1. FaceNet: A Unified Embedding for Face Recognition and Clustering [CVPR 2015]
Triplet loss를 제안한 첫번째 논문, metric learning 쪽에서 널리 쓰임.
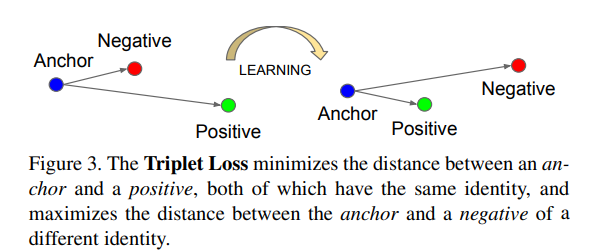
3개의 샘플(triplet);
- Anchor, Positive, Negative.
- Anchor가 Positive와는 가깝게, Negative와는 멀리 떨어지도록 학습.
-- : anchor와 Positive와의 거리
- : anchor와 Nagative와의 거리
- : hyper-param. Positive 샘플보다 Negative가 최소한 일정 정도 거리를 확보하도록 유도하는 term.
- 3 샘플을 선택하는 방법도 연구 주제가 될 수 있음.
- Hard-example mining 언급 - 별로 집중해서 안본 부분들 : 이미지 Quality에 대한 민감도, Dimension에 의한 민감도, Harmonic Triplet loss(서로 다른 embedding을 합치는 방식)
2. Mining on Manifolds: Metric Learning without Labels[CVPR2018]
- Triplet loss를 위한 sample 선택 방법.
- 같은 Manifold에 있는 샘플을 positive, 다른 Manifold에 있는 sample을 Nagetive로 해석함.
- In particular, we exploit similarity measured on a manifold estimated by a random walk process[previous work 21].
- Mining hard positive example. 같은 Manifold를 가지면서 Euclidean에서는 다소 먼 샘플을 고르는 것.
3. Deep Metric Learning Beyond Binary Supervision [CVPR 2019]
- Problem : Triplet loss는 같은지 틀린지에 대해서만 label을 매김(Binary).
- This paper : countinuous label을 도입하며 두가지 method를 제시.
- a new triplet loss that allows distance ratios in the label space to be preserved in the learned metric space.
- a triplet mining strategy adapted to metric learning with continuous labels.
- a new triplet loss(log-ratio loss)
-
- : Embedding의 distance 들의 log-거리비율.
- : label의 distance 들의 log-거리비율.
- 특징, # i와 j가 서로 바뀌어도 똑같은 값을 가짐.
-> i,j가 neg나 positive일 이유가 없음. - a trplet mining strategy
- label distance 상에서 가까운 sample을 사용.
- i,j가 서로 바뀌어도 triplet 똑같은 효과가 있기에 중복을 위해 없앰. - Experiment : human pose retrieval(비슷한 pose를 갖고 있는 sample 찾기), Room layout retrieval, caption-aware Image Retrieval.
