
본 게시물은 패스트캠퍼스 '딥러닝/인공지능 올인원 패키지 Online`강의를 바탕으로 정리한 내용입니다.
✅ Neural Networks
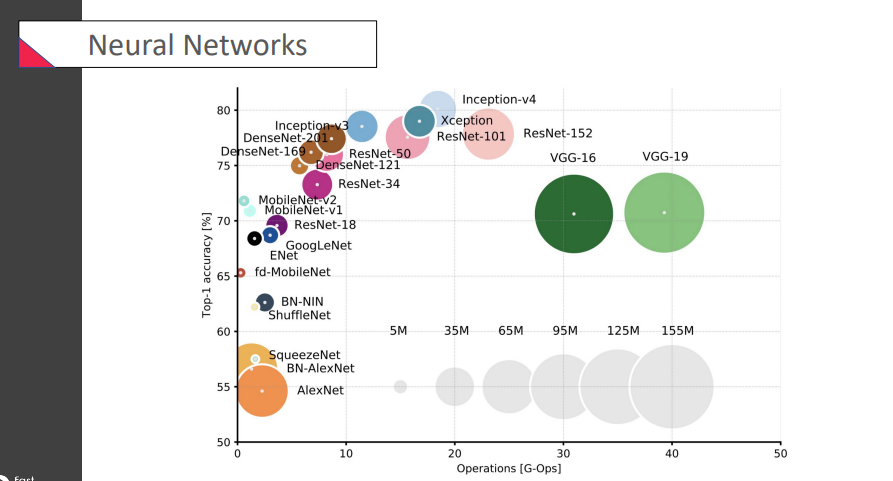 가로: 연산량, 세로: 정확도
가로: 연산량, 세로: 정확도
inception & ResNet이 정확도가 높은 편에 속함
accuracy가 그렇게 가장 중요한 것은 아님! 실제로 우리가 사용할 때속도나용량도 매우 중요하다고.
그래서 weight을 줄이자.. 연산속도를 줄이자.. 이런 제안들이 많이 나오고 있음 (추세) -> 효율적
이런 부분에서 보면, 오늘 배울
MobileNet이나SqueezeNet이 꽤 쓸만한 녀석이라는 것을 알 수 있겠지.. 성능이 아쉬운 문제를 해결하기 위해DenseNet도 등장
효율적인 CNN을 만들기 위해 어떤 노력을 했을까?
 우리의 목표! 하나에만 치중하지 말고 다 잘하는 애를 고르자 이고야
우리의 목표! 하나에만 치중하지 말고 다 잘하는 애를 고르자 이고야
✅ MobileNet
경량화 모델 중 가장 많이 reference되고 있는 유명한 모델
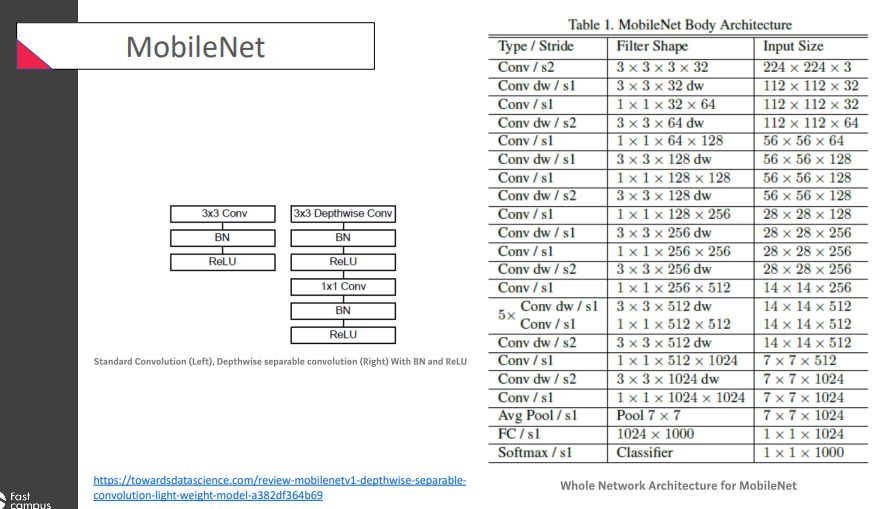 가장 유명한 것은
가장 유명한 것은 Depthwise separable convolution이 주목을 받음!
🔅 Dimension Reduction
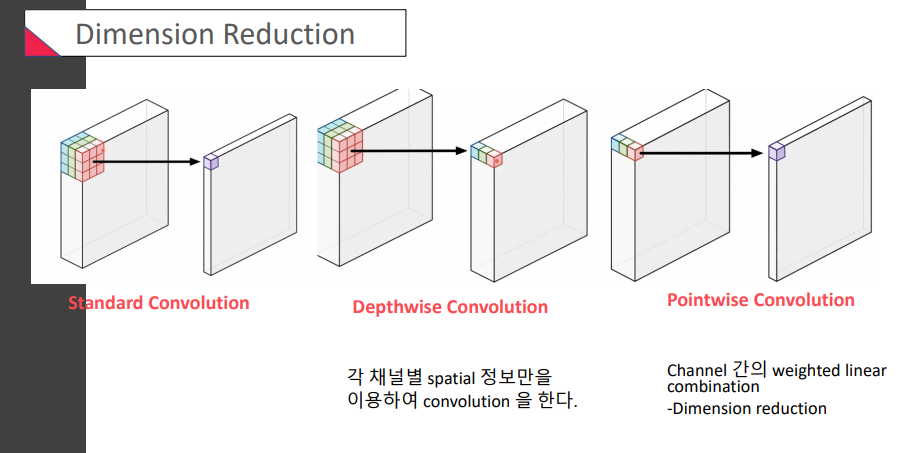
Depthwise convolution은 뭐가 다른걸까?
: 각 채널별 spatial 정보만을 이용하여 conv를 한다!? -> 각각의 정보가 유지가 된다
Pointwise convolution 요 아이는 또 무엇인지
: channel간의 conv(linear combination)가 이루어짐
: 다른 말로, 1x1 conv
🔅 Depthwise separable convolution
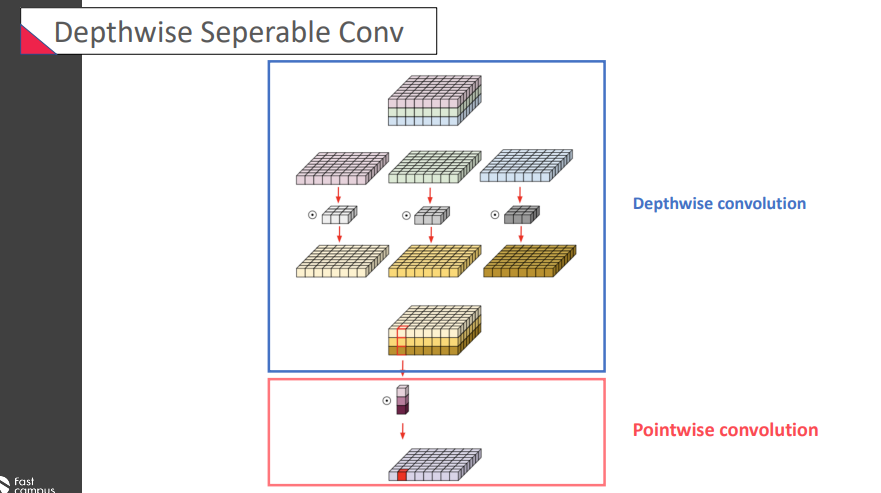
Depthwise separable convolution
= Depthwise convolution + Pointwise convolution
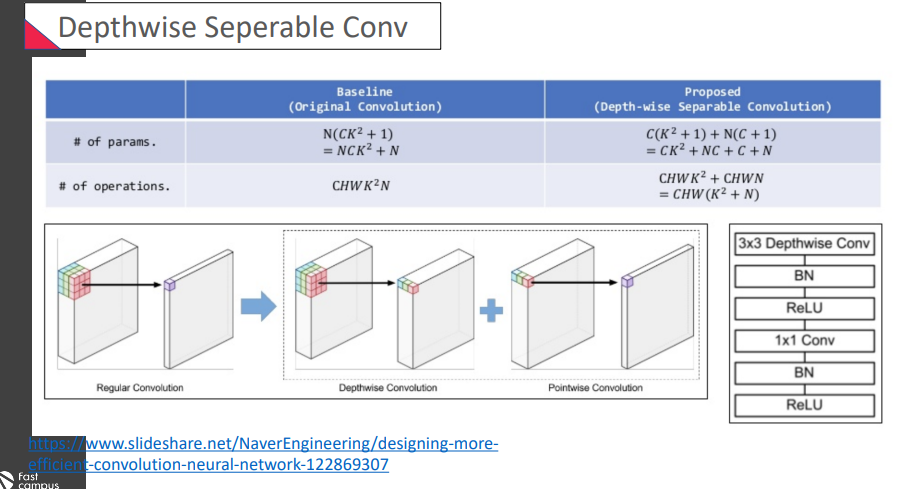 어떤 장점이 있을까? 기존의 값보다 훨씬 operation이 작아진 것이 확인할 수 있었음
어떤 장점이 있을까? 기존의 값보다 훨씬 operation이 작아진 것이 확인할 수 있었음

Width Multiplier: width 조정Resolution Multiplier: input resolution 조정
위 결과들을 보면, narrow일수록 / width가 클수록 / resolution이 클수록 -> 결과(accuracy)가 좋은 것을 확인할 수 있었다는거
accuracy는 resolution보다 width영향을 더 받는 것 같고, operation은 그 반대로 예상된다는 것을 표를 보고 확인 가능
✅ SqueezeNet
🔅 Fire Module
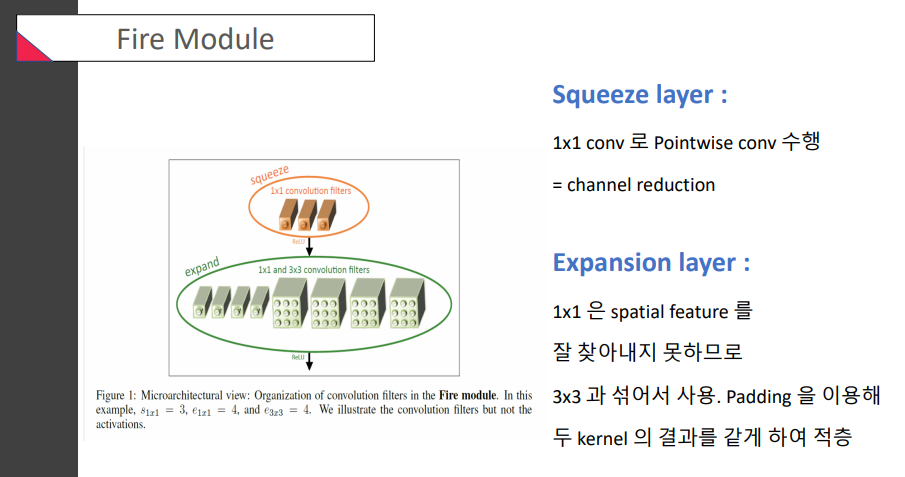 MobileNet처럼, depth정보와 channel정보를 구분해야 하지 않을까?
MobileNet처럼, depth정보와 channel정보를 구분해야 하지 않을까?
squeeze layer에서 1x1 conv를 이용하여 channel의 크기를 조정하고, expansion layer에서는 1x1 conv와 3x3 conv를 병렬적으로 사용함
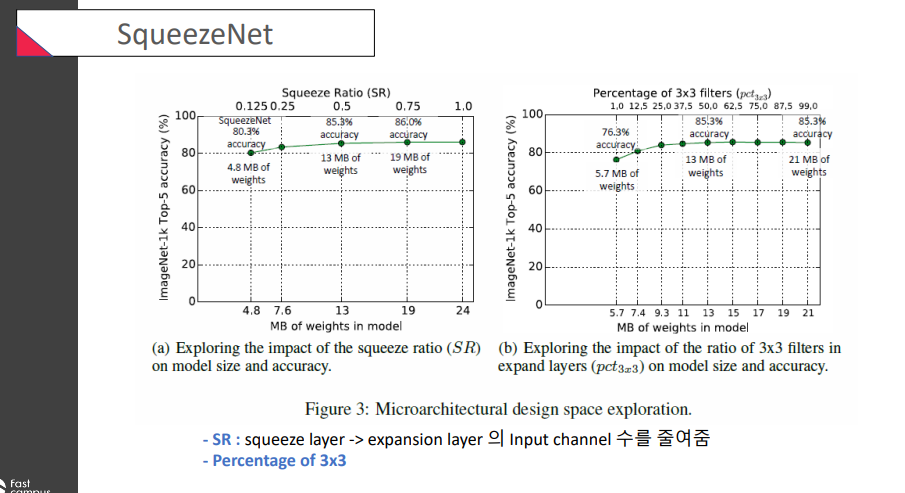
SR(Squeeze Ratio): squeeze layer -> expansion layer의 input channel 수를 줄여줌
(오른쪽) 50개 정도의 3x3 filter을 가질 때 결과가 좋았따..
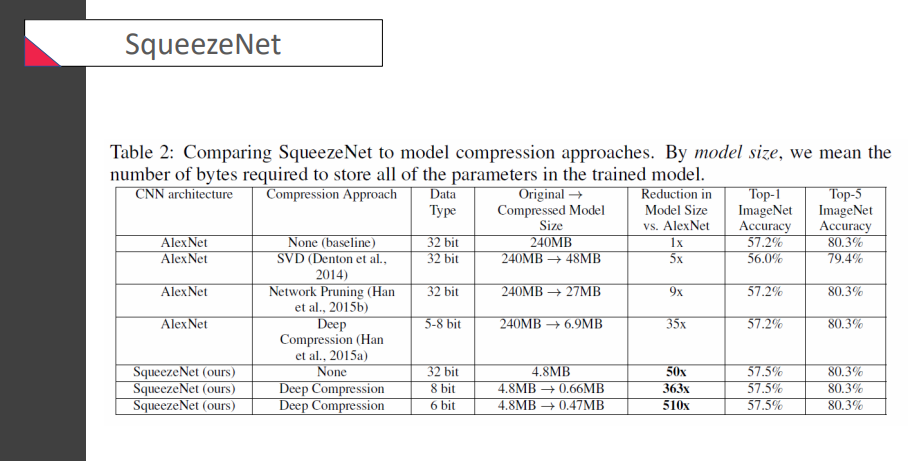 AlexNet과 비교했을 때.. SqueezeNet은 크기를 매우 줄일 수 있다고 주장 중
AlexNet과 비교했을 때.. SqueezeNet은 크기를 매우 줄일 수 있다고 주장 중
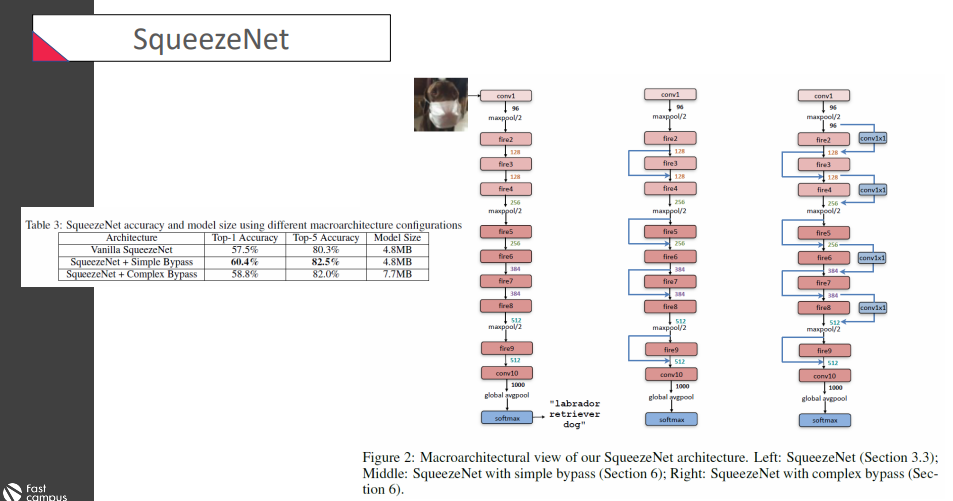 Bypass를 이용해서 성능을 높였다
Bypass를 이용해서 성능을 높였다
✅ DenseNet
ResNet과 비슷한 부분이 있음 (뒤로 정보를 넘겨주는거)
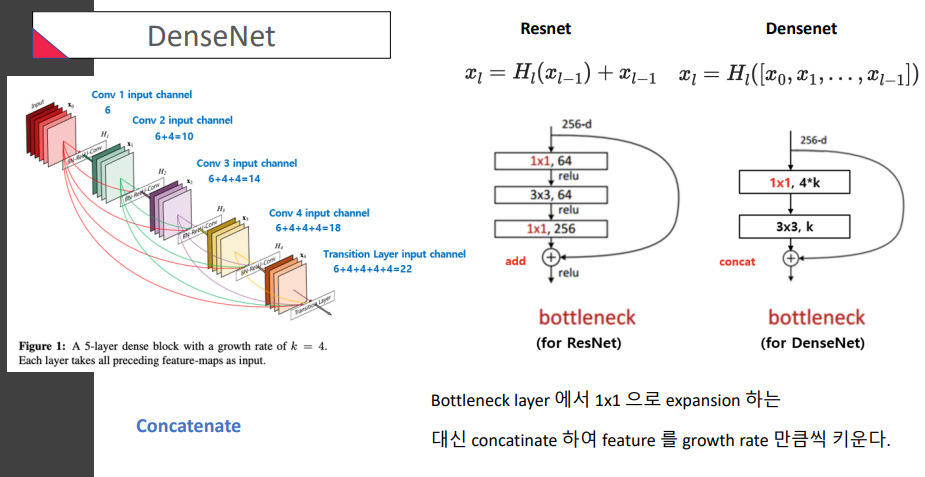
- ResNet은 input이 더해지는 형태였다면,
DensNet은concatinate한다는거! (옆으로 계속 붙인다는거, 마치 등차수열처럼 ㅎ) (growth rate만큼) - ResNet은 축소확대를 모두 하는 bottleneck이 있었는데
DenseNet은 concatination이 있으므로 처음에 축소하는 bottleneck만 있음
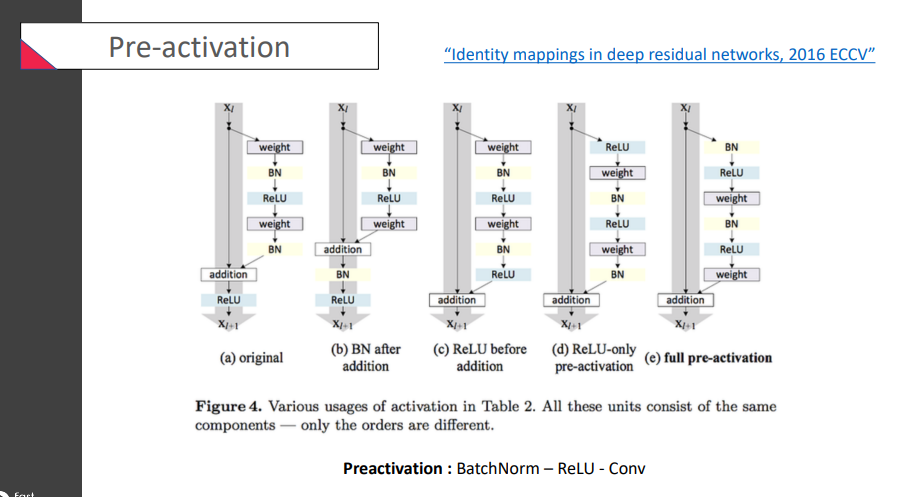 순서가
순서가 BatchNorm - ReLU - Conv를 하는 특이한 구조인 full pre-activation을 선택하였음
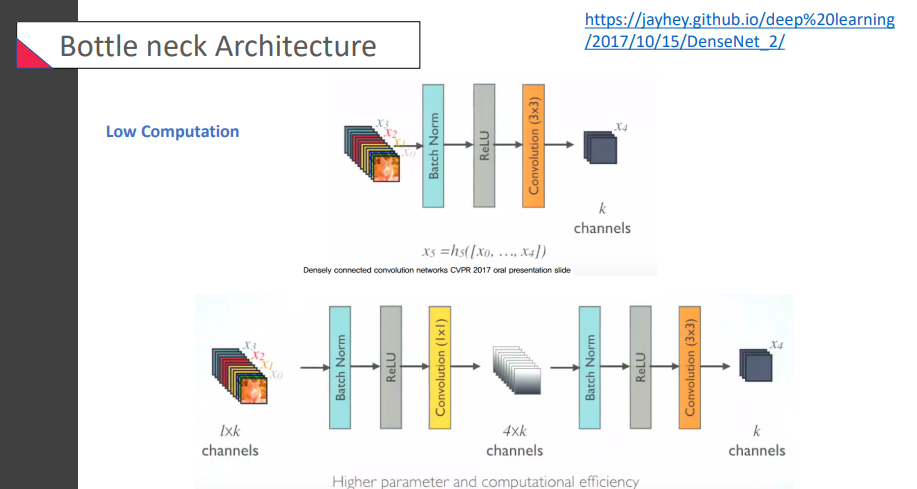 경량화를 시키는 모습. bottleneck 구조를 사용해서 역시나 연산을 줄이는 중
경량화를 시키는 모습. bottleneck 구조를 사용해서 역시나 연산을 줄이는 중
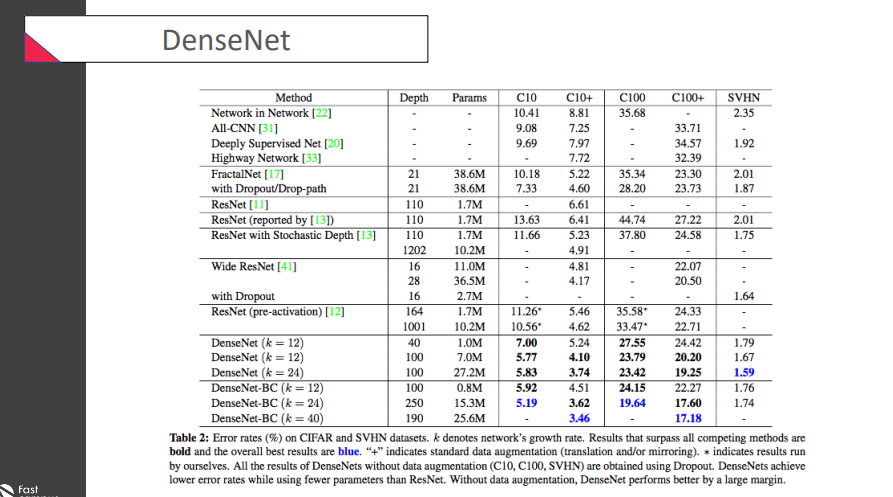 가장 좋은 결과 파란색으로 기록..
가장 좋은 결과 파란색으로 기록..
