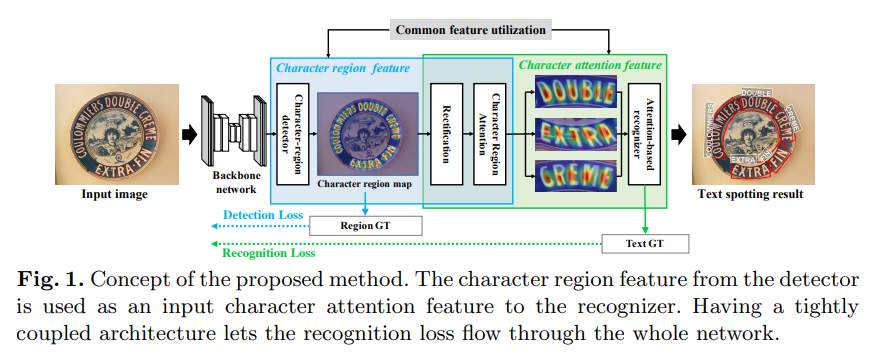
Character Region Attention For Text Spotting
Abstract
scene text spotter = text detection + recognition modules
typical architecture = detection, recognition module 을 다른 브랜치로 두고 feature share를 위해 ROI Pooling
attention decoder와 spatial information을 가지고 있는 detector를 사용하면 더 효율적으로 연결 가능
single pipeline model
recognizer에 들어간 detection output을 활용
dectection stage를 통해 recognition loss 전파
→
character score map 을 사용하여 recognizer가 character center point를 더 잘 인식
detection module로의 recognition loss 전파가 character region localization 성능 향상
Intro
OCR은 horizontal text에서는 잘 작동하지만 scene image는 도전적인 과제였다.
이미지에서 곡선 텍스트를 찾으려면 기존의 탐지 및 인식 모델을 계단식으로 연결하여 각각의 텍스트 인스턴스를 관리하는 것이 일반적인 방법
detector는 복잡한 post-processing technique을 통해 curved text의 geometric attribute를 파악하고,
recognizer는 curved text 인식정확도를 높이기 위해 multi-directional encoding / rectification modules 을 적용했다.
jointly trainable end-to-end network 등장 → 모델 사이즈, 속도를 향상 & shared feature로 성능도 향상→ 대부분 detection, recognition 의 low-level feature layer 를 share 하려고 ROI Pooling 사용
→ 학습 단계에서 전체 네트워크를 학습하는 대신 detection and recognition losses를 사용하여 shared feature layer만 학습
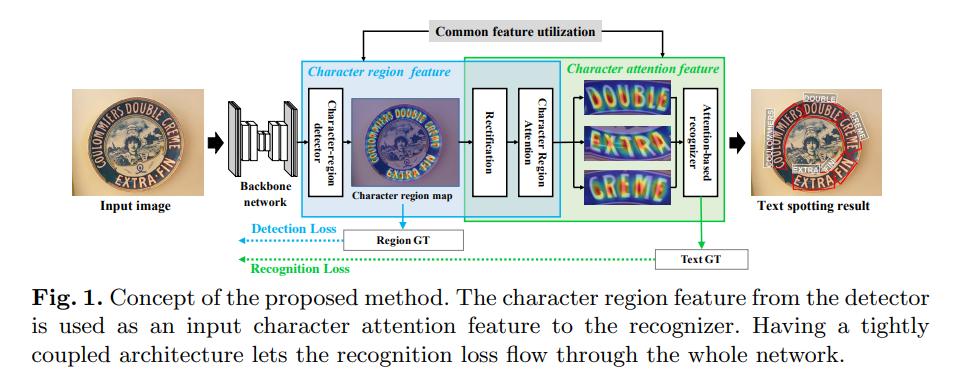
detection and recognition modules 가 완전히 연결된 e2e framework 제안 (CRAFT).
attention based decoder와 문자 공간 정보(character spatial informatinon)를 캡슐화하는 decoder를
사용하는 recognizer가 문자 영역을 localize하는 공통 sub task을 공유한다는 것을 관찰한다.
- 두 module을 결합함으로서 얻는 이점
- character score map 을 사용하여 recognizer가 character center point를 더 잘 인식
- detection module로의 recognition loss 전파가 character region localization 성능 향상
- 공통 sub-task를 통해 feature representation quality 향상
<Contribution 요약>
(1) arbitrary text 를 detect, recognize 하는 end2end network 제안
(2) rectification and recognition module 에서 spatial character information 을 활용하여 모듈간 상호보완
(3) recognition loss를 network 전체로 전파하는 single pipeline 구성
(4) IC13, IC15, IC19-MLT, and TotalText [20,19,33,7] datasets 에서 SOTA 달성
Related Work
Text detection and recognition methods
End-to-end using RNN-based recognizer
End-to-end using CNN-based recognizer
Methodology
Overview
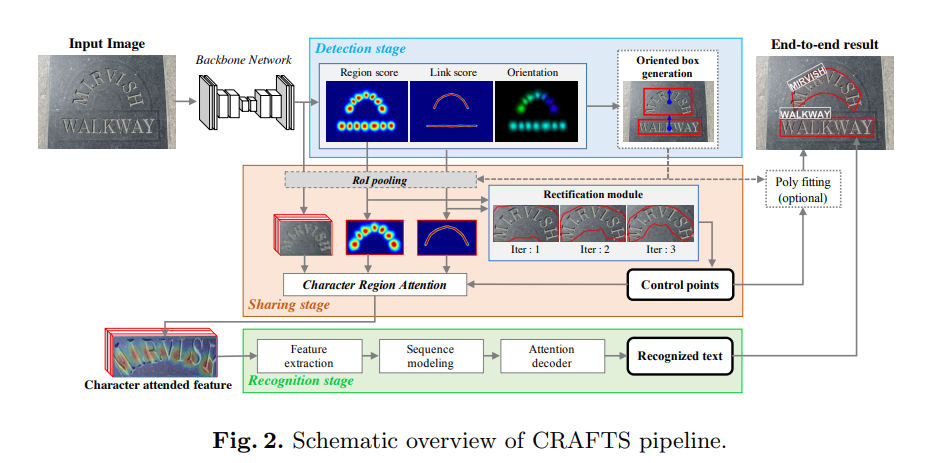
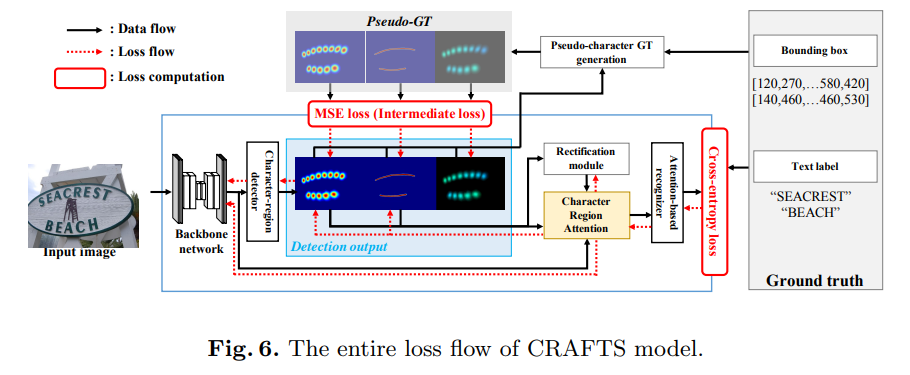
Craft : detection stage, sharing stage, and recognition stage - 3단계로 구성됨
detection stage : input image를 받아 oriented(방향이 있는) text box를 localize
sharing stage : backbone의 high-level feature와 detector output 을 pooling. pooled feature는 rectification module로 rectified된 후 concat해서 character attended feature가 됨
recognition stage : attention-based decoder 가 character attended feature를 사용하여 text label 예측
Detection Stage
base network : CRAFT
CRAFT의 output : center probability of character regions, linkage between them
문자의 중심 information이 recognizer의 attention module을 support하는데 사용됨. 두 모듈 모두 문자의 중심 위치를 찾는 것이 목적이기 때문에.
CARFT 모델에서 변경한 3가지
-
backbone replacement
VGG16 → ResNet50 (feature representation 잘 잡음) -
link representation
동아시아 지역에서 잘 보이는 세로로 써진 글씨 - binary center line은 sequential character region을 연결하는데 사용
세로 텍스트에 original affinity maps을 사용하는 것이 종종 잘못된 위치 원근법 변환( ill-posed perspective transformation )을 생성하여 잘못된 상자 좌표를 생성했기 때문 → 기존 가로로 쓴 글자는 문자박스의 대각선을 이어 만든 위, 아래 삼각형 이용, but vertical text는 좌우 삼각형을 이용해야 함 (좌우는 뇌피셜)
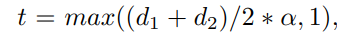
GT linkmap을 만들기위해 인접한 문자사이에 두께 t인 line segment를 그림. d1, d2 는 인접한 문자 박스 사이의 대각선 길이, 알파는 scaling coefficient. 위의 방적식 사용하면 center line의 width가 문자의 크기에 비례할 수 있다. 구현시 알파는 0.1 로 설정
-
orientation estimation
방향까지 잘 정의된 box coordinates 가 잇어야 text를 적절히 인식 가능
이를 위해 detection stage에서 two-channel outputs 을 추가 - 문자의 x축, y축 각각의 각도를 예측하는데 사용된다
orientation map의 GT 를 생성하기 위해, GT c-box의 upward angle을 θbox라고 하면
x축을 예측하는 채널은 Scos(p) = (cos θ+1)×0.5, 값을 가지고, y축을 예측하는 채널은 Ssin(p) = (sin θ + 1) × 0.5 값을 가진다.
orientation map의 GT 는 word box 내에 있는 픽셀값을 Scos(p), S*sin(p) 로 채워서 만든다.
삼각함수는 채널이 region map 과 link map 과 동일한 출력 범위(0과 1 사이)를 갖도록 하지 않음.orientation map 의 loss function
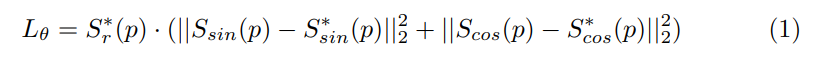
Ssin(p), Scos(p)는 text orientation GT. region map Sr(p)는 weighting factor : 문자 중심인지에 대한 confidence score이기 때문에 가중치로 쓰면 orientation loss가 positive character region인 곳에 대해서만 계산을 함
detection stage의 최종 loss Ldet

Lr and Ll denote character region loss and link loss, Lθ is the orientation loss, 람다는 0.1
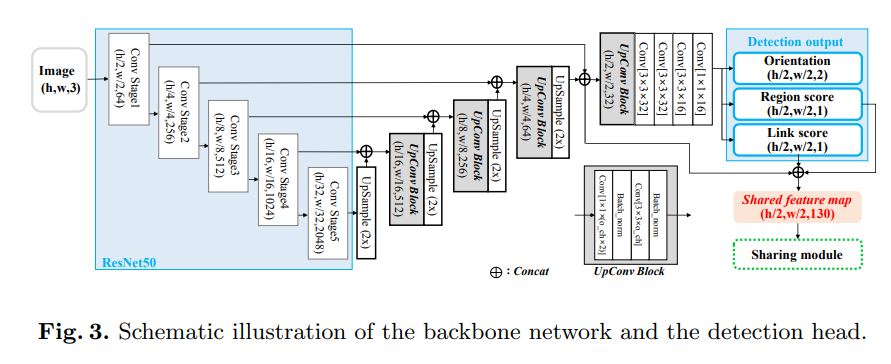
detector의 final output은 4개의 채널, character region map Sr, character link map Sl, and two orientation maps Ssin, Scos
inference에는 CRAFT와 동일한 post-processing : Sr , Sl을 사용하여 CCL, 최종 결과는 text영역을 최소한으로 감싸는 bbox
추가적으로 pixel-wise average 를 활용하여 bbox의 방향 결정
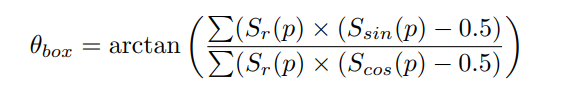
θbox denotes orientation of the text box, Scos and Ssin are the 2-ch orientation outputs
손실 계산에 사용된 것과 동일한 character centerdeness-based weighting scheme(:region map value로 pixel별 가중치 주는 것)가 방향 예측에도 적용된다.
Sharing Stage
: text rectification module and character region attention(CRA) modules 두 가지 모듈로 구성
- text rectification module

arbitrarily-shaped text 영역을 조정(rectify)하기 위해서 thin-plate spline (TPS) transformation 이 사용된다.
더 나은 text 영역을 얻기 위해 반복 TPS 사용 - control points를 업데이트하면서 이미지 내에서 텍스트의 곡선 형상이 개선된다.
실험 결과 3번 반복하면 충분
일반적인 TPS 모듈의 입력 : 단어 이미지
e2e craft TPS 모듈의 입력 : character region map and link map (text 영역의 기하학적 정보를 담고 있기 때문)
20개의 control point 는 detection 결과로 사용하기 위해 원래 입력 이미지 좌표로 변환된다. 부드러운 bounding polygon을 위해 2D polynomial 수행
- character region attention module
detection과 recognition 모듈을 묶어주는 핵심 역할.
rectified character score map 과 feature representation 을 단순히 concat 시켜줌으로서 다음과 같은 이점을 얻는다.- detector와 recognizer를 이어줌으로써 recognition loss가 detection stage까지 전파
- 이것이 character score map의 퀄리티를 좋게 만듬
- character region map과 feature를 붙여 recognizer가 character 영역을 더 잘 파악하게 함
Recognition Stage
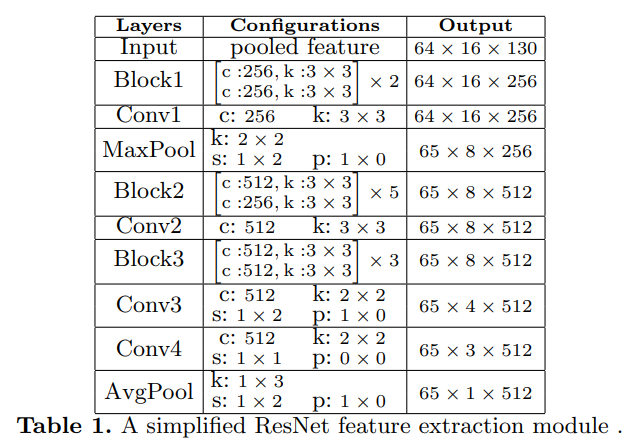
3개의 componenet로 구성된다.
(1) feature extraction : lighter then a solitary recognizer since it takes high-level semantic features as input.
(2) sequence modeling : bi LSTM
(3) prediction : attention based decoder
-
recognition stage object function
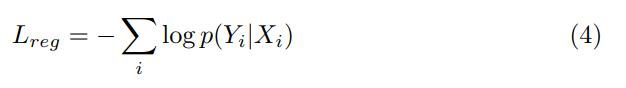
p(Yi|Xi) : 문자 시퀀스 생성 확률→ ?
Yi : cropped feature representation, Xi : e i-th word box -
final loss
L = Ldet + Lreg
Experiment
-
Datasets
English dataset : IC13, IC15, TotalText
Multi-language dataset : IC19 -
Training strategy
detection : weakly-supervised training
recognition : 각 이미지에서 랜덤샘플링된 crop word image로 배치만들어서 loss 계산
이미지 당 단어의 최대개수 : 16 (oom 막으려고)
data augmentation in the detector : crops, rotations, and color variations
data augmentation in the redognizer : the corner points of the ground truth boxes are perturbed in a range between 0
to 10% of the shorter length of the box모델을 처음에 SynthText 데이터로 50k iter 학습시킨 후 target dataset으로 학습시킴
optimizer : Adam
OHEM : 1:3 of positive : negative pixles in the detection loss
fine tunning : SynthText dataset is mixed with the ratio of 1:5Experimental Results
Ablation study
Discussions
Conclusion
detection , recognition 모듈을 결합한 end-to-end trainable single pipeline model 제시
→ sharing stage의 CRA는 recognizer가 text 영역을 더 잘 인식하게 함
→ recognition loss가 detection stage까지 전파되어 character localization 성능 향상
→ sharing stage의 rectification module이 curved-text의 세밀함 localization을 가능하게 하고, 수작업이 들어간 후처리 필요없음
