https://www.samsungsds.com/kr/insights/multi-modal-ai.html
다음 글을 읽고 정리해봅니다.
이번 연구에 multi-modal 관련한 논문을 읽게 되었습니다. 멀티모달이라고 하면, 여러 종류의 입력 데이터를 동시에 처리하는 수준으로만 알고 있었지만, 처음 제안된 배경에 대해 알아보고 싶습니다.
다른 포유류와 다른 인간만의 특징
- 텍스트로 소통하고 기록하며 지식을 축적하는 '언어'
- 다양한 시각 정보를 받아들이고 이해하는 '뇌의 처리 능력'
- 후각과 미각, 통각을 비롯한 다양한 감각과 기억을 융합하여 사물을 받아들이는 '지식 통합 능력'
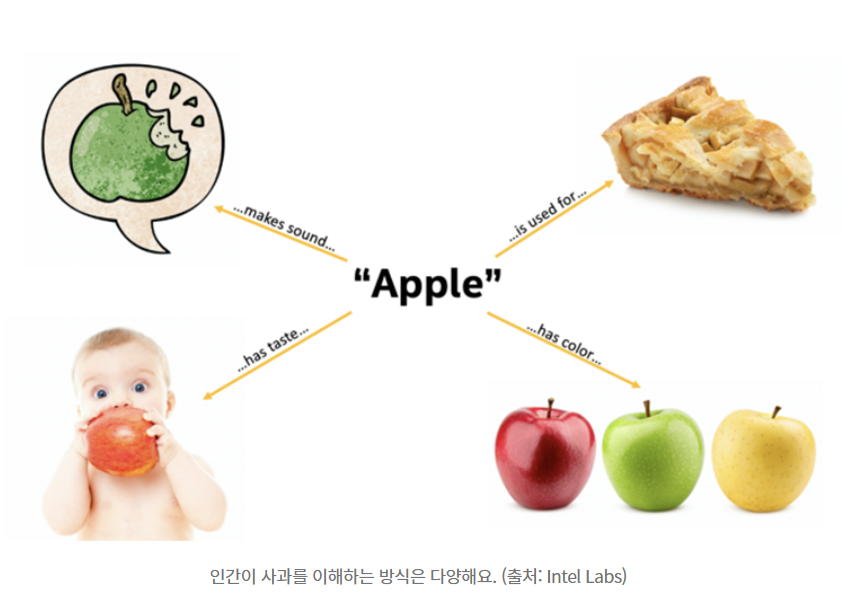
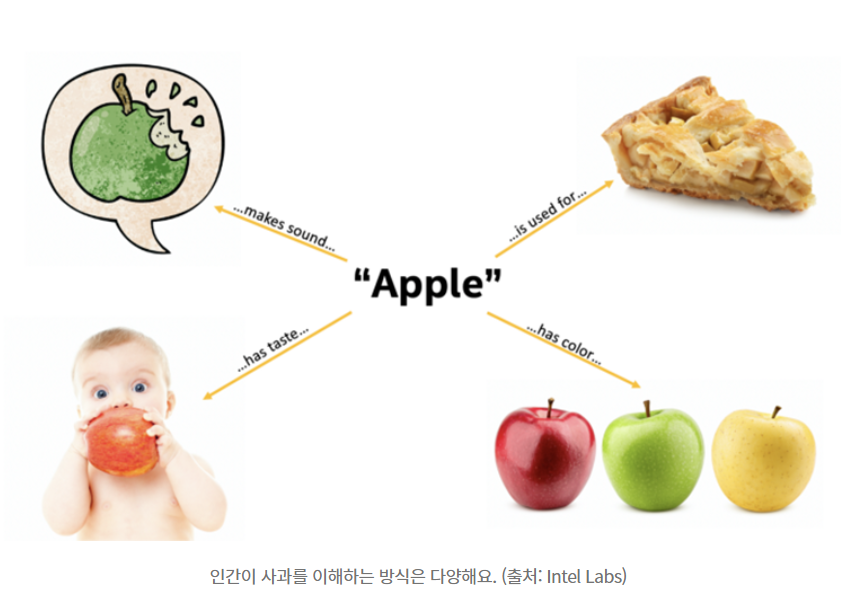
ex) 우리가 태어나서 '사과'라는 과일을 인식하게 되는 과정을 곰곰이 생각해봅시다.
우리는
(1) 사과를 맛보고
(2) 생김새와 색깔, 크기, 맛, 촉감들을 알게 되고
(3) 비슷한 모양의 풋사과, 상하거나 멍든 사과도 알게 된 후
그제서야 '사과(Apple)'이라는 개념을 뇌에 통합해 저장하게 됩니다.
다시 말해 사과라는 개념을 이해하기 위해서 시각, 미각, 촉각, 텍스트까지 여러 개념을 통합해 인식을 했습니다.
그렇다면 AI는 어떻게 사과라는 개념을 받아들일까요?
인간이 학습했던 방법으로 배우기 위해 등장한 것이 바로 '멀티 모달리티(Multi Modality)'입니다.
- '멀티모달'은 시각, 청각을 비롯한 여러 인터페이스를 통해서 정보를 주고 받는 것을 의미합니다.
멀티모달AI와 기존AI의 차이
기존 우리의 AI는 텍스트나 자연어를 이해하는데 중점을 두었습니다. (데이터 처리나 통계, 텍스트를 검색해서 보여주는 것)
그러나 여기서 문제가 발생했죠.
AI는 실제 그 단어가 의미하는 것이 어떻게 생겼고, 실제 세상에는 어떤 형태로 존재하는지 이해하지 못합니다.
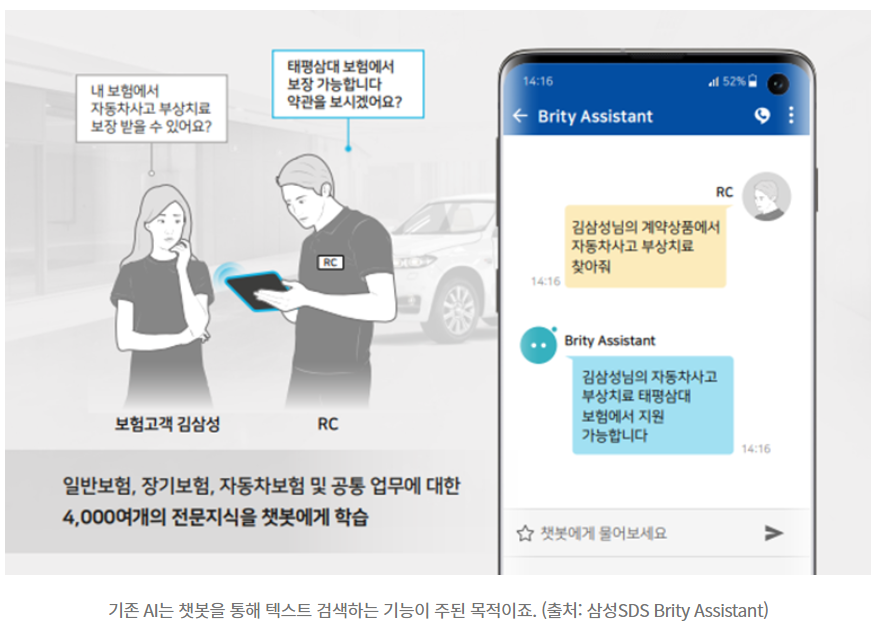
ex) '남자가 말을 타고 있다'라는 문장을 받았을 때,
AI는 'ride'의 개념을 이해하지 못할 뿐 아니라, 말의 크기가 얼마만 한 것인지, 어떤 형태로 타는 것인지 알 수가 없습니다.
AI가 사람처럼 세상을 인식하기 위해서는 멀티모달 AI의 등장이 필수적이었던 것이겠죠.
멀티모달 AI의 시대가 오면 어떻게 바뀔까?
텍스트<->이미지
변환해주는 많은 모델 등을 개발 중
혹은 이미지 안에서 텍스트로 질문을 해도 답을 해주는 모델(아래 그림)

아직까지는 이미지를 만들어내고 검색하는 정도로만 활용되는 단계입니다.
하지만 멀티모달 AI가 활성화되면, 텍스트나 이미지로만 가능했던 활용 영역을 엄청나게 변화시킬 것입니다.
ex) ‘번호판이 3X가1234인 차량의 전면부가 크게 파손되어 있는 사진’만 보험사에 전송하면, 해당 차량이 가입된 보험 상품을 검색하고, 고객의 피해 정도가 얼마나 될지 예측한 다음 담당자와 고객에게 사고 접수와 처리를 바로 진행하도록 해줄 수 있습니다.
-> 정확한 상황 인지를 통해서 조금 더 명확한 판단
ex) 첩보영화에서나 보던 테러범의 이미지를 분석해서 CCTV에서 실시간으로 찾아내는 상상 속의 이야기가 실제가 될 겁니다. 자동차 업계에서는 자율주행에서 필수적인 속도, 차선 위반, 운전자의 상태, 날씨까지 여러 정보를 기반으로 하는 AI도 멀티모달 기반으로 구현되어야 될 테고요. 의료계에서도 사람의 눈으로는 알아낼 수 없는 질병의 초기 진단이나 원격 진료에서도 크게 활약할 것으로 예상하고 있어요. 사람과 동일한 방식으로 세상을 인지하지만, 더욱 날카롭고 정확하게 분석해 낼 수 있는 것이 멀티모달 AI가 될 테니까요.
