Ref
Yolo survey Paper
Object-Detection-YOLO-v1v6
yolov6-object-detection
딥러닝의 Quantization (양자화)와 Quantization Aware Training
IoU 종류
각종 Reference 논문 본문에 링크함
이 글은 object detection 에 대한 기본적인 이해가 있으신 분들을 위한(?) 글입니다.
- Yolo 1~4 까지의 내용을 접해보신 분
- 1stage detector와 2stage detector의 차이를 알고 계시는 분
- Anchor Based와 Anchor Free detector의 차이를 알고 계시는 분
전체적인 요약과 내용은 Yolo survey Paper를 참고했으며, 자세한 내용은 각 논문을 직접 읽어본 내용입니다.
YOLOv6, YOLOv6-v3.0의 Main Changes
YOLO v6
2022, https://arxiv.org/abs/2209.02976
2022년 9월, Meituan Vision AI Department 에서 논문을 공개했다.
v4,v5와 비슷하게 다양한 크기의 모델을 공개했으며,
당시 트렌드인 anchor point base 방법론을 따라 Anchor를 사용하지 않는 Anchor-Free 모델이다.
Main Changes
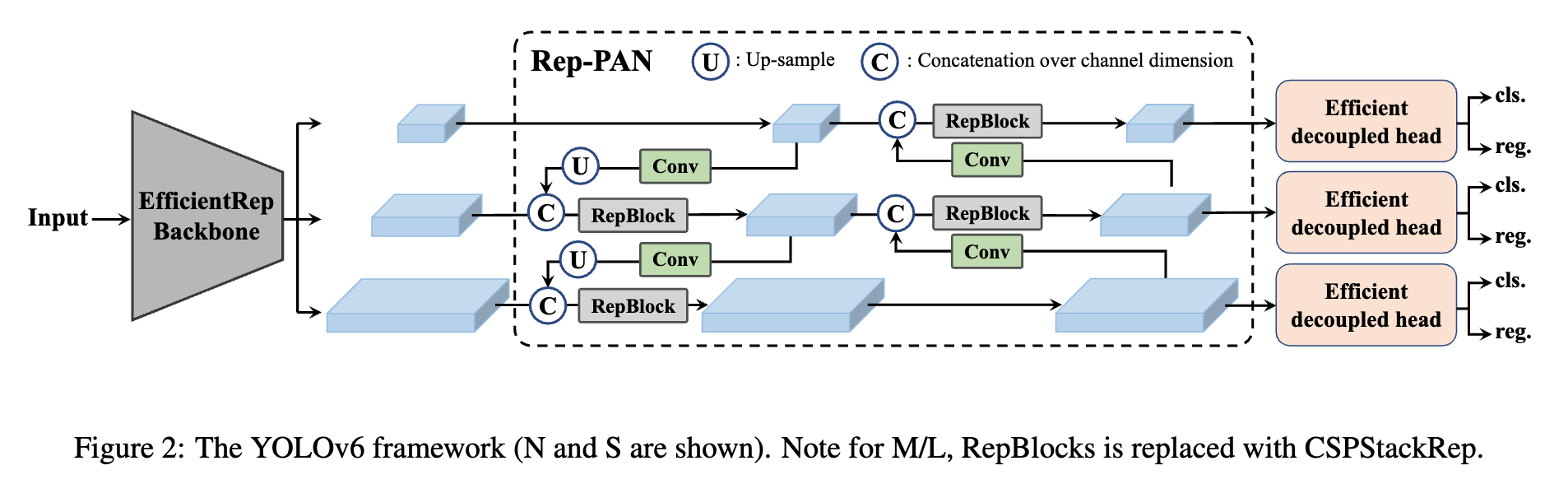
- A new backbone based on RepVGG
- Backbone : 이전 yolo backbone보다 higher parallelism을 자랑하는 EfficientRep 사용
- Neck : RepBlocks으로 강화된 PAN 사용 (더 큰 모델의 경우 CSPStackRep 블록을 사용)
- Head : Efficient Decoupled Head 사용 (from YOLOX)
- New classification and regression losses.
- classification : VariFocal loss
- regression : SIoU / GIoU loss
- Label assignment using the Task alignment learning approach introduced in TOOD.
- A self-distillation strategy for the regression and classification tasks
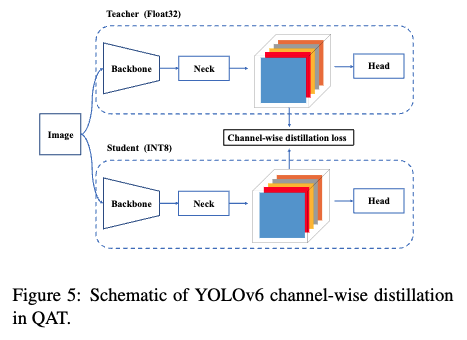
- A quantization scheme for detection using RepOptimizer and channel-wise distillation that helped to achieve a faster detector.
YOLO v6 - v3.0
2023, YOLOv6 v3.0: A Full-Scale Reloading
Yolo v7, v8 이후인 2023 년 1월에 v3.0이 나왔다.
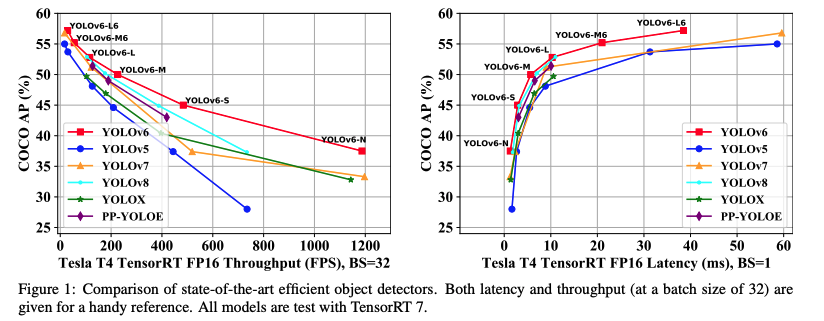 다른 모델들과 비교했을 때 정확도와 속도 측면에서 모두 나은 성능을 보인다.
다른 모델들과 비교했을 때 정확도와 속도 측면에서 모두 나은 성능을 보인다.
Main Changes
- Renew the neck of the detector with a Bi-directional Concatenation (BiC)
- Anchor-Aided Training (AAT)
- Deepen YOLOv6 to have another stage in the backbone and the neck
- New self-distillation strategy, in which the heavier branch for DFL is taken as an Enhanced Auxiliary Regression Branch
Yoolv6 자세한 설명
[Main Changes 1] A new backbone based on RepVGG
Backbone Background - RepVGG
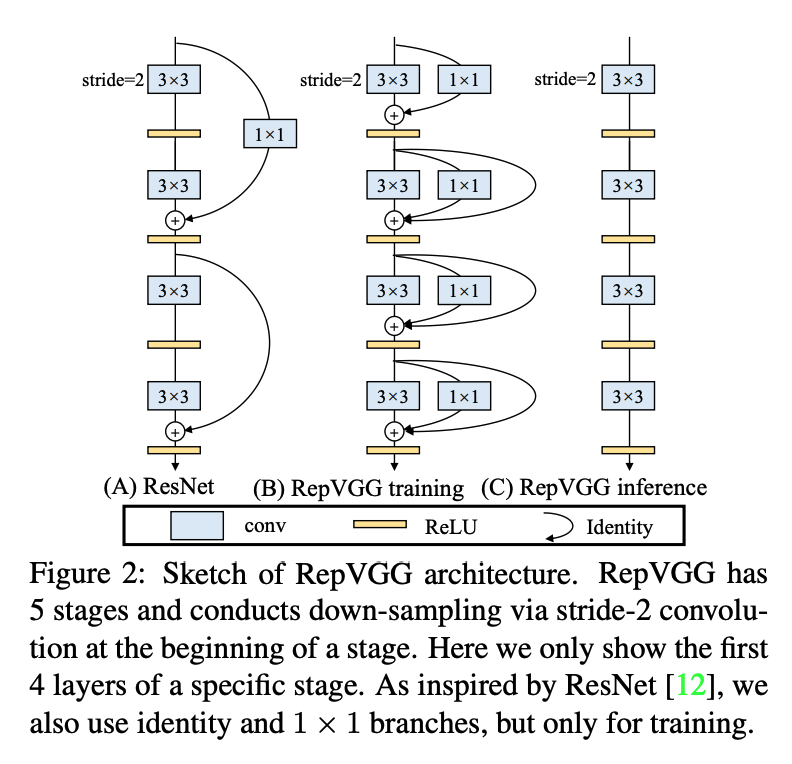
ResNet, DenseNet과 같은 multi-branch network는 높은 정확도를 보이지만 parallism은 줄어들고 inference time이 증가한다. 반면 VGG 와 같은 single-path model들은 적은 메모리 사용량, 높은 infererece 효율을 보인다.RepVGG는 training time에는 ResNet 과 같이 multi-branch 로 구성되는 반면 inference time 에는 structural re-parameterization 기법을 통해 3x3 Conv layer, ReLU로만 구성된 single-path model을 만들어서 inference time을 줄였다.
논문에서는 identity를 degraded 1x1 Conv , 1x1 Conv를 degraded 3x3 Conv로 간주한다.
Parameter 관점에서 보면 수식 정리에 따라 3x3 Conv Layer를 거치고 BN을 거치는 과정은 하나의 3x3 Kernel 과 bias를 가지는 Conv Layer로 변환할 수 있다. Identity도 마찬가지로 1x1 Kernel과 bias를 가지는 Conv로 변환한다. 따라서 위 (1) 수식을 정리하면 하나의 3x3 Kernel, 두개의 1x1 Kernel, 세개의 bias vector로 변환할 수 있어서 구조적으로 Single Path를 만들 수 있다. (Structural re-Parameterization)
-
Backbone - EfficientREP
RepVGG는 작은 network에서는 inference time을 크게 증가시키지 않으면서 좋은 feature representation 능력을 가지고 있으나, 큰 네트워크에서는 single path로 인해 parameter와 computation cost가 크게 증가하는 단점이 있다.(Residual Connection을 없앴으므로)
따라서 작은 네트워크에서는 RepBlock을, 큰 네트워크에서는 CSPStackRep block을 사용했다.
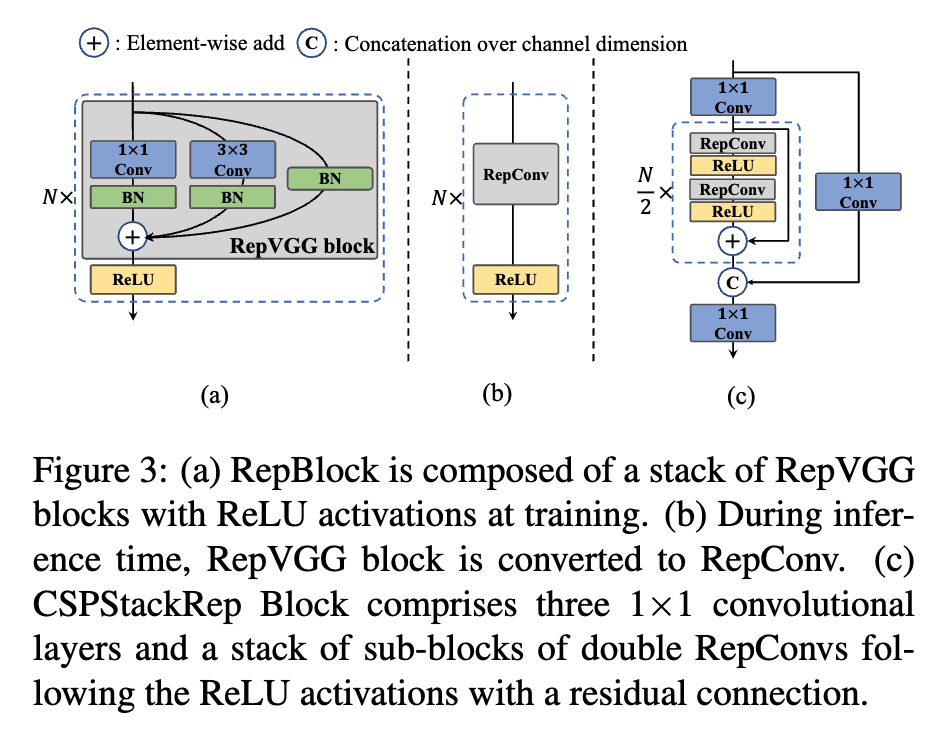 CSPStackRep block은 3개의 1x1 Conv layer와 두 쌍의 RepConv(inference에 사용되는 RepBlock을 말함)와 ReLU로 이루어진 sub-block으로 이루어져 있다. Residual connection을 사용하며 CSP connection을 통해 computation cost가 크게 증가하지 않는 선에서 accuracy를 향상시켰다. (accuracy와 speed 간의 trade-off 를 고려)
CSPStackRep block은 3개의 1x1 Conv layer와 두 쌍의 RepConv(inference에 사용되는 RepBlock을 말함)와 ReLU로 이루어진 sub-block으로 이루어져 있다. Residual connection을 사용하며 CSP connection을 통해 computation cost가 크게 증가하지 않는 선에서 accuracy를 향상시켰다. (accuracy와 speed 간의 trade-off 를 고려)
Neck Background - PAN
PAN은 bottom-up path augmentation을 통해 lower layers feature 정보를 top layer까지 효과적으로 전달하여 localization 성능을 높인다.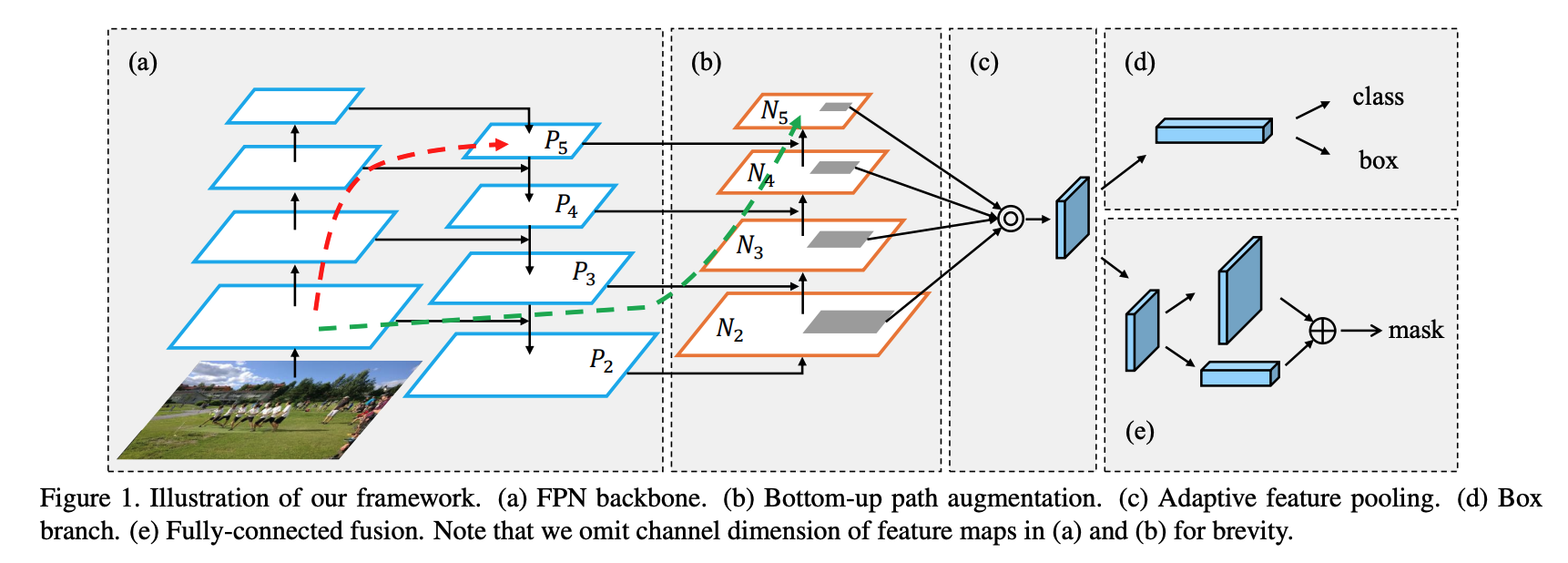 low level feature는 객체의 texture, pattern, edge 와 같은 local feature를, high level feature는 이미지 전체의 context와 같은 global feature 정보를 담고 있다. 따라서 FPN과 같이 low level, high level feture 정보를 잘 섞어주어야 모델이 다양한 정보를 토대로 예측을 잘 할 수 있다.
low level feature는 객체의 texture, pattern, edge 와 같은 local feature를, high level feature는 이미지 전체의 context와 같은 global feature 정보를 담고 있다. 따라서 FPN과 같이 low level, high level feture 정보를 잘 섞어주어야 모델이 다양한 정보를 토대로 예측을 잘 할 수 있다.
PAN 구조가 특히 localization 성능을 높이는데 기여한 이유도 마찬가지로 edge에 대한 정보를 가진 local feature 를 잘 활용했기 때문에 객체의 위치를 조정하는 localization 성능을 높일 수 있는 것이다.
FPN과 비교하면(그림에서 빨간 점선) low layer feature를 top layer로 보낼 때
FPN은 100개 이상의 layer를 지나야 하는데 PAN은 FPN에 extra bottom-up pathway shortcut을 추가하여 10개 이하의 layer만 지나면 된다. -
Neck - RepPAN(RepBlocks으로 강화된 PAN)
YOLO v4, v5 에서 사용된 PAN이 v6의 base가 되었고, 위에서 설명한 이유로 작은 모델에는 RepBlock을, 큰 모델에는 CSPStackRep을 사용하였고 이를 YOLO v6에서는 Rep-PAN이라고 칭한다. -
Efficient DeCoupled Head
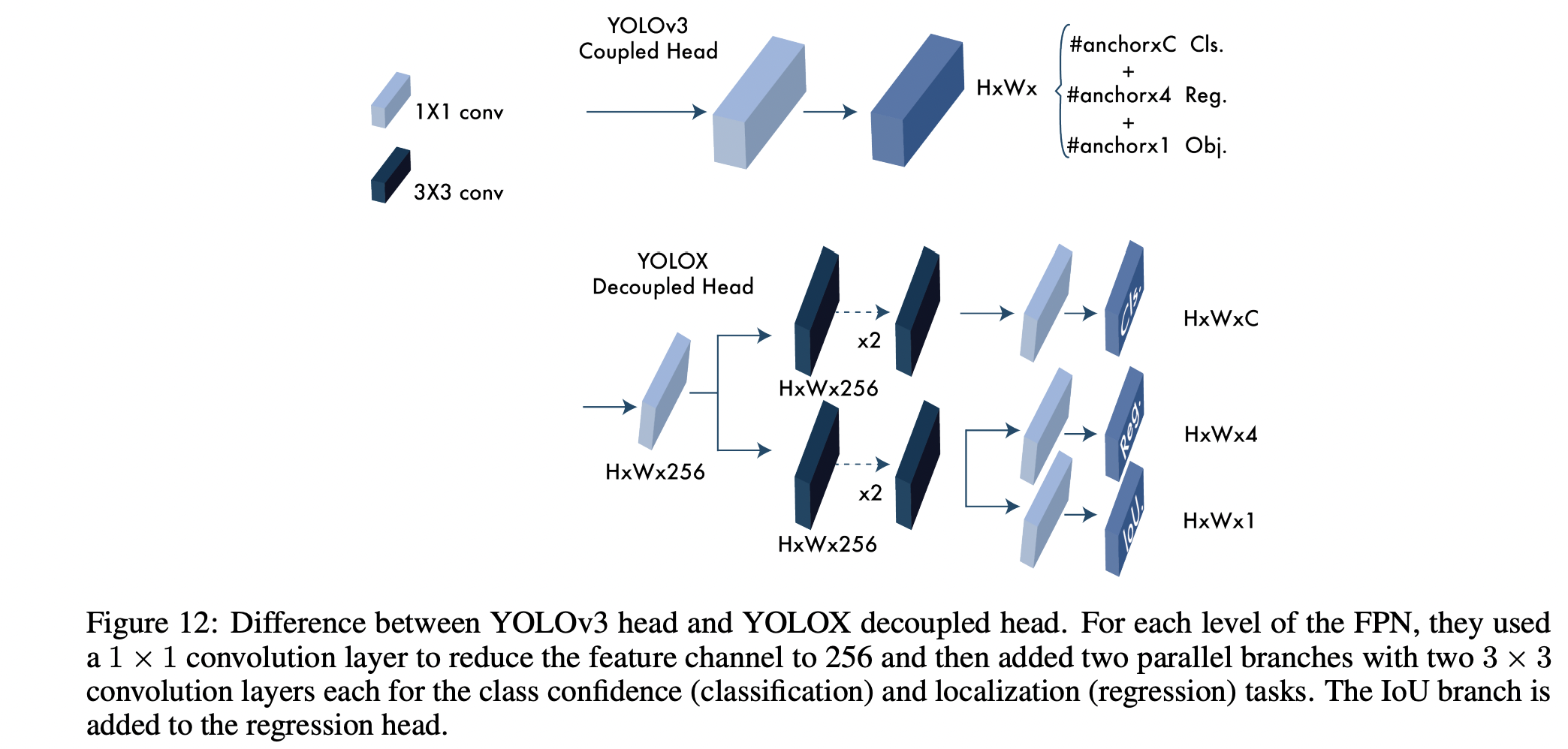 2021년에 나온 YOLOR에서 사용된 기법으로, 이전에는 Classification branch와 Regression branch가 parameter를 공유했으나 classification confidence와 localization accuracy 간의 misalignment가 있을 수 있어 두 branch를 각각 다른 head로 분리했고, 그 결과 AP가 1.1 상승하고 학습할 때 수렴도 더 빨랐다고 한다.
2021년에 나온 YOLOR에서 사용된 기법으로, 이전에는 Classification branch와 Regression branch가 parameter를 공유했으나 classification confidence와 localization accuracy 간의 misalignment가 있을 수 있어 두 branch를 각각 다른 head로 분리했고, 그 결과 AP가 1.1 상승하고 학습할 때 수렴도 더 빨랐다고 한다.
[Main Changes 2] New classification and regression losses.
Classification Loss Background - Focal loss
Focal loss 는 모델의 weight update를 조절하여 class imbalance의 문제를 완화하는 loss이다.
Detector의 최적화에서 classifier의 성능을 높이는 것은 중요한 부분이다. 전통적으로 classification loss에는 cross-entropy를 사용했는데, CE loss는 가중치를 업데이트 할 때 hard/easy sample 또는 positive/negative sample 모두 동일한 비율로 가중치를 업데이트 시킨다.
1-stage detecter의 경우 사람이 미리 정의한 anchor box를 사용하지 않고 이미지 전체에서 모델에 feed할 input bounding box를 뽑아내므로 전체 박스중에서 배경(negative sample)이 차지하는 비율이 클 수 밖에 없다. 이는 class 간의 imbalance를 야기하고, 자연스럽게 모델은 더 많이 학습한 배경만을 쉽게 분류하게 된다. 이렇게 되었을 때 배경을 easy sample, 객체를 hard sample이라고 부른다.
이는 1-stage detector 뿐 아니라 class-imbalance가 심한 데이터인 경우에 어느 모델에서나 일어나는 문제이다.
우리의 목적은 모델이 배경이 아닌 객체를 더 잘 분류하게 만드는 것이므로 easy sample일 경우에는 loss에 가중치를 적게 주고, hard sample인 경우에는 loss에 가중치를 크게 주어 hard sample을 학습할 때에 모델의 weight가 더 많이 업데이트되도록 하였다.
이 loss가 바로 Focal loss이다.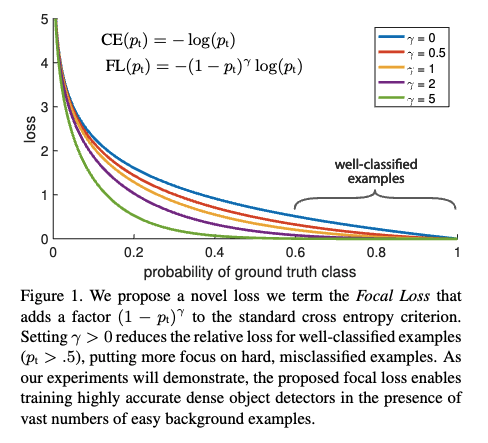 : model’s estimated probability for the class with =1
: model’s estimated probability for the class with =1
: focusing parameter, loss become CE loss when = 0
: modulating factor
class confidence score인 가 0.5 이상으로 클수록(높은 정확도를 가지고 잘 분류되었을 때) factor는 0에 가까워지고 loss에 대한 가중치도 작아진다.Classification Loss - VariFocal Loss
YOLO v6 연구자들은 Focal Loss, Quality Focal Loss , VariFocal Loss, Poly Loss와 같은 다양한 Loss를 실험해보고 가장 성능이 좋은 VFL을 선택했다.
VFL도 Focal Loss에서 출발했기 때문에 기본 아이디어는 같다.
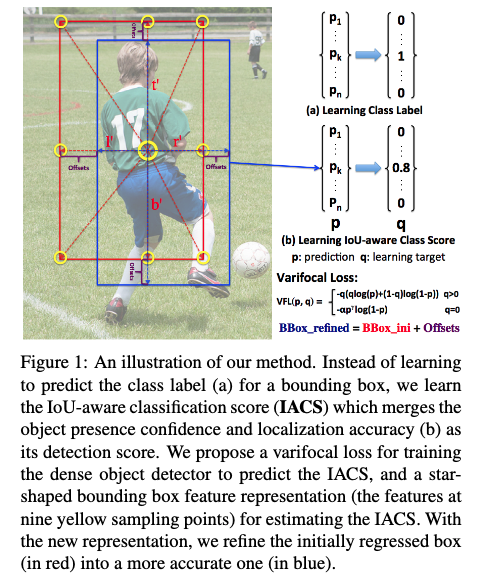
FL과의 차이점은 Loss의 구성요소인데, VFNet 논문에서는 bounding box classification과 regression을 동시에 수행하기 위해 단순히 class confidence score만 구하는 것이 아니라 GT와의 IOU를 고려한 IoU-aware classification score(IACS)를 측정했다.
P는 예측된 IACS값. q는 target IOU score. (positive sample인 경우 GT와의 IOU, negative sample인 경우 0)
q=0일 때만 (negative sample일 때만) loss 앞의 를 사용하여 가중치 업데이트가 적게 일어나게 한다.Regression Loss - SIoU / GIoU loss
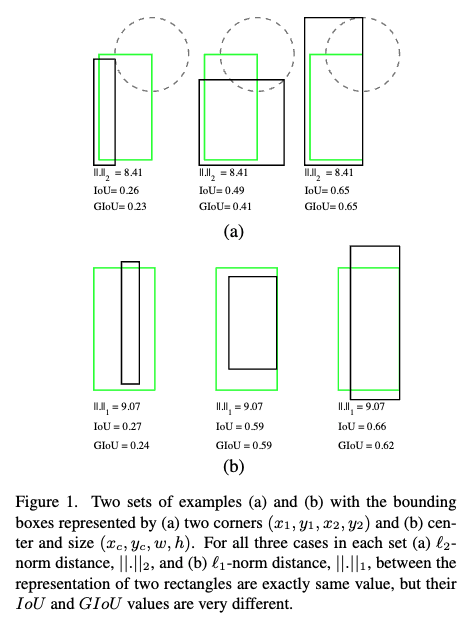
기존의 Regression Loss로는 L1 Loss가 사용되었는데, L1 loss는 bounding box의 생김새에 따른 GT와의 겹침 정도(IoU)가 달라도 같은 값을 내어놓는 문제로 인해 IOU를 이용하는 IoU-series Loss가 많이 연구되었다.
Yolo v6에서는 GIoU, CIoU, SIoU를 실험한 결과 YOLOv6-N and YOLOv6-T에는 SIoU를, 나머지 모델에는 GIoU를 사용한다.
- SIoU (SCYLLA-IoU)
Angle, Distance, Shape, IoU 를 모두 고려한 metric
- GIoU (Generalized IoU)
IoU는 두박스가 겹치지 않을 때 언제나 0의 값을 가지므로 두박스의 거리가 얼마나 가까운지 정보를 알 수 없고, 영역에 따른 겹침 정도만 파악하기 때문에 박스가 겹쳐진 모양 또한 파악할 수 없다는 단점이 있어 이를 극복하기 위해 GIoU 제안.
GIoU는 Predict bounding box와 GT를 모두 포함하는 박스 중 가장 작은 box인 Convex object C를 이용한다. 는 C에서 A와 B의 영역의 합을 뺀다는 것을 의미하고 전체 IoU에서 이 값을 빼서 loss를 계산한다.
[Main Changes 4] A self-distillation
knowledge distillation 이란, teacher model 과 student model 두 모델을 사용하는데, teacher model은 student model을 학습할 때 사용된다. 미리 학습된 teacher model의 예측 값이 GT와 함께 soft label로 사용되는 방법이다.
Computation Cost를 증가시키지 않고 model의 정확도를 향상시키기 위해 teacher model과 student model의 KL-divergence를 최소화하는 knowledge distillation technique을 사용했다. 이때 teadcher model이 그대로 stdent model로 사용되지만 pre-train을 했기 때문에 self-distillation이라고 말한다.
Regression and Classification tasks 모두에 적용하는데, Regression task를 위해서는 DFL(Distribution Focal Loss)을 사용한다.
DFL은 GFL의 한 종류인데, GFL(Generalized Focal Los)은 original FL이 category label이 discrete할 때만 사용이 가능하기 때문에 continuous value를 가진 target도 예측할 수 있도록 한 Loss이다.
기존의 Focal Loss는 binary classification 문제에서 사용되며, 이 문제에서는 두 개의 클래스 중 하나를 선택하는 것이다. 이때 선택되지 않은 클래스는 무시하고, 선택된 클래스의 확률값을 최대화한다. 하지만 object detection과 같은 문제에서는 continuous value를 가진 target을 예측해야 한다. 예를 들어, bounding box regression에서는 바운딩 박스의 좌표값(x, y, w, h)이 continuous value를 가진다.
GFL은 이러한 continuous value를 가진 target을 예측하기 위해 다음과 같은 방식을 사용한다. 먼저, object detection 모델은 bounding box의 좌표값(x, y, w, h)을 예측하게 되고, 이때 예측값과 실제값(target)의 차이를 계산한다. 이 차이를 IoU(Intersection over Union)로 변환한 다음, 이 값을 GFL에서는 continuous value로 사용한다. 이렇게 변환된 값을 사용하여 Focal Loss와 유사한 방식으로 Loss를 계산한다.DFL은 Focal Loss와 Cross Entropy Loss를 결합한 형태로, 클래스 간 불균형 문제를 해결하고 분류 성능을 향상시키는 데 도움을 준다.
DFL은 Focal Loss와 Cross Entropy Loss의 가중치를 조정하는 방식으로 동작한다. Focal Loss는 높은 확률을 가진 예측값에 대해 더 큰 가중치를 부여하고, Cross Entropy Loss는 모든 클래스에 대해 동일한 가중치를 부여한다. DFL은 이 두 가지 손실 함수를 결합하여 높은 확률을 가진 클래스에 대해서만 Focal Loss의 가중치를 적용하는 방식으로 동작한다.
이 논문에서는 Teacher 모델과 Student 모델을 학습시키고, DFL을 적용하여 높은 확률을 가진 클래스에 대해 더 큰 가중치를 부여하여 분류 성능을 향상시켰다.
[Main Changes 5] A quantization scheme
더 빠른 detecter를 만들기 위해 Post-training quantization(PTQ)과 quantization-aware training (QAT) 두가지 방법을 사용하여 실험을 진행했다.
PTQ는 작은 calibration data set 만을 사용해서 학습이 완료된 후에 model 의 weight를 quantize 하는 방법이고, QAT는 training set을 사용해서 학습 도중에 quantize 하였을 때를 시뮬레이션하여 최적의 weight를 구하는 것과 동시에 quantization을 하는 방법이다. QAT는 주로 distillation과 함께 사용한다.- RepOptimizer(PTQ)
Yolo v6는 re-parameterization block을 많이 사용했기 때문에 기존의 PTQ 방법을 적용하면 정확도의 하락이 너무 커서 RepOptimizer로 문제를 완화한다.
RepOptimizer는 기존의 역전파 기반 최적화 알고리즘과는 달리, 파라미터를 새로운 형태로 변환한 후 최적화를 수행하는 방법이다.
RepOptimizer는 네트워크의 파라미터를 RepVGG와 같은 간단한 형태로 변환한다. 이렇게 하면 네트워크의 파라미터 수를 줄일 수 있으며, 모델의 일반화 성능을 향상시킬 수 있다. 변환된 파라미터에 대한 최적화는 기존의 역전파 기반 최적화 알고리즘과 동일하게 수행된다.
- channel-wise distillation(QAT)
PTQ의 정확도 하락을 보완하기 위해 QAT 기법 적용
Architect
result
| 모델 | 사용 데이터 셋 | GPU | AP | AP50 | FPS |
|---|---|---|---|---|---|
| YOLOv6-L | MS COCO dataset test-dev 2017 | NVIDIA Tesla T4 | 52.5% | 70% | 50 |
Evaluated on MS COCO dataset test-dev 2017, YOLOv6-L achieved an AP of 52.5% and AP50 of 70% at around 50 FPS on an NVIDIA Tesla T4.
Yolov6-v3.0 자세한 설명
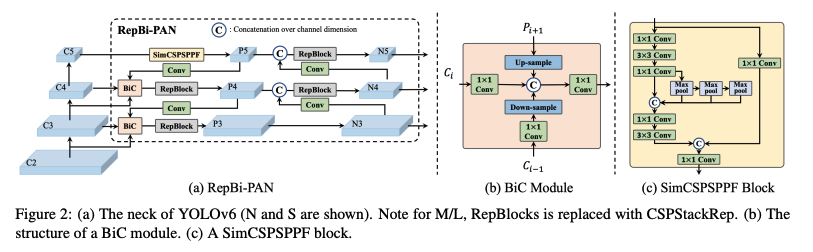
[Main Changes 1] Bi-directional Concatenation (BiC)
Detector의 neck을 BiC로 대체한다.
세개의 인접한 layer의 feature map을 inregrate하기 위해 Bi-directional Concatenation(BiC) module을 제안한다. 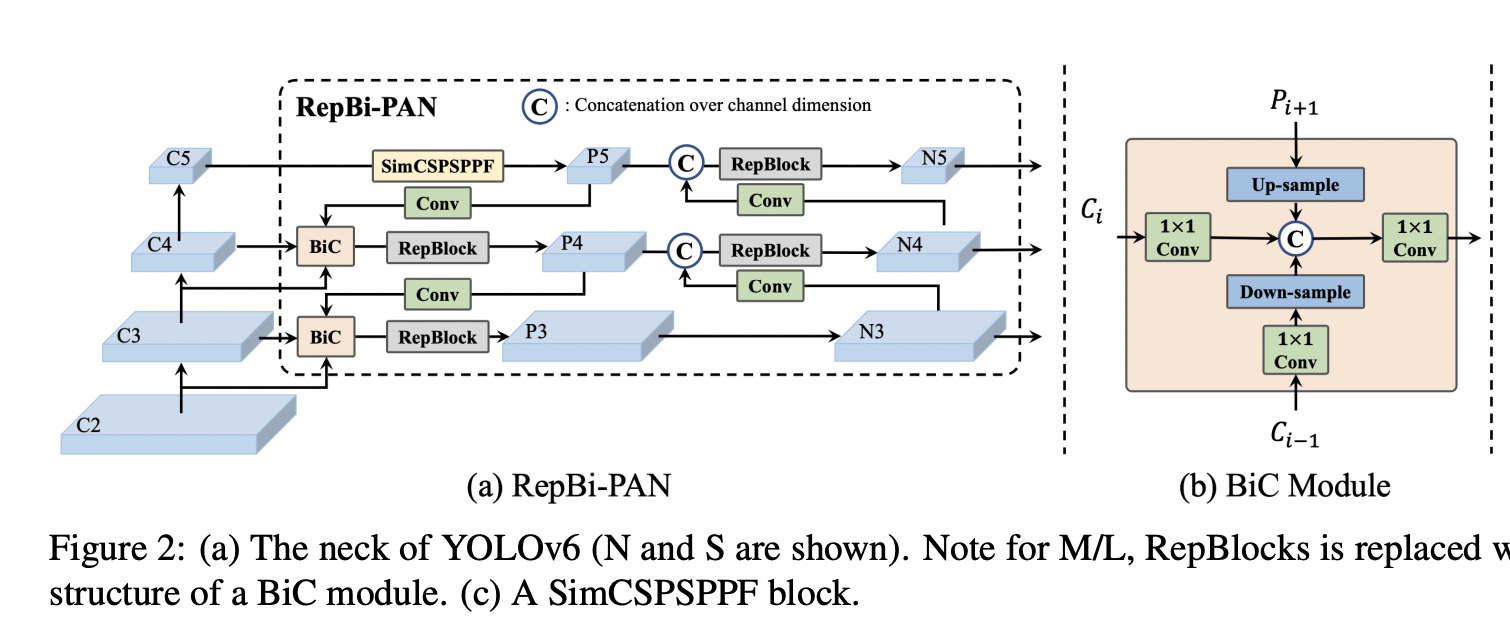 이는 PAN의 top-down path에서 오는 feature인 에 backbone의 번째 layer에서 나온 low-level feature를 추가로 fusion 한다. 이렇게 하면 더 정확한 localizatoin signal을 얻을 수 있다.
이는 PAN의 top-down path에서 오는 feature인 에 backbone의 번째 layer에서 나온 low-level feature를 추가로 fusion 한다. 이렇게 하면 더 정확한 localizatoin signal을 얻을 수 있다.
YOLOv5 release v6.1에서 사용한 SPPF block을 CSP-like version인 SimCSPSPPF Block으로 간소화한다. SimCSPSPPF는 representational ability, 즉 표현력을 강화한 방법이다.
SPPF는 SPP (Spatial Pyramid Pooling)의 변형으로
SPP는 입력 이미지를 여러 사이즈의 그리드로 분할하고, 각 그리드 영역에서 최대 풀링 연산을 수행하여 공간적인 정보를 추출하는 방법이다. 이를 통해 입력 이미지의 크기와 무관하게 동일한 크기의 특성 맵을 얻을 수 있다.
반면, SPPF는 SPP에서 추가적으로 특성 맵의 크기를 줄이는 기능을 수행한다. 이를 위해 SPP 후에 1x1 크기의 컨볼루션 연산을 적용하고, 이를 반복적으로 수행한다. 이 과정을 통해 특성 맵의 크기를 줄이면서도 공간적인 정보를 보존할 수 있다.
따라서, SPPF는 SPP와 비슷한 기능을 수행하지만 특성 맵의 크기를 줄이는 추가적인 기능을 가지고 있다.
SimCSPSPPF에서 찾을 수 있는 CSPNet의 특징은 input에서 갈라져서 1x1 Conv 를 거쳐 마지막에 Concat되는 Connection 이다.
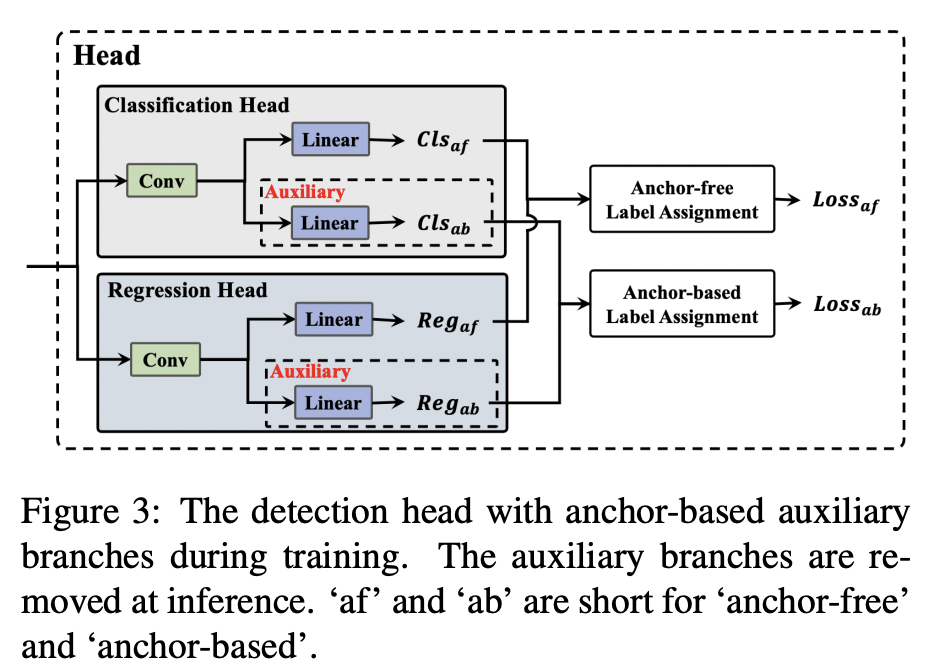
[Main Changes 2] Anchor-Aided Training (AAT)
Inference efficiency에 영향을 주지 않으면서 Anchor-Based와 Anchor-Free paradigms의 장점을 모두 가져가기 위해 Anchor-Aided Training을 적용한다.
Yolov6-n에서 Anchor-Free와 Anchor-Based 기법을 비교했을 때 Anchor-Based에서 더 좋은 성능을 냈다. AAT는 Anchor-Based 에서 오는 성능 향상을 위해 학습을 할 때 Anchor-Based를 사용하는 보조브랜치를 함께 학습한다. Inference할 때는 보조 브랜치를 제거하여 속도 감소를 피한다.
[Main Changes 3] Deepen YOLOv6
Backbone과 Neck에 stage를 추가하여 모델의 깊이를 깊게한다. 이를 통해 high-resolution input으로 들어오는 COCO dataset에서 SOTA를 달성했다.
[Main Changes 4] New self-distillation strategy : Enhanced Auxiliary Regression Branch
YOLOv6의 small model의 성능을 높이기 위해 새로운 self-distillation을 제안한다. 학습중에는 regression branch의 DFL을 enhanced auxiliary regression branch로 바꾸어 사용하고 inference 시에는 속도를 위해 제거한다.
전체 loss는 로 구성되며 KD를 조절하는 파라미터인 는 teacher model에서 오는 soft label과 student model 에서 오는 hard label을 dinamically하게 적용하기 위해 cosine weight decay를 사용한다.
이 때 DFL은 regression branch를 위해 extra parameter가 필요한데, 이는 inference time을 증가시키는 원인이 된다.
이를 피하기 위해 본 논문에서는 Decoupled Localization Distillation (DLD) 를 제안한다. DFL을 통합하기 위헤 heavy auxiliary enhanced regression branch를 제안했다. Self-distillation 과정에서 student model은 naive regression branch와 enhanced regression branch를 동시에 사용하는 반면 teacher model은 auxiliary branch만 사용한다.
naive regression branch는 오직 hard-label로만 학습되고, auxiliary branch는 teacher model에서 오는 soft label로 학습된 signal과 hard label 모두를 사용하여 학습된다.
Distillation 이후에 naive regression branch 유지되고 auxiliary branch는 제거된다. 이 방법으로 Distillation 에서 inference efficiency에 영향을 주지 않고 DFL을 사용할 수 있다.
Architect
result
| 모델 | 사용 데이터 셋 | GPU | AP | AP50 | FPS |
|---|---|---|---|---|---|
| YOLOv6-L6 | MS COCO dataset 2017 val | NVIDIA Tesla T4 | 57.2% | 74.5% | 29(TRT, bs32) |
Evaluated on MS COCO dataset 2017 val, YOLOv6-L6 achieved an AP of 57.2% and AP50 of 74.5% at around 29 FPS on an NVIDIA Tesla T4 in the same environment with TensorRT.
전체 요약
Yolov6과 Yolov6-v3.0 에서 정확도를 향상시키면서도 inference 속도를 증가하지 않기 위한 많은 기법이 소개 되었는데,
이를 (1)학습 정확도를 높이기 위한 방법과 (2)Inference 속도 증가를 막는 기법으로 나누어 생각해보면 다음과 같다.
(1) 학습
BackBone으로 EfficientRep Block, Neck으로 Rep Bi-PAN, PAN에서 BiC Module 사용하는데,
v3.0에서 Backbone과 Neck에 Stage 추가하여 깊이를 깊게 함
기본적으로 Anchor-Free 모델이지만 Anchor-Based Branch 추가한 AAT 기법으로 학습
Cls 에 VariFocal Loss , Reg 에 SIoU / GIoU loss 사용
Label assignment using the Task alignment learning approach / v3.0 ATSS 적용
(2) Inference
BackBone, Neck에 모두 Re-Parameterization 사용
Self-distillation 사용
PTQ, QAT 모두 적용한 모델(nano, small)
