CSPNet: A New Backbone that can Enhance Learning Capability of CNN, IEEE 2020
Intro
ResNet, ResNeXt 및 DenseNet의 inference 에서 heavy inference computation을 완화하기 위한 방법 제시
연산량을 줄임과 동시에 gradient 소실이 일어나지 않도록 하는 것(richer gradient combination)이 목적
Base layer 의 feature map 을 두개로 나누고 cross-stage hierarchy를 통해 merge → gradient infomation이 큰 상관관계를 가지게 되고 정확도 증가, 연산량 감소
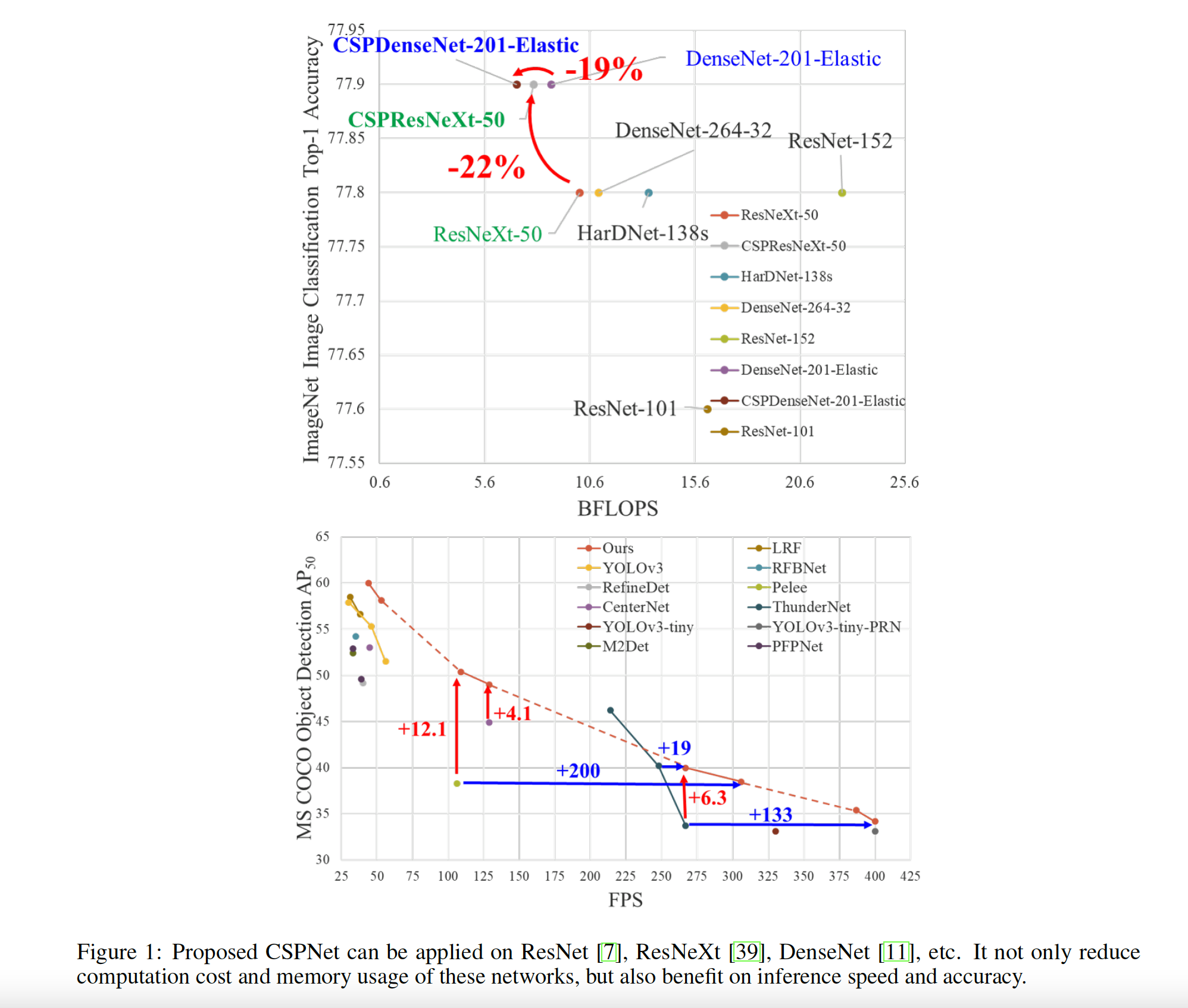
기존의 DenseNet, ResNeXt 과 비교했을 때 CSPNet을 적용했을 때 속도와 정확도가 모두 향상됨
-
CSP Net의 효과 (기존 네트워크의 문제)
-
Strengthening learning ability of a CNN
많은 모델이 경량화되면서 성능이 낮아짐 - 경량화와 동시에 정확도도 유지하려 함
→ ResNet, ResNeXt, and DenseNet 에 CSP Net 적용시 계산량 10%~20% 감소, ImageNet 분류에서 정확도는 더 잘나옴 -
Removing computational bottlenecks
YOLOv3-based model 로 coco data 테스트해봤을 때 computational bottleneck 80% 감소 -
Reducing memory costs
cross-channel pooling 으로 feature pyramid generating 과정에서 feature map 압축
→ Pelee 에서 feature pyramid 만들 때 메모리 사용 75% 감소
-
Abstract
- DenseNet vs CSP Dense Net
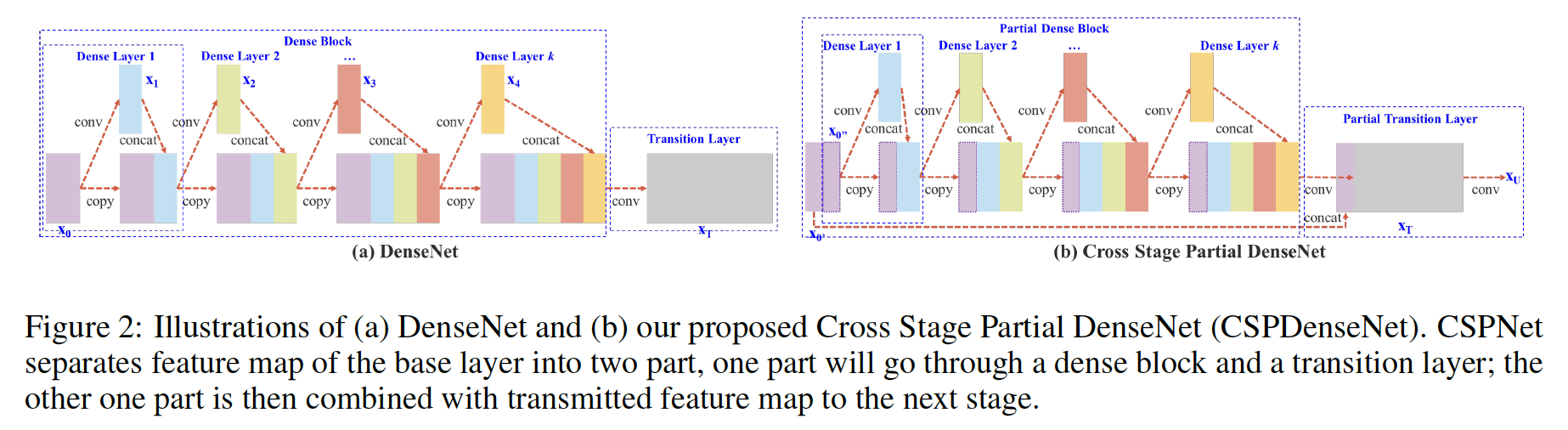
1. Dense Net
순전파 계산은 다음과 같다. 각 layer의 입력을 concat해서 convolution
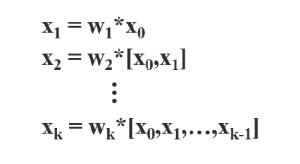
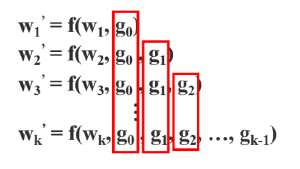
역전파 계산은 다음과 같다. f is the function of weight updating, and gi represents the gradient propagated to the ith dense layer.
각 dense layer 에서 전파되는 gradient information 이 계속 복사되어 재사용됨.
2. Cross Stage Partial DenseNet
base layer 의 feature map 이 두개로 나누어짐. (x0 = x'0, x''0)
x''0은 다음 dense block으로 전달되고, x'0은 stage의 마지막과 연결됨
Dense layer의 출력값(x''0, x1, x2, ... )은 transition layer를 거쳐서 xT가 생성되고, xT는 x'0과 concatenation 되어 다음 transition layer를 통과하여 xU를 생성함
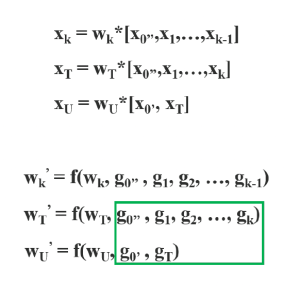
따라서 dense layer를 통과하지 않는 x'0의 gradient 정보는 복사되지 않음.
즉, CSPDenseNet은 DenseNet의 feature reuse 특성을 활용하면서, gradient flow를 truncate하여 과도한 양의 gradient information 복사를 방지함.
-
partial dense block
base layer의 feature map을 절반으로 나눔<설계목적>
-
increase gradient path
-
balance computation of each layer
기존 Dense Layer 는 feature map을 concat하면서 layer를 거칠수록 channel수가 급격하게 증가함
partial dense block을 통해 computational bottleneck을 거의 절반으로 감소시킴 -
reduce memory traffic
-
-
partial transition layer
분할된 feature map을 조합(융합)함<설계목적>
maximize the difference of gradient combination (gradient 조합의 차이를 최대화하는 것)
다른 layer가 중복된 gradient 정보를 학습하는 것을 방지함
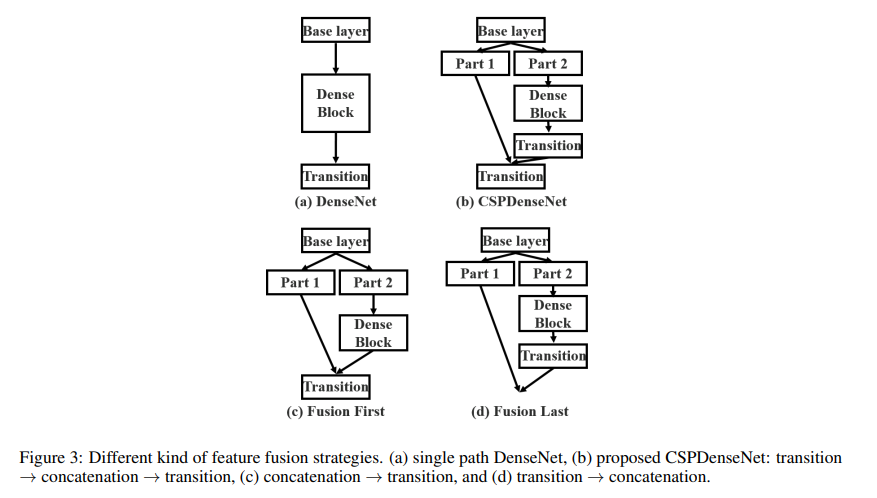
(c) 와 (d)는 다른 fusion strategy.
(c)-Fusion First는 두 파트에서 생성된 feature를 먼저 합친 뒤에 transition 진행
→ 많은 양의 gradient가 재사용됨.
(d)-Fusion Last는 dense block에서 나온 feature map은 transition layer를 거친 후에 base layer에서 나온 feature map과 합쳐짐.
→ grdient flow가 분할되었기 때문에 gradient가 재사용되지 않음.두 전략을 이미지 분류에 적용했을 때의 결과.
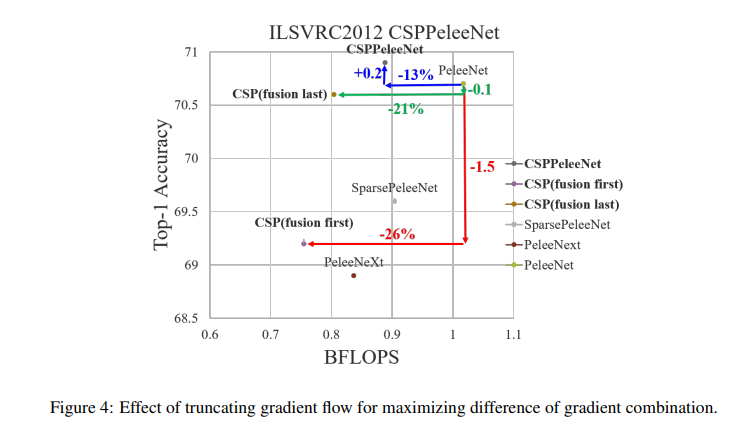
계산 복잡도 : CSP-Fusion first : 26%, CSP-Fusion last : 21% 좋아짐
Top-1 Accuracy : CSP-Fusion last는 오직 0.1%감소, 즉 원래 정확도와 비슷하지만, CSP-Fusion first는 1.5 감소함
Take-Home message
DenseNet 과 같은 구조로 inference 시 feature map 의 채널이 기하급수적으로 늘어나는 구조에서 Cross Stage Partial 구조를 이용하여 연산량은 줄이고 성능은 향상시킴
ref
[논문 읽기] CSPNet(2020)
[논문 읽기] DenseNet (2017)
[논문 읽기] Pre-Activation ResNet(2016) 리뷰
