#참고
기계 번역 = Machine Translation = MT
인간의 번역 = Human Translation = HT
기존에 사용되던 metric (논문 외)
1. Perplexity (PPL)
: a metric that quantifies how uncertain a model is about the predictions it makes
→ 선택 가능한 경우의 수를 의미 (분기 계수, Branching Factor)
- 특정 시점에서 평균적으로 몇 개에 선택지를 갖고 고민했는가?
- 더 낮은 PPL을 갖는 모델이 같은 테스트 데이터에 대해 더 일치할 것임
PPL의 유의점
1) PPL 값 낮다는 것은 오직 test 데이터와의 일치율이 높은 것만을 의미할 뿐
- 그게 사람이 느끼기에 진짜 좋은건 아닐 수도
2) PPL 수치는 테스트 데이터의 좌우됨
- 테스트 데이터가 달라지면 PPL 달라짐
- test 데이터 자체도 양이 충분해야 함
2. Cross Entropy
: a measure of the difference between two probability distributions for a given random variable or set of events → 실제 데이터와 모델이 계산한 데이터의 확률 분포의 차이
0. Abstract
기계 번역(Machine Translation, MT)에 대한 사람의 평가는 포괄적이지만 비용이 많이 들고 시간이 오래 걸린다(수 주~ 수 개월). 따라서 우리는 빠르고 저렴하며 언어에 구애받지 않는 자동화된 기계 번역 평가 방법을 제안한다.
BiLingual Evaluation Understudy → BLEU
1. Introduction
선행 연구
1994, 1999 - MT에 대한 인간 평가는 변역의 정확도, 충실도, 유창성 등 여러 측면 고려함
2001 - MT 평가 기법에 대한 문헌 제공됨
1999 - MT를 인간이 평가하는 방식은 비싸다
기계 번역 성능 확인 피드백 많지만 인간 평가는 한계(병목 현상) → 그래서 BLEU 제안
Main Idea
: 번역된 문장이 인간이 한 전문적 번역에 가까울수록 성능이 좋은 것
그러기 위해서는?
1. 수치화된 ‘번역 근접성’ 지표 확보
2. 좋은 품질의 인간 번역 말뭉치 확보
문장의 번역은 정답이 없고 여러 번역이 존재할 수 있다. 인간은 좋은 번역, 나쁜 번역 구분 가능하지만 기계는 그렇지 않음. 다만 번역 문장과 레퍼런스 문장 간의 일치하는 단어나 구의 개수로 좋은 번역인지 판단 가능
2. The Baseline BLEU Metric
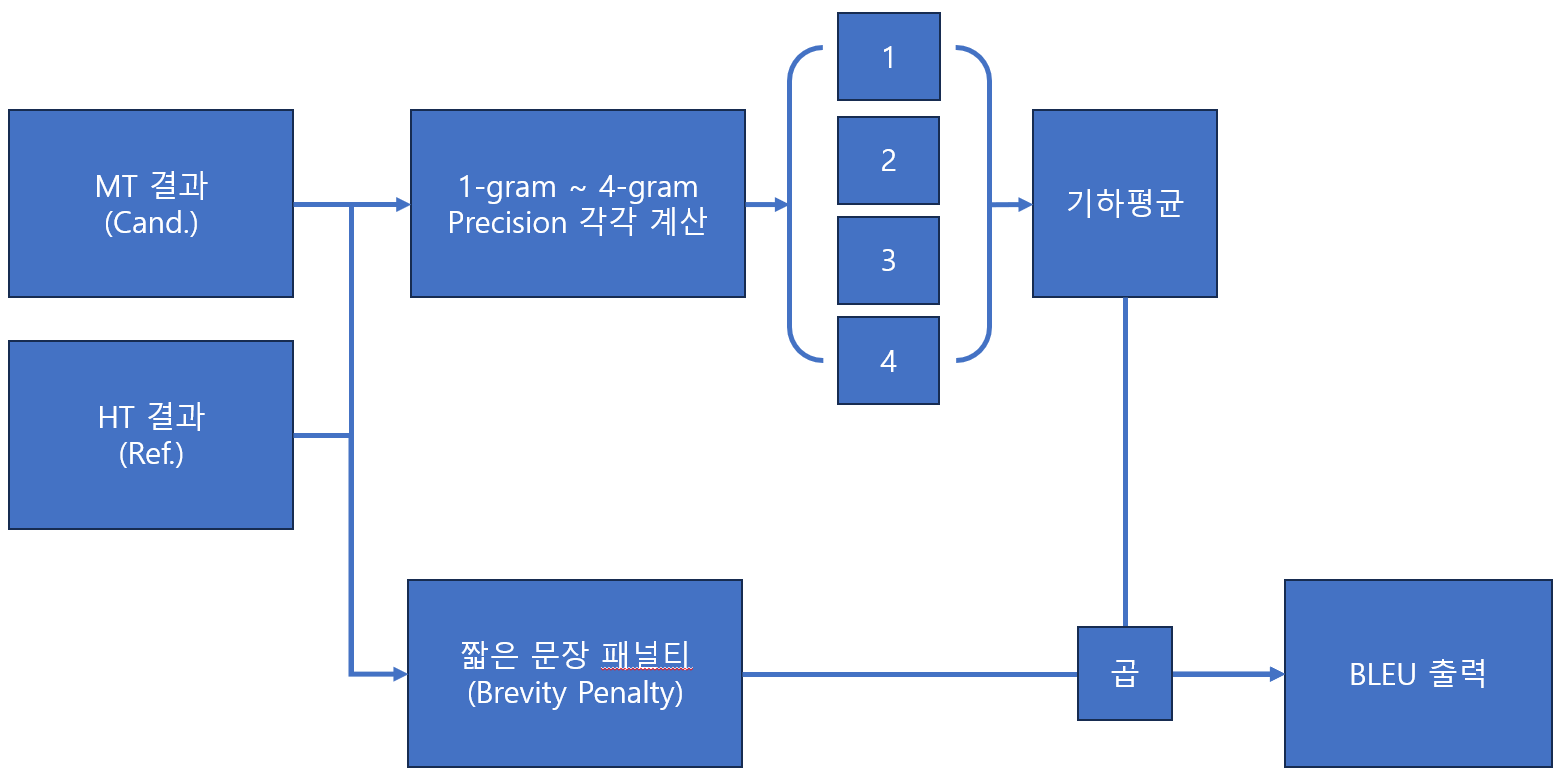
1) Modified n-gram precision의 등장 배경
Example
Candidate 1: the the the the the the the.
Candidate 2: The cat is on the mat.
Reference: There is a cat on the mat.
| n-gram | 1-gram | 2-gram | 3-gram | 4-gram |
|---|---|---|---|---|
| Cand. 1 | 7/7 | 0/6 | 0/5 | 0/4 |
| Cand 2 | 5/7 | 2/6 | 1/5 | 0/4 |
Modified n-gram: Reference에서 한번 나온 단어는 더 이상 count하지 않음
→ 반복되는 단어에 대한 penalty 부여 가능
| Modified n-gram | 1-gram | 2-gram | 3-gram | 4-gram |
|---|---|---|---|---|
| Cand. 1 | 7/7 → 2/7 | 0/6 | 0/5 | 0/4 |
| Cand 2 | 5/7 → 5/7 | 2/6 | 1/5 | 0/4 |
2) Precision을 기하평균 하는 이유
- n-gram에서 n 값이 증가할수록 정밀도가 지수적으로 떨어지는데, 일반적인 가중 산술 평균은 이를 반영하지 못함
- 로그의 가중 평균을 사용하는 기하 평균 방식을 사용(Geometric mean)
- 최대의 n-gram 값은 4가 적절함(실험적으로 얻은 결과)
3) Brevity Penalty의 등장 배경
→ Reference에 있는 모든 단어를 다 사용한다면? or 문장이 너무 짧다면?
Candidate 1: I always invariably perpetually do.
Candidate 2: I always.
Reference 1: I always do.
Reference 2: I invariably do.
Reference 3: I perpetually do.
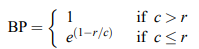
| 1-gram | 2-gram | 3-gram | BP | |
|---|---|---|---|---|
| Cand. 1 | 5/5 | 0/6 | 0/3 | 1 (c>r) |
| Cand 2 | 2/2 | 1/1 | - | 0.x (c<r) |
사실 reference 보다 긴 candidate는 이미 완전히 일치 하지 않는 이상 modified n-gram precision 의해 패널티를 받고 있음 → 그래서 짧은 문장에 패널티를 주는 BP 도입
최종적인 BLEU 계산
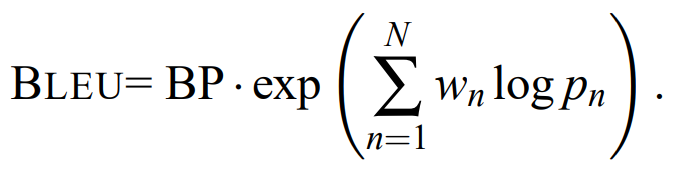
-
0≤ BLEU ≤ 1
→ 1에 가까울수록 더 좋음 -
레퍼런스와 동일하지 않는 이상 1일 수는 없음
3. The BLEU Evaluation
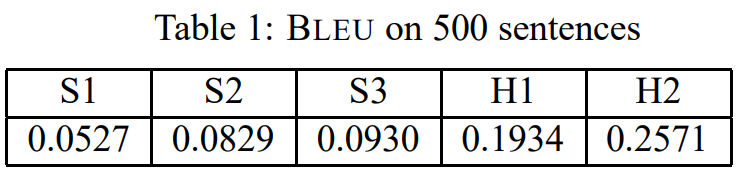
- S1 / S2 / S3 : 상업적인 시스템에 의한 기계 번역
- H1 : 중국어, 영어 전문성이 부족한 인간 번역
- H2 : 영어 전문성이 있는 인간 번역
- S1<S2<S3<<<H1<H2
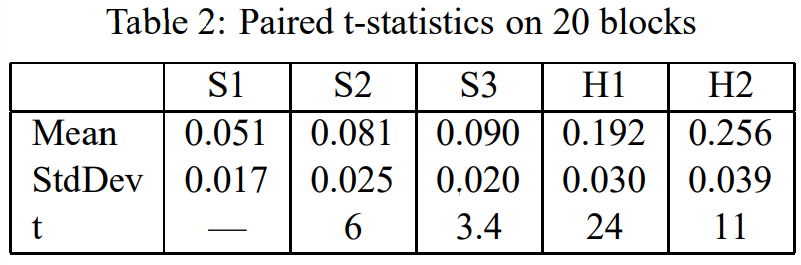
Table 1을 보고 드는 의문
- BLEU 지표 차이를 신뢰할 수 있나?
- BLEU 지표의 분산은 얼마인가?
- 500개 문장이 달라진다면 여전히 S3가 S2보다 나을까?
→ 그래서 25개로 구성된 20개 블록으로 나누고 paired t-test 진행
- Deviation(표준편차)이 크지 않음
4. The Human Evaluation
- Evaluated by rating from 1 (very bad) ~ 5 (very good)
- Figure 3 : Monolingual group - 10 native English speakers
- Figure 4 : Bilingual group - 10 native Chinese Speakers (lived in US for several years)
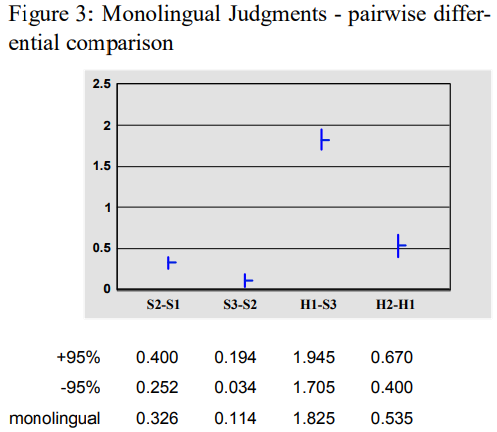
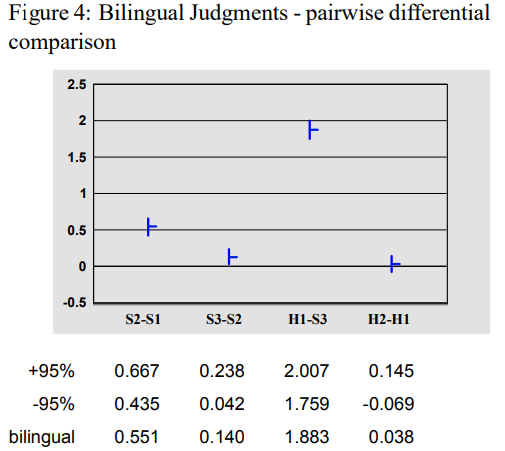
- H1-S3의 수치가 큼 → HT를 높게 평가함
5. BLEU vs The Human Evaluation
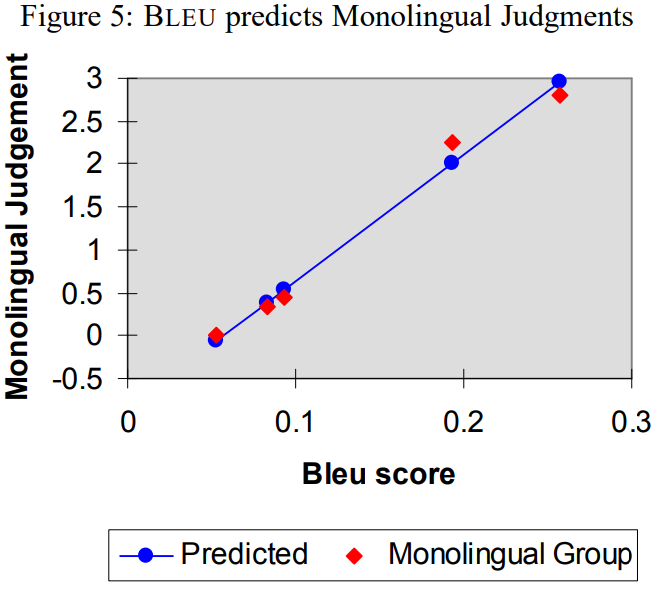
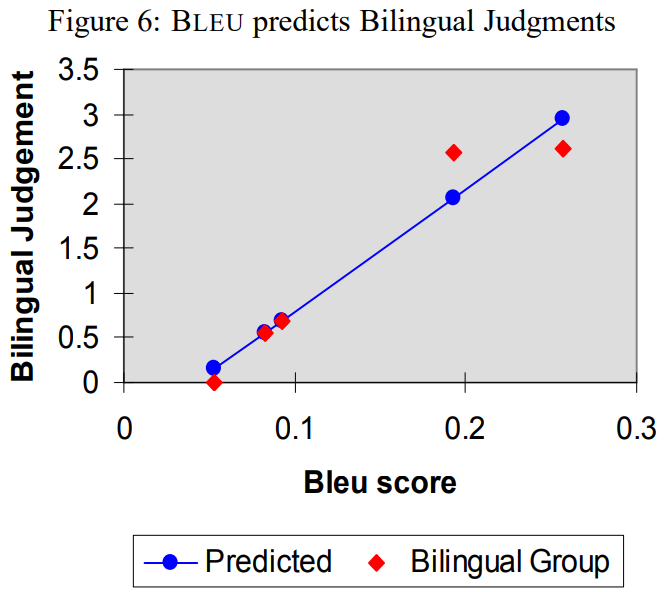
- 각 점이 왼쪽에서 오른쪽으로 갈수록 S1, S2, S3, H1, H2 의미
- Monolingual 상관관계 계수: 0.99
- Bilingual 상관관계 계수: 0.96
- 특히 BLEU가 인접한 S2, S3 구별해낸게 흥미로움
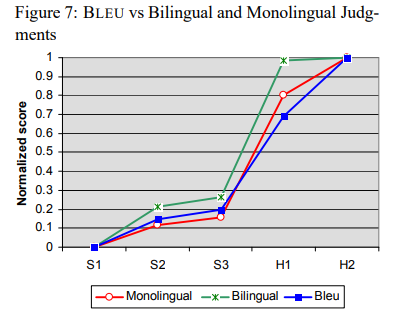
- BLEU와 monolingual은 높은 상관 관계
- MT와 HT에는 수치적으로 차이 존재
- Bilingual은 H1, H2 큰 차이 두지 않음
6. Conclusion
- 텍스트 말뭉치에서 개별적인 문장 판단의 오류를 평균화함으로써 인간이 하는 판간과 높은 상관 관계를 수치화함
- MT R&D 사이클의 가속화를 기대
- 텍스트 summarization 평가나 비슷한 NLG task에서 사용을 기대
