
Chapter 5. Web Servers
(해석 또는 이해가 잘못된 부분이 있다면 댓글로 편하게 알려주세요.)
❤️ 원문 번역 ❤️
Step 2: Receiving Request Messages
As the data arrives on connections, the web server reads out the data from the network connection and parses out the pieces of the request message (Figure 5-5).
- 데이터가 연결에 도착하면 웹 서버는 네트워크 연결에서 데이터를 읽어 요청 메시지의 조각을 파싱합니다. (Figure 5-5)
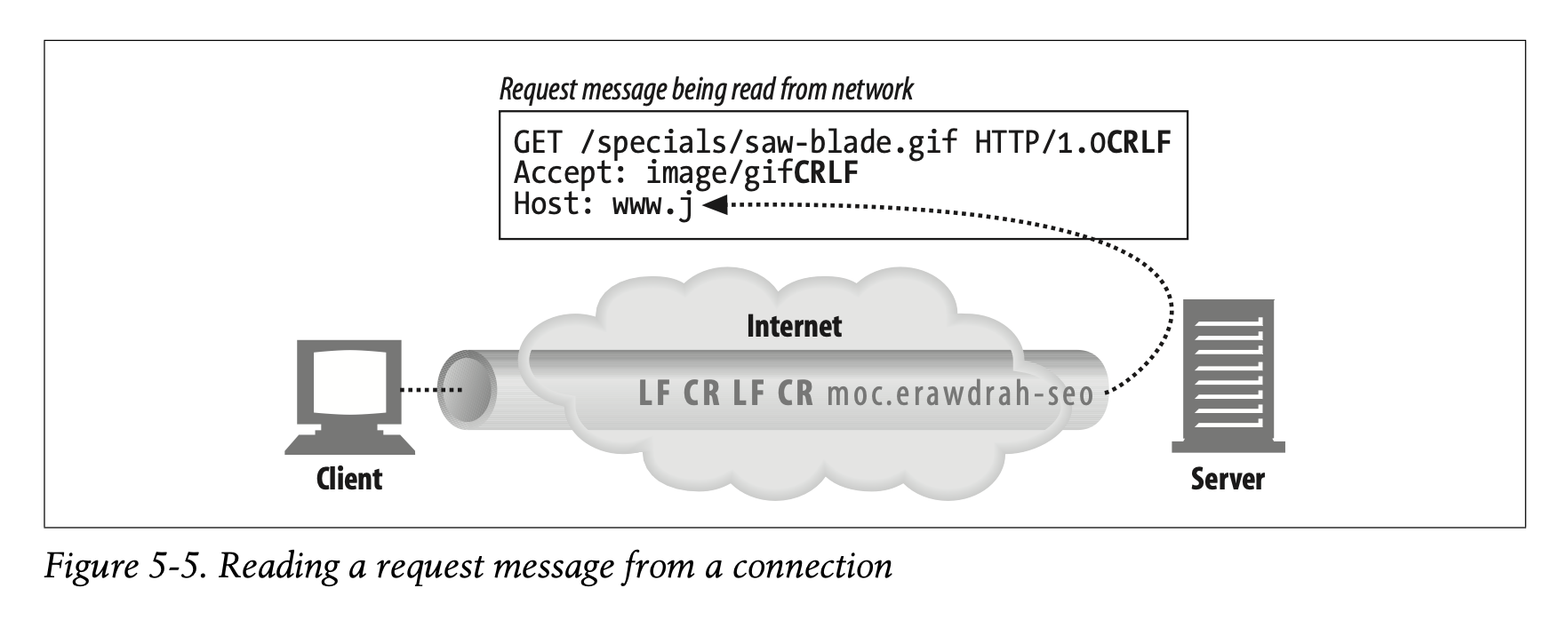
When parsing the request message, the web server:
- Parses the request line looking for the request method, the specified resource identifier (URI), and the version number,* each separated by a single space, and ending with a carriage-return line-feed (CRLF) sequence†
- Reads the message headers, each ending in CRLF
- Detects the end-of-headers blank line, ending in CRLF (if present)
- Reads the request body, if any (length specified by the Content-Length header)
- 요청 메시지를 파싱할 때 웹 서버는 다음과 같은 역할을 수행합니다.
- 요청 메소드, URI, 버전 번호, 구분된 요청 라인을 파싱합니다. 각각의 요소들은 공백에 의해 구분되고 CRLF 시퀀스로 끝납니다.
- CRLF로 끝나는 메시지 헤더를 읽습니다.
- CRLF로 끝나는 헤더 끝 공백 라인을 탐지합니다.
- (Content-Length 헤더로 지정되는 길이의) 요청 본문을 읽습니다.
When parsing request messages, web servers receive input data erratically from the network. The network connection can stall at any point. The web server needs to read data from the network and temporarily store the partial message data in memory until it receives enough data to parse it and make sense of it.
-
요청 메시지를 파싱할 때 웹 서버는 네트워크로부터 입력 데이터를 비정상적으로 받습니다.
-
네트워크 연결은 모든 지점에서 정지할 수 있습니다.
-
웹 서버는 네트워크로부터 데이터를 읽고, 파싱하고 이해할 수 있을 정도로 충분한 데이터를 받을 때까지 일부 메시지 데이터를 메모리에 임시로 저장해야 합니다.
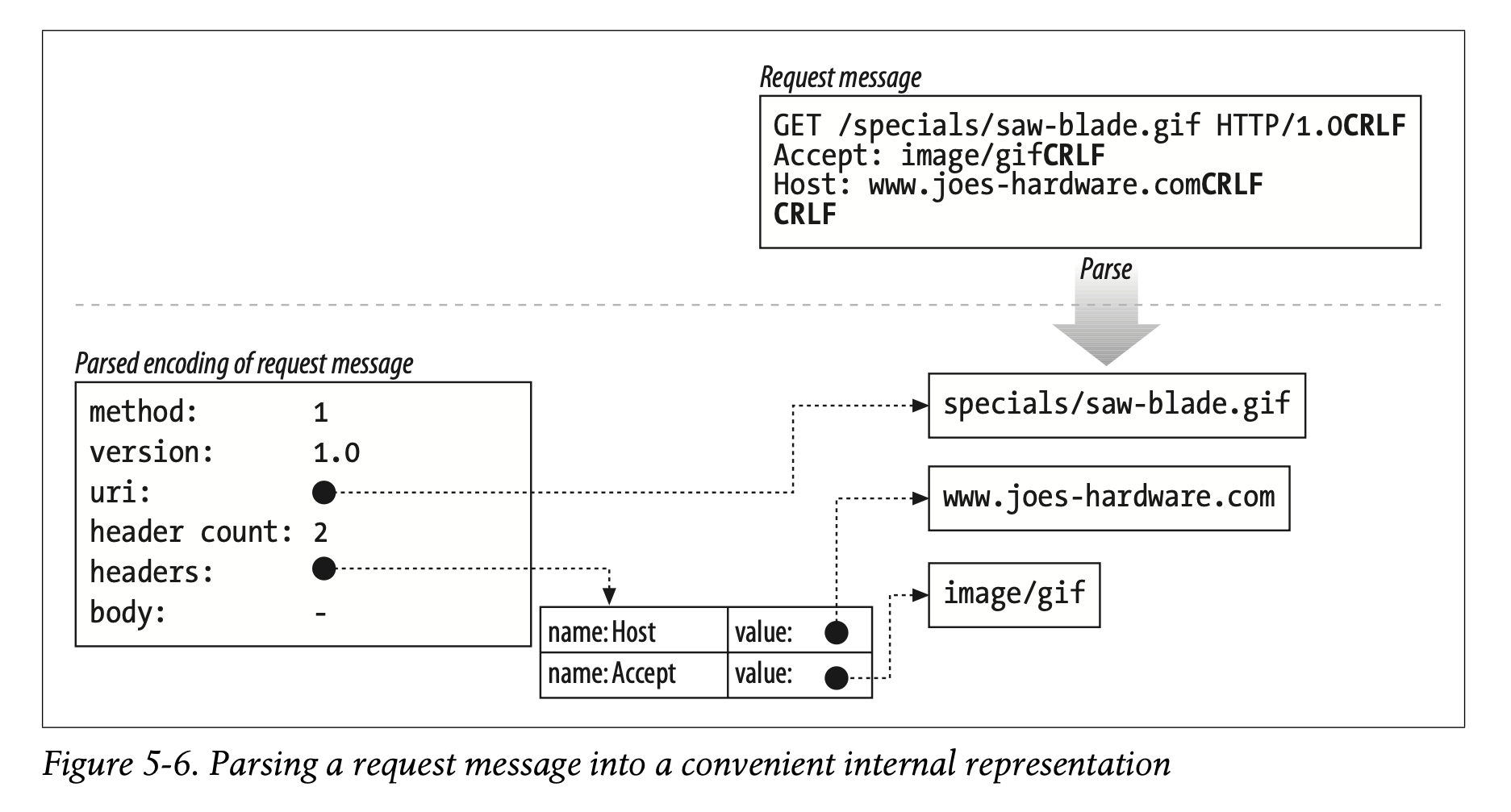
Internal Representations of Messages
Some web servers also store the request messages in internal data structures that make the message easy to manipulate. For example, the data structure might contain pointers and lengths of each piece of the request message, and the headers might be stored in a fast lookup table so the specific values of particular headers can be accessed quickly (Figure 5-6).
-
일부 웹 서버는 요청 메시지를 쉽게 조작할 수 있는 내부의 자료구조에 그것을 저장하기도 합니다.
-
예를 들어 자료구조는 포인터와 요청 메시지 조각의 길이를 포함할 수 있습니다. 또한 헤더가 빠른 검색 테이블에 저장되어 헤더의 특정값을 빠르게 접근할 수 있게 합니다. (Figure 5-6)
Connection Input/Output Processing Architectures
High-performance web servers support thousands of simultaneous connections. These connections let the web server communicate with clients around the world, each with one or more connections open to the server. Some of these connections may be sending requests rapidly to the web server, while other connections trickle requests slowly or infrequently, and still others are idle, waiting quietly for some future activity.
-
고성능의 웹 서버는 수천 개의 동시 연결을 지원합니다.
-
이 연결들은 웹 서버가 전세계의 클라이언트와 하나 이상의 연결을 통해 통신할 수 있게 합니다.
-
일부 연결은 웹 서버로 요청을 빠르게 전송하고 있을지도 모릅니다. 한편 다른 연결은 요청을 천천히 혹은 빈번하지 않게 전송합니다. 그리고 또다른 연결은 여전히 비어있는 상태로 향후의 활동을 조용히 대기하고 있을지도 모릅니다.
Web servers constantly watch for new web requests, because requests can arrive at any time. Different web server architectures service requests in different ways, as Figure 5-7 illustrates:
-
웹 서버는 즉시 새로운 웹 요청을 탐색할 수 있습니다. 요청은 언제든 도착할 수 있기 때문입니다.
-
웹 서버 아키텍처들은 Figure 5-7에 나타나는 것처럼 서로 다른 방식으로 요청을 서비스합니다.
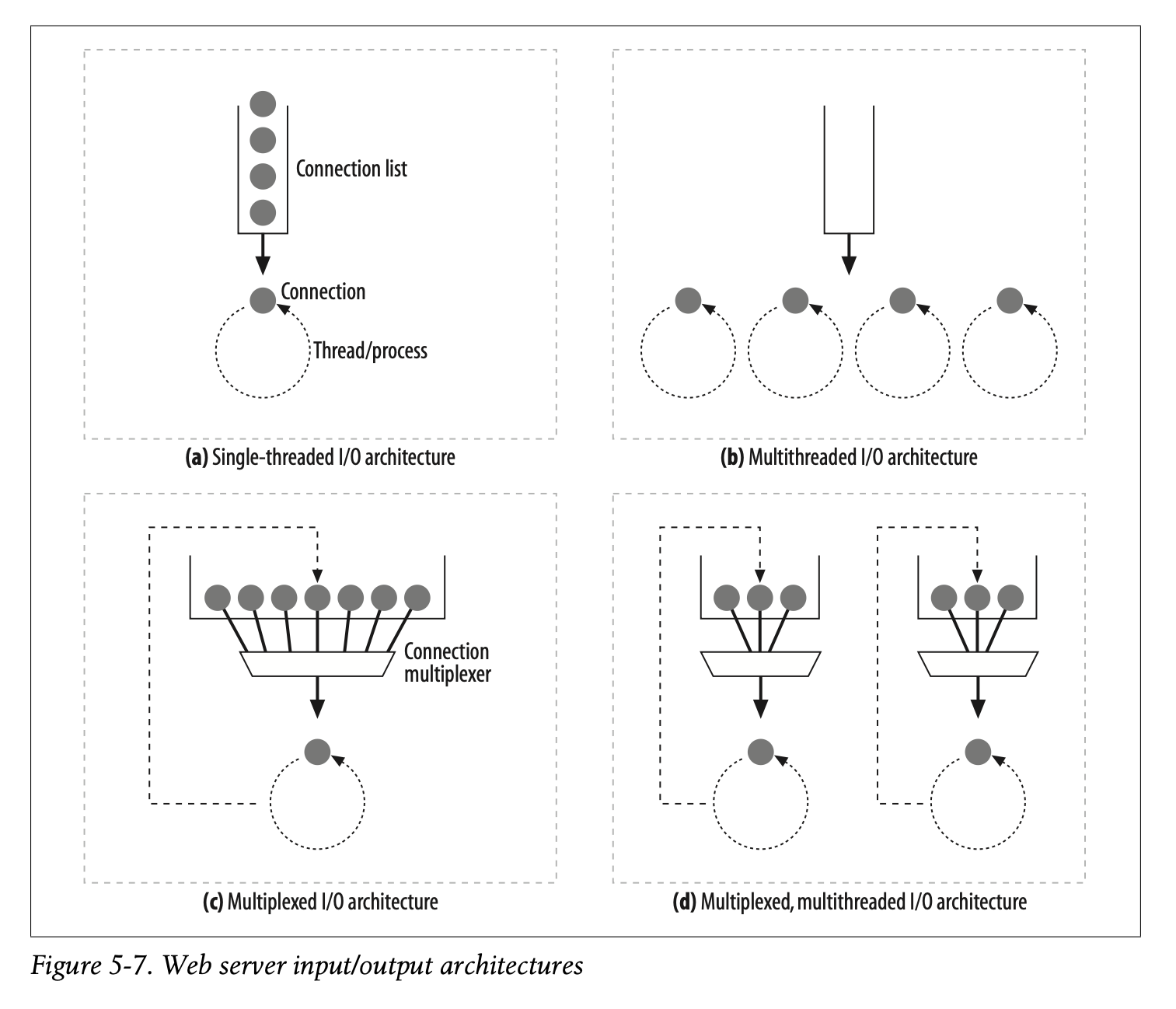
Single-threaded web servers (Figure 5-7a)
Single-threaded web servers process one request at a time until completion. When the transaction is complete, the next connection is processed. This architecture is simple to implement, but during processing, all the other connections are ignored. This creates serious performance problems and is appropriate only for low-load servers and diagnostic tools like type-o-serve.
싱글쓰레드 웹 서버 (Figure 5-7a)
-
싱글쓰레드 웹 서버는 트랜잭션이 완료될 때까지 한 번에 하나의 요청을 처리합니다.
-
그리고 트랜잭션이 완료되었을 때 다음 연결이 처리됩니다.
-
구현은 쉽지만 처리 시간 동안 모든 다른 연결이 무시됩니다.
-
이것은 심각한 성능 문제를 야기합니다. 따라서 비교적 부하가 덜 가해지는 서버와 type-o-serve와 같은 진단 툴에 대해서만 적합합니다.
Multiprocess and multithreaded web servers (Figure 5-7b)
Multiprocess and multithreaded web servers dedicate multiple processes or higher-efficiency threads to process requests simultaneously.* The threads/ processes may be created on demand or in advance.† Some servers dedicate a thread/process for every connection, but when a server processes hundreds, thousands, or even tens of thousands of simultaneous connections, the resulting number of processes or threads may consume too much memory or system resources. Thus, many multithreaded web servers put a limit on the maximum number of threads/processes.
멀티프로세스와 멀티쓰레드 웹 서버 (Figure 5-7b)
-
멀티프로세스와 멀티쓰레드 웹 서버는 요청을 동시에 처리하기 위해 여러 개의 프로세스나 고효율의 쓰레드를 사용합니다.
-
쓰레드와 프로세스는 필요에 따라 혹은 사전에 생성될 수 있습니다.
-
일부 서버는 쓰레드와 프로세스를 모든 연결에 사용합니다. 하지만 서버가 수백, 수천, 혹은 수만 개의 동시 연결을 처리한다면, 결과적으로 발생하는 프로세스 혹은 쓰레드의 수가 메모리나 시스템 리소스를 과도하게 소비할 수 있습니다.
-
따라서 많은 멀티쓰레드 웹 서버는 쓰레드와 프로세스 개수의 상한선을 지정합니다.
Multiplexed I/O servers (Figure 5-7c)
To support large numbers of connections, many web servers adopt multiplexed architectures. In a multiplexed architecture, all the connections are simultaneously watched for activity. When a connection changes state (e.g., when data becomes available or an error condition occurs), a small amount of processing is performed on the connection; when that processing is complete, the connection is returned to the open connection list for the next change in state. Work is done on a connection only when there is something to be done; threads and processes are not tied up waiting on idle connections.
멀티플렉스 I/O 서버 (Figure 5-7c)
-
다수의 연결을 지원하기 위해 많은 웹 서버가 멀티플렉스 아키텍처를 채택합니다.
-
멀티플렉스 아키텍처에서는 모든 연결이 동시에 활동을 탐색합니다.
-
연결의 상태가 변화할 때(데이터가 사용 가능해지거나 오류가 발생했을 때) 연결에 대해 약간의 처리가 수행됩니다.
-
처리가 완료되면 연결은 다음의 상태 변화를 위해 개방된 연결 목록에 반환됩니다.
-
작업은 오직 무언가 수행해야 할 것이 있을 때에만 연결 내에서 수행됩니다. 쓰레드와 프로세스는 유휴 연결을 기다리는 동안 묶여있지 않습니다.
Multiplexed multithreaded web servers (Figure 5-7d)
Some systems combine multithreading and multiplexing to take advantage of multiple CPUs in the computer platform. Multiple threads (often one per physical processor) each watch the open connections (or a subset of the open connec- tions) and perform a small amount of work on each connection.
멀티플렉스 멀티쓰레드 웹 서버 (Figure 5-7d)
-
일부 시스템은 멀티쓰레딩과 멀티플렉싱을 결합하여 컴퓨터 플랫폼에서 여러 CPU를 사용하는 이점을 취합니다.
-
여러 개의 쓰레드는(물리적인 프로세서당 종종 한 개의 쓰레드를 가진다) 각각 개방된 연결을 탐색하고 각각의 연결에서 소량의 작업을 수행합니다.
🧡 요약 정리 🧡
What Web Servers Do
Step 1: Accepting Client Connections
https://velog.io/@dvlp-sy/TIL-HTTP-The-Definitive-Guide-p113-p116
Step 2: Receiving Request Messages
- 서버가 요청 메시지를 파싱하여 편리한 내부의 식으로 표현하는 것
- 파싱된 데이터 : method, version, uri, headers, body 등
Web Server Processing Architecture
- Single-threaded Web Server : 한 번에 하나의 연결 처리, 트랜잭션이 완료되면 다음 연결 처리
- Multiprocess and Multithreaded Web Server : 여러 개의 프로세스와 쓰레드를 사용하여 여러 개의 연결을 한 번에 처리 (너무 많으면 리소스 과잉소비)
- Multiplexd I/O Server : 연결의 상태가 변화할 때 한 번에 하나의 연결 처리
- Multiplexed Multithreaded Web Server : 여러 개의 프로세스와 쓰레드를 사용하여 상태가 변화한 여러 개의 연결을 한 번에 처리
(비유가 조금 지저분하긴 하지만 이렇게 이해하면 편하다)
- Single-threaded Web Server : 화장실이 한 칸뿐이라 한 줄로 서서 기다리는 것
- Multiprocess and Multithreaded Web Server : 여러 칸의 화장실을 동시에 여러 명이 사용할 수 있는 것
- Multiplexd I/O Server : 한 칸뿐인 화장실을 신호가 온 사람이 먼저 사용하는 것
- Multiplexed Multithreaded Web Server : 여러 칸의 화장실을 신호가 온 여러 명의 사람들이 동시에 사용하는 것
💛 감상 💛
-
이전까지는 몰랐는데 책을 읽으면 읽을수록 Parallel, Simultaneous, Process, Thread, I/O와 같은 용어들이 자주 등장하고 있습니다. 운영체제를 공부하면서 자주 듣던 용어들인데 이것을 네트워크와 연관지어 생각하려니 조금 어렵습니다. 보통은 운영체제 따로, 네트워크 따로, 서버 따로 배우니까 더 그런 것 같습니다. 사실 서버와 운영체제가 굉장히 가까운 관계에 놓여있음에도 학교에서는 전혀 별개인 것처럼 배우니 그동안 배운 내용들도 전혀 연결이 되지 않습니다. 그동안 너무 학점을 잘 받기 위한 공부만 해왔던 것은 아닐까 반성도 됩니다.
-
그림이 많아서 두 페이지보다 조금 많이 읽었습니다. 앞으로 더 열심히 올려볼게요!
