알고리즘 시간복잡도 1, 2, Big-O 표기법
알고리즘 성능 비교를 위한 실행 환경 - RAM
자료구조와 알고리즘은 코드를 기반으로 컴퓨터에서 동작함. 이때 동작하는 HW, SW 환경과 입력의 크기가 다양함. 고로 실행환경마다 성능이 달라짐. 이러한 상황에서 알고리즘의 성능을 비교하려면 객관적인 모델이 필요함.
->"가상컴퓨터(virtual machine) + 가상 언어(pseudo language) + 가상 코드(pseudo code)"을 기준으로 객관적인 알고리즘 성능을 비교함.
가상 컴퓨터(virtual machine)
가상의 컴퓨터 모델은 초기엔 Turing Machine에서 RAM(Random Access Machine)으로 발전했으며, RAM은 cpu와 memory가 존재하고 기본연산이 가능한 모델임.
- 기본연산 : 단위시간에 수행되는 연산. RAM은 해당 연산을 단위시간에 수행할 수 있다고 봄.
-배정,대입,복사연산 (A=B)
-산술 연산 (+,-,*,/) : 원래의 RAM모델은 반올림, 나머지 등의 연산은 포함하지 않으나, 강의에선 포함함
-비교 연산 (<,<=,>,>=,==,!=)
-논리 연산 (AND, OR, NOT)
-비트 연산 (bit-AND,OR,NOT)
가상 언어(pseudo language) : 가상 컴퓨터가 알아들을 수 있는 형태의 언어. 이는 실제 프로그래밍 언어일 필요가 없음. 다만 다음의 표현들이 가능해야함.
1) 배정, 산술, 비교, 논리, bit-논리 등의 기본 연산
2) 비교가 가능해야함 (if, if else 등)
3) 반복문 (for, while)
4) 함수 (정의, 호출, return)
가상 코드(pseudo code) : 가상 언어로 작성된 코드. 이는 실제 모델이 안니 가상 모델인 RAM에서 실행되며, 내용만 정확히 전달되면 됨.

알고리즘의 성능비교 지표 - 시간복잡도
알고리즘의 성능비교는 시간복잡도가 지표가 된다. 실행시간이 얼마나 걸리는지를 비교하는 것이다. 이때, 시간복잡도는 다음과 같이 정의할 수 있다.
- 모든 경우의 수(모든 입력에 대해 기본연산 횟수)를 더한 후 평균내기
- 이는 입력의 경우의 수가 너무 많아서 현실적으로 불가함
- W.T.C(worstcase time complexity) : 가장 안좋은 입력(가장 기본 연산이 많은 입력)에 대한 기본연산횟수를 측정
- 어떤 입력에 대해서도 이보다 수행시간이 작거나 같다.
알고리즘 분야에서는 일반적으로 시간복잡도를 W.T.C로 정의함.
모든 알고리즘은 W.T.C 시간 복잡도를 측정할 수 있음. 보통 n에 대한 함수가 됨(T(n)). 참고로 위의 사진에서의 W.T.C는 2n-1임. 맨처음 A[0]대입으로 1번, 그리고 남은 n-1개의 정수에 대해 비교 및 대입하여 각 2번씩. 고로 2n-2+1 = 2n-1임. 이때 n은 입력 데이터의 요소 개수이다.
- 시간 복잡도 도출 예시

Big-O 표기법
위의 사진들에서 제시한 알고리즘에 각각 1,2,3인덱스를 붙일 때, arraymax는 T_1(n) = 2n-1, sum1은 T_2(n)=4n+1, sum2는 T_3(n) = n(n+1)*3/2 +1의 값을 갖는다. 입력의 개수 n에따라 어떤 알고리즘의 속도가 더 빠른지를 대입하여 비교할 수 있다.
자, 최고차항의 관점에서 T_3가 T_2, T_1보다 수행시간 증가율이 더 크다. 최고차항의 차수가 더 크기 때문이다. 최고차항의 차수는 수행시간의 증가율을 결정한다. T_1, T_2의 최고차항의 계수는 다르지만, 수행시간 증가율의 관점에서 보면 최고차항의 차수가 같으므로, 수행시간이 같다고 본다.
결국 알고리즘의 수행시간을 결정하는 가장 중요한 요소는 수행시간의 증가율이고, 증가율은 곧 T(n) 함수에서 최고차항의 차수이다. 고로, 최고차항만 취하여 수행시간을 표시한다. 이것이 Big-O 표기법의 핵심개념이다.
- Big-O 표기법 : 알고리즘의 수행시간을 함수값을 결정하는 최고차항만으로 간단하게 표기하는 방법
- 방법- T(n)의 최고차항만 남긴다
- 최고차항의 계수(상수)를 날린다
- "O(최고차항)" 의 형태로 표기한다.
ex) T_1(n) = O(n), T_2(n) = O(n), T_3(n) = O(n^2)
예시에서 보면 Big-O관점에서 보면 T_3은 T_2, T_1보다 더 느린 알고리즘임을 알 수 있다.
Big-O 집합으로 이해하기
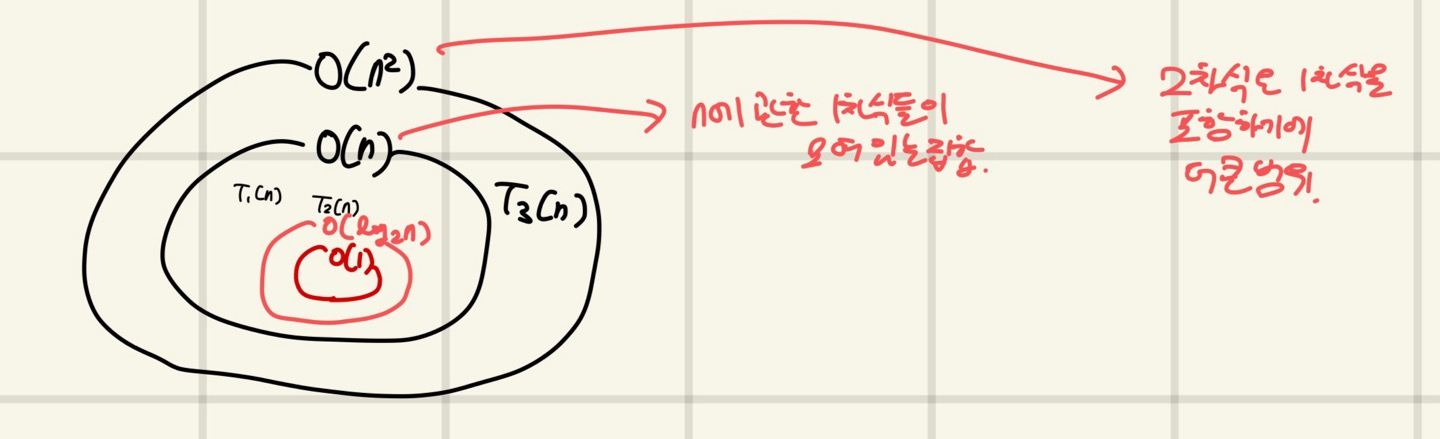
이를 보면 n의 차수가 클수록 더 큰 범위의 집합으로 생각할 수 있음을 알 수 있다.
Big-O 예시 적용
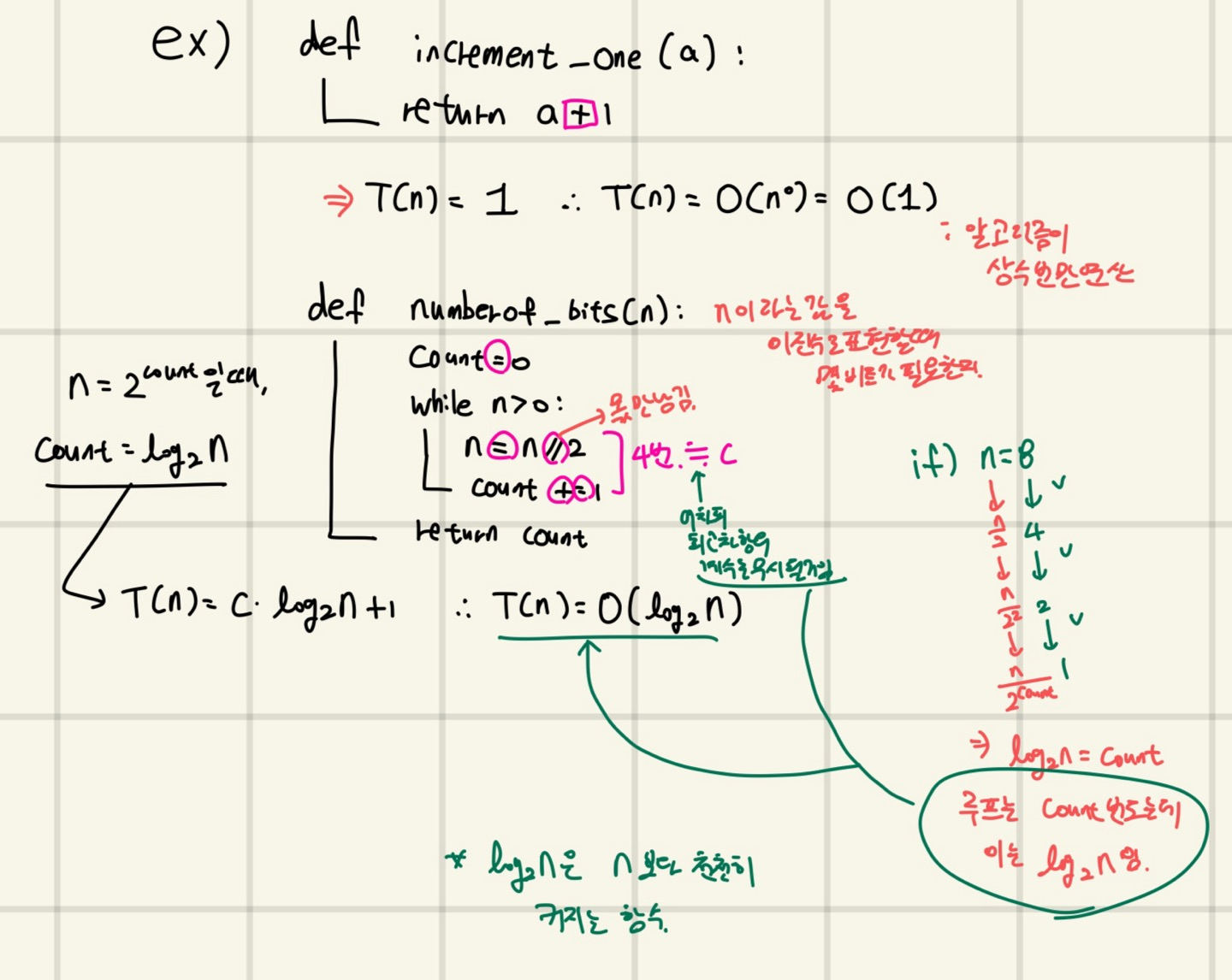
위 사진처럼 함수의 Big-O표시로 알고리즘의 시간복잡도를 구할 수 있고, 이 값으로 알고리즘 성능을 비교할 수 있다.
