입출력 관리
입출력 장치에는 키보드, 마우스, 프린터, 스피커, 마이크 등이 있다. 운영체제는 컴퓨터에 연결된 입출력 장치 및 주변장치를 제어하고 관리한다.
하드웨어에는 컨트롤러라는 것이 존재하는데, 일종의 작은 CPU로 하드웨어를 제어한다. 그리고 이 컨트롤러 안에는 데이터를 임시로 저장하는 작은 메모리 공간을 가지고 있으며 이를 Local Buffer(버퍼)라고 한다. 컨트롤러는 레지스터 또한 가지고 있다.
입출력 명령
-
입출력 맵 입출력(I/O mapped I/O)
메모리와 입출력의 주소 공간을 분리하여 액세스한다. 입출력 접근을 메모리 접근과 분리하기 때문에 메모리용으로 주소 영역 전체를 사용할 수 있다. 또 다른 장점은 어셈블리어로 된 소스 목록을 볼 때, 언제 입출력이 수행되는지를 알아보기가 쉽다. 이는 바로 입출력용으로만 쓰는 명령어를 써서 입출력을 수행하기 때문이다. -
메모리 맵 입출력(Memory Map I/O)
장치 제어 레지스터를 프로세서의 주소 공간으로 사상, 각 주변장치 레지스터들은 메모리 주소와 일대일 대응이 되고, 컴퓨터는 이러한 메모리 주소에 데이터를 읽고 쓰는 것으로 장치 제어기의 레지스터에 직접 데이터를 읽고 쓰는 역할을 수행한다. 메모리에 기록하는 것이 매번 입출력 명령어를 사용하는 것보다 빠르기에 현재의 I/O는 대부분 이 방식을 채택한다. -
Programed I/O
모든 입출력 작업을 CPU 명령어를 이용한다. CPU는 계속해서 입출력 장치의 상태를 확인(polling)하느라 다른일을 하지 못하므로 비효율적이다.
입출력 하드웨어의 동작
-
폴링
장치의 제어기의 레지스터 에는 비지 비트(busy bit) 라는 것이 존재 하는데, 이것은 현재 장치가 사용가능한 상태인지 아니면 다른 작업을 처리중이라 사용이 불가능 한지를 나타낸다. 제어기는 작업이 하느라 바쁠 때에는 비지 비트를 1로 설정하고 준비 중인 경우에는 0으로 설정하여 컴퓨터가 현재 장치가 사용중인지를 알 수 있게 해준다.여기서 컴퓨터는 시시때때로 장치가 사용중인지를 검사하기 위해 비지 비트 를 검사해야 하는데, 이것을 계속 돌면서 반복한다고 하여 폴링 이라고 부른다. 이러한 폴링에는 컴퓨터 자원이 많이 소요되지 않지만(3 사이클 정도) 장치가 준비하는 시간이 길어지면 매우 비효율적이다.
-
인터럽트
인터럽트란 폴링 방식을 단점을 개선한 기법으로, CPU가 처리 중에 있을 때, 입출력 하드웨어 장치나 다른 예외적 상황의 발생으로 처리가 필요한 상황에 CPU를 불러 처리하도록 하는 것이다.CPU는 IRQ(Interrupt ReQuest) Line을 가지고 있는데, 하나의 명령어의 실행을 완료할 때마다 항상 이 선을 검사한다. 컨트롤러가 이 라인에 신호를 보내면 CPU는 하던 일을 잠깐 멈추고(경우에 따라 인터럽트를 지연시키기도 한다.) 현재 작업 내용을 Context에 잠깐 저장한 상태로 Interrupt handling(입출력 장치를 서비스함으로써 이 인터럽트를 처리해 주는 것)을 하게 된다. 처리가 끝나면 context를 다시 불러와 작업을 재개한다.
직접 메모리 접근(Direct Memory Access)
입출력 장치와 컴퓨터 사이의 데이터는 어떤 방식으로 주고 받을까? 만약 CPU를 사용하여 디스크와 같은 대용량 입출력 장치의 데이터를 읽어들인다면 CPU의 사용량이 매우 높아지고 이는 컴퓨터 성능을 심각하게 저하시킬 것이다. 즉, CPU가 매번 바이트 전송을 제어하는 것은 심한 낭비인 것. 이렇게 CPU가 1바이트씩 옮기는 입출력 방식을 PIO 라고 부른다.
많은 컴퓨터들은 이렇게 CPU의 낭비를 막기 위해 PIO를 DMA 제어기 라고 불리는 특수 프로세서 에게 위임함으로써 CPU의 일을 줄여준다. 그 과정은 다음과 같이 진행된다.
먼저, 컴퓨터(호스트)는 메모리에 DMA 명령 블록을 쓴다. 이 블록에는 전송할 데이터가 있는 곳의 포인터와 전송할 장소에 대한 포인터 그리고 전송될 바이트 수를 기록해 놓는다. 그러면 CPU는 DMA 명령 블록의 주소를 DMA에게 알려주고 자신은 다른 일을 처리한다. 그러면 DMA는 CPU의 도움 없이 자신이 직접 버스를 통해 DMA 명령 블록을 액세스하여 입출력을 실행한다.
파일관리
디스크는 물리적으로 Track과 sector로 구성되어 있으며, 여기서 파일이라는 논리적 관점으로 데이터를 바라보고 관리하는 것이다.
파일은 OS가 실행되는 컴퓨터에서 자주 볼 수 있는데, 이는 복잡한 과정으로 하드디스크에 저장되어 있는 것을 사용자가 편리하게 사용할 수 있도록 파일이라는 논리적 형태로 운영체제에서 관리하여 보여준다.
- 파일의 생성과 삭제(file creation, deletion)
- 디렉토리(Directory)의 생성과 삭제
- 기본 동작 지원: open, close, read, write, create, delete
- Track/sector - file 간의 매핑(mapping)
- 백업(Backup)
디스크의 구조
디스크 시스템이란 데이터를 저장하는 디스크 팩과 저장 또는 저장된 데이터를 읽어내는 장치인 디스크 드라이브(Drive)를 묶어 표현한 것이다.
디스크 팩은 전원이 끊겨도 데이터를 보존할 수 있는 저장 매체이며 여러 장의 원판 디스크로 이루어져 있다.
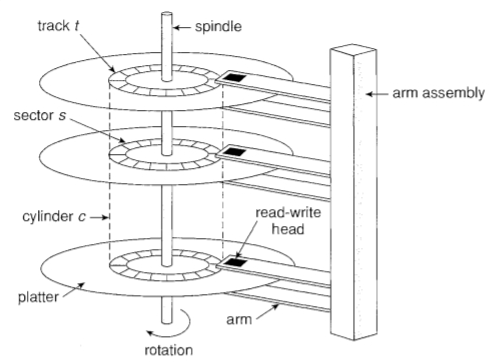
회전축에 의한 회전 동작과 붐(Boom)에 의한 전후 동작이 있는데 이 두 가지 동작이 연동되어 특정 위치에 헤드(Head)를 위치시키고 읽기나 쓰기가 이루어진다.
디스크의 한 면을 보면 여러 개의 트랙(Track)으로 구성되며 한 트랙은 다시 여러 개의 섹터(Sector)로 이루어진다.
데이터는 섹터 단위로 디스크에 쓰이거나 읽히는데 우리가 블록이라 부르는 것도 일반적으로 섹터의 크기이다.
섹터가 모여 트랙을 이루고, 트랙이 모여 한 면을 이루고 다시 여러 면이 모여 디스크 팩 전체 공간이 된다.
암(Arm)의 길이는 같기 때문에 헤드는 각 면의 같은 트랙에 위치하게 되고, 디스크 팩에서 동심원의 모든 트랙을 묶어 실린더(Cylinder)라 부른다.
RAID(Redundant Array of Inexpensive Disks) 구조
디스크 시스템의 성능뿐 아니라 비용과 신뢰성 등 모두 고려하여 구성한 디스크 시스템의 형태
비용이 낮은 소규모 디스크들을 여러 개 사용하여 이를 배열 형태로 구성한다.
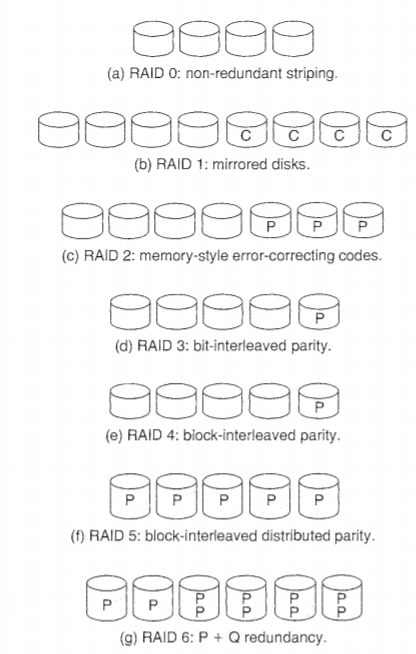
RAID 레벨은 각각 독립적으로 유지되며 높은 레벨이 낮은 레벨의 형태를 포함하지 않으므로, RAID 구조를 이용하기 위해서는 각 응용에 최적인 RAID 레벨을 선택하거나 몇 가지의 RAID 레벨을 복합하여 구성하는 것이 바람직하다.
디스크 접근 시간
- 탐색 시간, Seek Time : 주어진 주소로부터 실린더 번호를 보고 헤드를 해당 트랙으로 이동하는 시간
- 회전 지연 시간 , Rotational Delay or Latency Time : 지정된 섹터가 회전하여 헤드 밑으로 이동하는 시간
- 전송 시간 , Transfer or Transmission Time : 섹터가 헤드 밑을 회전하는 동안 읽거나 쓰게 되는 시간
디스크 스케줄링 기법의 평가 기준
-
단위 시간당 처리량 (Throughput) :
디스크 스케줄링은 단위 시간당 처리량을 최대화할 수 있어야 한다. 같은 시간에 보다 많은 디스크 입출력 요구들에 대해 서비스할 수 있어야 한다는 의미 -
평균 응답 시간 (Mean Response Time) :
디스크 스케줄링은 각 요구들에 대해 평균 응답 시간을 최소화할 수 있어야 한다. 디스크 입출력 요구들에 대해 가능하면 빠른 시간 내에 서비스를 제공할 수 있어야 한다는 의미 -
응답 시간의 예측성(Predictability) :
디스크 입출력 요구를 보낸 측에서 자신의 요청에 대한 서비스가 언제 끝날 것인지를 추측할 수 있는 점과 관련된 성능 평가 지표이다. 응답 시간의 분산을 줄이고 예측성을 높이는 스케줄링을 하게 되면 무기한 연기 등의 상황도 방지할 수 있게 된다.
디스트 스케줄링 기법
-
FCFS(First Come First Served) 스케줄링
디스크 입출력 요청들을 도착한 순서대로 서비스하는 기법으로, 스케줄링으로 인한 오버헤드가 작아 디스크 입출력에 대한 부하가 작을 경우 적합하다. -
SSTF(Shortest Seek Time First) 스케줄링
큐에 도착해 있는 요구 중 현재 헤드 위치로부터 가장 가까운 요구를 먼저 서비스한다.
새로운 요청까지 포함해서 가장 가까운 요청을 처리하여
단위 시간당 처리량을 극대화하지만 헤드와 먼 요구들은 무기한 연기 상황이 나타난다. -
SCAN 스케줄링
현재 헤드의 위치와 가장 가까운 위치에 대한 요구를 먼저 서비스하지만 현재 헤드의 진행 방향으로만 입출력 요구들을 처리하며 양 끝의 실린더에 도착했을 때에만 방향 전화하여 나머지 요구들을 처리한다.
SSTF 스케줄링의 응답 시간의 문제를 개선한 방법이다. -
LOOK 스케줄링
엘레베이터가 동작하는 방식과 비슷해서 엘리베이터 알고리즘이라고도 한다.
SCAN과 유사하지만 헤드가 진행하는 도중 진행 방향의 앞쪽으로 더 이상의 요청이 없으면 양 끝의 실린더까지 진행하지 않고 그 자리에서 방향을 바꾼다. 항상 마지막 실린더까지 진행하는 SCAN의 단점을 개선했지만
헤드의 진행 방향 앞쪽으로 계속해서 디스크 요구가 들어오게 되면 반대 방향 요구의 대기 시간이 길어진다. -
C-SCAN 스케줄링
서비스 방향을 안쪽 또는 바깥쪽 중 한쪽으로 미리 정해놓고, 정해진 방향으로 헤드가 이동할 때에만 큐의 요구들을 처리하는 방법이다. 마지막 실린더에 도착하면 요청에 대한 처리 없이 반대쪽 마지막 실린더로 이동한다.
한쪽 방향으로만 서비스를 진행하면서 양끝 부분의 트랙과 중앙 부분 트랙을 균등하게 서비스하는 기법으로,
응답 시간에 대한 예측성이 매우 높은 기법이다. -
SLTF(Shortest Latency Time)
섹터 큐잉(Sector Queueing) 이라고도 한다.
회전 지연 시간의 최적화를 위한 기법으로 각 섹터별로 별도의 큐를 두어 관리하며 하나의 실린더 또는 트랙에 대한 여러 개의 입출력 요구가 도착할 경우 각 섹터별로 설정되어 있는 큐에 삽입한다. 헤드의 탐색 시간이 끝나고 특정 실린더에 도착한 뒤에 헤드 아래에 먼저 도착하는 순서대로 각 섹터에 대한 서비스를 진행한다.
출처
입출력관리
https://ko.wikipedia.org/wiki/%EB%A9%94%EB%AA%A8%EB%A6%AC_%EB%A7%B5_%EC%9E%85%EC%B6%9C%EB%A0%A5
https://peterleeeeee.github.io/Intro-OS(2)/
디스크 구조와 스케쥴링
