Ref
ONNX github
ONNX homepage
ONNX 1.15.0 documentation
PyTorch Docs - torch.onnx
도서:실전 파이토치 딥러닝 프로젝트
블로그:PyTorch 모델 ONNX로 export 하기
ONNX란?
Open Neural Network Exchange의 약자로 ML model을 표현하기 위한 open standard format이다. 즉 Tensorflow, Pytorch와 같이 다른 framework에서 개발된 모델을 서로 호환되게 사용할 수 있게끔 만들어진 ecosystem이다. ONNX는 특히 inferencing 에 필요한 기능에 집중한다.
- ONNX의 장점
-
Framework Interoperability
ONNX의 설명에도 나와있듯이 특정 환경에서 생성된 모델을 다른 환경으로 import하여 자유롭게 사용을 할 수 있다. -
Shared Optimization
HW vendor(가속기와 같은 HW 제조업체)의 입장에서 ONNX와 같은 프레임워크 간 공유되는 포맷이 존재하면, 하드웨어 설계시 ONNX representation을 기준으로 최적화를 하면 되기 때문에 효율적이다.
neural network는 dataflow graphs를 통해 계산을 수행한다.
일부 프레임워크(예: CNTK, Caffe2, Theano 및 TensorFlow)는 정적 그래프(static graphs)를 사용하는 반면 다른 프레임워크(예: PyTorch 및 Chainer)는 동적 그래프(dynamic graphs)를 사용한다.
그러나 이들은 모두 개발자가 최적화된 방식으로 그래프를 처리하는 실행 시간과 계산 그래프를 쉽게 구성할 수 있는 인터페이스를 제공한다. 그래프는 개발자의 소스 코드의 특정 의도를 포착하는 Intermediate Representation(=IR, 중간 표현) 역할을 하며, 특정 장치(CPU, GPU, FPGA 등)에서 실행되는 최적화 및 번역에 도움이 된다.
이 중 어떤 프레임워크를 선택하느냐는 빠른 학습시간, 복잡한 네트워크 아키텍쳐 지원, 모바일 장치에서의 추론 등 어떤 요구사항을 가지고 있느냐에 따른 선택이다.
하지만 모든 상황에서 단 하나의 프레임워크를 사용할 수 없기 때문에 프레임워크 전환에 따른 오버헤드가 있다.
ONNX(Open Neural Network Exchange) 형식은 이 강력한 생태계를 구축하는 데 도움이 되는 공통 IR이다.
Open Neural Network Exchange Intermediate Representation (ONNX IR)
어떻게 다른 framework에서 개발된 모델들을 통합할 수 있을까?
ONNX는 계산 그래프의 공통 표현을 제공하여 프레임워크마다 다르게 만들어지는 computation graph를 통합한다. 이를 Open Neural Network Exchange Intermediate Representation (ONNX IR)이라고 한다.
ONNX IR의 큰 구성요소는 아래와 같다.
- A definition of an extensible computation graph model.
- Definitions of standard data types.
- Definitions of built-in operators.
1과 2가 함께 ONNX IR을 구성한다.
built-in operators는 set of primitive operators와 functions으로 나누어진다.
functions은 다른 연산자 및 함수를 사용하여 sub graph로 만들어진 연산자를 의미한다.
각 computation data flow graph 는 비순환 그래프를 형성하는 노드 목록으로 구조화된다. 노드에는 하나 이상의 입력과 하나 이상의 출력이 있다. 각 노드는 연산자에 대한 호출이다. 그래프에는 목적, 작성자 등을 문서화하는 데 도움이 되는 메타데이터도 있다. 연산자는 그래프 외부에서 구현되지만, 내장된 연산자 세트는 프레임워크 간에 이식할 수 있다. ONNX를 지원하는 모든 프레임워크는 해당 데이터 유형에 대한 이러한 연산자 구현을 제공한다.
PyTorch 모델 ONNX로 export 하기
PyTorch 모델을 ONNX 그래프로 export 하는 과정을 도식화한 그림이다.
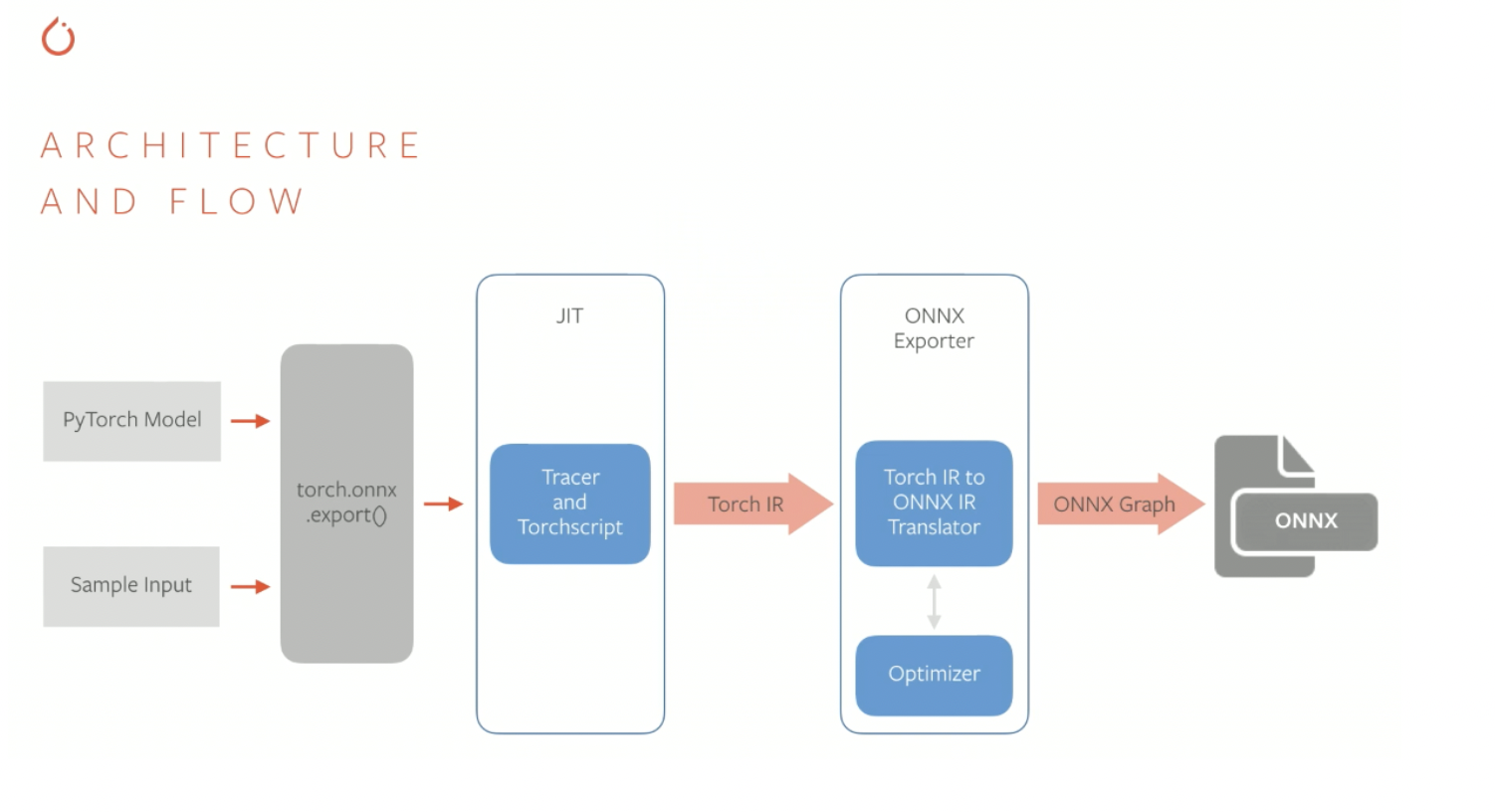
- PyTorch 모델과 example input을 인자로 하여 torch.onnx.export 함수를 호출하면, PyTorch의 JIT 컴파일러인 TorchScript를 통해서 trace 혹은 script를 생성한다. Trace나 script는 PyTorch의 nn.Module을 상속하는 모델의 forward 함수에서 실행되는 코드들에 대한 IR (Intermediate Representation)을 담고 있다. 쉽게 설명하면 forward propagation 시에 호출되는 함수 및 연산들에 대한 최적화된 그래프가 만들어진다.
- 생성된 trace / script (PyTorch IR)는 ONNX exporter를 통해서 ONNX IR로 변환되고 여기에서 한 번 더 graph optimization이 이루어진다.
- 최종적으로 생성된 ONNX 그래프는 .onnx 포맷으로 저장된다.
TorchScript란?
PyTorch의 just-in-time 컴파일러.
pyTorch는 수학연산을 바로 실행하는 eager-mode로 동작하기 때문에, 중간결과를 메모리에 쓰고 읽으면서 하나씩 실행하면 추론하는데까지 대기시간이 걸린다. 이 문제를 해결하기 위해 PyTorch의 JIT Compiler인 TorchScript를 사용한다.
TorchScript는 모델을 컴파일하여 전체 모델에 대해 하나의 정적 그래프를 만든다.
TorchScript를 사용하면 python의 GIL을 제거하여 멀티스레드를 사용할 수 있게 하는 등의 최적화를 하고 C++과 같은 포맷으로 직렬화할 수 있다.
- Example: AlexNet from PyTorch to ONNX
AlexNet을 alexnet.onnx로 변환하는 예시이다. 먼저 torch.onnx.export를 통해 model을 trace하고, traced model을 다시 export하는 과정이다.
import torch
import torchvision
dummy_input = torch.randn(10, 3, 224, 224, device="cuda")
model = torchvision.models.alexnet(pretrained=True).cuda()
# Providing input and output names sets the display names for values
# within the model's graph. Setting these does not change the semantics
# of the graph; it is only for readability.
#
# The inputs to the network consist of the flat list of inputs (i.e.
# the values you would pass to the forward() method) followed by the
# flat list of parameters. You can partially specify names, i.e. provide
# a list here shorter than the number of inputs to the model, and we will
# only set that subset of names, starting from the beginning.
input_names = [ "actual_input_1" ] + [ "learned_%d" % i for i in range(16) ]
output_names = [ "output1" ]
torch.onnx.export(model, dummy_input, "alexnet.onnx", verbose=True, input_names=input_names, output_names=output_names)alexnet.onnx 파일을 binary protocol buffer를 포함하는데, protocol buffer는 네트워크의 구조와 모델의 파라미터 정보를 담고 있다.
export 시 verbose=True로 두면 human-readable한 모델의 정보를 출력할 수 있다.
# These are the inputs and parameters to the network, which have taken on
# the names we specified earlier.
graph(%actual_input_1 : Float(10, 3, 224, 224)
%learned_0 : Float(64, 3, 11, 11)
%learned_1 : Float(64)
%learned_2 : Float(192, 64, 5, 5)
%learned_3 : Float(192)
# ---- omitted for brevity ----
%learned_14 : Float(1000, 4096)
%learned_15 : Float(1000)) {
# Every statement consists of some output tensors (and their types),
# the operator to be run (with its attributes, e.g., kernels, strides,
# etc.), its input tensors (%actual_input_1, %learned_0, %learned_1)
%17 : Float(10, 64, 55, 55) = onnx::Conv[dilations=[1, 1], group=1, kernel_shape=[11, 11], pads=[2, 2, 2, 2], strides=[4, 4]](%actual_input_1, %learned_0, %learned_1), scope: AlexNet/Sequential[features]/Conv2d[0]
%18 : Float(10, 64, 55, 55) = onnx::Relu(%17), scope: AlexNet/Sequential[features]/ReLU[1]
%19 : Float(10, 64, 27, 27) = onnx::MaxPool[kernel_shape=[3, 3], pads=[0, 0, 0, 0], strides=[2, 2]](%18), scope: AlexNet/Sequential[features]/MaxPool2d[2]
# ---- omitted for brevity ----
%29 : Float(10, 256, 6, 6) = onnx::MaxPool[kernel_shape=[3, 3], pads=[0, 0, 0, 0], strides=[2, 2]](%28), scope: AlexNet/Sequential[features]/MaxPool2d[12]
# Dynamic means that the shape is not known. This may be because of a
# limitation of our implementation (which we would like to fix in a
# future release) or shapes which are truly dynamic.
%30 : Dynamic = onnx::Shape(%29), scope: AlexNet
%31 : Dynamic = onnx::Slice[axes=[0], ends=[1], starts=[0]](%30), scope: AlexNet
%32 : Long() = onnx::Squeeze[axes=[0]](%31), scope: AlexNet
%33 : Long() = onnx::Constant[value={9216}](), scope: AlexNet
# ---- omitted for brevity ----
%output1 : Float(10, 1000) = onnx::Gemm[alpha=1, beta=1, broadcast=1, transB=1](%45, %learned_14, %learned_15), scope: AlexNet/Sequential[classifier]/Linear[6]
return (%output1);
}모델이 성공적으로 변환이 되었으면, onnx 라이브러리를 설치하고 아래와 같이 실행할 수 있다.
import onnx
# Load the ONNX model
model = onnx.load("alexnet.onnx")
# Check that the model is well formed
onnx.checker.check_model(model)
# Print a human readable representation of the graph
print(onnx.helper.printable_graph(model.graph))이렇게 exported model은 ONNX Runtime(multiple platform, hardware에서 high performance를 내도록 하는 inference engine)을 통해 onnx뿐 아니라 onnx가 지원하는 많은 runtime애서도 실행이 가능하다.


Tracing vs Scripting
torch.onnx.export()는 torch.nn.Module이 아닌 torch.jit.ScriptModule 형식의 model이 필요하다. 따라서 위에서 언급한 PyTorch 자체 JIT 컴파일러인 TorchScript로 1차 변환을 해야하는데, 이때 컴파일 방법이 Tracing mode, Scripting mode 두가지이다.
만약 모델이 ScriptModule이 아니라면, export()는 기본적으로 tracning을 사용한다.
Tracing : torch.onnx.export()를 호출하면 torch.jit.trace()를 통해 주어진 args로 모델이 동작하는 과정을 기록한다. 주어진 input에 따라 동작하는 operations를 기록하기 때문에, 만약 input이 달라지거나 모델 안에 if와 같은 dynamic behavior가 존재하면 Trace는 dynamic flow를 export할 수 없다.
Scripting : Script는 dynamic control flow를 보존하고 input size가 달라져도 되도록 torch.jit.script()를 통해 model을 compile하여 ScriptModule을 만든다.
Script를 사용해도 export를 할 때 args가 필요하지만, 이는 example output을 만들기위해서만 사용된다.
| Trace | Script |
|---|---|
| 더미 입력 필요 | 더미 입력 필요 없음 |
| 더미 입력을 모델에 전달해 정해진 일련의 수학 연산을 기록함 | 파이토치 코드 내부의 nn.Module 콘텐츠를 조사해 토치스트립트 코드/그래프를 생성함 |
| 모델 순전파 내에 여러 제어 흐름(if-else)를 처리할 수 없음 | 모든 종류의 제어흐름을 처리하는 데 유용함 |
| 모델이 토치스크립트에서 지원하지 않는 파이토치 기능을 포함하고 있어도 작동함 | 모델이 토치스크립트에서 지원하지 않는 파이토치 기능을 포함하지 않을 때만 작동할 수 있음 |
Avoiding Pitfalls
- Avoid NumPy and built-in Python types
Torch.Tensor가 아니라 Numpy와 Python type을 사용하면, tracing 시에 상수로 변환된다. 이는 의도한 것과 다른 결과를 만들게 된다.
따라서 numpy 보다는 torch에서 제공하는 함수를 사용하고, 모델 내에 Tensor를 python built-in number로 변경하는 torch.Tensor.item()과 같은 함수는 사용하지 않는 것이 좋다.
# Bad! Will be replaced with constants during tracing.
x, y = np.random.rand(1, 2), np.random.rand(1, 2)
np.concatenate((x, y), axis=1)
# Good! Tensor operations will be captured during tracing.
x, y = torch.randn(1, 2), torch.randn(1, 2)
torch.cat((x, y), dim=1)
# Bad! y.item() will be replaced with a constant during tracing.
def forward(self, x, y):
return x.reshape(y.item(), -1)
# Good! y will be preserved as a variable during tracing.
def forward(self, x, y):
return x.reshape(y, -1)
-
Avoid Tensor.data
Tensor.data는 부정확한 ONNX graph를 만들 수 있기 때문에 torch.Tensor.detach()를 사용해야 한다. -
Avoid in-place operations when using tensor.shape in tracing mode
tracing mode에서는 tensor의 shape 또한 tensor로 trace 되며, 같은 메모리를 share 한다. 이는 최종 output이 기대했던 것과 다르게 만들어질 수 있기 때문에 operation을 다시 작성해야한다.
class Model(torch.nn.Module):
def forward(self, states):
batch_size, seq_length = states.shape[:2]
real_seq_length = seq_length
real_seq_length += 2
return real_seq_length + seq_length위와 같은 모델은 tracing mode에서 real_seq_length와 seq_length가 같은 메모리를 공유하기 때문에 값이 rewrite된다. 따라서 아래와 같이 처리를 해주어야 한다.
real_seq_length = real_seq_length + 2Limitations
-
Types
Torch.Tensor만을 지원한다. numeric types, tuples, lists Tensor만이 모델의 input과 output이 될 수 있다.- tracing
Dict나 str이 input으로 사용되면 tracing 시에 constant value로 해석된다.
dict로 반환된 output은 key는 제거되고 flattened sequence of its values만 남는다.
str으로 반환된 모든 output은 제거된다. - scripting
tuples이나 lists를 포함하는 특정 operation들은 ONNX의 nested sequences 에 대한 제한적인 지원으로 인해 scripting mode에서 동작하지 않는다. tracing mode에서는 nested sequences는 자동으로 flatten된다.
- tracing
-
Differences in Operator Implementations
operator의 서로 다른 구현으로 인해 다른 runtime에서 동작하는 exported model은 다른 결과를 도출한다. 이 차이는 수치적으로 매우 작긴하지만, 작은 차이도 중요한 상황에서는 문제가 될 수 있다. -
Unsupported Tensor Indexing Patterns
Export할 수 없는 Tensor indexing pattern이 있다. 아래와 같은 패턴이 포함된 모델을 export할 때 문제가 있다면 최신 opset_version을 사용하고 있는지 다시 체크해야한다.-
Reads / Gets
Tensor를 읽을 때 아래와 같이 음수를 포함하는 패턴은 지원되지 않는다# Tensor indices that includes negative values. data[torch.tensor([[1, 2], [2, -3]]), torch.tensor([-2, 3])] # Workarounds: use positive index values. -
Writes / Sets
Tensor를 쓸 때 아래와 같이 2차원 이상의 Multiple tensor, not consecutive한 Multiple tensor, 음수 포함, Implicit broadcasting을 포함하는 패턴은 지원하지 않는다.# Multiple tensor indices if any has rank >= 2 data[torch.tensor([[1, 2], [2, 3]]), torch.tensor([2, 3])] = new_data # Workarounds: use single tensor index with rank >= 2, # or multiple consecutive tensor indices with rank == 1. # Multiple tensor indices that are not consecutive data[torch.tensor([2, 3]), :, torch.tensor([1, 2])] = new_data # Workarounds: transpose `data` such that tensor indices are consecutive. # Tensor indices that includes negative values. data[torch.tensor([1, -2]), torch.tensor([-2, 3])] = new_data # Workarounds: use positive index values. # Implicit broadcasting required for new_data. data[torch.tensor([[0, 2], [1, 1]]), 1:3] = new_data # Workarounds: expand new_data explicitly. # Example: # data shape: [3, 4, 5] # new_data shape: [5] # expected new_data shape after broadcasting: [2, 2, 2, 5]
-
