outfit recommendation
쇼핑을 하다보면 어떤 옷을 골랐을 때 내가 고른 옷과 어울리는 다른 옷도 추천해주는 경험을 해본 적이 있을 것이다.
 사진 출처 : SSF몰
사진 출처 : SSF몰
상의, 하의는 물론 모자, 가방, 신발까지 추천해주는 이 서비스는 보통 인공지능을 학습시켜 추천해주는데, 자칫 잘못하면 엉뚱한 추천을 해주어 서비스의 퀄리티가 낮아질 수 있다.
제품이 기본적으로 가지고 있는 카테고리(아우터, 티셔츠, 팬츠, 가방, 신발 등), 기장, 색상과 같은 정보가 있어도, 이러한 정보에서 모델이 상품의 시각적 정보를 파악하기는 쉽지 않다.
따라서 요즘 인공지능을 사용한 outfit recommendation system은 이미지와 텍스트를 함께 활용하며, 패션 아이템들간의 호환성(compatibility, 잘 어울리는지)을 판단하기 위해 고객이 함께 구매한 상품, 전문가(패션 디자이너)의 패션구성, 소셜미디어 사진에서 사람들의 의상까지 데이터로 활용해야 한다.
이렇듯 모델이 사람이 보기에도 "잘 어울리는" 룩을 추천하기 위해서는 일반화를 위해 많은 데이터가 필요하고,
상품의 카테고리나 이미지만을 사용해서는 좋은 결과를 낼 수 없다.(다만 Graph 모델로 이미지만을 사용해서 좋은 결과를 낸 논문이 있다.)
오늘 리뷰할 논문은 추천이 까다로운 패션 아이템들을 학습할 때에 사용할 수 있는 기법에 대해 연구한 논문이다.
background
-
triplet loss
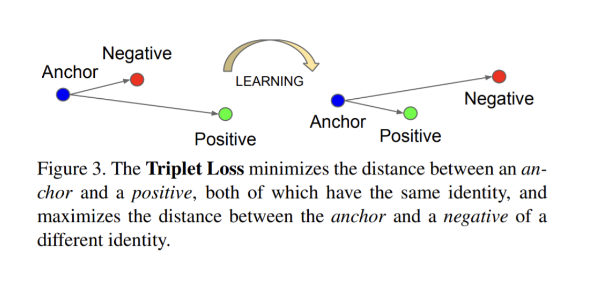
사진출처 : FaceNet
논문에 대해 이해하려면 먼저 triplet loss에 대해 이해해야 한다.
Triplet loss는 baseline인 anchor를 positive, negative input들과 비교하는 인공 신경 네트워크에 대한 손실 함수 (loss function)이다.
anchor input과 positive input 사이의 거리는 최소화 되야하며, negative input과의 거리는 최대가 되어야 한다.
보통 워드 임베딩 (word embeddings)에서 유사성을 학습하는 데 사용되며, 유클리디안 거리를 사용한다.
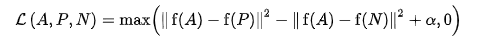
A : anchor input
P : A와 같은 class에 속하는 positive input
N : A와 다른 class에 속하는 negative input
: positive , negative pair간의 margin
f : embedding -
미리(함께) 읽으면 좋은 논문
-
[1]-Learning Fashion Compatibility with Bidirectional LSTMs (2017)
bi-LSTM을 사용하여 fashion compatibility 연구 수행, visual-semantic embedding (이미지와 텍스트 데이터를 함께 embedding) 제안 -
[2]-Learning Type-Aware Embeddings for Fashion Compatibility (2018)
SiameseNet을 사용하여 fashion compatibility 연구 수행 , (1) 에서 발전하여 type-aware embedding space( : item type(e.g. top, bottom, shoes) 별 image embedding을 학습) 를 사용하는 end to end 학습법 제안
-
SAT: self-adaptive training for fashion compatibility prediction
abstract
- hard items(비슷한 색상, 질감, 패턴을 가졌으나 미관 또는 계절적 이유로 incompatible한 items) 학습에 집중
- 각 outfit 마다 Difficulty score(DS) 정의
- self-adaptive triplet loss (SATL) 제안 → DS에 따라 weights 를 결정
- simple conditional similarity network 제안
method
self-adaptive training (SAT) model은 CNN에 hard sample을 더 많이(가중치를 통해) 학습시키는 방법이다.
key-insight는 positive sample(Dn)과 negative sample(Dp)간 embedding distance는 margin보다 클것이다 라는 가정을 통해 거리가 margin보다 작은 hard item에 대해서는 더 큰 가중치를 주어 학습을 시킨다.
Model Architecture and Training
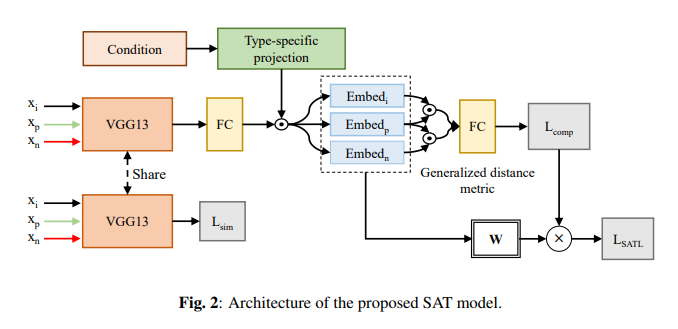
학습 방법
우리가 이미지 를 가지고 있다고 가정했을 떄, trplet loss input 이 만들어진다,
u, v : image types
xi, xp → positive pair / xi, xn → negative pair
(1) triplet input 를 VGG13에 넣어 general features (Fxi(u), Fxn(v), Fxp(v))얻는다.
(2) general feature를 type-specific embedding space M(u,v) 에 projection → 목표는 M 안에서 Fxi(u), Fxp(v) 간의 거리가 작아지게 하는 것
type-specific embedding space 란?
- motivation
논문[1]처럼 이미지 type에 상관없이 general embedding space를 하나만 사용할 경우 두가지 문제 발생
compresses variation : outfit이 compatible하지 않은데도 embedding space에서 거리가 가까우면 matching되는 문제
improper triangles : a가 b와 매치, b와 c가 매치되면 a 는 무조건 c 와 매치될 수 밖에 없음(stemming from using a single embedding)- method
두 종류의 embedding space 사용
1. 이미지 similarity 측정을 위한 general embedding space
2. 두 아이템간의 compatibility를 계산하기 위한 type-aware embedding space
(3) compatibility
이때 compatibility는 아래 수식으로 계산된다.
j : type이 v인 이미지 중 랜덤으로 선택
: 주어진 이미지 와 compatible
할 수도, incompatible할 수도 있다.
(4) loss 는 triplet loss of the input(), self-adaptive triplet loss(), similarity loss of the general features() 가 있다.
triplet loss of the input()
: margin
는 positive pair 와 negative pair 간 거리에 margin(in paper : 0.3)을 더한 값과, 0 중에 큰 값을 택한다.
self-adaptive triplet loss():
SATL은 triplet loss of input() 에 가중치를 곱한 값이다.
데이터는 color compatible, pattern compatible, or style compatible하게 레이블링 되었지만, 이는 표준(기준)이 아니다. 따라서 type-specific embedding space 안에서 positive pair distance () 와 negative pair distance 의 차이는 margin보다 커야한다. 만약 그렇지 않다면 이는 hard sample로 간주한다.
hard sample을 잘 학습시키기 위해, 논문에서는 각각의 outfit마다 DS(Difficulty Score)를 정의한다.
이후 학습된 weight parameter인 를 each triplet loss에 assign한다. 이렇게 하면 최종 weight matrix는 다음과 같다.
different triplet inputs에 different weights 을 assign함으로서 각 triplet input의 DS가 사용되어 모델이 hard items의 compatibility를 더 잘 학습할 수 있으며, input의 특징을 더 잘 나타내는 embedding space를 생성한다.
similarity loss of the general features()
: type이 같은 positive와 negative간 general featutes의 거리
,
: type v인 positive input의 general feature와 type u인 input image general feature간 거리
,
. type v인 negative input의 general feature와 type u인 input image general feature간 거리
type-aware loss
experiment & conculsion
실험의 셋팅은 [2] Siamese-Net 논문에서와 같은데, 대략적으로는 다음과 같다.
popular compatibility prediction and fill-in-the-blank (FITB) tasks
VGG13 [15] pre-trained on ImageNet [16] was adopted as our backbone CNN model
The embedding size is 128, the margin µ is 0.3, and the minibatch size is 128
initial learning rate to 5 × 10−5
Since there are no ground truth negative images for each outfit, we randomly sample a set of negative images that have the same category as the positive image similar to [2].
FITB와 Compatibility accuracy
outfit recommendation에서 아이템을 추천하는 방법은 여러가지가 있는데, 대표적인 것이 FITB(Fill In The Blank)와 Compatibility prediction이다.
 사진 출처 : Learning Fashion Compatibility with Bidirectional LSTMs
사진 출처 : Learning Fashion Compatibility with Bidirectional LSTMs
먼저 FITB는 다른 카테고리(아우터, 상의, 하의, 가방)에 속하는 아이템은 모두 구성이 되어있을 때, 비어있는 카테고리(신발) 에 어떤 아이템이 가장 잘 어울리는지 추천하는 것이다.
Compatibility prediction은 구성되어 있는 outfit 모음이 잘 어울리는지 정도를 점수로 예측하는 것이다.
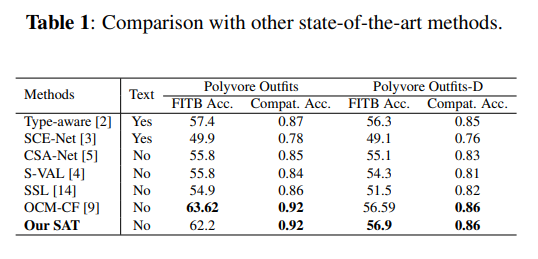 FITB 정확도와 Compatibility 정확도를 비교했을 때 SAT가 상위권에 있음을 보인다.
FITB 정확도와 Compatibility 정확도를 비교했을 때 SAT가 상위권에 있음을 보인다.
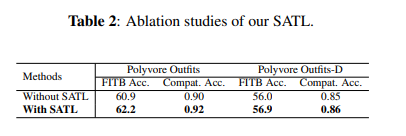 SATL의 영향을 알아보기 위한 ablation study에서도 SATL을 사용했을 때 FITB and compatibility accuracy가 더 높아졌다.
SATL의 영향을 알아보기 위한 ablation study에서도 SATL을 사용했을 때 FITB and compatibility accuracy가 더 높아졌다.

검정박스가 GT, (a)행의 빨간 박스는 SATL을 사용하지 않았을 때의 예측, (b)행의 초록박스가 SATL을 사용했을 때의 예측이다. SATL을 사용했을 때의 예측이 모두 GT와 동일하다는 결과.
take-home message
hard item을 고려한 self-adaptive triplet loss를 통해 outfit compatibility 성능을 향상시킬 수 있다.
논문에서 기여한 점은
단점은 이미지 데이터와 그에 해당하는 description 텍스트 데이터까지 있어야한다는 것.
또한 compatibility score 계산 시 embedding feature를 pairwise하게 비교한다.
item들을 pairwise하게(독립적으로) 비교하면 최종적인 final prediction은 각 item을 독립적으로 비교한 후 모아놓은 것이다.
이 방법은 context를 고려하지 않기 때문에 주어진 clothing pair에 대해 항상 같은 예측을 하게된다.
Compatibility는 패션 감각과 트렌드가 변하면 함께 변하기 때문에 항상 같은 예측을 하는것은 문제가 있다.
이를 해결한 논문이 Context-Aware Visual Compatibility Prediction(cvpr 2019) 이다. 다음엔 이 논문을 리뷰해보겠다.
