강의 내용 복습
(01강) Introduction to PyTorch
deep learning framework 의 종류
딥러닝 프레임워크는 굉장히 많다. 대표적인 것은 keras, Tensorflow, PyTorch가 있다.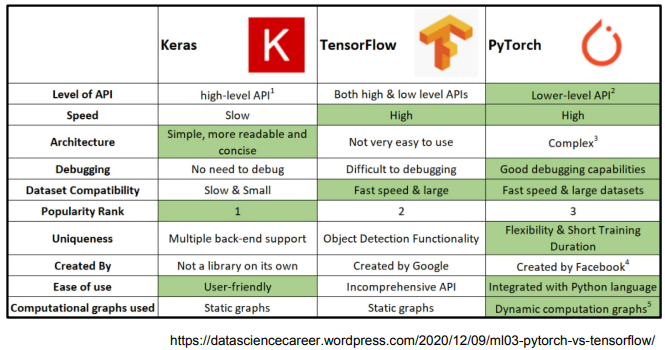
그 중 가장 많이 사용되는 것은 pytorch와 tensorflow를 사용한다.
두 프레임워크의 가장 큰 차이점은 computational graph의 사용이다. computational graph란 연산과정을 그래프로 표현한 것이다. backward propagation을 위해 현재 있는 데이터들을 그래프로 표현해야하는데, tensorflow는 graph를 그려놓은 다음 실행 시점에 사용되는 static graph를 사용하고, pytorch는 실행 시점에 그래프를 정의하는 dynamic computation graph를 사용한다.


pytorch
Numpy + AutoGrad + Funtion
- Numpy구조를 가지는 tensor 객체로 array 표현
- 자동미분을 지원하여 DL연산을 지원
- 다양한 형태의 DL을 지원하는 함수와 모델을 지원함
furthur question
- AutoGrad 란?
autograd 패키지는 Tensor로 수행한 모든 연산에 대하여 자동-미분(Autimatic differentiation) 기능을 제공합니다. autograd는 실행 시점에 정의되는(define-by-run) 프레임워크입니다. 이것은 코드가 어떻게 실행되는가에 따라서 역전파(backprop)가 정의됨을 의미합니다. 즉 반복마다1 역전파가 달라질 수 있다는 것을 의미합니다.
출처 : http://taewan.kim/trans/pytorch/tutorial/blits/02_autograd/
(02강) PyTorch Basics
- Tenser
- 다차원 array를 표현하는 pytorch 클라스
- 사실상 numpy의 ndarray와 동일(그러므로 TF의 Tensor와도 동일)
- tensor를 생성하는 함수도 거의 동일
- 생성
import numpy as np
n_array = np.arange(10).reshape(2,5)
print(n_array)
print("ndim :", n_array.ndim, "shape :", n_array.shape)
import torch
t_array = torch.FloatTensor(n_array)
print(t_array)
print("ndim :", t_array.ndim, "shape :", t_array.shape)- Array to tensor
nd_array_ex = np.array(data)
tensor_array = torch.from_numpy(nd_array_ex)
tensor_array-
tensor data type
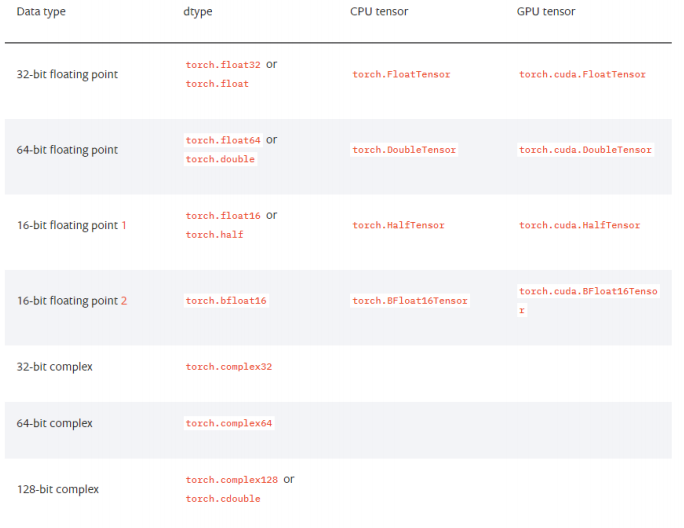
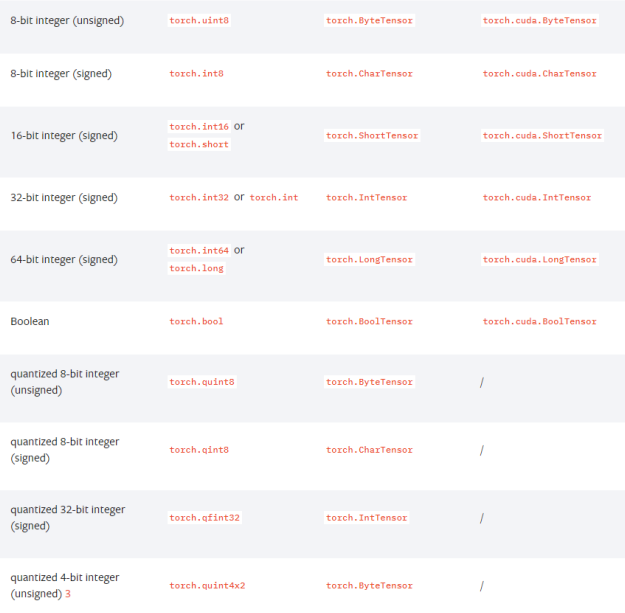
-
numpy like operations
# array to tensor
data = [[3, 5, 20],[10, 5, 50], [1, 5, 10]]
x_data = torch.tensor(data)
# list slicing
x_data[1:]
x_data[:2, 1:]
# flatten
x_data.flatten()
# ones_like
torch.ones_like(x_data)
# tensor to numpy
x_data.numpy()
# shape
x_data.shape
# data type
x_data.dtype
# pytorch의 tensor는 GPU에 올려서 사용가능
x_data.device
if torch.cuda.is_available():
x_data_cuda = x_data.to('cuda')
x_data_cuda.device- Tensor handling
- view : reshape과 동일하게 tensor의 shape을 반환
- squeeze : 차원의 개수가 1인 차원을 삭제(압축)
- unsqueeze : 차원의 개수가 1인 차원을 추가
tensor_ex = torch.rand(size=(2, 3, 2))
tensor_ex
tensor_ex.view([-1, 6])
tensor_ex.reshape([-1,6])- view와 reshape은 contiguity 차이
# view는 copy가 아닌 메모리 공유
a = torch.zeros(3, 2)
b = a.view(2, 3)
a.fill_(1)
a
b
# reshape은 copy
a = torch.zeros(3, 2)
b = a.t().reshape(6)
a.fill_(1)
a
b- squeeze unsqueeze
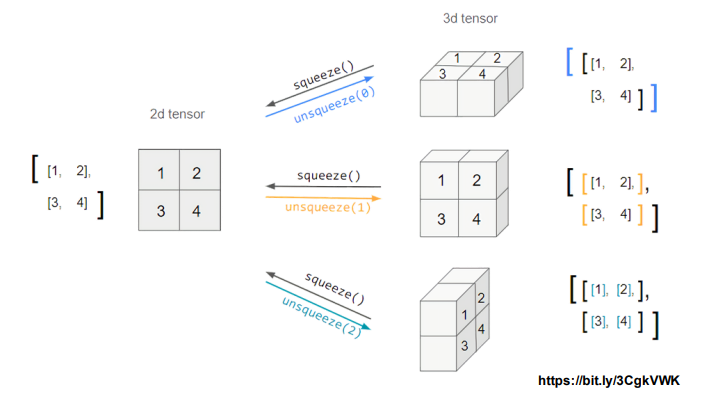
tensor_ex = torch.rand(size=(2, 1, 2))
tensor_ex.squeeze()
tensor_ex = torch.rand(size=(2, 2))
tensor_ex.unsqueeze(0).shape
tensor_ex.unsqueeze(1).shape
tensor_ex.unsqueeze(2).shape- Tensor operations
n1 = np.arange(10).reshape(2,5)
n2 = np.arange(10).reshape(5,2)
t1 = torch.FloatTensor(n1)
t2 = torch.FloatTensor(n2)
t1 + t1
t1 - t1
# 행렬곱셈 함수는 dot이 아닌 mm사용
n2 = np.arange(10).reshape(5,2)
t2 = torch.FloatTensor(n2)
t1.mm(t2)
t1.matmul(t2)
t1.dot(t2)
# dot은 vector연산 됨
a = torch.rand(10)
b = torch.rand(10)
a.dot(b)
a
# mm은 vector연산 안됨
a = torch.rand(10)
b = torch.rand(10)
a.mm(b)- mm과 matmul의 차이는 broadcasting 지원
# mm은 broadcasting 지원 안함
a = torch.rand(5,2, 3)
b = torch.rand(5)
a.mm(b)
# matmul은 broadcasting 지원함
a = torch.rand(5,2, 3)
b = torch.rand(3)
a.matmul(b)
# matamul연산은 아래와 같음
a[0].mm(torch.unsqueeze(b,1)).squeeze()
a[1].mm(torch.unsqueeze(b,1))
a[2].mm(torch.unsqueeze(b,1))
a[3].mm(torch.unsqueeze(b,1))
a[4].mm(torch.unsqueeze(b,1))- tensor operations for ML/DL formula
import torch
import torch.nn.functional as F
tensor = torch.FloatTensor([0.5, 0.7, 0.1])
h_tensor = F.softmax(tensor, dim=0)
h_tensor
y = torch.randint(5, (10,5))
y_label = y.argmax(dim=1)
y_label
torch.nn.functional.one_hot(y_label)
import itertools
a = [1, 2, 3]
b = [4, 5]
list(itertools.product(a, b))
tensor_a = torch.tensor(a)
tensor_b = torch.tensor(b)
torch.cartesian_prod(tensor_a, tensor_b)- torch autogard
# 미분 시 backward 사용
# y = w^2
# z = 10y + 50
# z = 10w^2 + 50
w = torch.tensor(2.0, requires_grad=True)
y = w**2
z = 10*y + 50
z.backward()
w.grad
# 편미분은 external_grad 인자
# Q = 3a^3 = b^2
# dQ/da = 9a^2
# dQ/db = -2b
a = torch.tensor([2., 3.], requires_grad=True)
b = torch.tensor([6., 4.], requires_grad=True)
Q = 3*a**3 - b**2
external_grad = torch.tensor([1., 1.])
Q.backward(gradient=external_grad)
a.grad
b.grad(03강) PyTorch 프로젝트 구조 이해하기
-
pytorch project template
- 개발 초기 단계에서는 대화식 개발과정이 유리 : 학습과정과 디버깅등 지속적인 확인
- 배포 및 공유단계에서는 notebook공유의 어려움 : 쉬운 재현의 어려움, 실행순서 꼬임
- DL코드도 하나의 프로그램 : 개발 용이성 확보와 유지보수 향상 필요
따라서 OOP + 모듈 = 프로젝트 형식의 구현 필요
템플릿 : https://github.com/victoresque/pytorch-template

과제 수행 과정 및 결과
<Custom model 개발>
-
nn.Module
- Container- torch.nn.Sequential
모듈(Module)들을 하나로 묶어 순차적으로 실행시키고 싶을 때 사용
묶어놓은 모듈들을 차례대로 수행하기 때문에 실행 순서가 정해져있는 기능들을 하나로 묶어두기 좋다. - torch.nn.ModuleList
파이썬의 list처럼 모아두기만 하고 그때그때 원하는 것만 인덱싱(indexing)을 통해 쓰고 싶을 때 사용
만약 리스트에 담긴 모듈의 크기가 정말 커진다면 나중에는 인덱싱(indexing)으로 원하는 모듈을 찾기가 힘들다는 단점이 있다. - torch.nn.ModuleDict
파이썬의 dict처럼 특정 모듈을 key값을 이용해 보관해놓고 원하는 모듈을 쉽게 가져올 수 있다.
- torch.nn.Sequential
-
named_children vs named_modules
둘다 모델 내부의 module을 출력해준다.
named_children은 한 단계 아래의 submodule까지만 표시하고,
named_modules는 자신에게 속하는 모든 submodule들을 표시해준다.
-
get_submodules
내가 원하는 특정 모듈만 가져올 때 사용 -
Parameter
nn.Module안에 미리 만들어진 tensor들을 보관할 때 사용
Parameter는 tensor의 subclass로, Module사용시 자동으로 parameter라는 학습가능한 매개변수로 저장된다. 학습가능한 매개변수는 pytorch의 auto grad로 역전파시 업데이트 될 수 있다.
일반 tensor는 그렇지 않다. -
Buffer
일반적인 Tensor는 Parameter와 다르게 gradient를 계산하지 않아 값도 업데이트 되지 않고, 모델을 저장할 때 무시된다.
하지만 Parameter로 지정하지 않아서 값이 업데이트 되지 않는다 해도 저장하고싶은 tensor가 있을 때, buffer에 tensor를 등록해주면 모델을 저장할때 Parameter뿐만 아니라 buffer로 등록된 tensor들도 같이 저장된다.- "Tensor"
- ❌ gradient 계산
- ❌ 값 업데이트
- ❌ 모델 저장시 값 저장
- "Parameter"
- ✅ gradient 계산
- ✅ 값 업데이트
- ✅ 모델 저장시 값 저장
- "Buffer"
- ❌ gradient 계산
- ❌ 값 업데이트
- ✅ 모델 저장시 값 저장
- "Tensor"
-
hook
패키지화된 코드에서 다른 프로그래머가 custom 코드를 중간에 실행시킬 수 있도록 만들어놓은 인터페이스.- 프로그램의 실행 로직을 분석하거나
- 프로그램에 추가적인 기능을 제공하고 싶을 때
<pytorch hook>
- Tensor에 적용하는 hook
- backword hook
- module에 적용하는 hook
- forward pre hook : 순전파 전에 호출되며 순전파 시 어떤 값이 전달되는 지 확인 가능
- forward hook : 순전파 이후 호출. 전달되는 값 수정 가능
- backward hook : 역전파 시 전파되는 gradient값 확인 가능
- full backward hook : 역전파 시 전파되는 gradient값 확인 가능
-
apply
모델에 무언가를 적용하려면 모델을 구성하는 전체 모듈에 모두 적용이 되어야하는데, custom 함수를 모델에 적용하고 싶을 때 apply 사용한다.
apply 를 통해 적용하는 함수는 모델의 모든 module들을 순차적으로 입력받아서 처리한다.
apply 함수는 일반적으로 가중치 초기화(Weight Initialization)에 많이 사용된다.
피어 세션
- pytorch gather 동작 방식
- 통계학 스터디 : conjugacy and exponential family
학습 회고
pytorch를 얼렁뚱땅 사용하고 있었는데, 이번 과제를 하면서 공식문서를 정독하고, 다양한 operation을 직접 사용, 비교해보며 확실한 개념을 잡을 수 있었다. 잊어버리지 않게 자주 사용하자!
keep
- 그날 할당량은 그날 끝내고 자기
problem
- 시간 너무 오래 걸림
try
- 우선순위 to-do list만들어서 급한거부터 빠르게 끝내기!!!!!
