Deep Learning 05 Stochastic gradient descent
Gradient Descent notation
- Batch size: parameter를 한 번 업데이트할 때 사용할 training data의 개수. parameter를 한 번 업데이트 할 때 사용하는 데이터를 Batch라고 함.
- Number of epochs : 전체 training data를 파라미터 업데이트를 위해 몇 바퀴 돌릴지에 대한 횟수.
- Iteration : epochs를 한 번 돌릴 때 필요한 Batch의 개수
- Hyper parameter : Batch size와 Number of epochs가 해당하며, 머신러닝에서 사람이 직접 정해줘야하는 파라미터를 말함.
- 파라미터 업데이트 과정 : 1. forward pass 2. backpropagation
- 최적의 hyper parameter를 찾기위한 magic rule은 없음. 직접 해봐가면서 찾아야함
Gradient Descent 종류
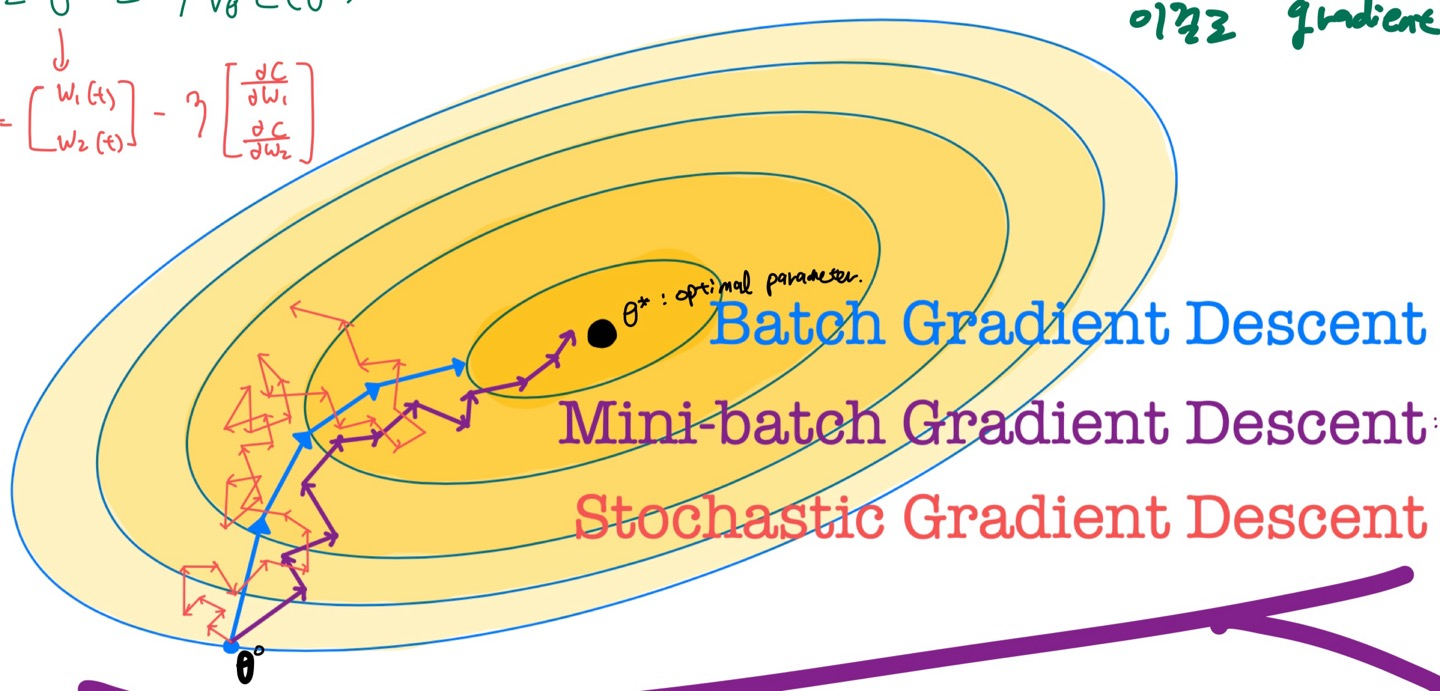
- Batch Gradient Descent : training data 전체를 하나의 Batch로 사용함
- 머신러닝처럼 training 데이터가 별로 없다면 이걸 쓰는게 좋긴함
- Stochastic Gradient Descent(SGD) : training data 중 1개씩만 batch로 사용함
- 데이터 하나하나가 중요하다면 이걸 쓰기도함.
- Minibatch Gradient Descent : 1번과 2번의 단점을 보완함. 적당한 Batch size로 진행하는 것. 딥러닝에선 데이터가 너무 많아서 딥러닝에선 보통 이 방법만 씀.
- Minibatch gradient descent는 SGD로 불리기도함.
Batch Gradient Descent
- 전체 데이터셋으로 gradient 계산함(한번 파라미터 업데이트를 할때마다 한번의 epoch가 돎.)

- 장점
1. convex한 면에 대해 local minimum이 아닌 global minimum으로 잘 찾아감
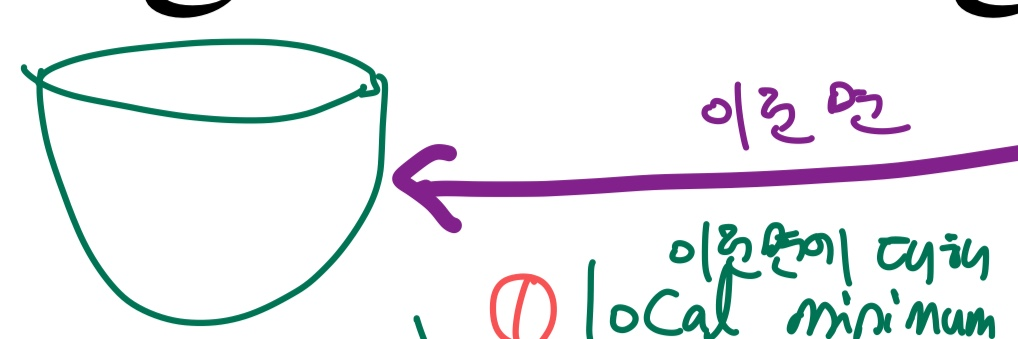 <<Fig. convex한 면의 예시>>
<<Fig. convex한 면의 예시>>
2. total cost를 따지기에 cost surface상으로 판단하여 최적의 경로를 찾아감 -> 노이즈에 강건함 - 단점
1. 한번 트레이닝할 때 데이터 수가 너무 많아서 메로리도 많이 먹고 트레이닝 속도도 느림
2. 실시간으로 데이터를 받으면서 할수도 없음. 해당 time의 전체 데이터가 다 들어올 때까지 학습을 못하기 때문임 -> 온라인러닝 못함
Stochastic Gradient Descent
- 개별의 training set을 기준으로 gradient를 계산함

- 장점
1. 빠르며, 온라인 러닝이 가능함 - 단점
1. 분산이 너무 높음(SGD fluctuation 현상)- 노이즈에 예민함 (개별 데이터를 기준으로 업데이트하기 때문에 노이즈에 약함)
Minibatch Gradient Descent
- 전체 샘플을 미니배치들에 batch size로 나눔. 이때 나누는건 랜덤으로 나누며, 파라미터 업데이트를 할때마다 랜덤으로 다시 나눠야함.
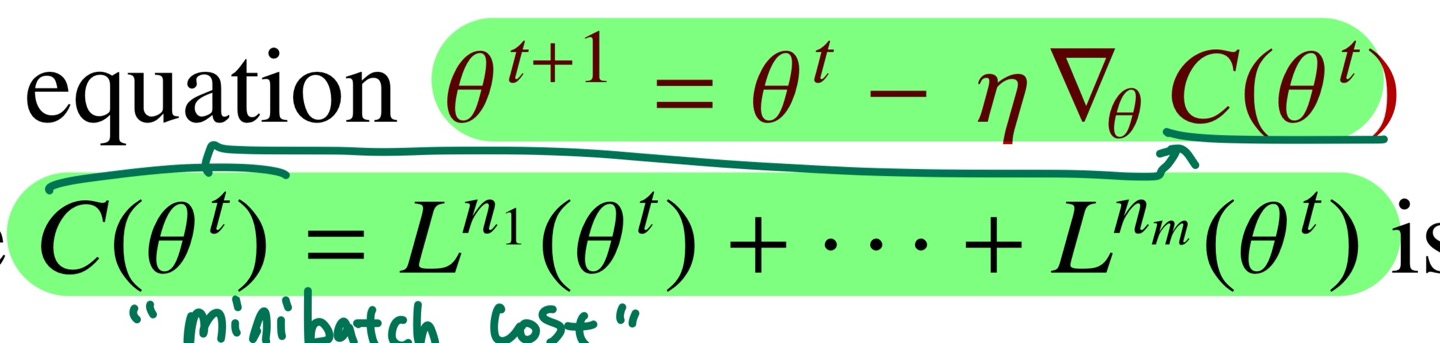
<<Fig. minibatch cost>>
- 장점: 빠르며, 온라인러닝이 가능하고, 분산이 낮다(노이즈에 꽤 강건함)
- 단점 : minibatch size가 hyperparameter이기 때문에 최적의 hyperparameter를 얻기 위한 시도가 필요하다.

Gradient descent method 비교