DECOUPLING REPRESENTATION AND CLASSIFIER FOR LONG-TAILED RECOGNITION, ICLR 2020
official code
Background
- long-tail distribution
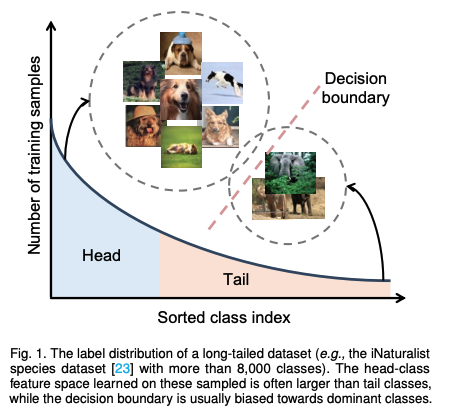
long-tail distribution 이란 위 그림과 같이 class 갯수의 분포가 극명하게 차이나는 데이터셋을 말함. 갯수가 많은 class를 head class, 적은 class를 tail class 라고 하는데, head class 의 갯수는 적고 tail class의 갯수가 많아서 분포 그래프를 그려봤을 때 긴 꼬리가 달린듯 하여 long-tail 이라고 부름.
이런 데이터의 decision boundary는 head class(dominant class)에 편향되게 학습되고, 따라서 tail class에서는 극심한 성능 저하가 일어남.
Abstract
- long-tail distribution (이하 LTD) dataset은 class imbalance 를 어떻게 해결할 것인지가 이슈였음. 본 논문에서는 representation learning과 classification을 분리하여 2 stage 로 학습하는 전략을 통해 LTD dataset에서 성능을 향상시킴
- ImageNet-LT, Places-LT and iNaturalist와 같은 long-tailed dataset 에서 SOTA 달성
Related Work & Motivation
이전까지는 LTD dataset을 다루기 위해 loss re-weighting, data re-sampling, or transfer learning from head to tail-classes 와 같은 연구가 진행됨.
- Class-balanced Losses (loss re-weighting)
Focal loss와 같이 class의 분포에 따라 loss의 가중치를 조절하여 weight 학습을 다르게 하는 방법.
affinity measure을 사용하여 head class, tail class 의 분류 영역을 조절하여 각 class의 cluster 중심이 균일한 간격과 거리에 있도록 하는 방법이나
속한 데이터 개수가 작은 few-shot class가 더 넓은 margin을 가지게끔 하는 LDAM Loss 도 있음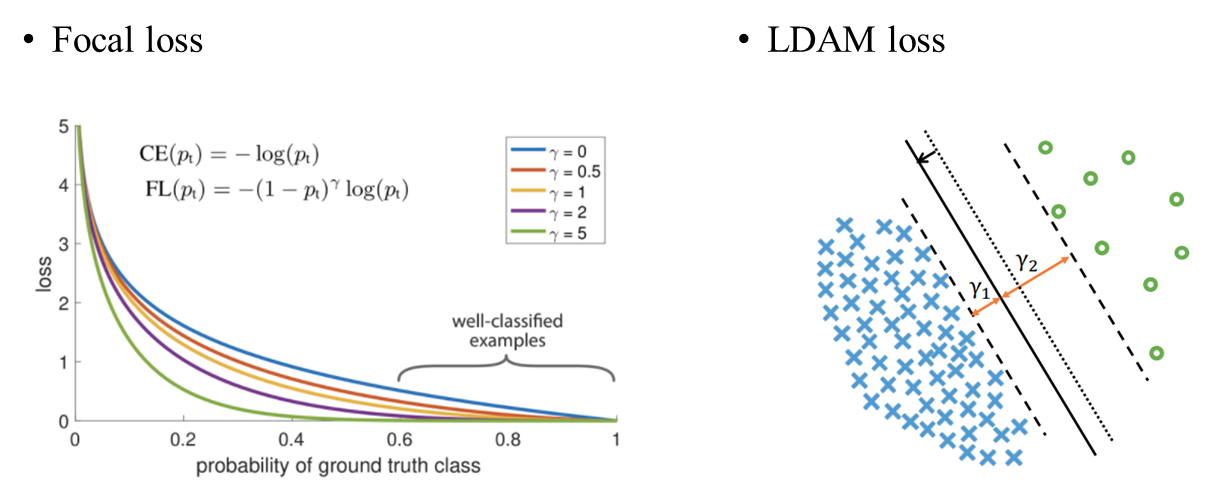
-
Data distribution re-balancing (data re-sampling)
balanced data distribution을 얻기 위해 data를 re-sampling하는 방법.
갯수가 적은 class의 data를 늘리는 over sampling, 갯수가 많은 class의 data를 삭제하는 under sampling, 각 class의 갯수에 의거한 class-balanced sampling 방법이 있다. -
transfer learning from head to tail-classes
데이터가 풍부한 head class에서 학습한 특징을 tail class로 전이하여 학습하는 방법.
transferring the intra-class variance(class 내 분산 전이), transferring semantic deep features와 같은 방법이 있는데, 이런 방법은 feature transfer를 위한 복잡한 memory module을 설계해야함.
위의 연구들은 모두 데이터의 representation을 추출하는 backbone 학습과 데이터의 decision boundary를 학습하는 classifier를 함께 학습함. (joint learning)
그러나 joint learning은 모델이 data representation을 잘 학습해서 성능이 잘 나오는지, 아니면 classifier가 decision boundary를 잘 조정하여 class imabalance 문제를 해결했기 때문에 성능이 잘 나오는지 확인할 수 없음.
따라서 저자들은 이를 확인하기 위해 joint learning을 (1)representation learning (2)classification 두 가지로 나누어 진행함.
(1) representation learning
다양한 sampling strategies를 사용하여 모델을 학습시킴
(2) classification
representations 학습 이후, classifier를 통해 decision boundary를 조정함. 이때 classifier만 재훈련하는 방법, 재훈련 없이 representation을 사용하여 nearest class mean classifier로 교체하는 방법, classifier 가중치 정규화와 같은 방법을 사용함.
실험의 결과는 다음과 같음.
- decoupled learning이 LTD dataset recignition에서 좋은 성능을 보임
- classifier 재훈련 없이 representation을 이용해 decision boundary를 조정하는 것이 LTD dataset 인식에 효과가 있다는 실험 결과
- ResNeXt과 같은 standard network에 decoupled learning을 적용했을 때 이전 연구 (different sampling strategies, new loss designs and other complex modules)보다 LTD에서 더 좋은 성능을 보임
- OLTR(representation learning에서는 instance-balanced sampling을 사용하여 학습하고 이후 class-balanced sampling을 사용하여 fine tuning하는 방법), LDAM(few-shot class의 decision boundary를 확장하는 label-distribution-aware margin loss 제안)과 같이 추가적인 메모리를 필요로 하는 sampling, balanced loss 를 사용한 방법과 비교했을 때 decoupled learning은 추가적인 memory module 없이 높은 성능을 달성함
Methods : LEARNING REPRESENTATIONS FOR LONG-TAILED RECOGNITION
- Notation
논문에서 사용할 notation을 먼저 설명.- : training set
- : data point, label
- : class 에 해당하는 sample 갯수
- : traing sample의 총 갯수 ( : class의 총 갯수)
- class index : 각 class에 속하는 sample의 개수가 많은 순서대로 정렬
- long-tail setting에 의해
- : x의 representation
- : classifier 가 예측한 값
- : a linear classifier
- : training set
-
Sampling strategies
네가지의 sampling strategies를 사용함.: class j에 속하는 sample이 뽑힐 확률
: 0과 1사이의 값으로, sampling stratgy를 조절하는 인자-
Instance-balanced sampling
- q=1
- training set 의 모든 sample이 뽑힐 확률이 같음.
- class j에 속하는 sample이 뽑힐 확률은 class의 cardinality 와 같음
-
Class-balanced sampling
- q=0.
- 모든 class는 뽑힌 확률이 모두 같음 ()
- 2 stage sampling strategy라고도 볼 수 있는데, 우선 class가 uniform하게 선택되고, class에 속하는 instance를 uniform하게 선택함
-
Square-root sampling
- 앞의 두가지 방법의 혼합
- q=1/2
-
Progressively-balanced sampling
- 위의 모든 방법을 조합함
- 처음 학습 할 때는 instance-balanced sampling을 사용하고 학습이 진행됨에 따라 class-balanced sampling을 사용하는 방법
- .
- : current epoch, : total epoch
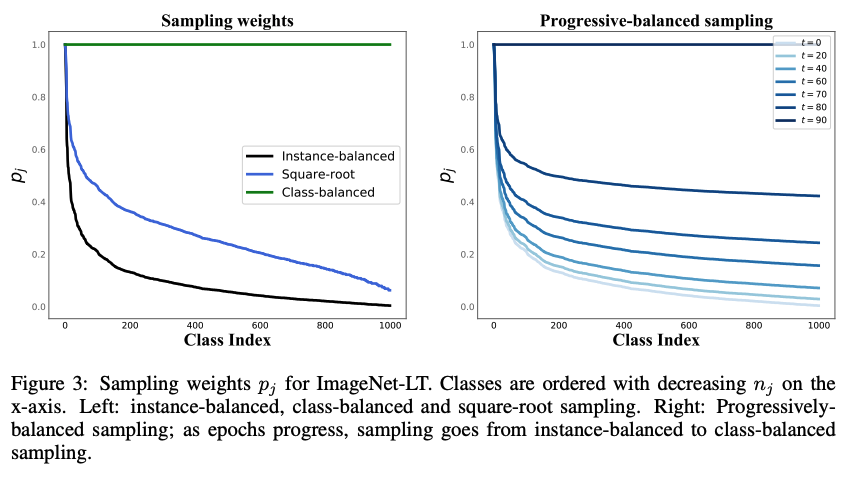
-
- Loss re-weighting strategies
imbalanced data를 위한 Loss re-weighting functions은 많은 연구가 되어 왔지만 훈련 및 재현이 어렵고, dataset-specific한 하이퍼 파라미터 튜닝이 필요하기 때문에 모든 loss를 테스트하진 못했고 몇가지를 테스트한 결과를 첨부함
또한 properly balanced classifier가 latest loss re-weighting approaches보다 좋지는 앉지만 동등한 성능을 낸다는 것을 실험으로 보임
Methods : CLASSIFICATION FOR LONG-TAILED RECOGNITION
Representation learning에서 사용된 classifier은 로 구성된 linear classifier :
(다른 classifier도 실험함)
이 섹션에서는 다른 sampling strategy를 사용하여 fine tuning을 통해 classifier의 decision boundary를 조정하거나 non-parametric nearest class mean classifiers를 사용하는 방법, 추가적인 학습 없이 classifier weights 을 재조정하는 네가지 방법을 소개함. 그리고 이들은 classifier을 재조정하지 않은 Joint learning scheme과 비교됨.
- Classifier Re-training (cRT)
- class-balanced sampling을 사용하여 classifier를 재학습하는 방법.
- representations는 고정하고 randomly re-initialize된 linear classifier를 적은 epoch 학습함
- Nearest Class Mean classifier (NCM)
- training set의 feature representation의 mean을 계산하여 cosine similarity(또는 Euclidean distance) on L2 normalized mean features 를 사용하여 nearest neighbor search 를 수행
- cosine similarity는 정규화를 통해 weight imbalance problem을 완화함
- τ -normalized classifier (τ -normalized)
- Instance-balanced sampling을 이용한 joint learning (representation learning+classifier learning) 이후, classifier의 각 weight의 norm 가 class에 속하는 sample의 수 와 연관성이 있음을 발견.
- class-balanced sampling을 이용한 classifier fine tuning 이후, classifier weights의 norm이 더욱 비슷해짐을 발견
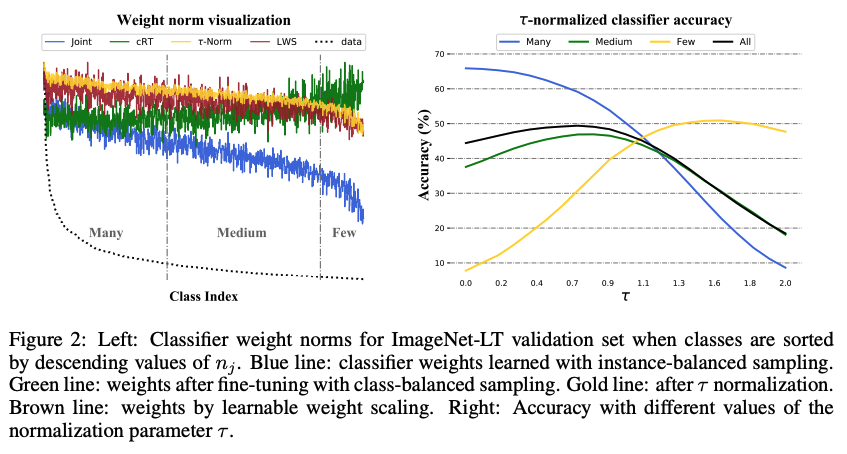
- 따라서, classifier re-training을 거치지 않고, 단순히 이 norm 값들만 재조정해준다면 비슷한 효과가 있지 않을까? 라는 생각으로 class imbalance를 완화하고자 함.
: class j에 상응하는 classifier weights
: 조정한 weights
: hyper-parameter controlling the “temperature” of the normalization, 0이면 no scaling, 1이면 일반 L2 norm
: L2 norm
논문에서는 validation set을 통해 를 탐색함
- Learnable weight scaling (LWS)
- τ -normalization의 일종으로, 각 class에 해당하는 weight의 magnitude를 조정하는 방법
- representation과 classifier를 모두 고정하고 class-balanced sampling을 통해 scaling factor 만 학습함.
- τ -normalization의 일종으로, 각 class에 해당하는 weight의 magnitude를 조정하는 방법
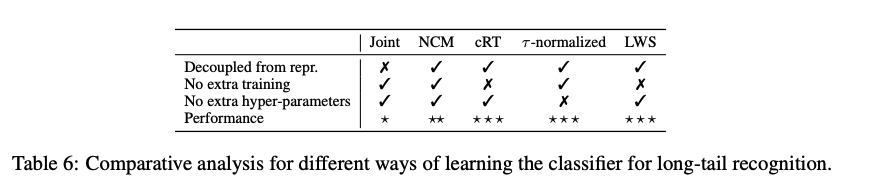
Table 6 :classifier 비교 표
Experiments
-
setup
- Datasets
large-scale long-tailed datasets : Places-LT, ImageNet-LT, iNaturalist 2018 사용 - Evaluation Protocol
top-1 accuracy를 사용했으며, 모든 class (All), 100장 이상 image를 포함한 class (Many-shot), 20~100장의 image를 포함한 class (Medium-shot), 20장 이하의 image를 포함한 class (Few-shot)로 분류하여 결과를 report - Implementation
PyTorch를 이용했으며, ResNet, ResNext 등을 backbone으로 사용. Representation learning stage에서는 90 epoch, cRT나 LWS 등 classifier의 학습이 필요한 경우에는 10 epoch동안 훈련시킴
- Datasets
-
SAMPLING STRATEGIES AND DECOUPLED LEARNING
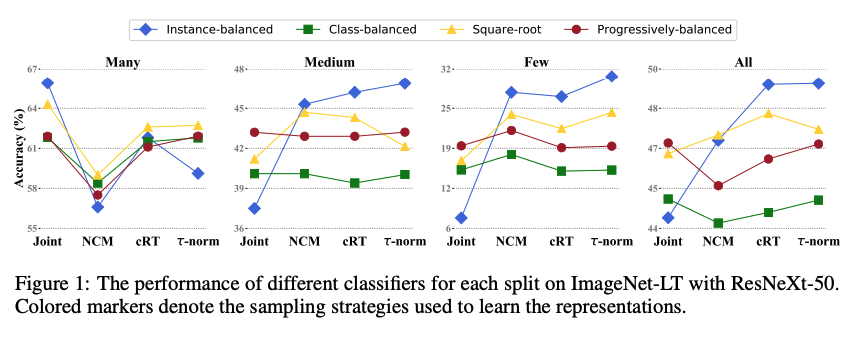
Method에서 소개한 네가지의 sampling stratgy와 네가지 classifier 대체 전략을 사용한 실험 결과. 분석 결과는 다음과 같다.- Sampling matters when training jointly
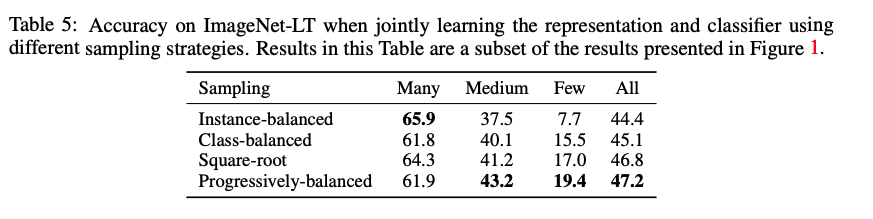
joint training에서는 medium- and fewshot classes 에서 progressively-balanced sampling이 좋은 성능을 내는 반면 many-shot classes에서는 instancebalanced sampling이 좋은 성능을 냄.
즉 더 나은 sampling staragy를 쓸수록 성능이 향상되었으며 지금까지의 연구방향과 일치함 - Joint or decoupled learning?
many-shot case를 제외하고 Decoupled method를 사용하는 것이 항상 더 좋은 결과를 보임
decoupled learning의 효과를 증명하기 위해 backbone 과 linear classifier의 범위를 바꾸어가며 실험해본 결과 only retraining the linear classifier
and fixing the representation 일 때 가장 좋은 성능을 보임
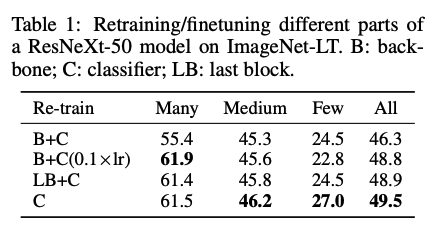
- Instance-balanced sampling gives the most generalizable representations
모든 decoupled methods중에서, 의외로 instance balanced sampling 을 사용했을 때 성능이 잘 나옴. 이는 "high-quality representations를 학습하는 데에 class imbalance가 큰 영향을 미치지 않을 수 있다"는 것을 의미함.
- Sampling matters when training jointly
-
HOW TO BALANCE YOUR CLASSIFIER?
Fig1 을 다시 보면, Training 과정이나, data imbalance 해소를 위한 추가적인 sampling strategy의 사용을 필요로 하지 않는 NCM과 τ-norm이 cRT와 비슷하거나 더 높은 성능을 보임 (many shot case에서만 큰 성능하락이 있음)
이러한 성능 향상은 decision boundary를 재조정하면서 얻은 이익일 것으로 예상함
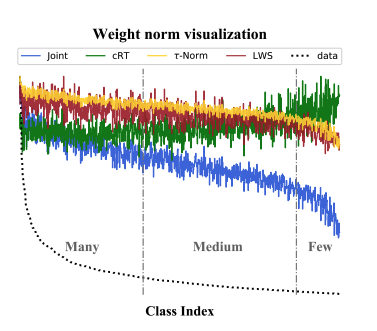
위의 그래프를 보면 joint classifier의 weight class 분포에 상응함을 볼 수 있는데, 이는 class 갯수가 많을 수록 classifier가 larger magnitude를 가짐을 의미함.
이는 feature space에서 wider decision boudary를 형성하여 데이터가 많은 class에서는 좋은 성능을, 적은 class에서는 낮은 성능을 냄 (아래 Fig4 참고)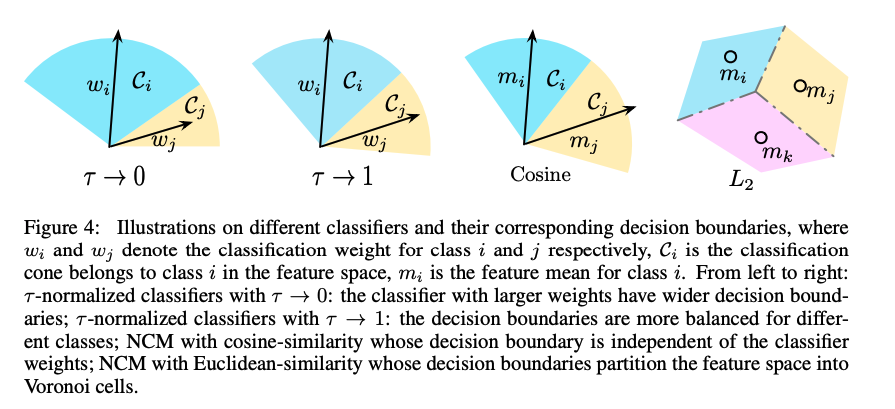
Fig 4: classifier가 decision boundary에 미치는 영향.
: class i,j의 weights
: feature space에서 class i에 속하는 classfication cone(?)
: class i의 feature mean
(1) τ 가 0일때 τ -normalized classifier : 큰 weight을 가질수록 decision boundary도 넓게 형성
(2) τ 가 1일때 τ -normalized classifier : 서로 다른 class에 대한 decision boundary가 조금 더 balanced 하게 형성
(3) NCM with cosine-similarity : decision boundary가 class weight와 independent하게 형성됨
(4) NCM with Euclidean-similarity : decision boundary가 feature space를Voronoi cells로 분할함따라서 τ -normalized classifiers에서 τ 가 커질수록, many-shot accuracy가 급격히 감소했으며 few-shot accuracy가 급격히 증가함
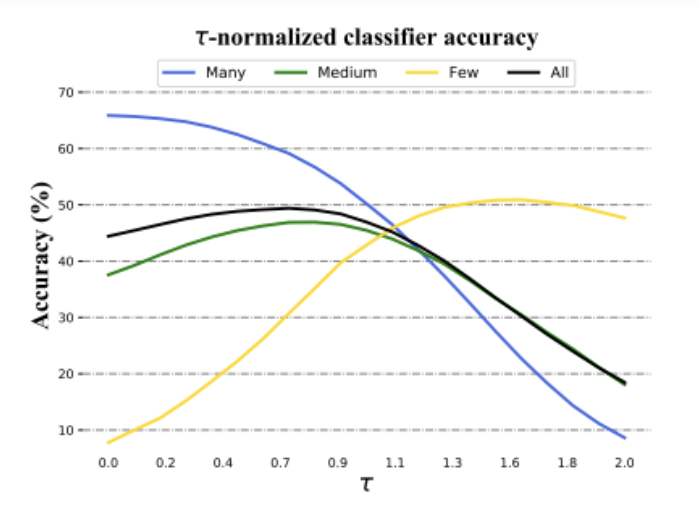
-
COMPARISON WITH THE STATE-OF-THE-ART ON LONG-TAILED DATASETS
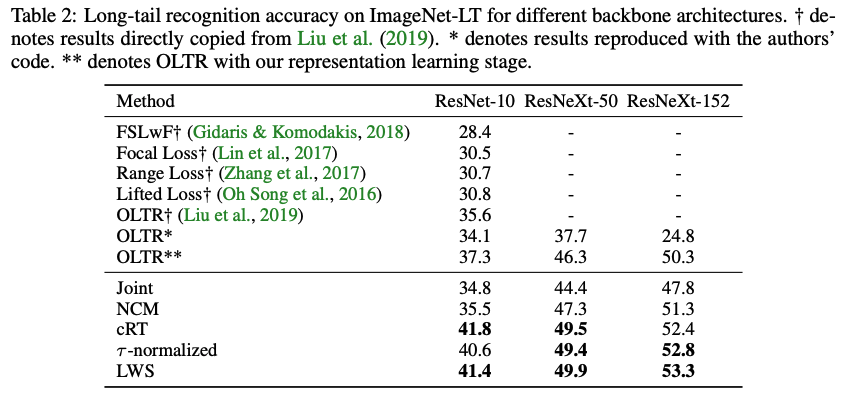
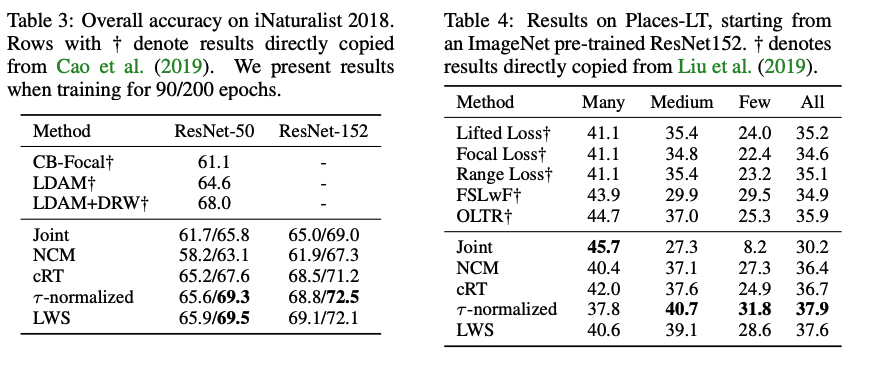
Conclusions
- long-tailed recognition에서 representation and classifier를 분리하는 decoupled methods 제안
- Representation과 classifier의 joint learning과, 다양한 decoupled method를 비교함
- Joint learning의 경우 sampling strategy가 유의미한 영향을 끼쳤으나, 무작위 추출인 instance-balanced sampling이 가장 generalizable representation을 학습할 수 있었으며 복잡한 loss나, memory unit 등 없이도 classifier weight의 re-balancing 이후에 SOTA 성능을 보임
Ref
Deep Long-Tailed Learning: A Survey
복만님 paper review : [딥러닝 논문리뷰] Decoupling Representation and Classifier for Long...
