
Resource-Aware Dynamic Scheduling for Tasks with Deadline Constraints on Edge Computing Systems
IEEE TRANSACTIONS ON CLOUD COMPUTING
Wenbiao Cao, Xiaoyong Tang, Tan Deng, Ronghui Cao, and Keqin Li
https://ieeexplore.ieee.org/abstract/document/11143954
연구 배경
AIoT 발전으로 MEC(Multi-access Edge Computing) 중요성 증대
AIoT와 IoT의 발전으로 데이터 소스와 가까운 위치에서 분산 연산 수요 및 지연 민감 서비스 급증
엣지 컴퓨팅은 코어 혼잡 완화 및 QoS 향상에 효과적
그러나, 엣지 환경은 다음과 같은 한계 존재
- 자원 이질성(Heterogeneity)
- 자원 경쟁(Resource competition)
- 마감시간 제약(Deadline Constraints)
핵심 과제 : 제한된 이질적 리소스와 동적 요구사항의 충돌
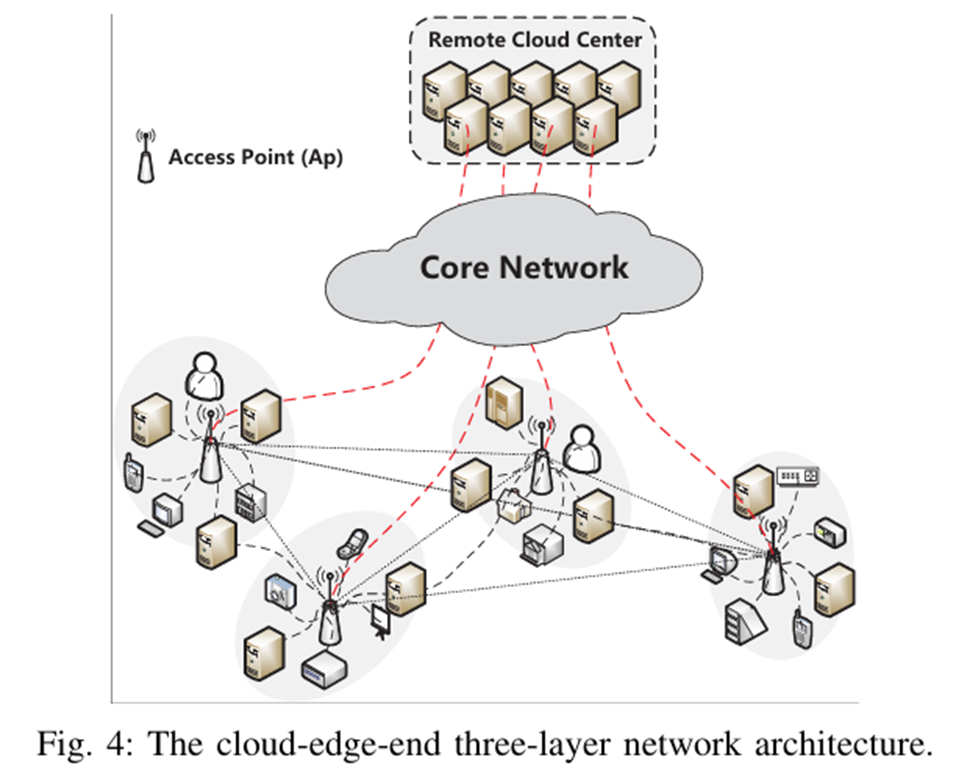
해당 논문의 Edge-Node에 대한 정의
Firstly, edge nodes have obvious heterogeneity in terms of resource type, performance, and architecture.
Secondly, resource competition is widely present in edge networks.
Such as gateways(access points), local servers, small data centers, and even high-performance terminal devices are geographically distributed.
관련 연구로 보는 주요 문제점
Task Dispatching and Scheduling in Edge Computing
대부분 정적인 태스크 처리 시간을 가정하며, 동적 자원 변화 및 경쟁 상황은 충분히 고려하지 못함
Heterogeneous Scheduling with Deadline Constraints
대부분 정적 자원 할당(static allocation) 기반이며, 온라인 자원 경쟁(online resource competition) 은 다루지 않음
Resource-aware Dynamic Task Scheduling
대부분 오프라인 모델에 의존하고 있으며, 이는 실제 동적 변화를 시의적절하게 반영할 수 없음
따라서 자원 인식(Resource-aware) 관점에서 동적 스케줄링 알고리즘을 제안하여
데드라인을 만족하면서 시스템 자원 효율을 높이고자 함
핵심 아이디어
RATGS(Resource-Aware Task Grouping Scheduling Strategy)
제한된 리소스로 최대한 많은 요청을 완료하는 것이 목표
데드라인 제약이 있는 태스크의 효과적인 스케줄링에 초점
- Task Regrouping & Priority Response (Algorithm 1)
- Resource-aware Greedy Scheduling (Algorithm 2)
- Task Adjusting (DI/HRI/MRR, Algorithm 3)
- Rescheduling (Algorithm 4)
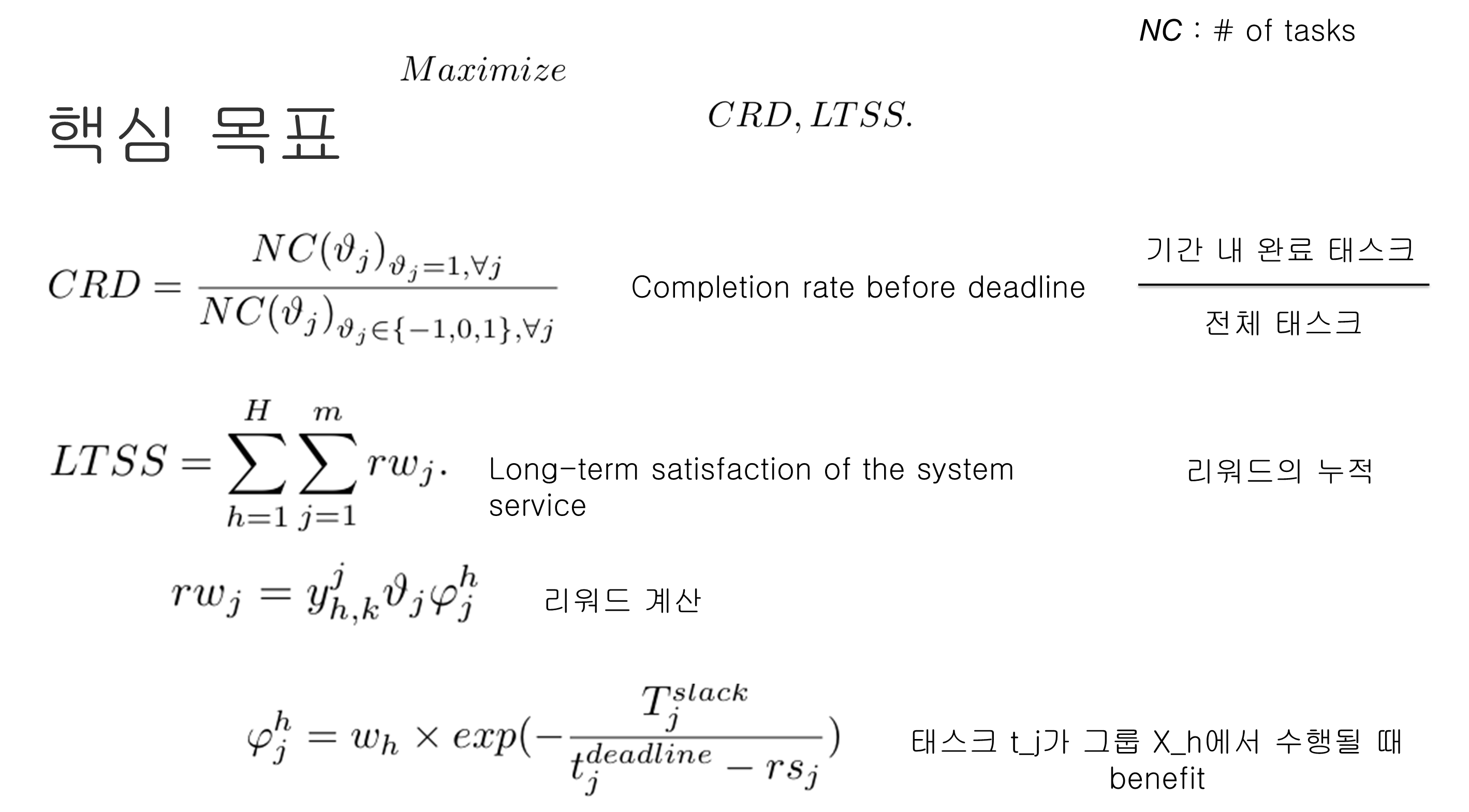
핵심 목표
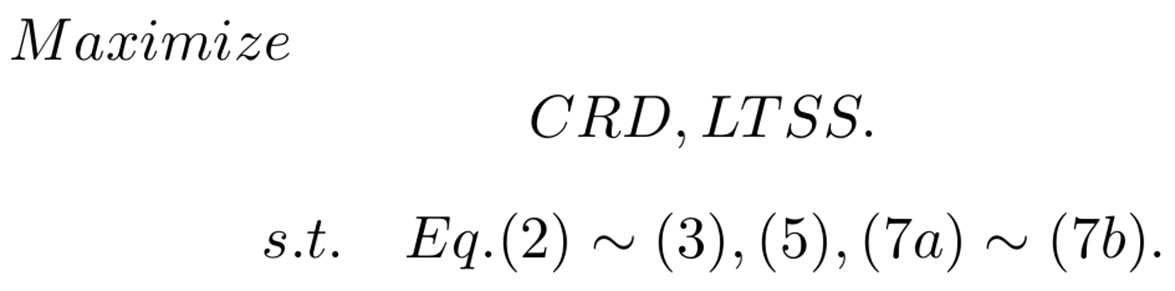
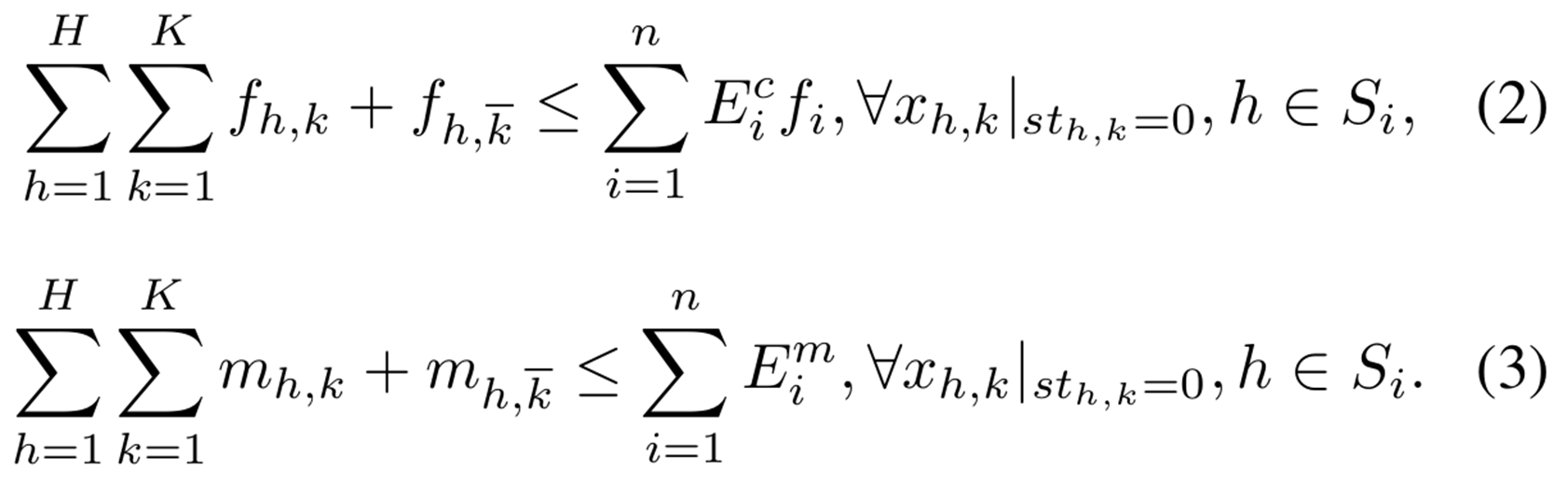
식(2) => 연산 능력 가용 검사
식(3) => 메모리 가용 검사
현재 사용중인 {컴퓨팅 파워, 메모리} + 할당하려는 CU의 {컴퓨팅 파워, 메모리} <= 엣지 노드의 총 {컴퓨팅 파워, 메모리} 용량
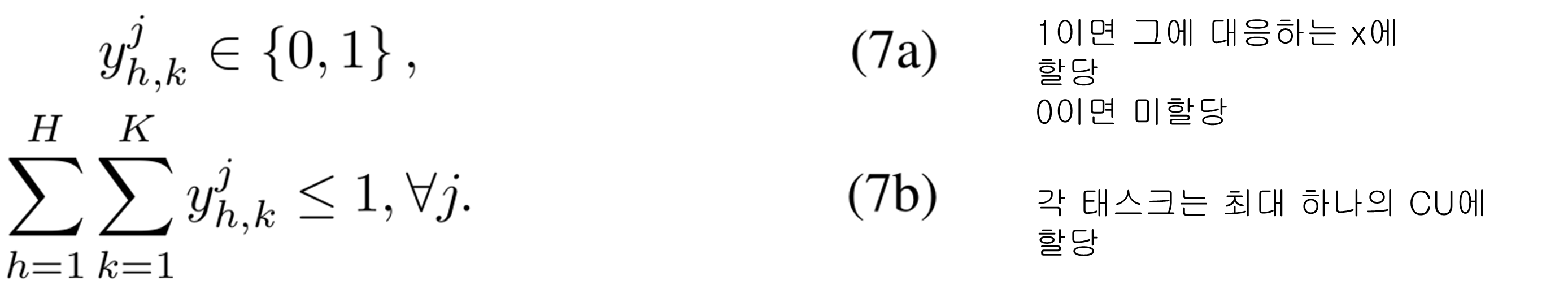


Algorithm
Regrouping의 필요성
초기에는 태스크들이 도착 시간(Arrival Time) 기준으로 단순 저장되기 때문에, 서비스 유형과 자원 요구가 뒤섞여 스케줄링 효율이 저하
-> 태스크를 서비스 유형(Service Type) 및 긴급도(Urgency) 기준으로 Regrouping
Algorithm 1

1. 태스크를 도착 시간에 따라 타이밍 그룹으로 분할
2. 각 타이밍 그룹의 태스크를 서비스 타입별 컴퓨터 그룹(X_h)에 매핑
3. 그 그룹의 기존 대기열의 각 태스크의 우선순위 및 평균 처리시간 계산
4. 우선순위 값에 따라 새 대기열 생성
5. 해당 서비스가 엣지에서 처리될 수 없으면 리모트 클라우드로 전송
Algorithm 2

즉시 가용 리소스가 있는 경우 (line 1~9)
- 가장 빠른 완료 시간을 가진 노드에 그리디 스케줄링 (line8~9)
리소스가 가득 찬 경우 (line 10~27)
- 각 슬롯 노드에 할당하여 EFT(Earliest Finish Time) 계산 (line 11~13)
데드라인 미충족 시 (line 14~27)
- 태스크 조정 호출 (line18~21)
- 실행가능한 솔루션이 없으면 리모트 클라우드로 스케줄링 (line22~25)
Algorithm 3

1. Direct Insertion(DI) (line 1~6)
새로운 태스크를 기존 실행 큐(PreScheme) 중간에 삽입하여 데드라인을 만족할 수 있는 위치를 찾음
특징 : 파편화된 리소스 활용하여 자원 낭비 감소
효과 : 데드라인 만족률 증가
2. Highest Reward Insertion(HRI) (line 7~15)
단순히 데드라인만 보는게 아닌 LTSS가 더 커지는 방향으로 태스크를 선택/재배치
특징 : Slack time을 활용하여 기다리면 더 가치있는 태스크를 살림
효과 : 전체 시스템 효용 극대화
3. Maximum Reward Replacement(MRR) (line 16~20)
가장 적은 재배치로 데드라인을 만족시키는 대안 탐색
특징 : 큰 구조 변경 없이 효율성 확보
효과 : 안정적이고 현실적인 조정 가능
Algorithm 4
Deadline 위반 태스크를 가장 빠른 EFT 노드로 재할당하여 CRD를 향상 시키는 것을 목표

가용 노드 집합 (AvaNodes) 생성 및 EFT 평가 (line 1~6)
EFT 최소 노드 선정 (line 7~8)
Deadline이내면 노드 갱신 및 우선순위 계산 (line 9~13)
충족 불가 시 리모트 클라우드로 전송 (line 14~17)
실험 환경
워크로드
실제 애플리케이션
이미지 처리, ALU 논리 연산, 부동소수점 연산, 얼굴 매칭 등
Python으로 작성된 여러 프로그램 사용
시뮬레이션 데이터셋
알리바바 클라우드 실제 트레이스 데이터 활용
밀도 데이터셋 : 8개 서브셋 (밀도 1~8), 각 약 10,000개 태스크
분포 데이터셋 : 3개 서브셋 (다양한 분포), 각 약 25,000개 태스크
각 태스크 디스패처는 서로 다른 종류의 애플리케이션을 실행
각 디스패처는 50~100ms 간격으로 0~1개의 태스크를 오프로딩
각 요청은 입력 메타데이터, 예상 마감시간 (Deadline),
긴급 여부(Expedited Flag)에 대한 정보 포함
서비스 인스턴스는 모두 pre-warmed 상태로 설정
평가지표
CRD(Completion Rate before Deadline)
LTSS(Long-Term Satisfaction of System Service)
ACT(Average Completion Time)
Resource Utilization + RU Efficiency
비교 대상
- Dedas : 노드의 스케줄을 순차적으로 순회하여 작업에 적합한 삽입 위치 탐색 삽입 불가 시, 총 완료 시간을 비용 요소로 고려하여 최적의 스케줄을 얻기 위해 작업을 교체
- RTH2S : 노드를 계층화하여 3단계 우선순위 큐와 EDF(Earliest Deadline First) 방식으로 스케줄링
- LSPT (LeastLoad + SRPT) : 부하가 가장 낮은 노드에 태스크를 보내고, 남은 처리시간이 짧은 순으로 실행
- LEDF (LeastLoad + EDF) : 부하 최소 + 가장 빠른 마감시간 순서로 태스크 할당
- SF (Self + FCFS) : 태스크가 스스로 가장 빠른 완료시간을 예측하여 FCFS로 실행
실험 결과
테스트베드
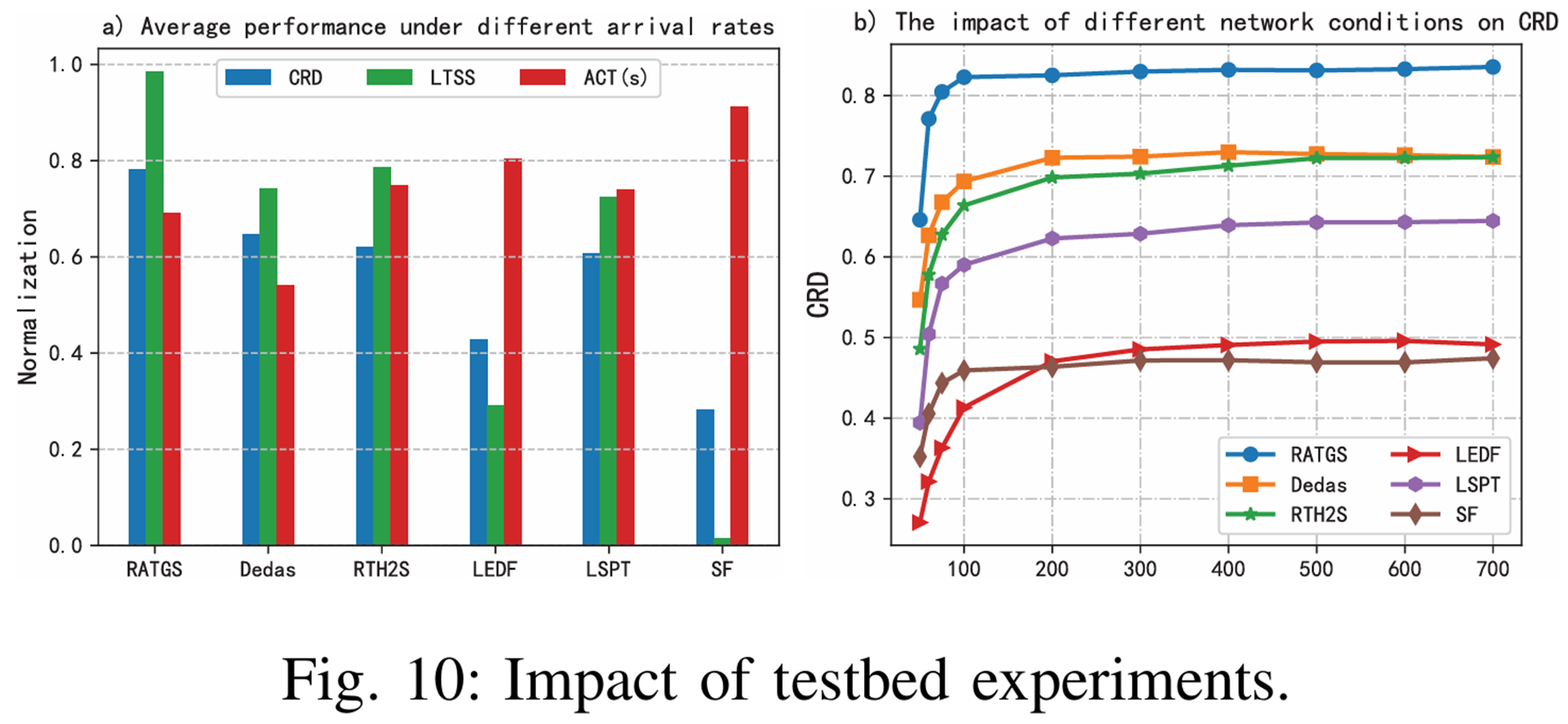

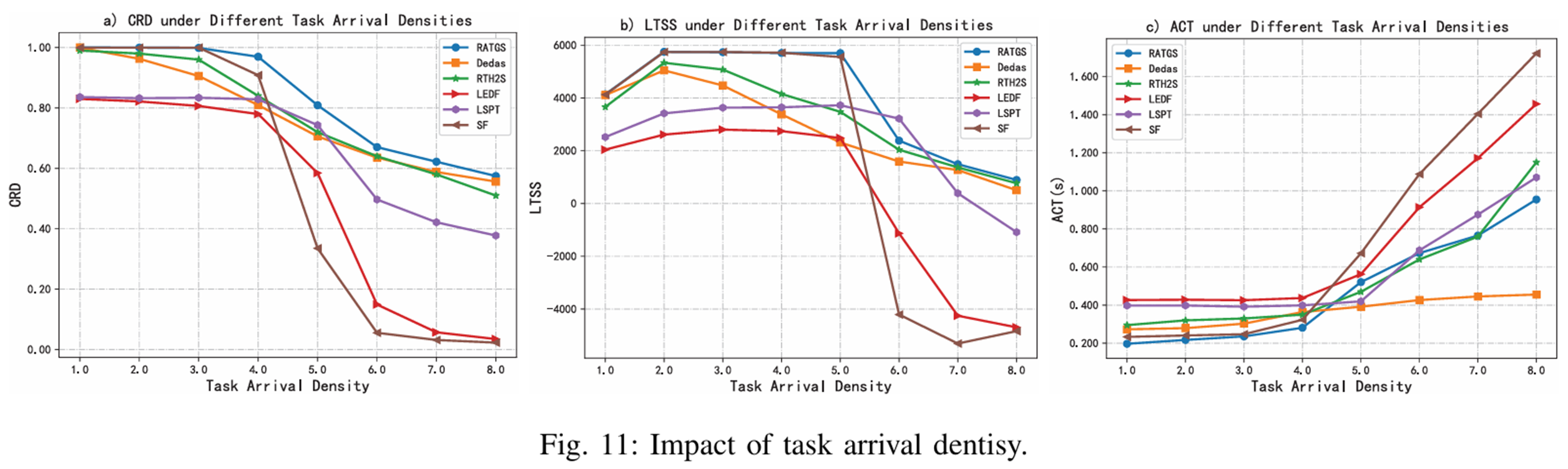
태스크 도착 밀도

태스크 분포
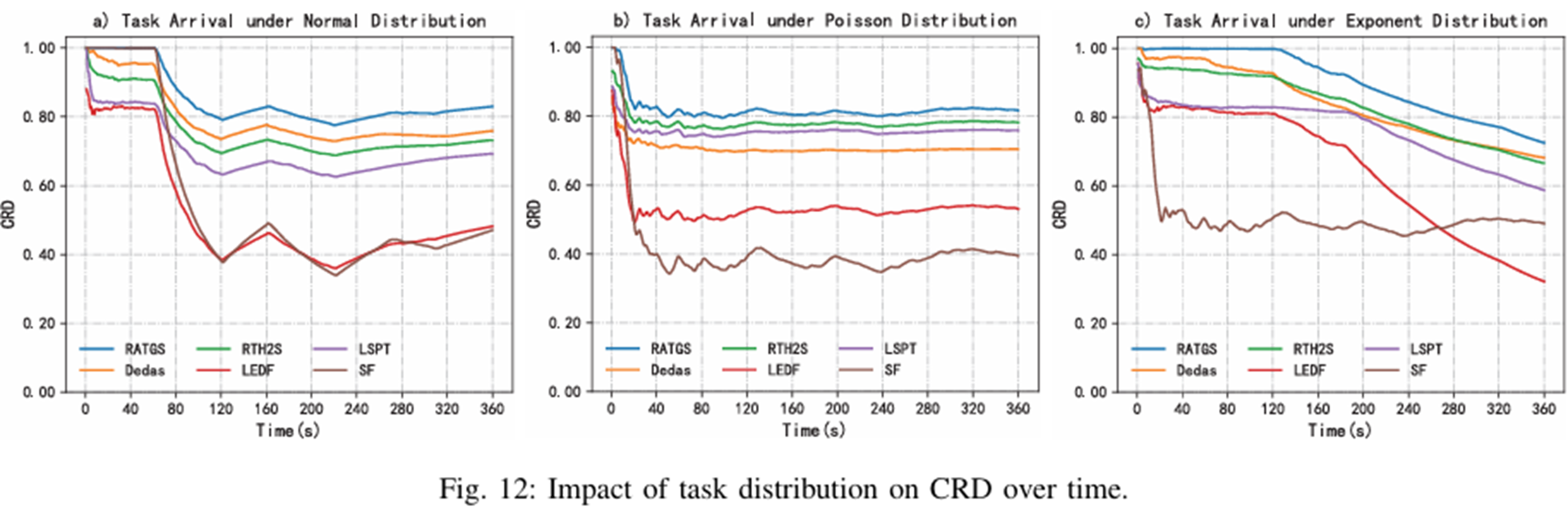
태스크가어떤 분포로 도착하여도 RATGS가 CRD가 가장 높은 것을 확인 가능
태스크 도착 불확실성을 반영하기 위한 시뮬레이션
컴퓨터 유닛 수에 따른 데드라인 미스율
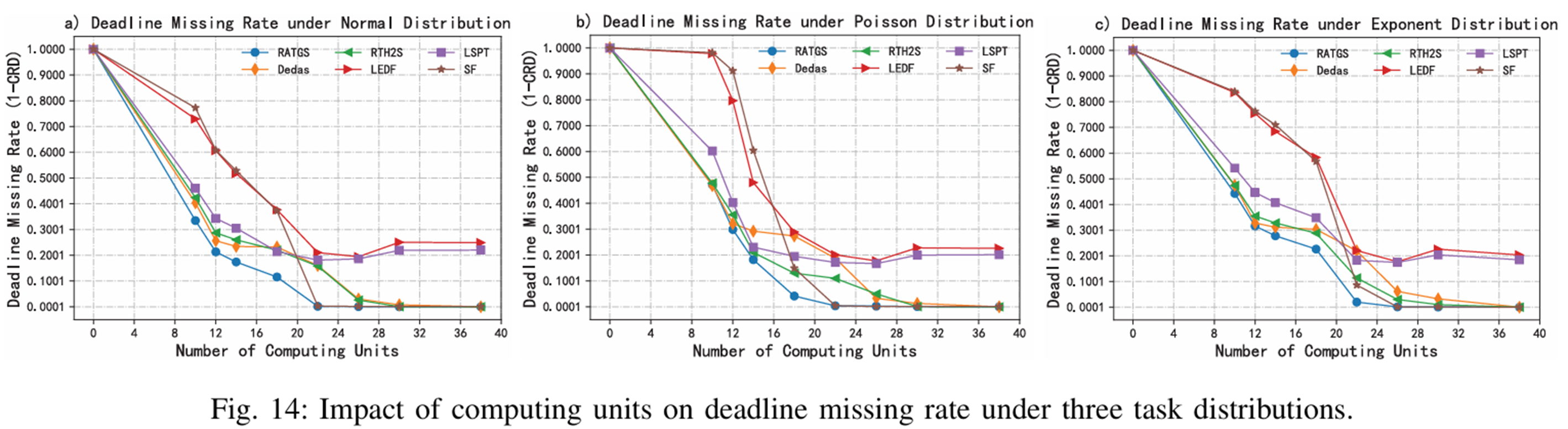
RATGS : 22 CU에서 99.9% 완료 (가장 빠름)
다른 전략 : 더 많은 CU 필요
LSPT/LEDF : CU증가해도 ~80% 완료
즉, RATGS는 자원이 부족한 상황일수록 성능 우위 확인 가능
컴퓨터 유닛 수에 따른 LTSS
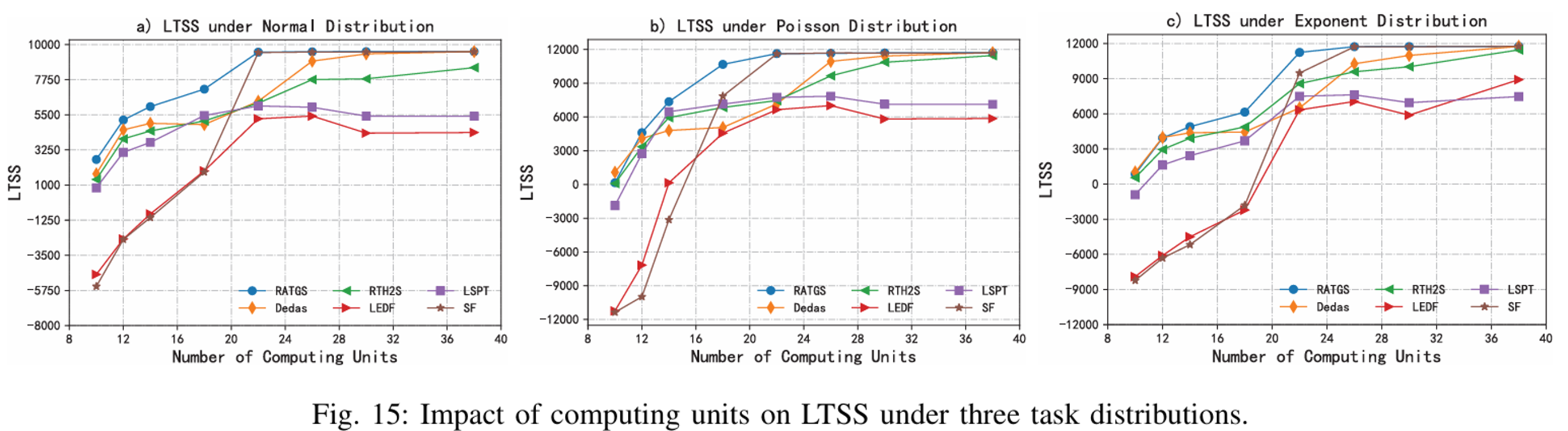
컴퓨팅 유닛 수가 30에 도달하면 각 스케줄링 전략의 성능이 가장 좋아지는 경향이 있지만,
22 미만이면 RATGS의 성능이 LTSS 지표에서 모든 전략보다 우수
컴퓨터 유닛 수에 따른 ACT
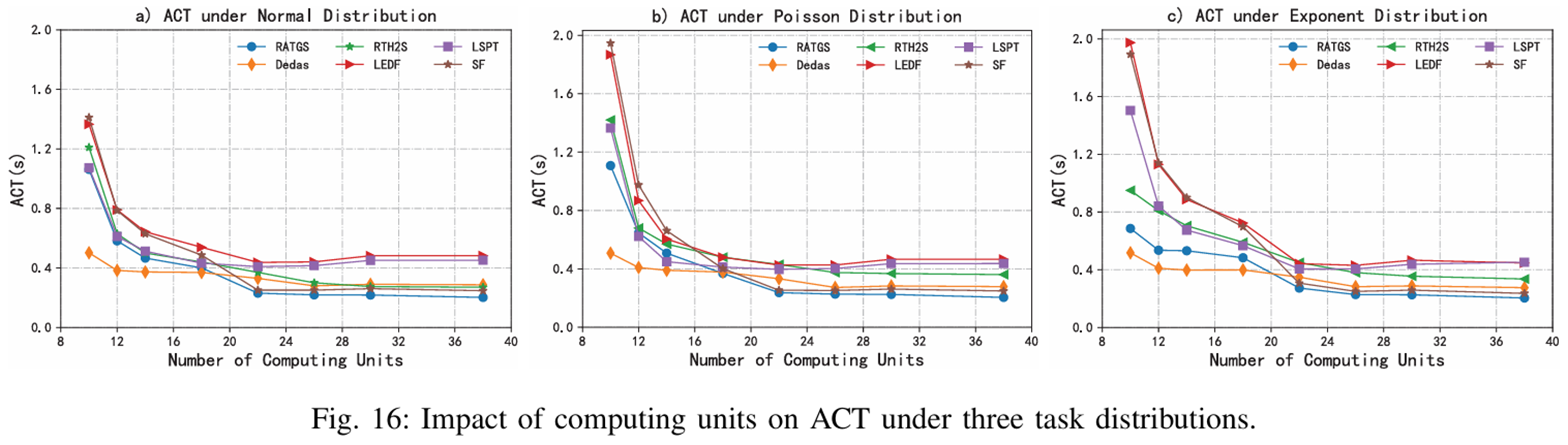
컴퓨팅 유닛 수가 30을 초과하고 점진적으로 증가함에 따라 RATGS는 ACT에서 Dedas보다 약간 더 나은 성능을 보이기 시작
컴퓨팅 유닛 수가 증가함에 따라 최적의 스케줄링을 달성하기 위한 작업 조정 공간과 선택 사항이 더 넓어지기 때문
리소스 활용
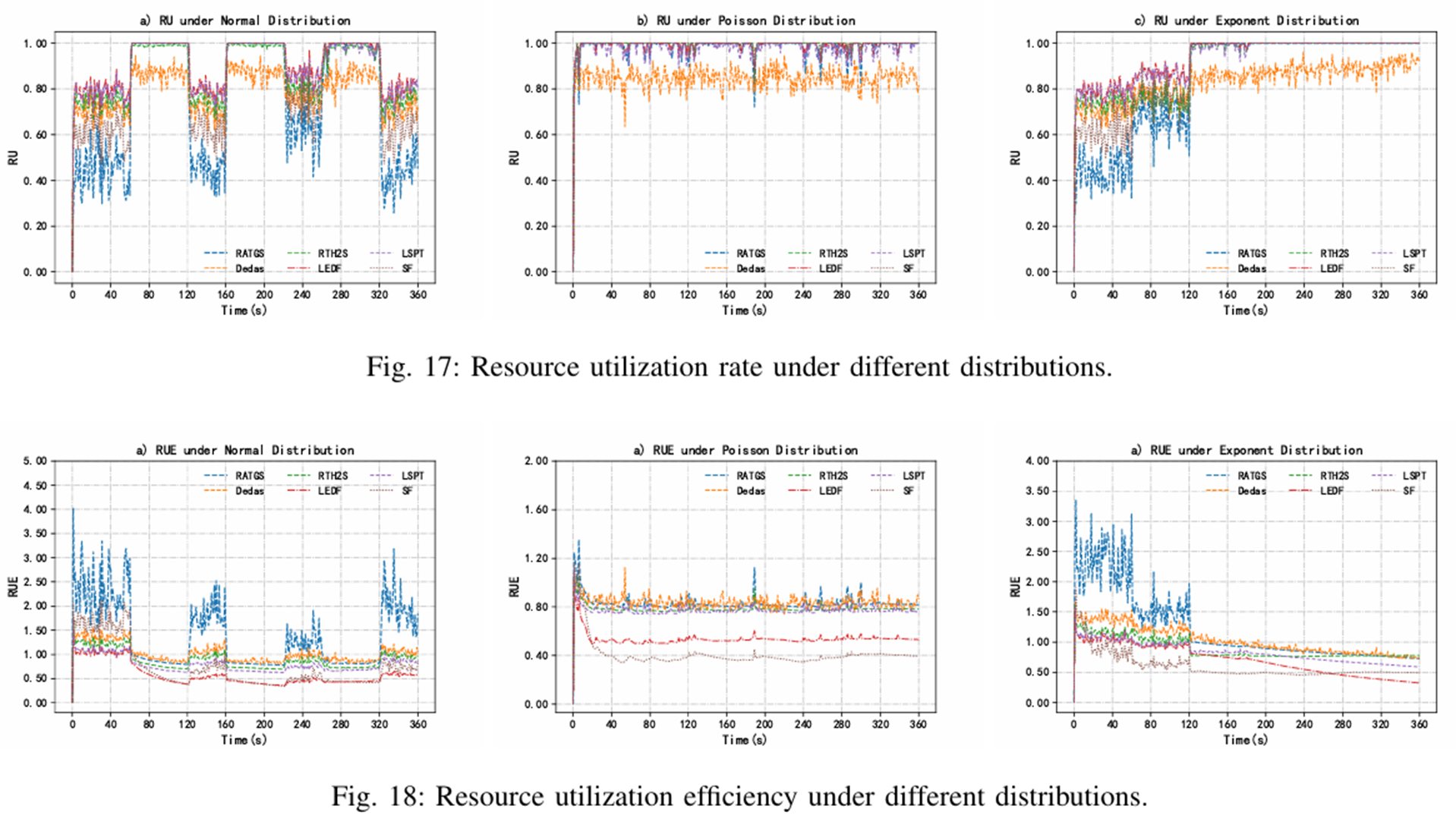
RU(Resource Utilization)
LSPT/LEDF: 평균 80% 이상 (최고) ->로드밸런싱 계열
RATGS: 고밀도 시 높음, 저밀도 시 낮음
RUE (RU Efficiency = CRD/RU)
RATGS: 대조적 상황에서 최고 RUE
적은 리소스로 더 많은 태스크 완료
핵심발견
엣지 환경과 같은 자원이 제한된 환경에선 RUE가 더 중요한 지표
단순 활용보다 활용 효율성이 중요
RATGS는 제한된 리소스를 가장 효율적으로 활용
연구의 핵심 성과
- 이질적 자원 환경을 현실적으로 모델링
- 노드별 성능, 메모리, 대역폭 등을 구체적으로 고려 - 다항시간 복잡도의 휴리스틱 솔루션 제시
- NP-hard 문제를 O(n²) 내에서 근사적으로 해결 - 마감시간 제약과 자원 경쟁을 동시에 고려한 스케줄링 정식화
- LTSS와 CRD를 통합적으로 최적화 - 단순한 RU보다 RUE의 성능지표로서의 가치
- 자원이 한정된 환경에서 RUE가 성능지표로 더 적합한 것을 확인
연구의 한계점 및 향후 연구
- 태스크 간 종속성 미고려
- 에너지 소비와 콜드 스타트로 인한 서비스 지연 무시
향후 연구
- 태스크 간 선후 관계를 반영한 스케줄링 모델
- 에너지 효율성 고려
