 # 강의 내용 복습
# 강의 내용 복습
(07강) Sequential Models - RNN
Sequential Model
이전 데이터를 통해서 다음의 데이터를 찾는 모델
뒤로 갈수록 고려해야할 과거의 정보의 양이 늘어난다.

따라서 timespan을 고정하여 과거의 N개의 정보만 사용하는 모델을 Autoregressive model 이라고 한다.
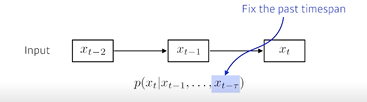
-
Marcov model(first-order Autoregressive model)

현재는 바로 전 과거에만 dependent하다는 가정
장점 : 결합분포를 표현하는 게 쉽다
단점 : 과거의 많은 정보를 버리게 된다 -
Latent aoutoregressive model
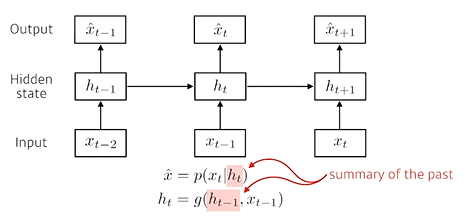
중간에 있는 hidden state가 과거의 정보를 가지고 있고, 다음 timestep은 그 hidden state(= latent state) 하나에만 dependent하다.latent state 를 만드는 방법
Recurrent Neural Network(Vanilla RNN)
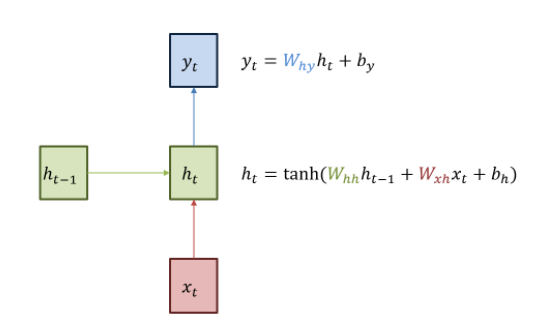
RNN은 히든 노드가 방향을 가진 엣지로 연결돼 순환구조를 이루는(directed cycle) 인공신경망의 한 종류이다.
녹색 박스는 히든 state를 의미한다. 빨간 박스는 인풋 x, 파란 박스는 아웃풋 y. 현재 상태의 히든 state ht는 직전 시점의 히든 state ht−1를 받아 갱신된다.
현재 상태의 아웃풋 yt는 ht를 전달받아 갱신되는 구조
자기자신으로 돌아오는 구조가 있어서 timestep t 에서의 hidden state ht는 xt에만 dependent한게 아니라 이전의 t-1에서 얻어진 cell state에 대해서도 dependent하다.
 위의 구조를 시간순으로 풀게되면 사실 입력이 굉장히 많고, (width가 큰) parameter를 공유하는 network하나가 된다.
위의 구조를 시간순으로 풀게되면 사실 입력이 굉장히 많고, (width가 큰) parameter를 공유하는 network하나가 된다.
RNN이 학습하는 parameter는 인풋 x를 히든레이어 h로 보내는 , 이전 히든레이어 h에서 다음 히든레이어 h로 보내는 , 히든레이어 h에서 아웃풋 y로 보내는 이며, 모든 시점의 state에서 이 param은 동일하게 적용된다. (shared parameter)
-
long term dependency
RNN은 어떤 fixed rule로 과거의 정보를 하나로 취합하기 때문에 먼 과거의 정보가 미래까지 살아남기 힘들다. 이를 long term dependency problem 라고 한다.예를 들어, 문장이 길어지면 이전의 중요하다고 생각하는 정보를 다 가지고 있다가 예측을 할때 사용해야 하는데 그렇게 하지 못하면 제한적인 모델이 된다.
이 단점을 해결한 모델이 LSTM이다.
-
RNN의 학습이 왜 어려울까

h0가 h4까지 가기 위해서는 같은 W를 곱하고 nonlinear function을 거쳐야한다. 이처럼 많은 W와 nonlinear function을 통과해야 한다.만약 activation fuction이 sigmoid 라면 이는 값을 [0,1]로 만든다. 즉, 정보를 줄이기 때문에 h0에서 왔던 정보는 값이 의미가 없어져버리게 된다. 이는 vanishing gradient를 야기한다.
만약 ReLU를 쓰고 W가 양수라면 ReLU의 특성상 W를 계속 곱해주게 되는것과 같아 h0의 값이 굉장히 크게 반영된다.
이는 explioding gradient()를 야기한다.
참고) RNN의 activation function 은 비선형 함수인 tanh 인데, 왜 비선형함수를 사용할까?
선형 함수인 h(x)=cx를 활성 함수로 사용한 3층 네트워크를 떠올려 보세요. 이를 식으로 나타내면 y(x)=h(h(h(x)))가 됩니다. 이 계산은 y(x)=c∗c∗c∗x처럼 세번의 곱셈을 수행하지만 실은 y(x)=ax와 똑같은 식입니다. a=c3이라고만 하면 끝이죠. 즉 히든레이어가 없는 네트워크로 표현할 수 있습니다. 그래서 층을 쌓는 혜택을 얻고 싶다면 활성함수로는 반드시 비선형함수를 사용해야 합니다.밑바닥딥러닝
LSTM
LSTM은 RNN의 히든 state에 cell-state를 추가한 구조

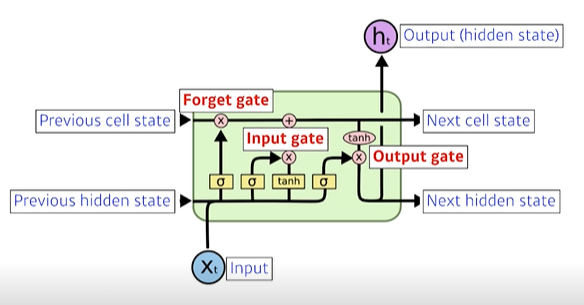
x : 입력(vector)
ht : 출력(hidden state)
Previous cell state : 내부에서만 흐름, 지금까지 t+1개의 정보를 취합하는 역할
Previous hidden state : 이전 시점의 출력값 (hidden state)
-
gate
cell state : 이전의 정보를 빼고, 더하고, 조작하여 다음으로 넘겨주는 역할. 이에 해당하는 것이 바로 gate를 출력하는 세 개의 레이어에서는 활성화 함수로 시그모이드(sigmoid, logistic)를 사용한다. 시그모이드 함수의 출력의 범위는 0 ~ 1 이며, 이 출력값은 각 forget, input, output 게이트의 원소별(element-wise) 곱셈연산에 입력된다. 따라서, 출력이 0일 경우에는 게이트를 닫고 1일 경우에는 게이트를 열기 때문에 를 gate controller라고 한다.
-
forget gate
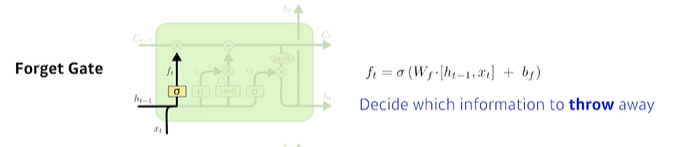
‘과거 정보를 잊기’를 위한 게이트현재 시점의 입력 와 이전시점에서 넘어온 hidden state 을 입력으로 받아 sigmoid를 취해준 값 ft를 만들어 어떤 정보를 버릴지 결정한다.
시그모이드 함수의 출력 범위는 0에서 1 사이이기 때문에 그 값이 0이라면 이전 상태의 정보는 잊고, 1이라면 이전 상태의 정보를 온전히 기억하게 된다. -
input gate

‘현재 정보를 기억하기’ 위한 게이트입력을 받아 무조건 cell state에 올리는 것이 아니라
현재 시점의 입력 와 이전 시점에서 넘어온 hidden state 을 입력으로 받아 sigmiod를 취해 를 만든다.그렇다면 올릴정보가 무엇인지 알아야한다.
이를 cell state candidate (다른 곳에서는 라고 부르기도 함) 라고 하는데, 이는 위와 같은 입력으로 tanh를 취한 값으로, -1,1로 정규화되어있는 값이다.input gate , 를 element wise product를 한 값을 내보낸다.
의 범위는 0~1, 의 범위는 -1~1이기 때문에 각각 강도와 방향을 나타낸다고 이해한다. -
update cell
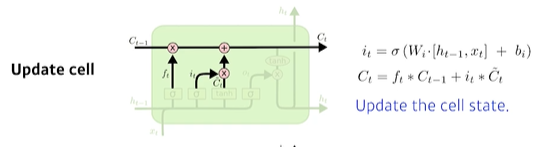
input gate에서 받은 값과, 이전 시점의 을 취합하여 cell state를 업데이트한다. -
output gate
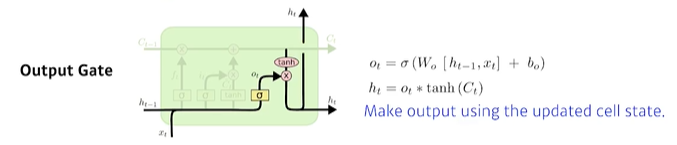
업데이트 된 cell state에서 output을 만든다.
-
GRU
Gated Recurrent Unit
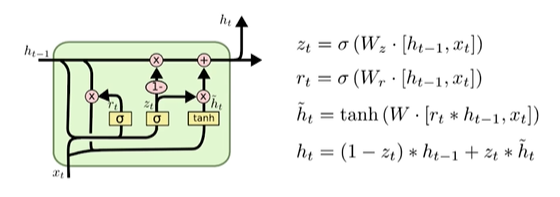
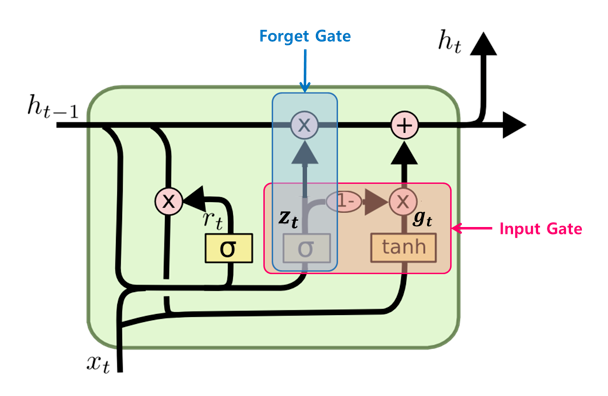
-
LSTM Cell에서의 두 상태 벡터 와 가 하나의 벡터 로 합쳐졌다.
-
하나의 gate controller인 가 forget과 input 게이트(gate)를 모두 제어한다. 가 1을 출력하면 forget 게이트가 열리고 input 게이트가 닫히며, 가 0일 경우 반대로 forget 게이트가 닫히고 input 게이트가 열린다. 즉, 이전(t-1)의 기억이 저장 될때 마다 타임 스텝 t의 입력은 삭제된다.
-
GRU 셀은 output 게이트가 없어 전체 상태 벡터 가 타임 스텝마다 출력되며, 이전 상태 의 어느 부분이 출력될지 제어하는 새로운 gate controller인 가 있다.
같은 task 에 대해 LSTM보다 성능이 좋은 경우가 있다. 대략적으로 parmeter수가 적으니 generalization 성능이 올라간다고 생각할 수 있다.
Further Question
- LSTM에서는 Modern CNN 내용에서 배웠던 중요한 개념이 적용되어 있습니다. 무엇일까요?
- Pytorch LSTM 클래스에서 3dim 데이터(batch_size, sequence length, num feature), batch_first 관련 argument는 중요한 역할을 합니다. batch_first=True인 경우는 어떻게 작동이 하게되는걸까요?
(08강) Sequential Models - Transformer
sequence data가 있을 때, 해당 데이터가 순서가 뒤바뀌거나 중간에 데이터가 빠지면 문제가 생긴다. 이를 해결하기 위한 것이 Transformer 구조 이다.
Transformer 구조
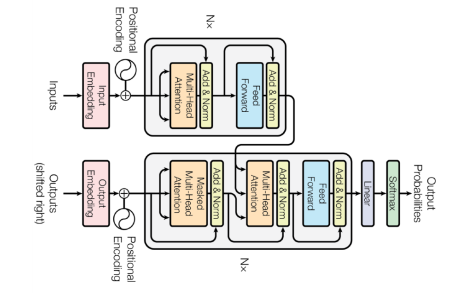
재귀적인 구조가 아닌, attention 기반으로 작동하는 모델
transformer 에서 사용되는 세가지의 attention 은 다음과 같다.

첫번째 그림인 셀프 어텐션은 인코더에서 이루어지지만, 두번째 그림인 셀프 어텐션과 세번째 그림인 인코더-디코더 어텐션은 디코더에서 이루어진다. 셀프 어텐션은 본질적으로 Query, Key, Value가 동일한 경우를 말한다.(여기서 Query, Key 등이 같다는 것은 벡터의 값이 같다는 것이 아니라 벡터의 출처가 같다는 의미) 반면, 세번째 그림 인코더-디코더 어텐션에서는 Query가 디코더의 벡터인 반면에 Key와 Value가 인코더의 벡터이므로 셀프 어텐션이라고 부르지 않는다.
인코더의 셀프 어텐션 : Query = Key = Value
디코더의 마스크드 셀프 어텐션 : Query = Key = Value
디코더의 인코더-디코더 어텐션 : Query : 디코더 벡터 / Key = Value : 인코더 벡터
위 그림은 트랜스포머의 아키텍처에서 세 가지 어텐션이 각각 어디에서 이루어지는지를 보여준다. 세 개의 어텐션에 추가적으로 '멀티 헤드'라는 이름이 붙어있는데, 이는 트랜스포머가 어텐션을 병렬적으로 수행하는 방법을 의미한다.

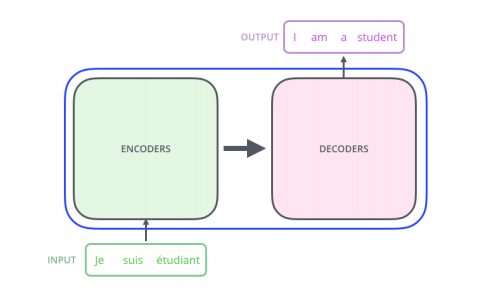

입력 시퀀스와 출력 시퀀스의 길이와 도메인이 다를 수 있다.
n개의 단어를 한번에 처리할 수 있는 구조이다.
동일한 구조를 갖지만 다른 parameter를 학습하는 encoder , decoder가 stack되어 있다.
인코더(Encoder)의 구조
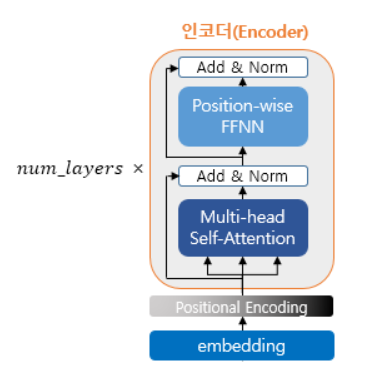
transformer는 hyper parameter인 num_layers 개수의 인코더층을 쌓는다. 논문에서는 총 6개의 인코더 층을 사용했다.
하나의 encoder layer는 크게 총 2개의 sub layer로 나누어 진다. self attention 과 feed forward 신경망이다. 그림에서는 multi head self-attention 과 position wides FFNN(feed forward neural network)라고 적혀있는데, 이는 셀프 어텐션을 병렬적으로 사용하였다는 의미와 우리가 알고있는 일반적인 피드 포워드 신경망을 뜻한다.
인코더의 셀프 어텐션

Q = Querys : 모든 시점의 디코더 셀에서의 은닉 상태들
K = Keys : 모든 시점의 인코더 셀의 은닉 상태들
V = Values : 모든 시점의 인코더 셀의 은닉 상태들
일반적인 어텐션함수는 주어진 쿼리(Query)에 대해서 모든 키(Key)와의 유사도를 각각 구한다. 이 유사도를 가중치로 하여 키와 맵핑되어 있는 각각의 값(Value)에 반영한다. 그리고 유사도가 반영된 '값(Value)'을 모두 가중합하여 리턴한다.
반면에 self-attention은 어텐션을 자기자신에게 수행한다는 의미이다.
기존에는 Q가 디코더 셀의 은닉상태이고, K가 인코더 셀의 은닉상태라는 점에서 Q와 K가 서로 다른 값을 가지고 있었는데, self attention에서는 Q,K,V가 전부 동일하다.
Q = K = V : 입력 문장의 모든 단어 벡터들
self-attention은 입력 문장 내의 단어들끼리 유사도를 구하므로서 문맥을 더 잘 파악한다.
self-attention 동작과정
우리는 아래의 세가지를 이해해야한다.
1. n개의 단어가 어떻게 encoder에서 한번에 처리되는지
2. encoder와 decoder사이에서 어떤 정보를 주고받는지
3. decoder가 어떻게 generate을 할 수 있는지
- n개의 단어가 어떻게 encoder에서 한번에 처리되는지
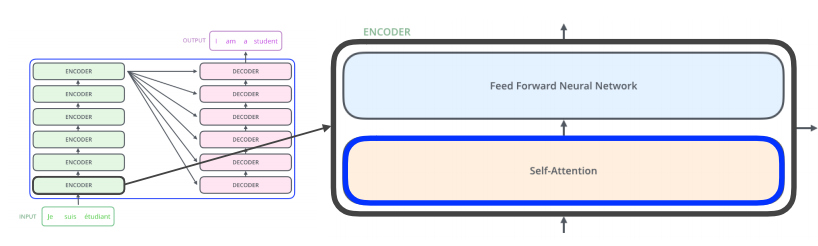
각 encoder와 decoder의 구조는 위와 같다.
- n개의 단어가 어떻게 encoder에서 한번에 처리되는지

3개의 단어가 입력으로 들어온다고 가정했을 때,
self-attention은 3개의 벡터로 인코딩한다.
그런데 이때, 나머지 입력도 함께 고려하여 인코딩하기 때문에 dependency가 있다.
더 간단히 하기 위해, Thinking, Machine 2개의 단어가 들어왔다고 가정해보자.
하나의 문장에서 있는 단어를 설명할 때는 해당 단어가 문장 속의 다른 단어와 어떻게 interaction이 있는지 중요하기 때문에 학습할 떄 단어들간의 관계성을 학습하게 된다.
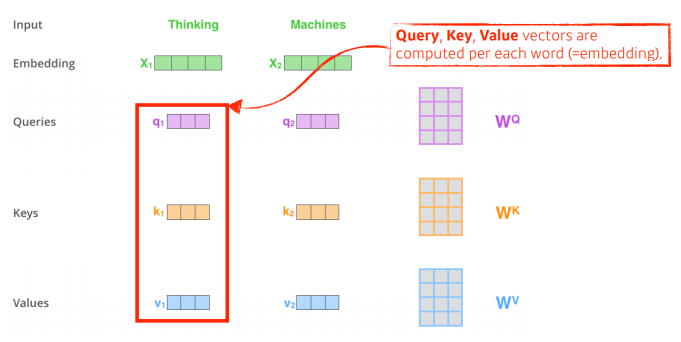
self-attention구조는 각 단어마다 q,k,v 3개의 벡터를 만들어내고, 이를 이용하여 단어를 인코딩한다.

i번째 단어에 대한 score벡터 : 내가 인코딩하고자하는 단어의 q 벡터와 나머지 단어의 k 벡터를 모두 구해 내적한다. 이를 통해 해당 단어가 나머지 단어와 얼마나 관계가 있는지 알아낸다.

k 벡터가 몇차원을 만들지는 hyper parameter, score 벡터의 값이 너무 커지는 것을 막기 위해 k 벡터의 차원(q 벡터의 차원과 같은)의 제곱근으로 나누어 준다.
이후 normalized score가 sum to one이 되도록 softmax를 튀한다.
그렇게 하면 Thinking이라는 단어가 자기자신과의 interaction에 대한 값(0.88), Machine 과의 interaction 값(0.12) 이 나온다. 이를 attention weight라고 한다.
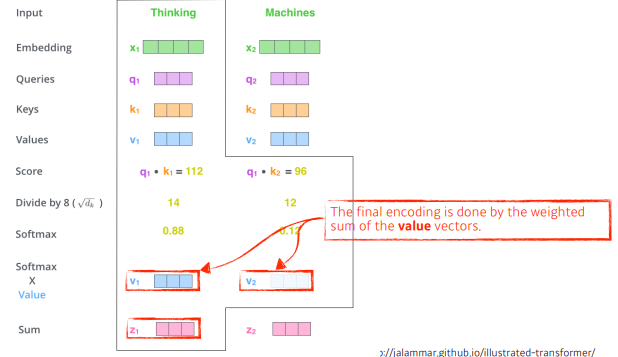
최종적으로 각 단어에서 나오는 value vector의 sum 을 사용한다.
정리하면
1. 각 단어에서 나오는 q,k vetor의 내적
2. q 벡터의 길이의 제곱근으로 normalize
3. softmax
4. 이렇게 나온 attention을 value 벡터와 weighted sum
--> 하나의 단어에 대한 encoding vector을 구할 수 있다.
이 때 주의할 점은 q,v 벡터는 내적을 해야하기 때문에 행렬 shape이 같아야 하고, v 벡터는 weighted sum을 하면 되므로 shape이 달라도 된다.
최종적으로 나오는 encoding vector의 차원은 value vector 와 같아야 한다.
위 과정(single headed attention)을 요약하면 다음 그림과 같다.
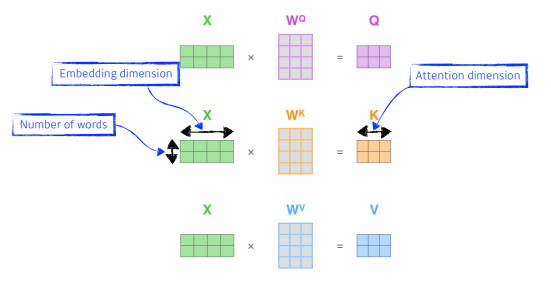
- 왜 잘될까?
내가 인코딩하려는 단어와 옆에 주어진 다른 단어들이 달라짐에 따라 출력이 달라질 수 있는 felxible 한 모델!
하지만 RNN은 1000개의 시퀀스가 주어지면 순서대로 돌리면 되지만(시간은 오래걸리겠지만 ) Transformer는 1000x1000 크기를 한번에 돌려야하기 때문에 한계가 있다.
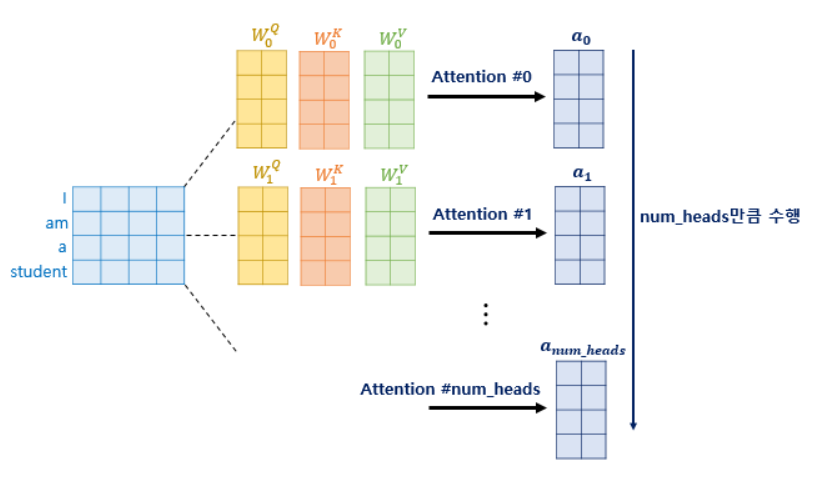
multi headed attention
multi headed attention 이란, attention을 병렬적으로 수행하는 것을 의미한다.
앞의 어텐션에서는 임베딩 차원()을 가진 단어벡터를 numheads(Q,K,V 를 $d{model}$ 보다 더 작은 차원으로 바꾸기 위한 transformer의 hyper parameter)로 나눈 차원을 가지는 Q,K,V 벡터로 바꾸는 어텐션을 수행한다.
논문 기준으로는 512의 차원의 각 단어 벡터를 8로 나누어 64차원의 Q, K, V 벡터로 바꾸어서 어텐션을 수행한 셈인데, 이제 이 의미와 왜 의 차원을 가진 단어 벡터를 가지고 어텐션을 하지 않고 차원을 축소시킨 벡터로 어텐션을 수행하였는지 이해해보자.
Further Question
-Pytorch에서 Transformer와 관련된 Class는 어떤 것들이 있을까요?
참고
[RNN, LSTM] https://ratsgo.github.io/natural%20language%20processing/2017/03/09/rnnlstm/
[RNN, LSTM, GRU]
https://excelsior-cjh.tistory.com/185
[Transformer][transformer wikidocs](https://wikidocs.net/31379)
과제 수행 과정 및 결과
- Scaled Dot-Product Attention (SDPA) 와 Multi-Headed Attention 의 구현
피어 세션
-
RNN 에서 a,b,c,d,e 의 시퀀스가 들어왔을 때 단어간의 관계성을 정확히 파악할 수 없는 이유가 무엇인지
시퀀스의 길이가 길어질수록 역전파 과정에서 기울기 소실이 일어나 앞쪽에 있는 정보를 제대로 업데이트하지 못하는 문제가 발생하기 때문에
이를 해결한 모델이 LSTM. -
Transformer에서 score가 나오는 과정? / 그럼 해당 score는 모든 단어의 k벡터와 내적하는데 그 유사도는 어떤 단어와의 관계를 나타내는 것인지 / attension map의 차원이 nXn ?
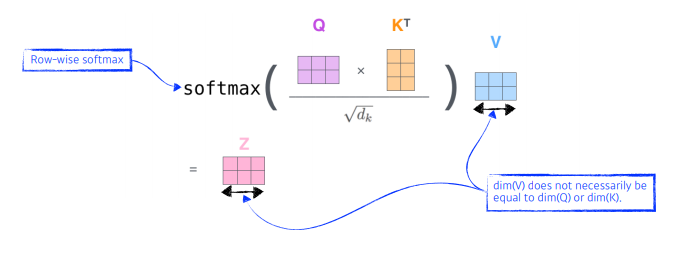
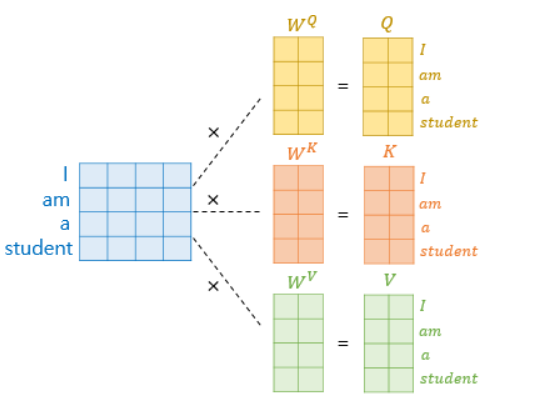 전체 입력은 nxm 행렬(단어의 갯수 x 임베딩 차원(hyper parameter))
전체 입력은 nxm 행렬(단어의 갯수 x 임베딩 차원(hyper parameter))
k,q벡터도 입력과 같은 차원임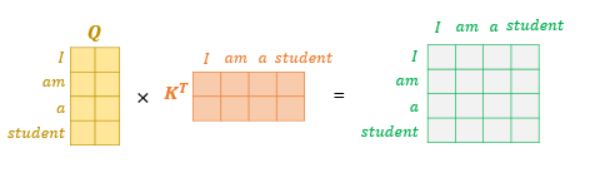
단어의 유사도를 구하기 위해 q 와 k^T를 내적하고, 그 결과는 nxn의 정방행렬이며 이 행렬의 원소가 각 단어의 유사도를 뜻함.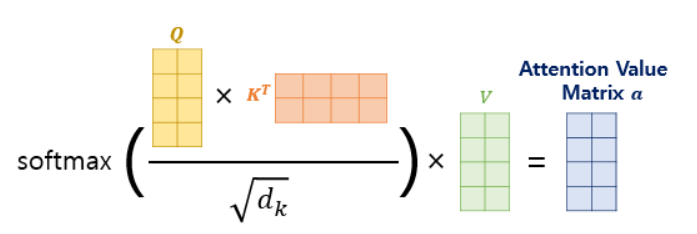
이 nxn 행렬 전체를 임베딩 차원의 제곱근으로 나눠 normalization한 후 softmax를 취하게 되면 최종적으로 각 단어들에 대한 유사도의 정보를 담은 weight가 나오게 된다.
이 weight와 단어별로 구한 value벡터를 weight sum하게 되면 최종적으로 attention 계층을 통해 나오는 단어 임베딩 벡터 z가 나오게 되는 것!! -
가우시안 분포에 대한 발표 진행
학습 회고
keep
- 잘 이해안되는 부분 더 찾아보고 정리하기
problem
- 코어시간에 강의를 먼저 다 들어야하기 때문에 시간 관리를 효율적으로 해야함
- 코어시간 끝난 후 공부안함
try
- 더 찾아보는건 강의 이해와 과제 수행에 필요한 것을 찾아보고, 추가적인건 나중에 정리하기
- 제발 코어시간 끝나고 공부해
