강의 내용 복습
(5강) Model 1
model
일반적으로, object, person, system 의 정보를 표현하는 것
pytorch
low-level
pythonic
flexibility
modules
nn.module family : nn.module을 상속받은 모든 클래스의 공통된 특징
모든 nn.moduled은 child modules를 가질 수 있다.
모든 nn.module은 forward함수를 가진다. 내가 정의한 모델의 forward()를 한번만 실행한 것으로 그 모델의 forward에 정의된 모듈 각각(conv, linear 등등)의 forward가 실행된다.
forward
모델(모듈)이 호출되었을 때 실행되는 함수
parameter
모델에 정의되어 있는 modules가 가지고 있는
계산에 쓰일 parameter
각 모델 parameter들은 data, grad, requires_grad 변수 등을 가지고 있다.
pytorch가 pythonic하기 때문에 모듈의 형식과구조를 미리 알고 여러가지 응용이 가능하고, 발생할 수 있는 에러들도 핸들링 할 수 있다.
Ref
파이토치 Module 문서
(6강) Model 2 - Pretrained model
기존에 검증된 우수한 모델 구조와 미리 학습된 weight를 재사용하는 방법
ImageNet
획기적인 알고리즘 개발과, 검증을 위해 높은 품질의 데이터셋은 필수적이다.
이미 공개되어 있는 다양한 pretrained m odel
torchvision.model
timm
transfer learning
이미지넷으로 학습된 모데릉ㄹ 가져와 우리 task에 적용하는 것
-
cnn base 구조

backbone : cnn 구조로 데이터에서 특징을 추출하는 feature extracter
classifier : fc = fully connevtes layer -
내 데이터와 모델과의 유사성
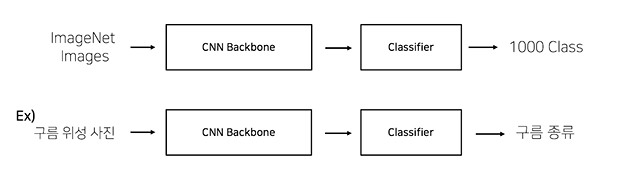 pretraining 할 때 설정했던 문제와 현재 문제와의 유사성을 고려해야 함
pretraining 할 때 설정했던 문제와 현재 문제와의 유사성을 고려해야 함
Case by Case
Case1. 문제를 해결하기 위한 학습 데이터가 충분하다.
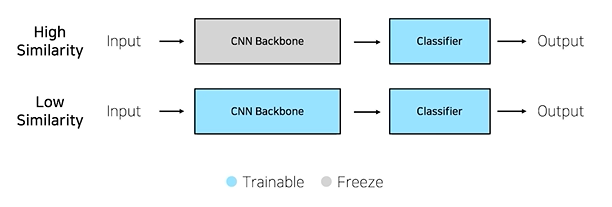
우리가 해야하는 task가 이미지 넷(실생활에 존재하는 1000개의 object 분류)과 유사하다면-실생활에 존재하는 물체 구분, class 갯수만 다르다면 backbone은 학습시킬 필요 없이 freeze하면 됨
만약 유사하지 않다면 (승용차의 브랜드, 차종을 분류, 구름의 종류를 구분하는 위성사진) -backbone까지 함께 학습
Case2. 학습데이터가 충분하지 않은 경우
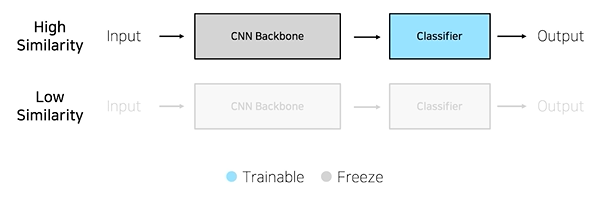
우리가 해야하는 task가 이미지 넷(실생활에 존재하는 1000개의 object 분류)과 유사하다면- classifier만 학습시켜서 어느 정도의 성능을 낼 수 있음
만약 유사하지 않다면- overfitting, underfitting 될 확률 매우 높음
결론은 충분한 데이터와 유사한 task를 가지고 있을 때 transfer learning 을 사용하는데게 이점이 있다.
Further Reading
Facebook AI Research(FAIR) 연구원이자 파이토치 라이트닝 프로젝트 오너인 Falcon 이 작성한 파이토치 성능향상을 위한 7가지 팁
https://towardsdatascience.com/7-tips-for-squeezing-maximum-performance-from-pytorch-ca4a40951259
(번역본 https://bbdata.tistory.com/9)
Tesla 자율주행 연구소 Lead 인 Karpathy 가 트위터에 작성한 Pytorch Common Mistakes 해설
https://medium.com/missinglink-deep-learning-platform/most-common-neural-net-pytorch-mistakes-456560ada037#:~:text=most common neural net mistakes
파이토치 꿀 기능. Autograd 의 official documentation 번역본
과제 수행 과정 및 결과
피어 세션
대회 관련 얘기
- 데이터가 매우 부족하기 때문에 외부 데이터 사용해야함
- 외부데이터 age, gender 라벨링이 힘들다면 pseudo labeling, meta pseudo labeling (self supervised learning)
학습 회고
이번 대회를 통해 데이터가 매우 부족하고 task 도 image net과 맞지 않는 경우 모델의 일반화 성능을 높이기 위한 노력을 많이 하고 있다. 대회 등수도 중요하지만, 이번 대회가 끝나기 전에 배울 수 있는것, 시도할 수 있는 것은 다 해보고 싶다.
