ㅇ 교수 : KAIST 차미영 교수
ㅇ 학습 목표
본 모듈은 본격적인 AI기술에 대한 이해에 앞서 데이터 과학자로서의 기본적 소양을 기르기 위한 과정입니다.
따라서 인공지능 기술 도입에 앞서 데이터 과학자로서 그리고 제도적으로 윤리적으로 어떠한 자세를 가져야 하는지 이해하고,
인공지능 기술로 어떻게 문제를 해결할 수 있는지 학습합니다. Part 1. 데이터 분석과 AI학습에서 유의할 점
데이터의 시대
데이터를 잘 해석하고 있는가?
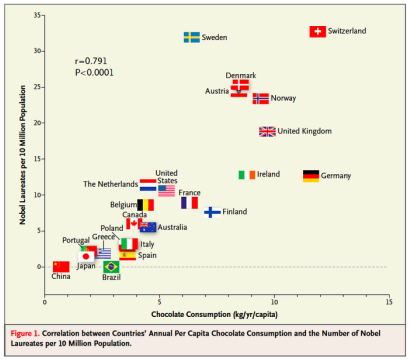 초콜렛을 많이 먹으면 노벨상을 탄다? -> 상관관계와 인과관계를 혼동하지 말아야 함
초콜렛을 많이 먹으면 노벨상을 탄다? -> 상관관계와 인과관계를 혼동하지 말아야 함
상관관계(Correlation)
: 두 변수 간의 통계적 관계, 한 변수가 다른 변수의 변화와 관련이 있다는 것
: 0에 가까울수록 약하고, -1 or 1에 가까울수록 강함
: 인과관계를 의미하지 x, 우연일 수도 있음
인과관계(Causation)
: 한 변수가 다른 변수를 직접적으로 원인으로 하는 관계. 한 변수의 변화가 다른 변수의 변화를 일으킴
데이터 전처리와 분석 방법은 적절한가?
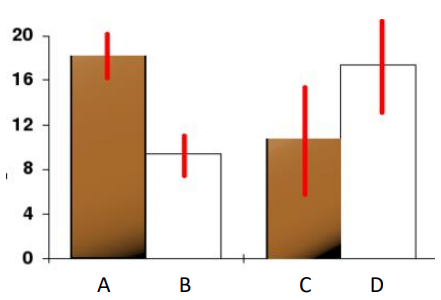
-
error bar 반드시 추가해야 함
(C,D는 표준편차가 겹치기 때문에 유의미한 결과라고 할 수 없기 때문)error bar
: 하나의 실험 결과값에 대해 하나의 표준편차의 범위를 나타냄 -
적합한 통계 테스트 찾기
-
아웃라이어 제거하기
-
데이터 표준화하기
-
EDA(Exploratory data analysis)에 충분한 시간을 보내기
😊 데이터 분석을 하면 할수록 데이터 정제 과정이 얼마나 중요한지 깨닫게 되지
학습에 쓰는 데이터는 충분한가?
일반적으로 우리는 밀리언(million) 스케일이라고 해서 100만 개의 데이터를 요구하지만, 이는 모델 별로 다를 수 있다는 것
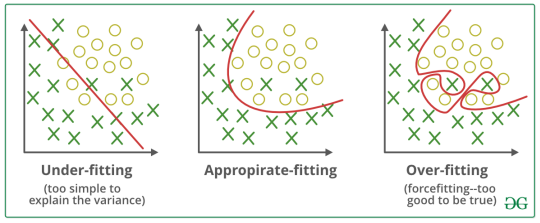
- 학습ㄷ의 결과가 적절한 수준인지에 대한 인식이 있어야 함
- 학습(training) 데이터는 테스트(testing) 데이터와 달라야 함
Black box algorithm
AI 모델의 결정에 설명력 더하기
실제 AI 모델은 input을 넣으면 output만을 알려주기 때문에 그 과정이 정확히 어떻게 이루어지는지 알 수 없다. (단점)
그래서 블랙박스 모델이라고 불리는데, 사용자가 output을 납득하기 위해서는 '설명력'이 매우 중요해진다.

- high risk 결정에서 설명력은 정확도 만큼이나 중요해짐
- Saliency map, SHAP와 같이 post-hoc explainability를 제공하는 기술이 생김
post-hoc explainability
: 머신 러닝 모델의 예측을 해석하고 설명하는 기술을 가리키는 용어
Saliency map
: 모델이 어떤 입력 특성에 주목하고 있는지를 시각적으로 나타내는 기술
: 주로 이미지 분류 모델에서 사용(특정 클래스를 분류할 때 어떤 부분에 주의를 기울이는지)
SHAP
: Shapley 값을 사용하여 모델 예측의 각 특성(feature)이 예측에 얼마나 기여하는지를 설명하는 알고리즘
: Shapley 값은 합리적인 방법으로 특성의 중요성을 할당하는 계산론적 게임 이론의 개념
학습 결과가 바뀔 수 있는 위험성

인간과 다르게 알고리즘은 pixel하나만 바뀌어도 학습 결과를 아예 다르게 출력할 수 있어
Part 2. AI Ethics
인간의 창조적 활동 영역으로 들어온 인공지능
AI에 의한 발명과 저작 등에 대한 법제 정비가 필요한 시점이고
AI에 대한 경계와 규제의 선택은 인류에 대한 재정의라고 해석할 수 있음
Part 3. 세계적인 데이터 과학자가 되는 방법
 강의 듣다가 급 반성 모드
강의 듣다가 급 반성 모드
내가 변화하지 않으면서 화려한 미래를 기대하는건 참 어리석은 일이었다.
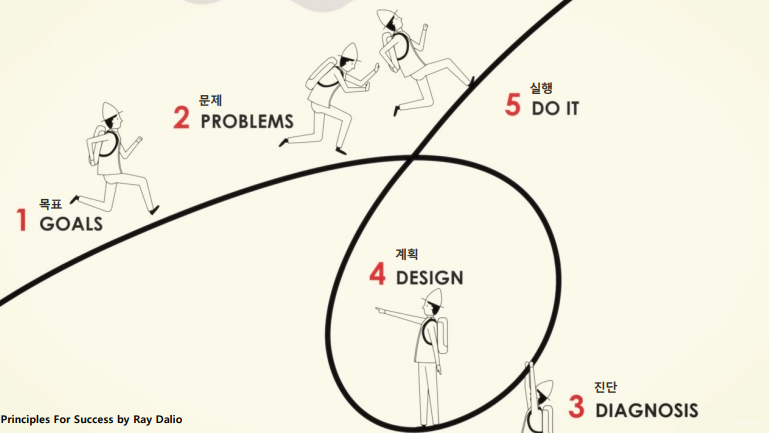 참 실패를 현명하게 겪는건 쉽지 않다.
참 실패를 현명하게 겪는건 쉽지 않다.
인생은 실패에 대한 태도로 결정이 난다고 하는데 나는 누구보다 이 부분에 취약했다고 생각한다.
문제에 봉착했을 때, 이를 진단했지만 적극적으로 해결책을 세우고 실천하는 노력이 부족했다.
그저 매달려 있는 나를 질책하고 원망하고 동정하기에 바빴을 뿐
꼬인 지점이 많이 있더라도 우상향 그래프를 완성하기 위해서는 해결하려는 계획, 4단계에 더 집중해야 한다는걸 잊지 말기
