5월 23일 일요일에 진행한 프로그래머스 2021 dev matching : 머신러닝 개발자 참여 후기!
데브 매칭?
프로그래머스에서 주최하는 대회? 로, 자세한 사항은 위의 링크~
데브매칭은 내 이력서와 테스트 점수가 함께 지원한 기업에 전달되어 나를 더욱 주목받게 하는 채용 프로그램입니다. 인공지능/머신러닝 관련 개발자 동료를 애타게 찾고 있는 기업들을 이 데브매칭을 통해 만나보세요! 하나의 이력서로 최대 5개의 관심 있는 포지션을 선택하여 지원할 수 있습니다.
문제
이미지 분류 문제
내 풀이방법
1. 학습 이미지 전처리 (data augmentation)
transforms_train = transforms.Compose([
transforms.Resize((256,256)),
transforms.RandomRotation(15,),
transforms.RandomResizedCrop(227),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],std=[0.229, 0.224, 0.225]),
])
transforms_test = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],std=[0.229, 0.224, 0.225]),
])Resize, 회전, 좌우반전, normalize 사용.
2. 학습에 사용한 모델
pretrained ResNet18, 34, 50 사용.
학습 이미지 개수가 많지 않아 파라미터가 너무 많은 모델은 사용하지 않음
최종 모델은 ResNet50, fullt connected layer는 그냥 Linear-Relu
FC = nn.Sequential(
nn.Linear(2048, 1024),
nn.ReLU(),
# nn.Dropout(),
nn.Linear(1024, 512),
nn.ReLU(),
# nn.Dropout(),
nn.Linear(512, num_classes)
)// 학습 후 정확도를 올리고자 kaggle에서 본 Spinal Net을 fc에 적용해 보았으나, 큰 정확도 차이는 보이지 않았음
3. 학습 방법
criterion : cross entropy loss
optimizer : SGD(momentum = 0.9, weight_decay = 0.0002)
scehduler : StepLR(step =5, gamma = 0.1)
pretrained model을 fine tunning하는 것으로,
학습 시 각 Epoch 단계에서 train과 validation을 동시에 진행.
원래 코드는 validation 단계에서의 accuracy가 가장 높은 모델을 저장해서 test에도 사용하는 것이지만, 대회에서는 테스트 데이터를 사용한 accuracy를 리더보드로만 볼 수 있어서
train 단계에서 accuracy가 가장 높은 모델을 저장하여 test 함.
(54 번째 줄의 phase == 'train' 부분의 설명)

파라미터 fine tunning은 epoch을 10씩 설정하여 위의 학습 반복 후 가장 정확도가 높은 모델을 반환하여,
learning rate만 1/10로 줄여서 다시 학습 단계 반복함.
최종 결과 및 부족한 점
공개 리더보드 (제출한 csv 파일의 20%만으로 점수 냄) : 95.714%
최종 리더보드 (제출한 csv 파일 전체데이터로 점수 냄) : 92.286%
최종 순위는 동점자 포함 77등이었다,,,,,,,,,인생 쓰구만
최종 리더보드 순위가 8위였던 친구의 코드를 받아서 비교해본 결과
음,,, 77위 할만했네...ㅋㅋ 공부하자,,,,
그래도 최종 결과는 합격!!
친구는
1. 데이터 탐색
클래스 별로 데이터 수가 일정하지 않다는 것을 알고 imbalance 문제를 해결하기 위해
"가장 많은 클래스 데이터 개수 / 각 클래스의 데이터 개수"
를 CrossEntropyLoss의 가중치로 줌
2.데이터 전처리
회전 - 좌우 반전 - ColorJitter를 이용한 밝기,대비,색조 등 변경 - normalize
// 사실 내 코드 전처리는 상당히 쓸데없고 이상,,,,
왜냐면 애초에 이미지 크기를 227x227로 줬기 때문에...ㅜㅜ
3. 모델
ResNet50_32X4d 사용.
친구도 마찬가지로 데이터개수가 적어 너무 큰 모델을 사용하지 않았다고 함.
다만 나는 torchvision 사용으로 직접 FC 정의하였고,
친구는 timm 사용으로 클래스 개수만 바꿔줌. --> timm github
ResNet50보다 benchmark가 더 좋아염.
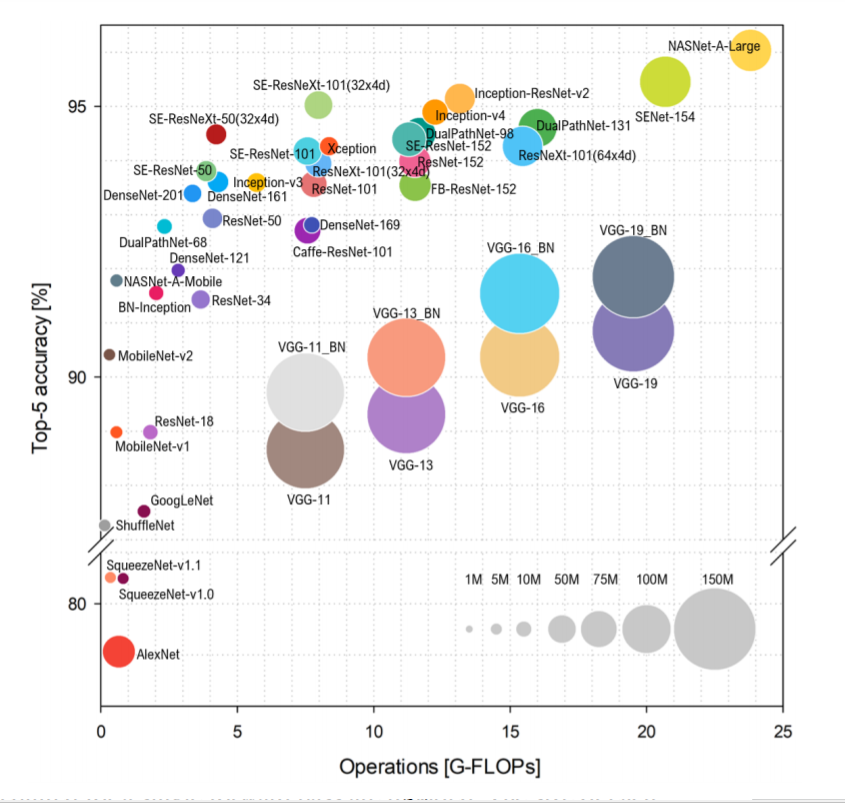
사진 출처 : Benchmark Analysis of Representative Deep Neural Network Architectures
4. 학습 방법
criterion : cross entropy loss (근데 이제 가중치를 준)
optimizer : AdamW (일반화 성능이 Adam보다 더 좋다)
scheduler : CosineAnnealingLR
친구도 한 epoch 반복마다 train과 validation이 반복되도록 함.
또 early stop으로 학습 시간을 줄이고, k-fold사용 하여 성능을 더 올림. 성능 평가 기준으로 f1 score도 확인.
최종 결과는!! 98%!!!!
후기 및 여담
집에서 혼자 유튜브나 블로그 강의 보면서 공부해서
내가 맞게 공부하고 있는건지도 모르겠고,,
특히 예를 들어 모델의 fine tunning이나 데이터 탐색 시 어떤 점을 잘 봐야할까 등 다양한 문제점이 생기면 그 해결방안이 확실하지 않아 개념도 잘 안잡혀있는 상태였다.
항상 내 공부법과 공부 내용, 그리고 어떤 것을 더 알아야할지도 애매해서 실력도 떨어지고 자존감도 떨어지고 있었는데! ! !
이번 대회를 계기로 확실히 내가 많이 부족하구나를 알았고,,
친구의 코드를 보고 분석하면서 어떤 점을 더 공부해야할지도 조금은 느낌이 오는 것 같다. (흔쾌히 코드도 주고 블로그 게시도 허락해준 친구에게 무한한 감사,,,,)
아직 멀었다 정말!! 열공하자!!!!!!!!!!!


좋아요오오옹~