B-Tree
B-Tree는 이진 탐색 트리의 일반화된 형태로, 하나의 노드가 두 개 이상의 자식 노드를 가질 수 있다.
핵심 특징
| 항목 | 설명 |
|---|---|
| 다진 트리 (m-ary Tree) | 한 노드가 최대 M개의 자식을 가질 수 있음 |
| 정렬된 키 저장 | 모든 노드에 키(key)가 정렬된 상태로 저장됨 |
| 균형 유지 | 모든 리프 노드가 같은 깊이에 위치 (균형 트리) |
| 디스크 친화적 | 노드 하나가 페이지 하나 (디스크 I/O 최적화) |
구조
노드의 구성
- 하나의 노드는 여러 개의 키와 포인터(자식 링크)를 가진다.
- 키는 정렬된 상태로 유지된다.
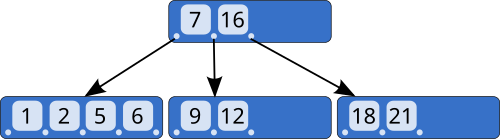
사진은 위키트리에서 가져왔습니다.
연산
검색
- 루트부터 시작해서 각 노드에서 키 범위를 확인해 자식 노드로 이동한다.
- 리프노드까지 탐색한다.(트리의 깊이는 작기 때문에 빠르다)
삽입
- 리프노드에 삽입.
- 노드가 넘치면 분할하여 부모 노드에 키를 전파한다.
- 분할을 반복하면 트리의 높이가 1 증가한다.
삭제
- 키를 삭제하고, 필요한 경우 병합 또는 빌림 처리.
- 마찬가지로 리밸런싱은 상위 노드까지 영향을 줄 수 있다.
사용 이유
검색, 삽입, 삭제가 빠르다
- 키와 데이터를 모든 노드에 저장하므로, 검색 시 리프까지 안 내려가도 될 수 있다.
- 삽입/삭제 시에도 균형을 유지하면서 효율적이다.
데이터 접근 경로가 짧다
- 중간 노드에 데이터가 있어서 탐색 중간에 결과를 얻을 수 있다.
- 메모리 기반 데이터 구조에서는 오히려 B-Tree가 B+Tree보다 빠를 수 있다.
메모리 기반 구조에 적합하다
디스크 접근 비용보다 비교 연산이 더 중요한 경우에는 메모리 기반 구조에 더 알맞다.
단점
- 범위 검색에는 상대적으로 비효율적이다.
- 중간 노드에 데이터가 있어 전체 데이터를 순차적으로 탐색하려면 트리 전체를 순회해야 한다.
B+ Tree
B- Tree의 확장 버전으로, 검색과 범위 조회에 특화된 다진 균형 트리이다.
구조
아래 이미지는 위키트리에서 가져왔습니다.
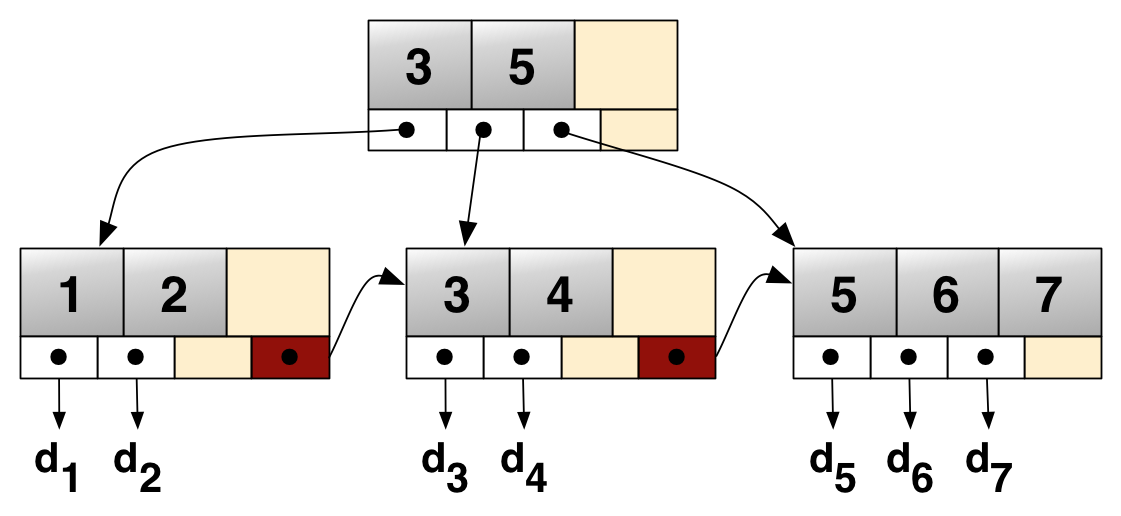
리프노드는 오른쪽으로 연결되어 범위 검색이 매우 빠르다.
내부 노드 (Internal Node)
- 오직 키와 자식 포인터만 가진다.
- 데이터는 없다.
리프 노드 (Leaf Node)
- 실제 데이터가 저장된다.
- 키들이 정렬되어 있고, 오른쪽 노드를 가리키는 포인터를 가진다.
연산
검색
- 내부 노드를 따라 내려가서 리프노드에 도달한다. 그리고 리프노드에서 데이터를 검색한다.
- 최대 O(log n)시간.
삽입
- 알맞은 리프노드에 키 삽입.
- 리프노드가 초과되면 분할.
- 중간 키는 부모 노드로 승격. 만약 내부 노드가 가득 차면 재귀적으로 분할한다.
삭제
- 리프노드에서 삭제.
- 노드 크기가 너무 작아지면 병합 또는 키 이동.
데이터베이스에서 쓰이는 이유
인덱스 구조 최적화
- 리프 노드에만 데이터를 저장한다.
- 내부 노드는 오직 키만 저장하여 더 많은 키를 저장할 수 있다.
- 디스크 한 블럭에 더 많은 키를 배치하여 트리의 높이를 낮추고 탐색 속도를 증가시킨다.
범위 검색에 매우 강력
- 리프노드끼리 포인터로 연결됨(LinkedList 형태)
BETWEEN등 순차적 탐색이 매우 빠르다.
정렬된 전체 스캔 가능
- 테이블 풀 스캔이 필요할 때도 인덱스만 따라가면 된다.
- 클러스터형 인덱스 구성에 매우 적합하다.
정해진 블록 크기에 최적화
- 디스크는 블럭 단위로 읽고 쓴다.
- 같은 디스크 공간에서 더 많은 키를 다룰 수 있어 검색 시 디스크를 덜 읽어도 되는 구조이다.
정리
시간 복잡도
| 연산 | B-Tree | B+ Tree |
|---|---|---|
| 검색 | O(log n) | O(log n) |
| 삽입 | O(log n) | O(log n) |
| 삭제 | O(log n) | O(log n) |

백엔드 개발자를 목표로 공부하는 대학생