트래픽이 감지된 이후, 미뤄두었던 여러 작업들을 한번에 진행했습니다. 그리고 다른 개발자분께서 해주신 서버사이드 캐싱인 Redis, 그리고 In-Memory Cache 도입을 추천해 주셨고 이와 같이 진행했죠.
프론트, 백엔드 모든 구간에 캐싱
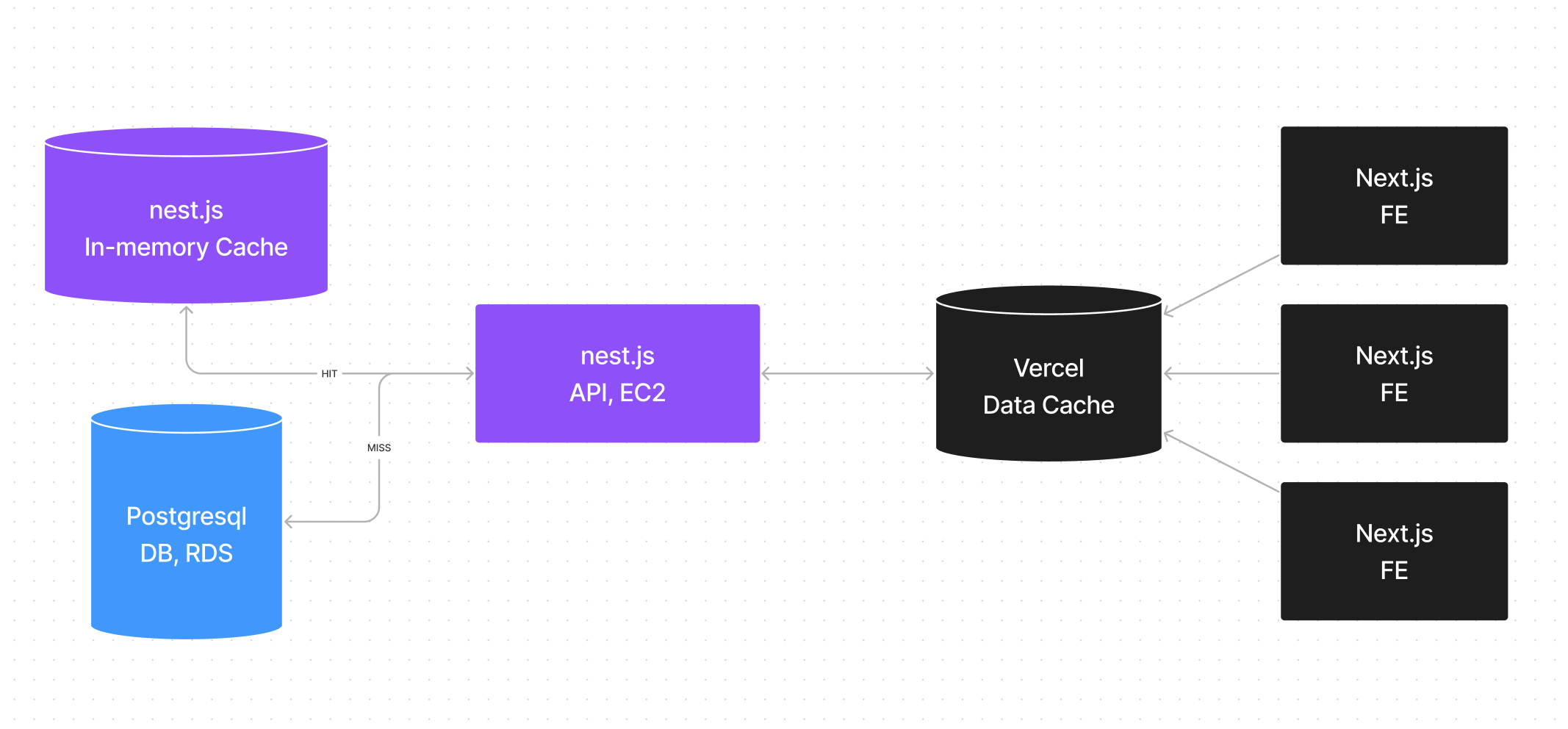
이날 이후로 현재까지, 이제 FE, BE 모든 구간에 캐시를 도입해 RDS로 가는 연산 요청을 최대한 줄이기 위해 노력하고 있습니다. 이 노력은 꽤나 성공적이였던 것이 3월 6일 부터 RDS의 지표가 눈에 띄게 개선되기 시작했거든요!
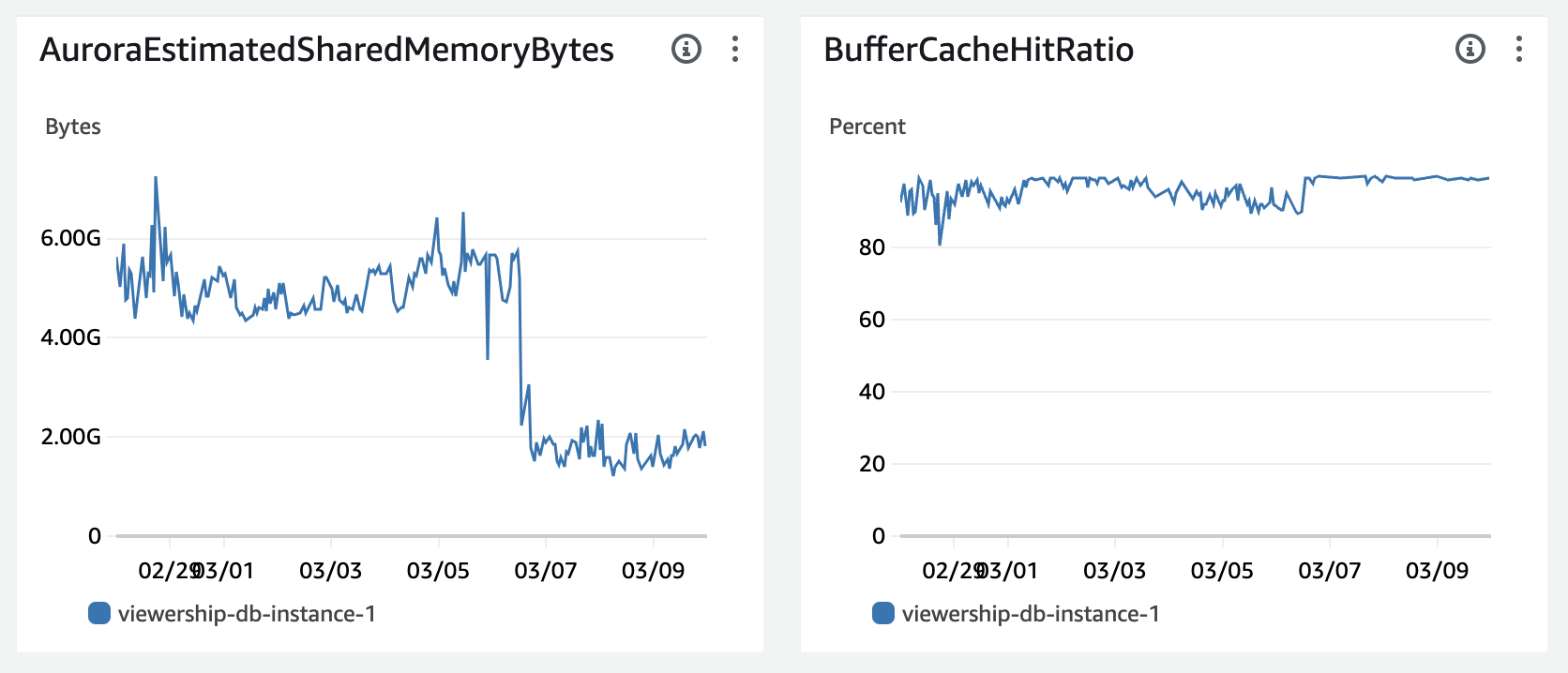
100%를 유지하지 못하던 버퍼 캐시 히트율 ( 메모리에 저장된 데이터를 사용하는 비율 )이 다시 100%대를 유지하기 시작했고, 실제 사용되는 메모리 양도 획기적으로 줄일수 있었습니다.
이와 더불어 크롤링 코드를 개선하고 몇몇 코드를 최적화하기도 했죠.
2023년 3월 15일. 오늘
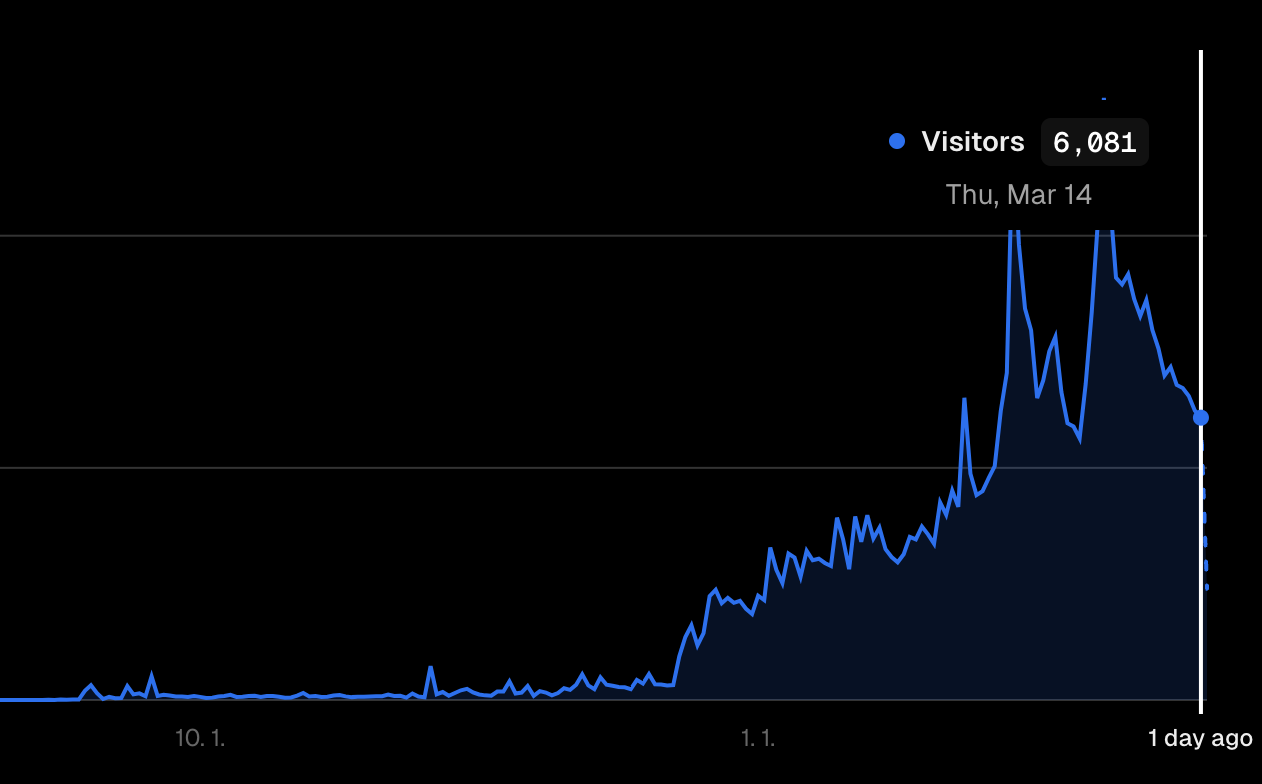
이제 피크치를 찍던 시기는 지나 다시 제자리를 찾아가는 모양새이지만, 인터넷방송 업계의 특성상 또다시 새로운 이벤트가 열리면 예상치 못한 트래픽이 찾아올수 있을것이라 예상하고 있습니다.
소프트콘 뷰어십은 현재 아프리카와 치지직의 상위 각 3,000명의 스트리밍 데이터를 수집하고 있으며 가장 시청자수가 많은 시간 기준 치지직은 3명, 아프리카는 4명 이상의 크리에이터의 방송을 수집하고 있다는 결론이 나옵니다.
총 600명씩 수집하던 사이트는, 이제 6,000명씩 수집하는 현재. 언젠가 인방 전체인 10,000명씩 수집할수 있는 범위로 확장하여 사이트의 데이터가 인기있는 방송인들 뿐만 아니라 이제 막 인터넷방송을 시작하는 분들께도 도움이 될수 있도록 노력하고자 합니다.
앞으로의 과제
이제 사이트가 본격적으로 시작된 10월 1일로부터 약 5개월 하고 보름입니다.
사이트의 데이터를 더 안정적으로 다룰수 있는 능력을 키우고 있고, 사용자들에게 더욱 필요한 데이터를 제공하기 위해 더 다듬어 보려고 합니다.
제한적인 범위의 검색을 넘어 이제 조금 더 큰 범위를 표시하고 여느 사이트에 뒤지지 않는 처리 능력으로 모든 사람이 이용할 수 있는 서비스를 제공하고자 합니다.
물론 걸리는 일도 많고, 어려운 일도 많겠지만
언제 또 이런걸 해보겠어요?
😗
생각
사이트를 운영하다 보니 정말 다양한 카테고리의 많은 분들을 만날 기회를 얻어 커피챗 혹은 다양한 제안들을 받았습니다.
너무나도 감사하고, 고마운 이야기들이였고 정말 대단하신 괴물같은 분들도 많으시더라구요.
이런 분들을 만나면서 들었던 한가지 생각은 아직 제가 너무 부족하고 배워야 할 점이 더 많다는 생각이 들더라구요. 이번 글에서 썼던 내용들 말고도 어렵고 힘들었던 점은 한두개가 아니였습니다.
하지만, 제가 부족하다고 생각하기 때문에 더욱 성장할수 있다고 생각합니다. 단순히 말로만 부족하다 이야기하는 것이 아닌 진짜 부족하다 생각하기 때문에 더 많은것을 빠르게 받아들이는 것에 거리낌이 없다고 생각했거든요,,
이 생각은 앞으로도 쭈욱 간직하고 나아가려고 합니다.
전 한 분야에 특징이 있는 개발자라기 보다, 하고싶은걸 만들고 문제가 생기면 해결하기 위해 노력하는 개발자이기에 디자인, 프론트, 서버, DB 등 다양한 분야의 전문가들에 비해 지식의 수준이 부족할 수 밖에 없을것이라고 생각합니다.
그렇기에 더 많이 듣고, 받아들이고, 이야기를 나눠 과거에 도태되지 않도록 노력하고자 합니다. 이 포인트는 제가 소프트콘 뷰어십을 운영하면서 느꼈던 가장 중요한 포인트였기도 했습니다.
마무리
소프트콘 뷰어십은 이제 더 많은 다양한 데이터를 이용해 더욱 보기 쉬운 정보로 가공하기 위해 노력하려고 합니다. 컨텐츠도 주기적으로 만들고, velog 글도 주기적으로 작성하면서 말이죠.
적당히 만들어서 포트폴리오로 사용할 프로젝트가 이렇게 커질것이라고는 예상하지 못했지만, 이왕 커진김에 좀더 해보려고 합니다!
언제또.. 이런걸 해보겠어요? 😗
지금까지 긴글 읽어주셔서 감사합니다.
다음 글은 더 발전된 모습으로 찾아뵙겠습니다!


하나의 프로덕트를 성공적으로 이끌어가는 모습이 굉장히 인상 깊습니다. 앞으로도 좋은 개발을 지속적으로 해주셨으면 좋겠습니다!