Luna: Linear Unified Nested Attention, NeurIPS 2021
Contribution
- Luna: Linear Unified Nested Attention 제안
- 두개의 중첩된 linear attention 함수로 softmax attention 을 대체함
- time and space complexity 를 linear 하게 만듬
- long-context sequence modeling, neural machine translation and
masked language modeling for large-scale pretraining 세 개의 sequence modeling 파트에서 좋은 성능을 기록함
Abstract
Motivation
- Transformer 모델의 softmax attention(full attention)으로 인한 quadratic complexity problem을 해결하기 위함
Method
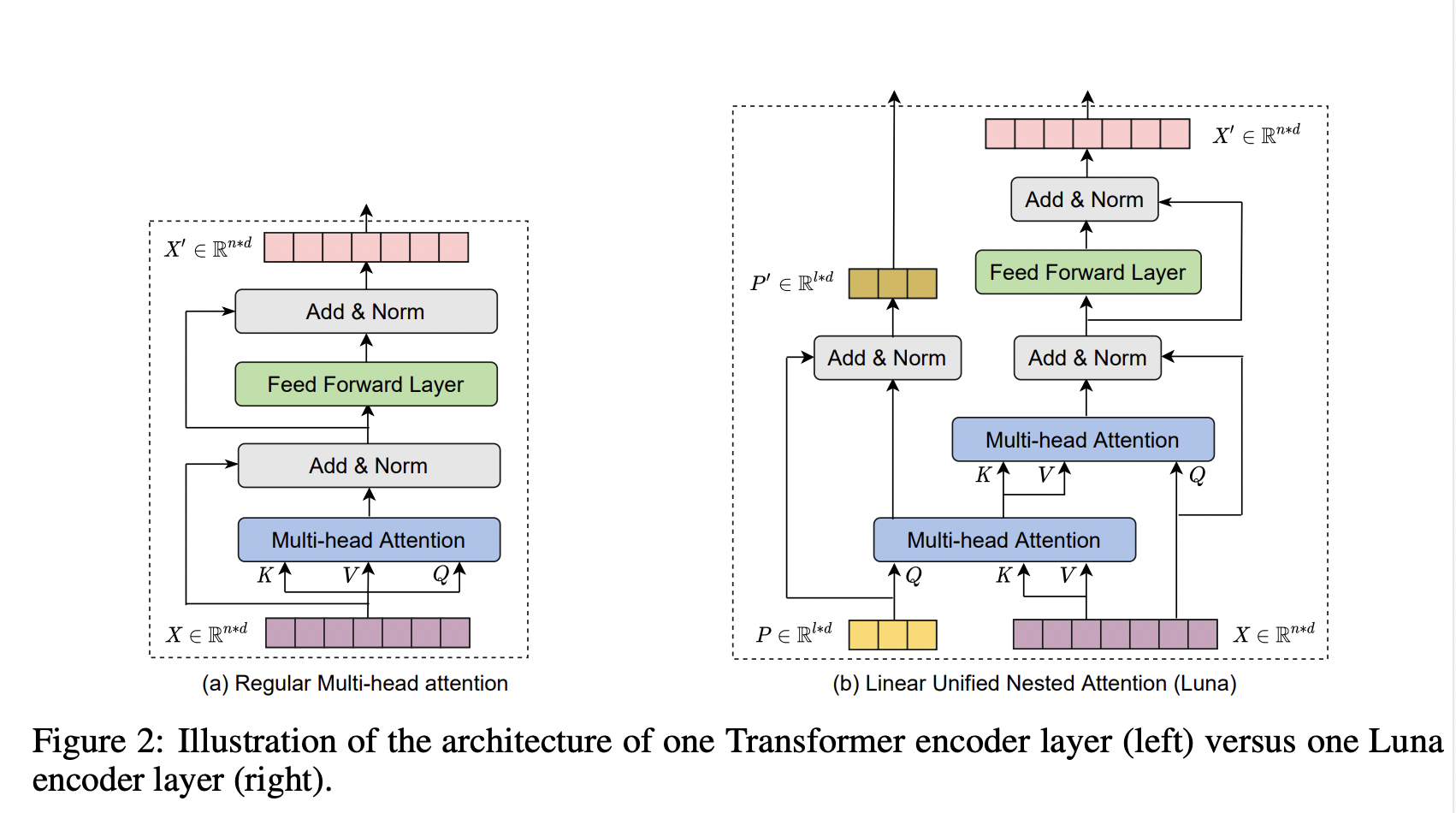
-
Luna attention : linear unified nested attention
regulat attention function을 linear efficiency를 가진 두 개의 nested atention으로 분리
how?- original query and context input sequences 대신 fixed (constant) length를 가진 extra input 사용
- Packed and Unpacked attention
- Packed attention : first attention. context sequence C 를 fixed length extra input sequence P 와 attention 하여 fixed-length sequence 를 생성. 이때 사용하는 attention 은 regular attention function임. P의 길이는 fixed length l이고, 기존 context sequence C의 길이는 m이라고 하면 packed attention의 시간 복잡도는 이며, l이 상수이기 때문에 m에 의존함. output 의 길이는 P와 같은 l.
- Unpacked attention : second attention. packed attention의 output을 다시 original query sequence X의 길이와 동일하게 만들어줌. X의 길이는 n이고, 의 길이가 l이기 때문에 unpacked attention 시간 복잡도는 이며, l이 상수이기 때문에 n에 의존함.
- Encoding Contextual Information in P
Extra input sequence P는 어디서 왔을까.
1, 2의 수식을 합치면 이 되는데, LunaAttn을 여러개 쌓아서 multiple layer를 만들고 이전 layer에서 나온 Y_P 를 P로 사용.(이렇게 해해야 C의 contexual information을 이용할 수 있기 때문에)
첫번째 layer에서의 P는 learnable positional embedding을 사용함.
-
architecture of each Luna layer
은 Luna Layer의 두개의 output.
Take a home message
두개의 linear unified nested attention 구조로 성능을 좋게 유지하면서 attention function의 time complexity 를 linear하게 만들 수 있음.

ML/AI Engineer