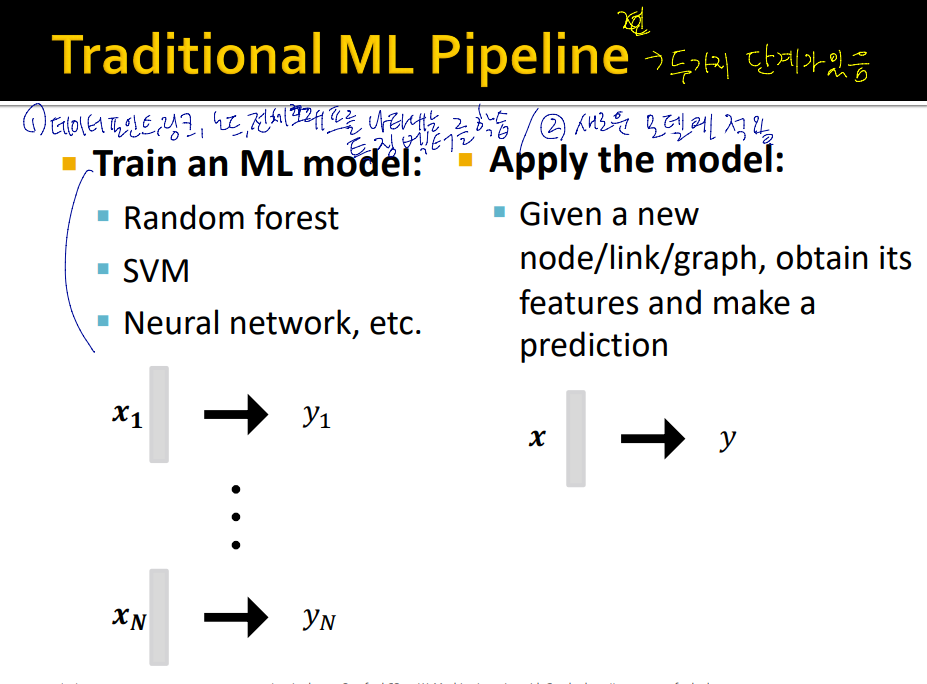
Traditional ML Pipeline
그래프 ml 에서 전통적인 pipeline
1) 노드, 링크, 전체 그래프를 나타내는 feature 를 디자인
2) 특징 벡터들을 SVM, Randon forest 등을 이용하여 학습
3) 새로운 예를 모델에 적용, 예측
Machine Learning in Graphs
목표 : 객체에 대한 예측
features : d 차원의 벡터
object : 노드, 링크, 노드 집합, 전체 그래프
object function : 우리가 해결하고자 하는 문제


목적함수를 어떻게 학습하고 예측에 사용할 것인지를 Node, Link, Graph level 로 나누어 task와 feature 학습
Node-level Tasks and Features
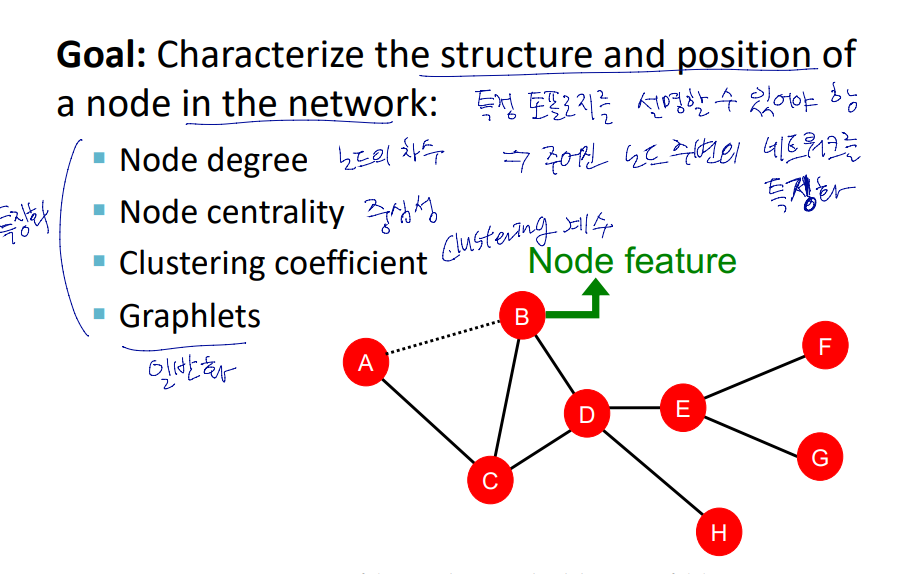
기계학습은 학습에 이용할 특징이 필요함.
node level task의 목적 : 네크워크 내의 노드를 특징화 (chracterize)
node level에서의 특징
- Node Degree (노드의 차수)
- Node centrality (노드의 중심성)
- Clustering coefficient (클러스터링 계수)
- Graphlets (그래플렛)
Node Degree
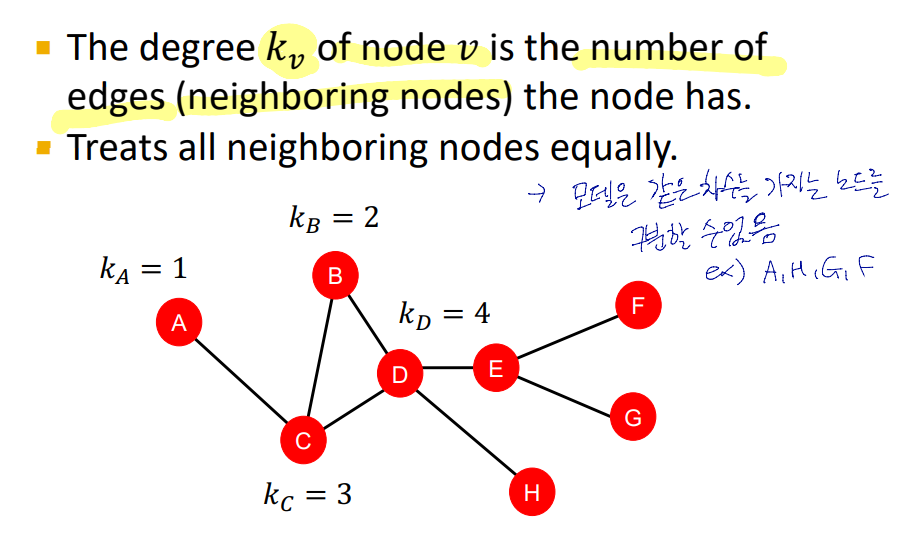
노드의 차수로 노드를 특징화하는 것의 한계는
같은 차수를 가진 노드는 구분할 수 없다는 것.
이를 해결하기 위해 중심성 개념 도입
Node Centrality

노드 중심성(Cv) : 그래프 내에서 노드의 중요성을 설명함.
중요성을 판단하는 다양한 방법
- Engienvector centrality (고유벡터 중심성)
- Betweenness centrality (매개 중심성)
- Closeness centrality (근접 중심성)
- ...
Engienvector centrality
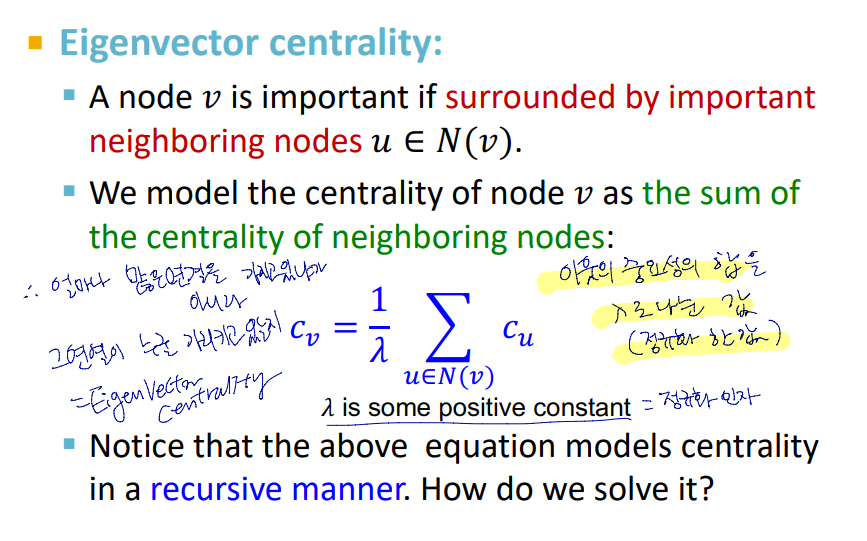

노드 v의 중요성은 이웃 노드의 중요성에 따라 결정 됨
노드 v의 중심성 : 이웃 노드의 중요성의 합
따라서 v가 얼마나 많은 이웃을 가지느냐가 중요한 것이 아니라, 얼마나 중요한 이웃과 연결되었는지가 중심성 판단의 기준
위의 식은 고유값 - 고유벡터 방정식으로 표현가능
이때 고유값인 람다가 최대인 경우 그래프가 방향이 없다고 판단하여 항상 positive and unique
고유 벡터 Cmax를 해당 노드에 대한 중심성 점수로 사용함
Betweenness centrality
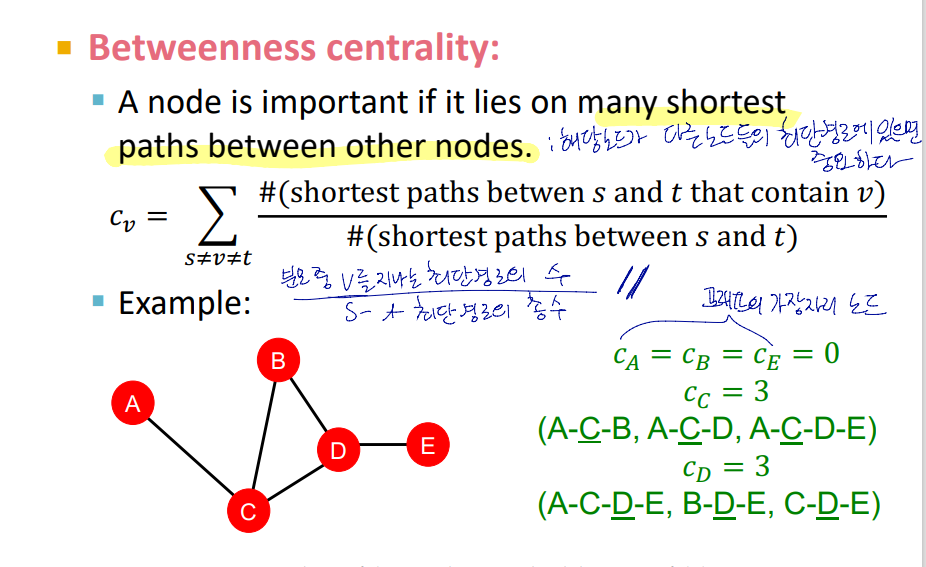
노드 v가 다른 두 노드쌍의 최단경로를 이루는 노드이면 중요하다는 개념.
노드 v의 중심성 :
Closeness centrality
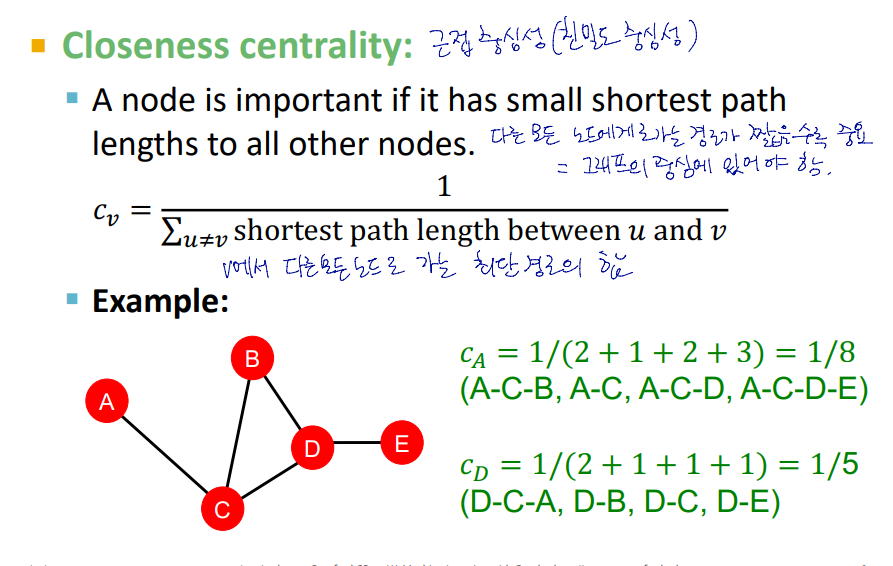
노드 v로 부터 다른 모든 노드로 가는 경로가 짧을수록 중요하다는 개념
그래프의 중심에 위치할수록 중요도가 커짐
노드 v의 중요성 :
Clustering Coefficient
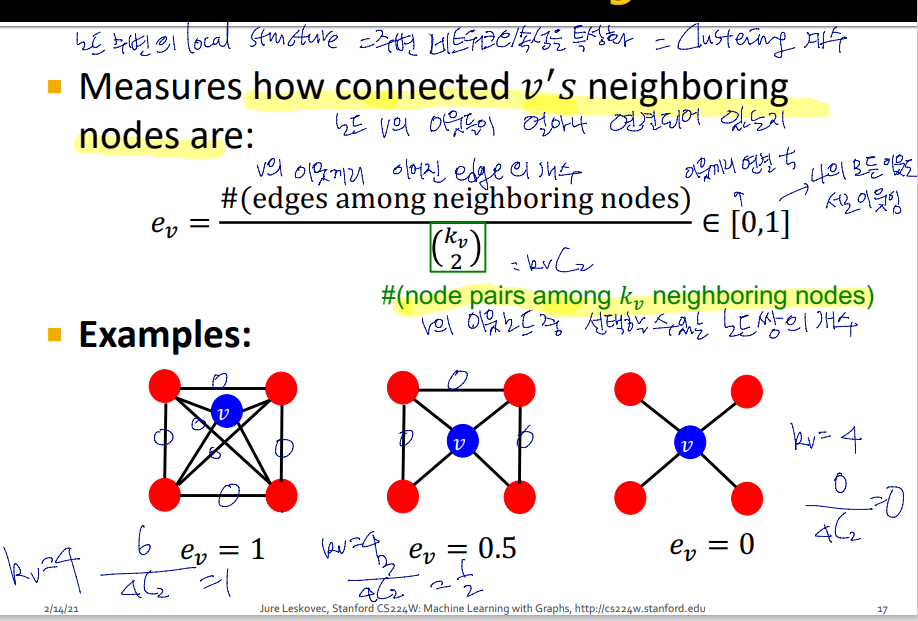
노드 v의 이웃들이 연결되어 있는 정도
Ev =
클러스터링 계수를 일반화한 것이 Graphlets
Graphlets
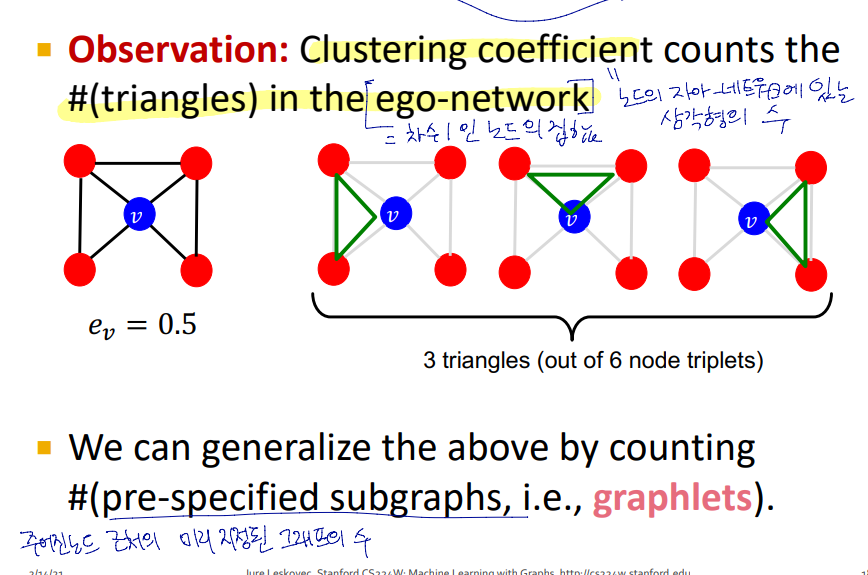
관심 노드 v에서 차수가 1인 노드로 이루어진 네트워크 (ego-network)에 있는 삼각형의 갯수
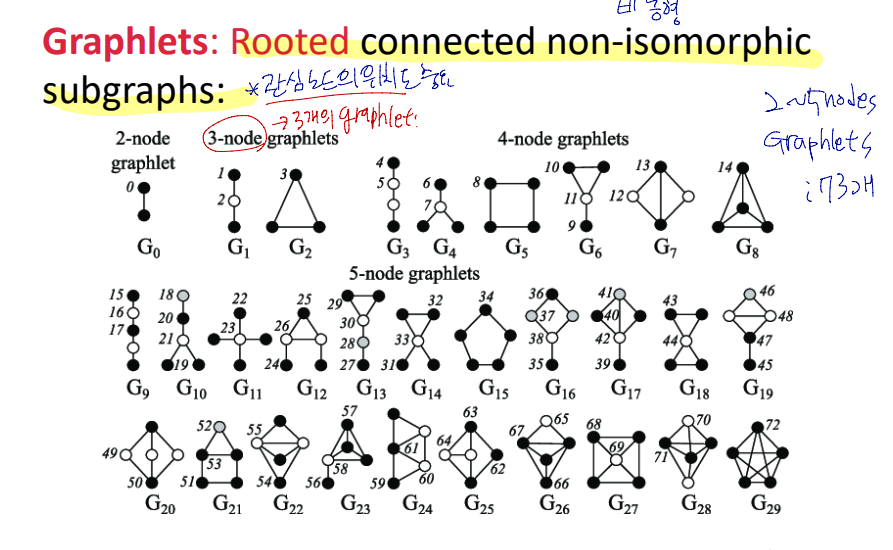
Graphlet은 연결된 비동형 그래프
그림은 노드의 개수에 따라 나올 수 있는 모든 graphlet의 경우
각 그림에서 노드옆에 있는 숫자가 관심노드. 관심노드가 무엇인지에 따라 같은 형태의 그래프여도 여러개의 graphlet이 존재함
노드 2개 - 5개까지 총 73개의 graphlet이 있음

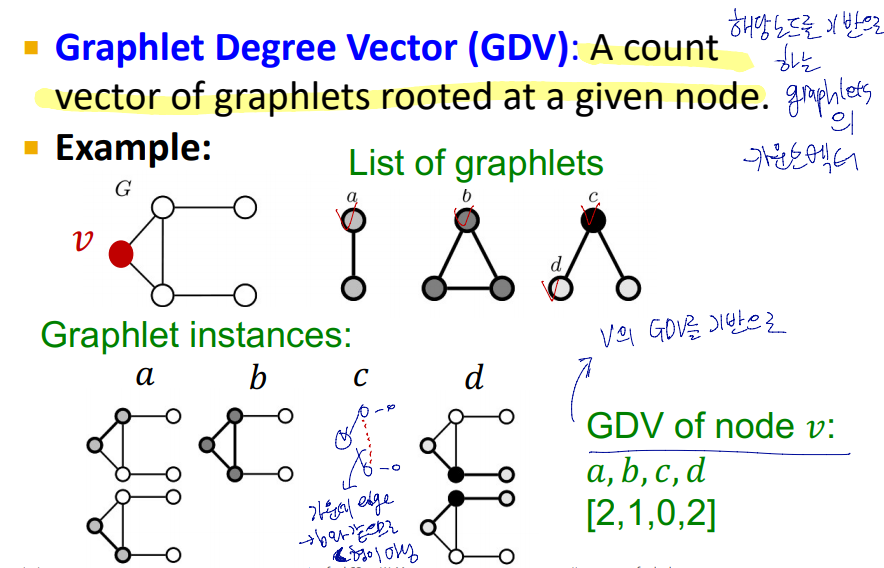
Graphlet Degree Vector(GDV) : 해당노드를 기반으로 하는 graphlet의 카운트 벡터
 노드의 갯수가 2부터 5까지의 grahlet : 각 노드의 이웃의 토폴로지를 기술
노드의 갯수가 2부터 5까지의 grahlet : 각 노드의 이웃의 토폴로지를 기술
이는 최대 4의 거리를 가진 토폴로지
graphet은 노드의 로컬 네트워트에 대한 토폴로지이며, 유사성에 대한 자세한 측정값
Node level Feature - Summary


 노드 수준에서 feature를 얻는 것은 두가지로 나뉨
노드 수준에서 feature를 얻는 것은 두가지로 나뉨
- 중요성 기반 feature
- 노드의 차수
- 노드 중심성 측정
- 구조 기반 feature
- 노드의 차수
- 클러스터링 계수
- GDV
Link-Level Prediction task
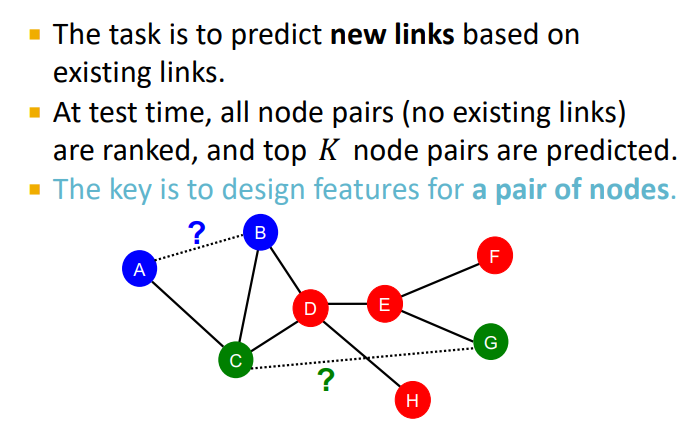
task : 기존링크를 기반으로 새 링크를 예측하는 것
테스트 시 아직 연결되지 않은 모든 노드 쌍을 순위를 매겨 top K의 노드쌍을 예측함
핵심 : 노드 쌍의 feature를 디자인하는 것
node level에서의 node1, node2의 feature를 concat 하여 모델을 학습시킨다면?
--> 두 노드사이의 관계에 대한 정보가 생략됨

-
네트워크의 링크가 무작위로 제거되었다고 가정하고 예측
-
시간이 지남에 따라 연결을 예측
: 시간이 지남에 따라 자연스럽게 진화하는 네트워크의 경우(ex) social nerwork) 시간 t0과 t0' 사이의 그래프를 입력으로 줌
output 은 시간 t1, t1' 사이에 나타날 수 있는 그래프의 예측을 rank 한 list -
평가방법
n = t1, t1'에 나타날 것이라고 예측한 새로운 edge의 갯수
list L 에서 top n개와 실제 나타난 edge를 비교
Link Prediction via Proximity
 주어진 노드쌍의 feature를 어떻게 만들것인지.
주어진 노드쌍의 feature를 어떻게 만들것인지.
- score c(x,y) : 노드사이의 공통 이웃 수
- score c에 따라 모든 노드쌍 정렬
- top n 개의 쌍을 새로운 링크로 예측
- 예측한 링크가 G[t1,t1']에 실제로 나타나는지
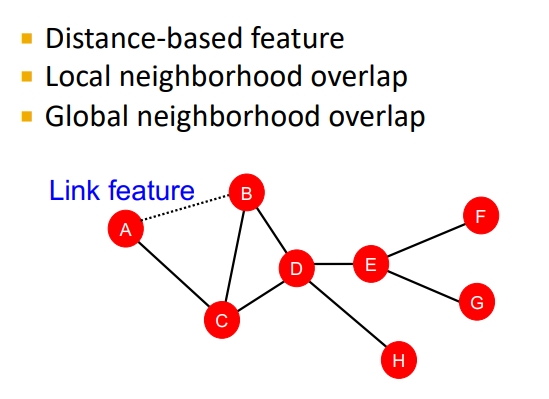 두 노드쌍의 feature를 정의하는 방법
두 노드쌍의 feature를 정의하는 방법 - Distance-based feature : 거리 기반
- Local neiborhood overlap : 지역 이웃 중첩
- Global neiborhood overlap : 글로벌 이웃 중첩
목표 : 두 노드 사이의 관계 예측
Distance-based feature
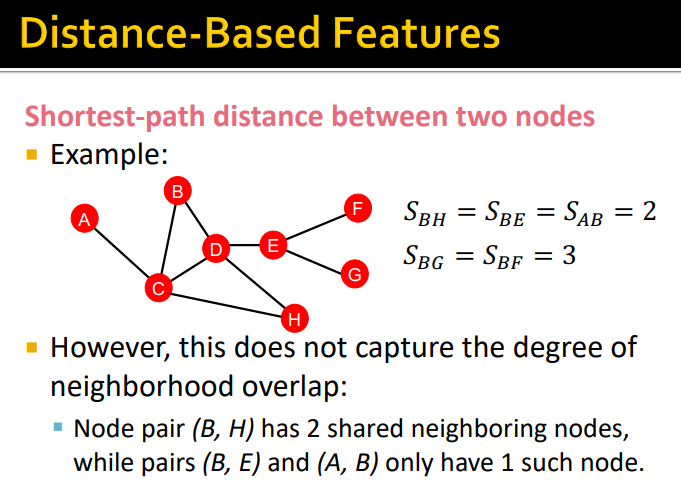 두 노드 사이의 최단경로 길이를 구하고 feature 정의
두 노드 사이의 최단경로 길이를 구하고 feature 정의
--> 두 노드사이의 연결성을 설명할 수 없음
-
노드 쌍 (B,H)의 공통 이웃은 C,D - 2개
(A,D)의 공통 이웃은 C - 1개이 경우 A,D 보다 B,H가 연결 강도가 높다
Local neiborhood overlap
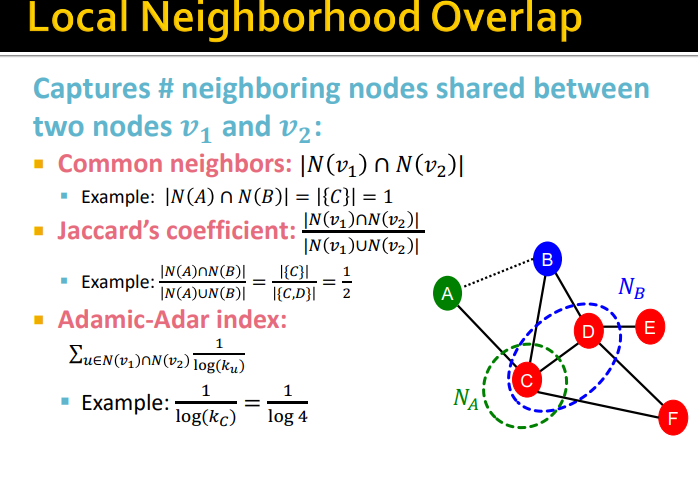
-
두 노드사이의 연결 강도 측정 : 두 노드사이에 공통 이웃의 수
== local neiborhood overlap -
자카드 계수 : 교집합의 크기를 합집합의 크기로 나눈 값
-
아다믹-아다르 계수 : 사회연결망에서 잘 작동
두 노드의 공통 이웃의 degree에 log를 취한 값의 역수를 모두 합한 값
-> 값이 클수록 노드가 더 가까운 것의 의미,
공통 이웃의 차수가 큰 것보다 작은 것이 나은데, 이유는 공통 이웃이 많아도 이웃들의 차수가 매우 크면 v1 ,v2 가 연결될 가능성은 낮기 때문
Global neiborhood overlap
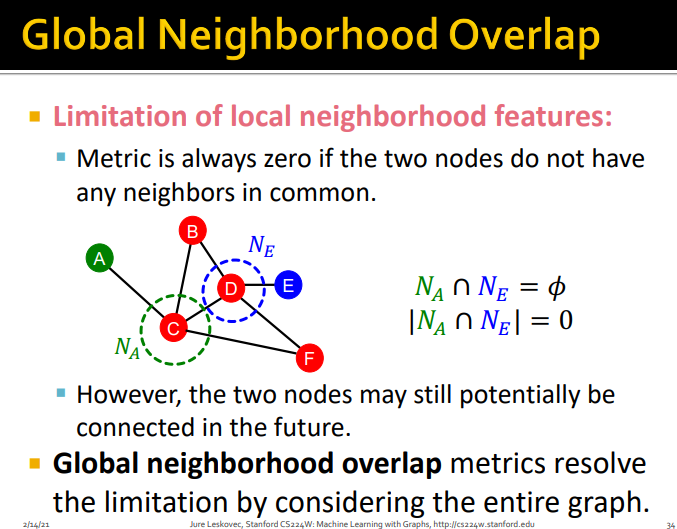
- local neiborhood feature의 한계
두 노드 사이에 공통 이웃이 없으면 항상 0을 반환함
--> global neiborhood overlap 거리가 2이상인, 전체 그래프에 대해서 고려함

-
카즈 지수 : 주어진 노드쌍 사이의 모든 경로의 수를 계산
-
계산 방법?
그래프 인접행렬의 거듭제곱 이용
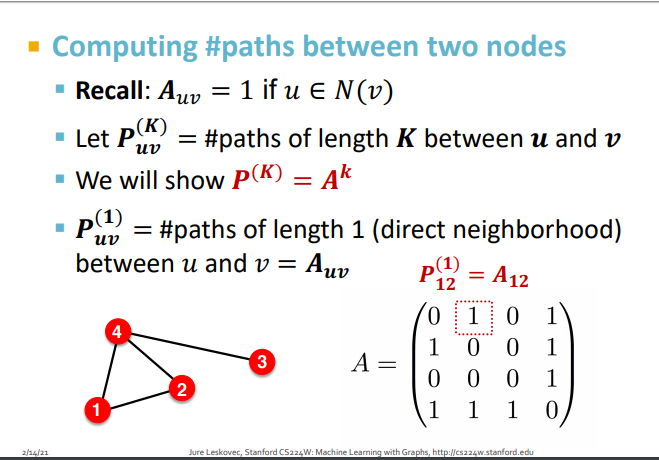
-
인접행렬의 k거듭제곱을 통해 길이가 K인 두 노드쌍의 경로의 수를 알 수 있음

인접행렬의 성질- k 거듭제곱의 1행 2열 : 노드1에서 노드2 로 가는데 길이가 2인 경로의 수
- 대각선 : 각 노드의 차수
 따라서 모든 길이의 경로의 수를 인접행렬의 거듭제곱을 통해 구하고, 이에 discount factor를 곱한 값의 합으로 카즈지수를 구함
따라서 모든 길이의 경로의 수를 인접행렬의 거듭제곱을 통해 구하고, 이에 discount factor를 곱한 값의 합으로 카즈지수를 구함
link level features summary
- distance-based
- 두 노드 간의 최단경로 길이
- 연결성 파악할 수 없음
- local neighborhood overlap
- 두 노드 간의 공통 이웃 수
- 공통 이웃이 없을 경우 (연결은 되어 있지만 그 길이가 2이상인 경우) 0의 값을 가짐
- global neiborhood overlap
- 두 노드간의 global graph 구조 이용 (길이가 1이상인 모든 경로의 수)
Graph level Features and Graph Kernels
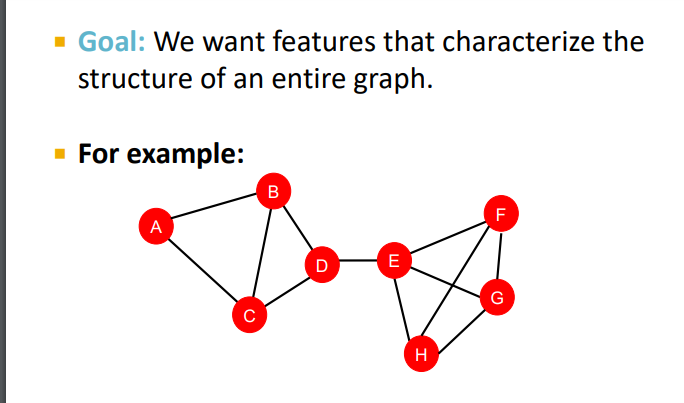 목표 : 전체 그래프의 구조를 특징 짓는 feature
목표 : 전체 그래프의 구조를 특징 짓는 feature

-
Kernel method
feature vector 대신에 커널을 디자인하자 -
커널?
- K(G, G') 은 두 그래프, 혹은 두 데이터 포인트 간의 유사성 측정
- 커널 행렬은 모든 그래프 쌍 또는 모든 데이터 포인트 간의 유사성 측정 : kernel matrix positive semidefinite : 설명

- 커널은 두 그래프의 벡터 표현의 내적
- 일단 커널이 정의되면 kerner SVM 과 같은 모델을 사용하여 예측 가능
 두 그래프 사이의 유사성을 측정할 수 있게 해주는 서로 다른 그래프 커널
두 그래프 사이의 유사성을 측정할 수 있게 해주는 서로 다른 그래프 커널
- Graphler kernel
- Weisfeiler-Lehman kernel
Graph Kernel : Key idea
 graph feature vector phi(G)를 디자인하는 것
graph feature vector phi(G)를 디자인하는 것
- 핵심 아이디어 : bag of words (bow)
- bow : 텍스트 문서를 단어의 빈도를 세서 단어 모음으로 나타내는 방법
- 노드를 단어로 간주
- 문제 : 같은 수의 노드를 가져도 다른 그래프 형태가 나올수 있는데 feature vector는 같음

따라서 노드의 차수로 bow를 만들고, 이를 feature vector로 표현하여 그래프 구분
Weisfeiler-Lehman kernel은 bag-of-* (bag of something) 을 사용, 노드 차수 보다 더욱 정교한 표현
Graphlet kernel
 핵심 아이디어 : 그래프에서 서로 다른 graphlet의 갯수
핵심 아이디어 : 그래프에서 서로 다른 graphlet의 갯수
여기서 graphlet의 개념은 node level graphlet과는 다름
- 노드 연결될 필요 없음
- 루트 없음
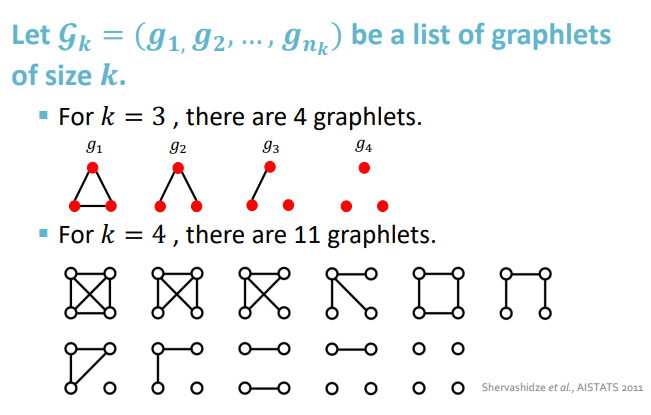

- graphlet count vector fG
주어진 그래프 G에 대해 나타나는 graphet의 개수
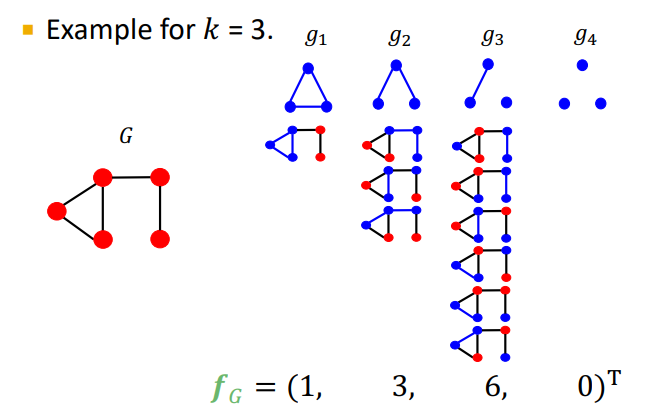

-
graphlet kernel
두 그래프가 주어졌을 때 각 그래프의 graphlet count vector의 내적 -
문제
그래프의 크기가 다를 때, 예를 들어 노드 갯수가 10000개와 2개일 경우 두 그래프의 f가 너무 차이나므로 f의 합으로 정규화 해줌 -
graphlet kernel 의 한계
계산 비용 - 크기가 n인 그래프에서 크기가 k인 graphlet을 구하는 것은 n^k로 지수승의 시간복잡도를 가짐
Weisfeiler-Lehman kernel

-
목표 : 효율적인 graph feature 설명 디자인
-
아이디어
bog of node degree는 1 hop 이웃의 정보만 가지므로 이를 일반화 하자 --> color refinement
color refinement

V개의 노드를 갖는 그래프 G
- 모든 노드를 같은 색으로 초기값 할당
- 다음 턴에 각 노드의 색을 이웃노드의 색과 concat
- 현재 시점의 내 색을 input, 이웃들의 색을 concat한 것을 output으로 하는 hash함수 이용
- k 단계 이후에는 k hop의 이웃들의 구조까지 요약되어 잇는 정보를 얻을 수 있음
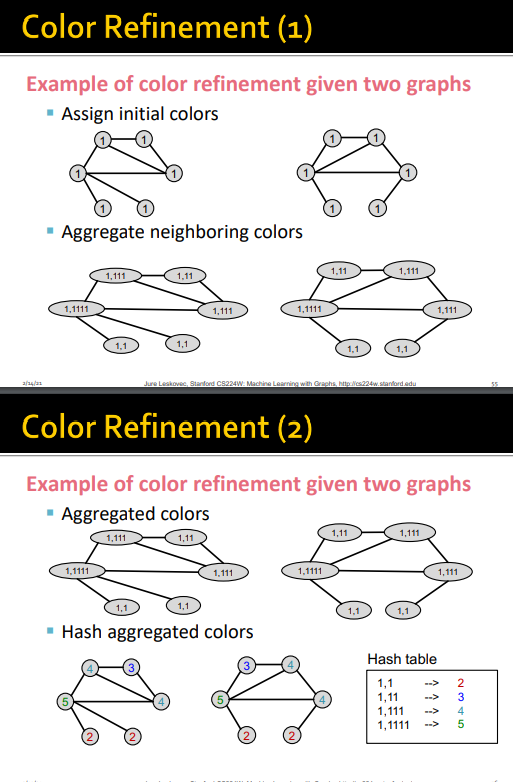
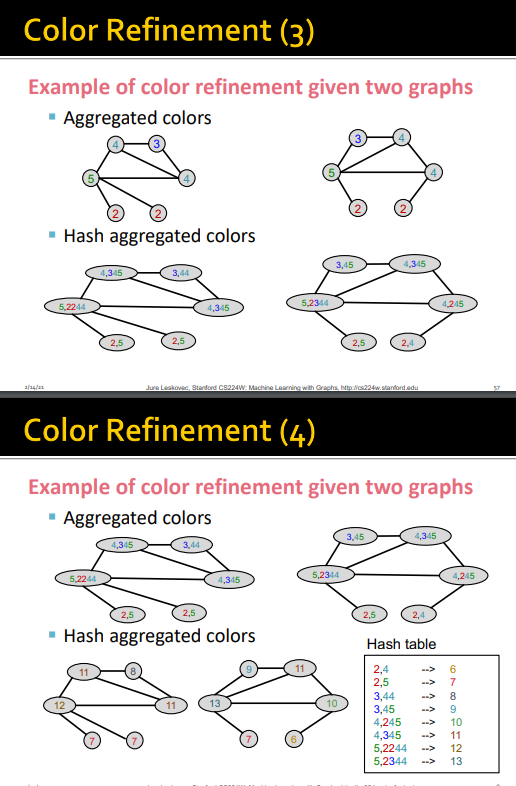

위의 단계를 거쳐 나온 vector를 내적하여 WL kernel을 얻음

이 방법은 graphlet kernel 에 비해 계산복잡도가 선형이므로, 효율적으로 graph level feature를 얻을 수 있음
summary

