RAG(Retrieval-Augmented Generation)란 무엇인가?
LLM이 "모르는 것"을 알게 만드는 기술
목차
- RAG가 왜 필요한가?
- RAG의 구조
- RAG에서 Embedding Model의 역할
- Retrieval — Sparse vs Dense Retrieval
- Embedding Model은 꼭 같은 모델을 써야 할까?
- 임베딩 모델의 두 가지 인코딩 방식
- 이전 모델 vs 최신 Embedding Model 비교
1. RAG가 왜 필요한가?
ChatGPT나 Claude 같은 LLM(대형 언어 모델)은 방대한 양의 텍스트로 사전 학습되어 있습니다. 하지만 이 모델들에게는 치명적인 한계가 두 가지 있습니다.
첫째, 지식의 시간적 한계입니다. 학습 데이터에 포함된 시점까지의 정보만 알고 있습니다. 어제 발표된 뉴스나 오늘 업데이트된 사내 문서는 알 수 없습니다.
둘째, 사내 비공개 정보를 모릅니다. 우리 회사의 내부 규정, 제품 매뉴얼, 고객 데이터는 공개 인터넷에 없기 때문에 학습된 적이 없습니다.
이 두 문제를 해결하기 위해 등장한 것이 RAG(Retrieval-Augmented Generation)입니다. 쉽게 말해, LLM이 답변하기 전에 관련 문서를 먼저 찾아서(Retrieval) 참고하게 만드는 방식입니다. 인터넷 검색 기능이 없는 사람에게 참고 자료를 쥐어주는 것과 같습니다.
2. RAG의 구조
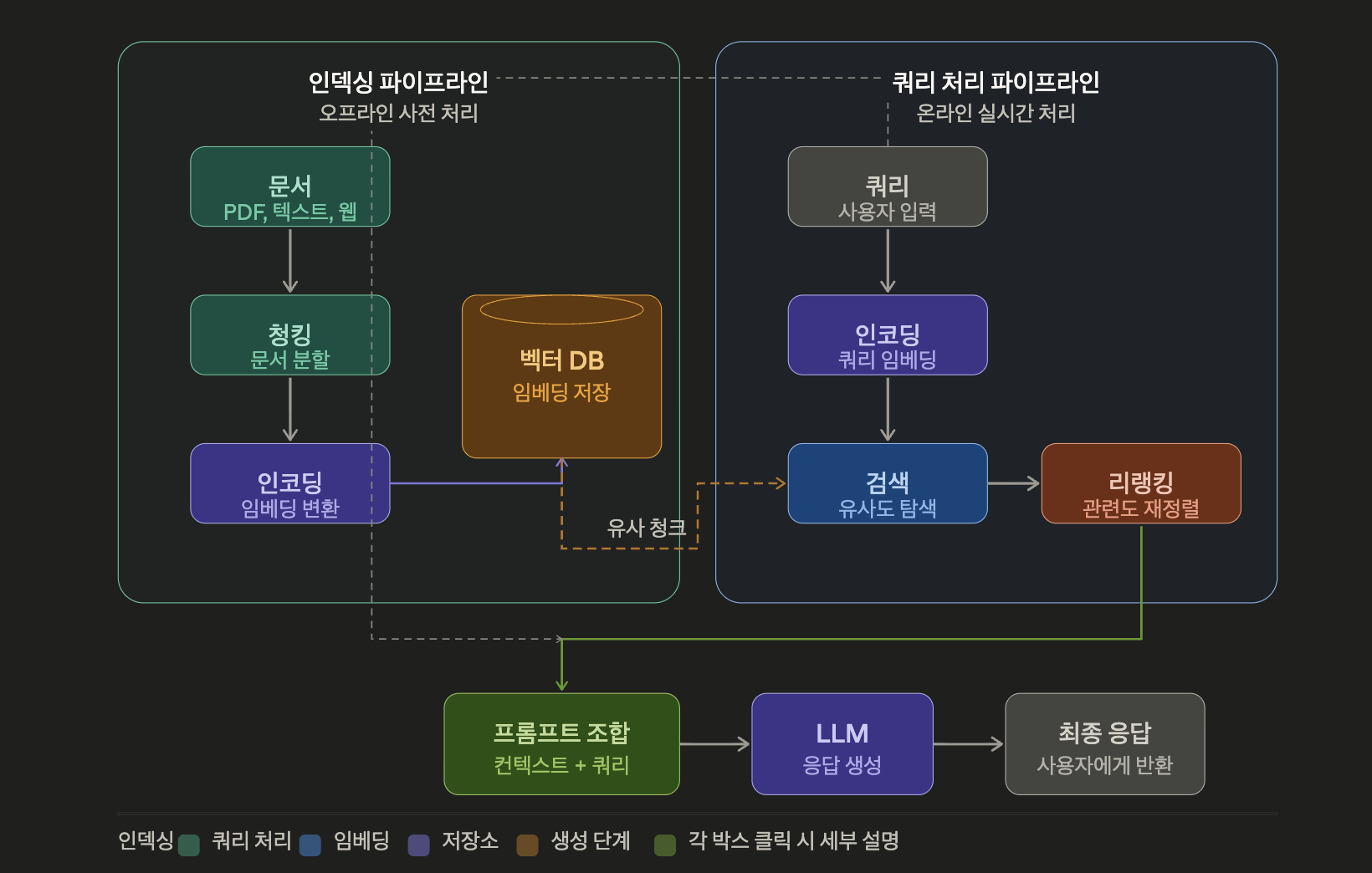
RAG는 크게 두 개의 파이프라인으로 나뉩니다. 오프라인에서 미리 처리하는 인덱싱 파이프라인과 사용자 요청이 들어올 때 실시간으로 동작하는 쿼리 처리 파이프라인입니다.
인덱싱 파이프라인 (오프라인, 사전 처리)
사용자의 질문이 들어오기 전, 검색 가능한 형태로 문서를 미리 가공해두는 단계입니다.
문서 (PDF, 텍스트, 웹 등)
↓
청킹 (Chunking) — 문서를 적절한 크기로 분할
↓
인코딩 (Encoding) — 각 청크를 숫자 벡터로 변환
↓
벡터 DB — 변환된 벡터를 데이터베이스에 저장청킹(Chunking) 은 긴 문서를 LLM이 처리하기 적합한 크기로 잘라내는 과정입니다. 너무 짧으면 문맥이 끊기고, 너무 길면 검색 정확도가 낮아집니다. 일반적으로 256~512 토큰 단위로 나누며, 문단 경계나 문장 단위를 기준으로 나누기도 합니다.
인코딩(Encoding) 은 텍스트를 고차원의 숫자 벡터로 변환하는 과정입니다. 이 벡터는 텍스트의 '의미'를 수치로 표현한 것으로, 의미가 비슷한 텍스트끼리는 벡터 공간에서 가까운 위치에 놓이게 됩니다.
벡터 DB 는 이렇게 만들어진 수백만 개의 벡터를 저장하고, 빠르게 유사도 검색을 수행할 수 있는 특수한 데이터베이스입니다. 대표적으로 Pinecone, Weaviate, Qdrant, FAISS 등이 있습니다.
쿼리 처리 파이프라인 (온라인, 실시간)
사용자가 질문을 입력하는 순간부터 시작됩니다.
사용자 쿼리 입력
↓
인코딩 (쿼리를 벡터로 변환)
↓
검색 (벡터 DB에서 유사한 청크 탐색)
↓
리랭킹 (검색 결과의 관련도를 재정렬)
↓
프롬프트 조합 (원본 쿼리 + 검색된 컨텍스트)
↓
LLM 응답 생성
↓
최종 응답 반환리랭킹(Reranking) 은 벡터 검색이 반환한 수십 개의 후보 문서 중, 실제로 질문에 가장 유용한 문서를 다시 정렬하는 과정입니다. 벡터 유사도만으로는 놓치는 미묘한 관련성을 Cross-Encoder 등의 모델로 보완합니다.
프롬프트 조합 단계에서는 사용자의 원래 질문과 검색된 문서 조각들을 하나의 프롬프트로 합칩니다. 예를 들면 아래와 같은 형태입니다.
[시스템]
다음 문서를 참고하여 질문에 답변하세요.
[참고 문서]
(검색된 청크 1) ...
(검색된 청크 2) ...
[사용자 질문]
우리 회사 환불 정책이 어떻게 되나요?LLM은 이 프롬프트를 받아, 자신의 사전 학습 지식과 제공된 문서를 함께 참고하여 정확한 답변을 생성합니다.
3. RAG에서 Embedding Model의 역할
Embedding Model(임베딩 모델)은 RAG의 핵심 부품입니다. 텍스트를 숫자 벡터로 변환하는 이 모델이 없으면 RAG 자체가 동작하지 않습니다.
임베딩 모델이 하는 일을 직관적으로 이해하려면, 지도 위에 단어를 찍는다고 생각해보세요.
- "고양이"와 "강아지"는 지도 위에서 서로 가까운 곳에 찍힙니다.
- "고양이"와 "주식"은 아주 먼 곳에 찍힙니다.
- "애플은 쿠퍼티노에 본사를 뒀다"는 "아이폰 만드는 회사는 어디야?"와 가까운 곳에 찍힙니다.
이 '지도'가 바로 벡터 공간입니다. RAG에서 임베딩 모델은 두 번 사용됩니다.
| 시점 | 역할 |
|---|---|
| 인덱싱 시 (오프라인) | 문서 청크들을 벡터로 변환하여 DB에 저장 |
| 쿼리 처리 시 (실시간) | 사용자 쿼리를 벡터로 변환하여 DB에서 유사 벡터 탐색 |
결국 "질문 벡터와 가장 가까운 문서 벡터를 찾는 것"이 RAG 검색의 본질입니다. 임베딩 모델의 품질이 곧 검색 품질을 결정하는 이유가 여기에 있습니다.
4. Retrieval — Sparse vs Dense Retrieval
문서를 검색하는 방법에는 크게 두 가지 접근이 있습니다. 오래된 방식인 Sparse Retrieval과, 딥러닝 기반의 Dense Retrieval입니다.
Sparse Retrieval (희소 검색)
대표적인 알고리즘은 BM25입니다. 검색 엔진(예: Elasticsearch)에서 오랫동안 사용해온 방식으로, 단어의 출현 빈도를 기반으로 문서의 관련도를 계산합니다.
동작 원리: 질문에 포함된 단어가 문서에 얼마나 자주, 얼마나 독특하게 등장하는지를 점수로 계산합니다.
장점:
- 빠르고 가볍습니다.
- "GPT-4o" 같은 정확한 고유명사 검색에 강합니다.
- 별도의 GPU가 필요 없습니다.
단점:
- 단어가 일치해야만 검색됩니다. "아이폰 만드는 회사"를 검색하면 "애플"이 적힌 문서를 찾지 못할 수 있습니다.
- 동의어, 패러프레이징에 취약합니다.
Dense Retrieval (밀집 검색)
임베딩 모델을 사용해 텍스트를 벡터로 변환한 뒤, 벡터 간 코사인 유사도로 관련성을 판단합니다.
동작 원리: 단어의 일치가 아닌, 문장의 의미적 유사성을 기반으로 검색합니다.
장점:
- 단어가 다르더라도 의미가 같으면 찾아냅니다.
- 문맥 이해가 필요한 복잡한 질문에 강합니다.
단점:
- 임베딩 모델 학습 및 추론에 컴퓨팅 자원이 필요합니다.
- "GPT-4o-mini" 같은 정확한 키워드 검색에서는 오히려 BM25보다 부정확할 수 있습니다.
실전에서는? — Hybrid Retrieval
현업에서는 두 방법을 함께 쓰는 Hybrid Retrieval이 일반적입니다. BM25로 키워드 매칭을 하고, Dense Retrieval로 의미 유사도를 계산한 뒤, 두 점수를 합산(RRF 등)하여 최종 순위를 결정합니다. 각 방법의 약점을 서로 보완하는 방식입니다.
5. Embedding Model은 꼭 같은 모델을 써야 할까?
기본적으로는 그렇습니다. 하지만 비대칭 검색에서는 예외가 있습니다.
Dense Retrieval 시스템은 텍스트를 숫자로 변환하는 Bi-Encoder(이중 인코더) 구조를 기반으로 합니다. 이때 사용되는 두 가지 핵심 모델인 질의용 모델과 문서용 모델은 다음과 같은 역할을 수행합니다.
1. 질의용 모델 (Query Encoder)
사용자가 입력한 질문(Query)을 벡터 공간의 한 점으로 변환하는 모델입니다.
- 역할: 질문의 의도와 핵심 키워드를 파악하여 벡터로 수치화합니다.
- 특징: 검색 시점에 실시간으로 동작하며, 짧은 문장 형태의 입력을 처리하는 데 최적화되어 있습니다.
2. 문서용 모델 (Document/Passage Encoder)
방대한 양의 지식 문서(Document)를 벡터로 변환하여 데이터베이스에 미리 저장하는 모델입니다.
- 역할: 각 문서의 의미적 맥락을 요약하여 벡터 공간에 좌표를 찍어둡니다.
- 특징: 시스템 구축 단계에서 미리 대량의 데이터를 인코딩(Indexing)하며, 긴 텍스트의 정보를 압축하는 능력이 중요합니다.
3. 왜 두 모델의 '기반'이 같아야 할까요?
질의용 모델과 문서용 모델은 같은 벡터 평면(Embedding Space) 위에서 대화해야 하기 때문입니다.
비유하자면, 두 사람이 같은 지도를 쓰지 않으면 서로의 위치를 비교할 수 없는 것과 같습니다. 서울 지도 위의 좌표를 뉴욕 지도 위의 좌표와 비교하는 건 아무 의미가 없습니다.
- 대칭형(Symmetric) 검색: 질문과 문서의 형식이 비슷할 때 사용하며, 보통 하나의 임베딩 모델이 두 역할을 모두 수행합니다.
- 비대칭형(Asymmetric) 검색: "질문은 짧고 문서는 길다"는 현실적인 차이를 극복하기 위해, 모델 내부적으로 질의와 문서에 대해 서로 다른 접두사(Instruction)를 붙여 처리하기도 합니다. 예를 들어, 질문에는
query:를, 문서에는passage:를 붙여 같은 모델 내에서도 인코딩 방식을 최적화합니다.
결론적으로, 두 모델은 동일한 가중치를 공유하는 하나의 모델이거나, 최소한 동일한 데이터셋으로 함께 학습되어 동일한 차원의 벡터 공간을 공유하는 쌍이어야만 정상적인 검색이 가능합니다.
6. 임베딩 모델의 두 가지 인코딩 방식
임베딩 모델에서의 Instruction(지시어)은 모델에게 "지금 들어오는 문장을 어떤 용도로 처리해라"라고 명시하는 일종의 '태그'입니다. 크게 두 가지 방식이 있습니다.
방식 1. 일반적인 방식 (Symmetric)
별도의 지시어 없이 문장만 입력하는 방식입니다.
질문: 오늘 날씨 어때? → (모델 입력) → 벡터 생성
문서: 서울의 오늘 날씨는 맑음입니다. → (모델 입력) → 벡터 생성모델은 들어온 문장의 '의미'만 보고 벡터를 만듭니다.
방식 2. 지시어를 쓰는 방식 (Asymmetric / Instruction-based)
최근 성능이 좋은 모델들(예: BGE, E5 등)은 질문과 문서의 성격이 다르다는 점을 활용하기 위해 특정 단어를 앞에 붙여서 학습합니다.
질문용 입력: query: 오늘 날씨 어때?
문서용 입력: passage: 서울의 오늘 날씨는 맑음입니다.왜 굳이 이렇게 할까요?
질문은 보통 "짧고 궁금한 상태"이고, 문서는 "길고 정보를 담고 있는 상태"입니다. 모델에게 "이 문장은 질문이니까 답을 찾기 적합한 위치에 점을 찍어줘"라고 명확히 가이드를 주면, 단순히 문장만 넣었을 때보다 검색 정확도(Similarity)가 비약적으로 올라가기 때문입니다.
즉, 질문과 문서에 "프롬프트가 다르다"는 것은 우리가 LLM과 대화하듯 내용을 바꾸는 게 아니라, 모델이 질문용 벡터와 문서용 벡터를 더 정교하게 구분해서 만들 수 있도록 정해진 머리말(prefix)을 붙여준다는 뜻입니다.
💡 사용하려는 모델의 공식 문서에 "Queries should be prefixed with..." 같은 문구가 있다면, 이 지시어를 반드시 지켜야 제 성능이 나옵니다.
지시어(Instruction) 사용 예시 — BGE 모델
가장 대표적인 모델인 BGE(Beijing General Embedding) 모델을 예로 들면 다음과 같습니다.
문서 저장 시 (Indexing): 별도의 지시어 없이 문장만 넣습니다.
입력: 임베딩 모델은 텍스트를 고차원 벡터로 변환하는 기술입니다.질문 시 (Retrieval): 모델에게 '검색을 위한 질문'임을 명시합니다.
입력: Represent this sentence for searching relevant passages: 임베딩 모델이 뭐야?이렇게 하면 모델은 질문 벡터를 만들 때 "이건 답을 찾기 위한 단서다"라는 점을 인지하고, 정보가 담긴 문서 벡터와 더 잘 결합되도록 수치화합니다.
7. 이전 모델 vs 최신 Embedding Model 비교
가장 큰 차이는 '문맥 이해의 깊이'와 '검색 목적의 최적화'입니다.
| 구분 | 이전 모델 (예: BERT 기본형) | 최신 모델 (BGE, E5, Mistral-7B-v0.2 등) |
|---|---|---|
| 학습 데이터 | 주로 위키피디아 등 일반 텍스트 | 질문-답변 쌍(QA Pair) 대량 학습 |
| 문맥 파악 | 단어의 의미적 유사성에 집중 | 질문과 답변 사이의 연관성에 집중 |
| 입력 길이 | 보통 512 토큰 내외 | 8,192 토큰 이상의 긴 문서 처리 가능 |
| 지시어 처리 | 없음 (모든 문장을 동일하게 처리) | 지시어에 따라 벡터 생성 방식 조절 가능 |
| 성능 (MTEB) | 점수가 낮거나 특정 언어에 편중 | 다양한 언어·작업에서 압도적 성능 (SOTA) |
핵심 개선 포인트
비대칭 검색(Asymmetric Retrieval) 최적화
예전 모델은 '사과'와 '포도'처럼 비슷한 단어가 들어간 문장을 가깝게 배치하는 데 그쳤다면, 최신 모델은 "아이폰 만드는 회사 어디야?"라는 질문과 "애플은 쿠퍼티노에 본사를 둔..."이라는 답변 문서를 가깝게 배치하는 능력이 월등합니다.
Contrastive Learning (대조 학습)
"이 질문의 답은 이거야(Positive)"와 "이건 전혀 상관없는 문서야(Negative)"를 명확히 구분하도록 훈련되어 검색 정확도가 높습니다.
다국어 성능
E5나 BGE-M3 같은 모델은 한국어를 포함한 수십 개의 언어를 동시에 지원하며, 언어가 달라도 의미가 같으면 가깝게 배치합니다.
마치며
RAG는 단순히 "LLM에 문서를 붙여주는 것"이 아닙니다. 인덱싱 전략, 청킹 방법, 임베딩 모델 선택, 검색 방식(Sparse/Dense/Hybrid), 리랭킹까지 — 각 단계를 얼마나 잘 설계하느냐에 따라 최종 답변 품질이 크게 달라집니다.
특히 임베딩 모델의 선택과 지시어 사용은 실무에서 가장 놓치기 쉬운 부분이면서, 동시에 검색 품질에 즉각적인 영향을 주는 요소입니다. RAG 시스템을 구축할 때 꼭 챙겨보시길 권장합니다.
