[U stage DAY 1] python basics for AI (1)
강의 내용 복습
numpy
넘파이는 선형대수와 관련된 다양한 기능을 제공하는 패키지로, 일반 list에 비해 빠르고 메모리 효율적이라 대용량 계산이 필요한 ml에서 많이 사용된다.
일반적으로 속도는 for loop < list comprehension < numpy 순으로 10억번의 loop를 돌때 4배이상의 성능차이를 보인다. numpy는 C로 구현되어 있어 성능을 확보하는 대신 파이썬의 가장 큰 특징인 dynamic typing을 포기하였다.
일반적인 list는 list에 메모리의 주소가 저장되고, 넘파이는 정적메모리에 값이 차례대로 들어간다.
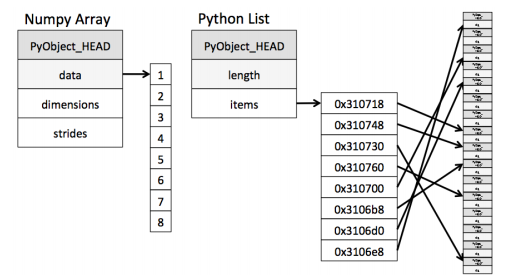 또한 list는 -5부터 256까지의 수는 메모리에서 static한 값에 저장하므로 다른 리스트여도 해당 범위에 있는 값이면 메모리의 주소가 같은 것을 볼 수 있다.
또한 list는 -5부터 256까지의 수는 메모리에서 static한 값에 저장하므로 다른 리스트여도 해당 범위에 있는 값이면 메모리의 주소가 같은 것을 볼 수 있다.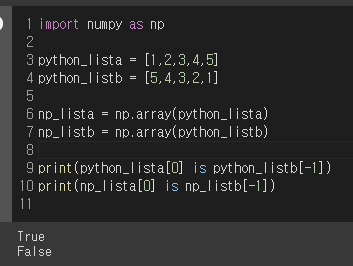
numpy array는 shape, reshape, ones, zeros, sum 등 다양한 함수를 제공한다.
pandas
pandas는 구조화된 데이터의 처리를 지원하는 Python 라이브러리로, 고성능 array 계산 라이브러리인 numpy와 통합하여 강력한 스프레드시트 기능을 제공한다. 인덱싱, 연산용함수, 전처리 함수 등을 제공하며 데이터 처리 및 통계분석을 위해 사용한다.
과제 수행 과정 및 결과
없음
피어 세션
-
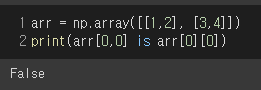
numpy 행렬의 같은 원소의 메모리 주소가 같은지 출력해봤을 때 (arr[0][0] is arr[0,0]) 다르게 나오는 이유에 대한 토의
(멘토님의 답변)
numpy array의 data는 내부적으로 연속적인 C array로 heap에 저장됩니다. 하지만 python object는 array에 대한 부가적인 정보 - count, dimension 등 - 를 저장하기 때문에, 예시의 text_array[0][0]는 memory의 data (C array) 에 대한 pointing을 하지 않습니다. 대신에 numpy는 array의 원소 접근 시 array의 data 를 python object로 wrapping 하게 되는데요, 예를 들어 type(text_array[0][0]) 를 호출해보시면 <class 'numpy.float32'> 를 얻게 됩니다. 이러한 과정은 array의 원소를 python에서 일반적인 indexing 을 통해 접근을 할 때마다 on-the-fly로 이루어진다고 합니다. 이에 따라text_array[0][0] is text_array[0][0]
구문을 실행해보시면 False 값을 얻으시게 될 것입니다. 따라서 같은 id(text_array[0][0]) 구문에 대한 실행 결과는 실행 시점에 따라, 그리고 시스템 최적화의 여부 및 정도에 따라 다르게 나올 수 있습니다. numpy array가 이러한 방식으로 설계된 이유는 원소 접근에 대한 퍼포먼스 보다는 행렬 연산과 같은 벡터화된 연산의 퍼포먼스를 최적화시키기 위함이라고 생각하시면 됩니다.
학습 회고
numpy와 pandas에 대해 다시 복습할 수 있는 수업이었다.
