
Chapter 7. Caching
(해석 또는 이해가 잘못된 부분이 있다면 댓글로 편하게 알려주세요.)
✏️ 원문 번역
Cache Processing Steps
Modern commercial proxy caches are quite complicated. They are built to be very high-performance and to support advanced features of HTTP and other technologies. But, despite some subtle details, the basic workings of a web cache are mostly simple. A basic cache-processing sequence for an HTTP GET message consists of seven steps (illustrated in Figure7-11):
- Receiving—Cache reads the arriving request message from the network.
- Parsing—Cache parses the message, extracting the URL and headers.
- Lookup—Cache checks if a local copy is available and, if not, fetches a copy (and stores it locally).
- Freshness check—Cache checks if cached copy is fresh enough and, if not, asks server for any updates.
- Response creation—Cache makes a response message with the new headers and cached body.
- Sending—Cache sends the response back to the client over the network.
- Logging—Optionally, cache creates a log file entry describing the transaction.
-
최신 상용 프록시 캐시는 상당히 복잡합니다.
-
고성능으로 HTTP의 진보된 기술과 그 밖의 여러 기술들을 지원하도록 구축되어 있습니다.
-
몇 가지 자잘한 세부사항들이 있는 한편 웹 캐시의 기본적인 작업은 대체로 간단합니다.
-
HTTP GET 메시지에 대한 캐시 프로세싱 과정은 다음의 7단계로 구성되어 있습니다. (Figure 7-11)
- Receiving : Cache가 네트워크로부터 도착한 요청 메시지를 읽는다
- Parsing : Cache가 URL과 헤더를 추출하고 메시지를 파싱한다
- Lookup : Cache가 로컬 사본이 존재하는지 확인하고, 없으면 사본을 불러와 로컬에 저장한다
- Freshness Check : 캐싱된 사본이 최신 사본인지 확인하고, 그렇지 않으면 서버에 업데이트를 요청한다
- Response Creation : 새로운 헤더와 본문을 포함하여 응답 메시지를 생성한다
- Sending : 네트워크를 통해 클라이언트에게 응답을 전송한다
- Logging : (Optional) 트랜잭션에 대한 로그 파일을 생성한다

Step 1: Receiving
In Step 1, the cache detects activity on a network connection and reads the incoming data. High performance caches read data simultaneously from multiple incoming connections and begin processing the transaction before the entire message has arrived.
-
Step 1에서 캐시는 네트워크 연결상의 활동을 감지한 후 수신되는 데이터를 읽습니다.
-
고성능의 캐시는 동시에 여러 개의 수신 데이터를 읽을 수 있으며 전체 메시지가 도착하기 전에 트랜잭션의 프로세싱을 미리 시작할 수 있습니다.
Step 2: Parsing
Next, the cache parses the request message into pieces and places the header parts in easy-to-manipulate data structures. This makes it easier for the caching software to process the header fields and fiddle with them.*
-
캐시는 요청 메시지를 파싱하여 헤더 부분을 조작하기 쉬운 형태의 데이터 구조로 변환합니다.
-
캐싱 소프트웨어가 헤더 필드를 더 쉽게 처리하고 조작할 수 있게 만드는 것입니다.
Step 3: Lookup
In Step 3, the cache takes the URL and checks for a local copy. The local copy might be stored in memory, on a local disk, or even in another nearby computer. Professional-grade caches use fast algorithms to determine whether an object is available in the local cache. If the document is not available locally, it can be fetched from the origin server or a parent proxy, or return a failure, based on the situation and configuration.
-
Step 3에서는 캐시가 URL을 취하여 로컬 사본이 있는지 확인합니다.
-
로컬 사본은 메모리나 디스크, 혹은 근처의 다른 컴퓨터에 저장되어 있을 수도 있습니다.
-
전문적인 수준의 캐시는 로컬 캐시 오브젝트 사용 가능성을 판단할 때 속도가 빠른 알고리즘을 사용합니다.
-
만약 로컬 사본이 없으면 Origin Server나 상위 계층 프록시로부터 가져오거나 Fail을 반환해야 합니다. 이는 상황과 프록시 구성에 따라 다릅니다.
The cached object contains the server response body and the original server response headers, so the correct server headers can be returned during a cache hit. The cached object also includes some metadata, used for bookkeeping how long the object has been sitting in the cache, how many times it was used, etc.*
-
캐싱된 오브젝트는 서버의 응답 본문과 Origin Server의 응답 헤더를 포함하고 있습니다.
-
따라서 Cache Hit가 발생하면 올바른 서버 헤더를 반환할 수 있습니다.
-
캐싱된 오브젝트는 다른 메타데이터도 포함하고 있습니다.
-
메타데이터는 오브젝트가 캐시에 보존된 기간, 접근 빈도 등을 저장하기 위해 사용됩니다.
Step 4: Freshness Check
HTTP lets caches keep copies of server documents for a period of time. During this time, the document is considered “fresh” and the cache can serve the document without contacting the server. But once the cached copy has sat around for too long, past the document’s freshness limit, the object is considered “stale,” and the cache needs to revalidate with the server to check for any document changes before serving it. Complicating things further are any request headers that a client sends to a cache, which themselves can force the cache to either revalidate or avoid validation altogether.
-
HTTP는 캐시가 일정 기간 동안 서버 문서의 사본을 보유할 수 있게 합니다.
-
이 기간 동안 문서는 "fresh" 상태로 간주되며 캐시를 서버와 연결하지 않고도 문서를 전달할 수 있습니다.
-
하지만 캐싱된 사본이 freshness 제한보다도 더 오랜 시간 보관되어 있다면 해당 오브젝트는 "stale" 상태로 간주됩니다.
-
캐시는 문서를 전달하기 전 서버로부터 수정 여부를 확인하기 위해 재검증을 수행해야 합니다.
-
클라이언트가 캐시에 전송한 임의의 요청 헤더는 상황을 더 복잡하게 만듭니다.
-
요청 헤더가 캐시에게 재검증을 수행하거나 수행하지 않도록 강제할 수도 있습니다.
HTTP has a set of very complicated rules for freshness checking, made worse by the large number of configuration options cache products support and by the need to interoperate with non-HTTP freshness standards. We’ll devote most of the rest of this chapter to explaining freshness calculations.
-
HTTP는 Freshness Checking에 대한 아주 복잡한 규칙셋을 가지고 있습니다.
-
캐시가 지원하는 구성 옵션 자체도 너무 많고 non-HTTP Freshness 표준과도 상호운용이 가능해야 하기 때문입니다.
-
이 챕터의 나머지 부분에서는 대부분 Freshness 연산에 대해 설명하는 데 긴 시간을 할애할 것입니다.
Step 5: Response Creation
Because we want the cached response to look like it came from the origin server, the cache uses the cached server response headers as the starting point for the response headers. These base headers are then modified and augmented by the cache.
-
사용자는 캐싱된 응답이 마치 원본 서버에서 온 것처럼 보이기를 원합니다.
-
따라서 캐시는 캐싱된 서버가 가지고 있는 응답 헤더를 실제 응답 헤더의 시작점에 사용합니다.
-
이러한 Base Header들은 캐시에 의해 수정 및 보강됩니다.
The cache is responsible for adapting the headers to match the client. For example, the server may return an HTTP/1.0 response (or even an HTTP/0.9 response), while the client expects an HTTP/1.1 response, in which case the cache must translate the headers accordingly. Caches also insert cache freshness information (Cache-Control, Age, and Expires headers) and often include a Via header to note that a proxy cache served the request.
-
캐시는 클라이언트에게 적합한 헤더를 선택하는 작업을 수행합니다.
-
예를 들어 서버가 HTTP/1.0 응답(혹은 HTTP/0.9 응답)을 반환하고, 클라이언트는 HTTP/1.1 응답을 기대하고 있다고 가정합니다.
-
이 상황에서 캐시는 헤더를 적합하게 변환해주어야 하며, Cache의 Freshness 정보(Cache-Control, Age, Expires 헤더)를 삽입해주어야 합니다.
-
종종 Via 헤더를 포함해서 프록시 캐시가 요청을 전송함을 나타내는 경우도 있습니다.
Note that the cache should not adjust the Date header. The Date header represents the date of the object when it was originally generated at the origin server.
-
단, 캐시가 Date 헤더를 조작하지 않는다는 점에 유의합니다.
-
Date 헤더는 Origin Server에서 오브젝트가 생성된 시점을 나타냅니다.
Step 6: Sending
Once the response headers are ready, the cache sends the response back to the client. Like all proxy servers, a proxy cache needs to manage the connection with the client. High-performance caches work hard to send the data efficiently, often avoiding copying the document content between the local storage and the network I/O
buffers.
-
응답 헤더가 준비되었다면 캐시는 클라이언트에게 응답을 반환합니다.
-
모든 프록시 서버가 그렇듯 프록시 캐시도 클라이언트와의 연결을 관리할 필요가 있습니다.
-
고성능 캐시는 로컬 스토리지와 네트워크 I/O 버퍼 사이에 문서 콘텐츠를 복사하는 것을 최소화하여 데이터를 효율적으로 전송하려고 합니다.
Step 7: Logging
Most caches keep log files and statistics about cache usage. After each cache transaction is complete, the cache updates statistics counting the number of cache hits and misses (and other relevant metrics) and inserts an entry into a log file showing the request type, URL, and what happened.
-
대부분의 캐시는 캐시 사용에 대한 로그 파일과 통계 자료를 보관합니다.
-
각각의 캐시 트랜잭션을 완료한 후 캐시는 Cache Hit과 Miss에 대한 통계 수치를 갱신합니다(다른 수치들도 마찬가지입니다).
-
그리고 요청 타입과 URL, 수행 작업 등을 나타내는 항목들을 로그 파일에 추가합니다.
The most popular cache log formats are the Squid log format and the Netscape extended common log format, but many cache products allow you to create custom log files. We discuss log file formats in detail in Chapter 21.
-
가장 자주 사용되는 캐시 로그 포맷은 Squid log format과 Netscape extended common log format이 있습니다.
-
물론 대부분의 캐시가 커스텀 로그 파일을 생성할 수 있게 합니다.
-
로그 파일 포맷에 대해서는 Chapter 21에서 자세히 다룹니다.
Cache Processing Flowchart
Figure7-12 shows, in simplified form, how a cache processes a request to GET a URL.*
- Figure 7-12는 GET URL 요청에 대한 단순한 형태의 캐시 프로세싱 과정을 나타냅니다.
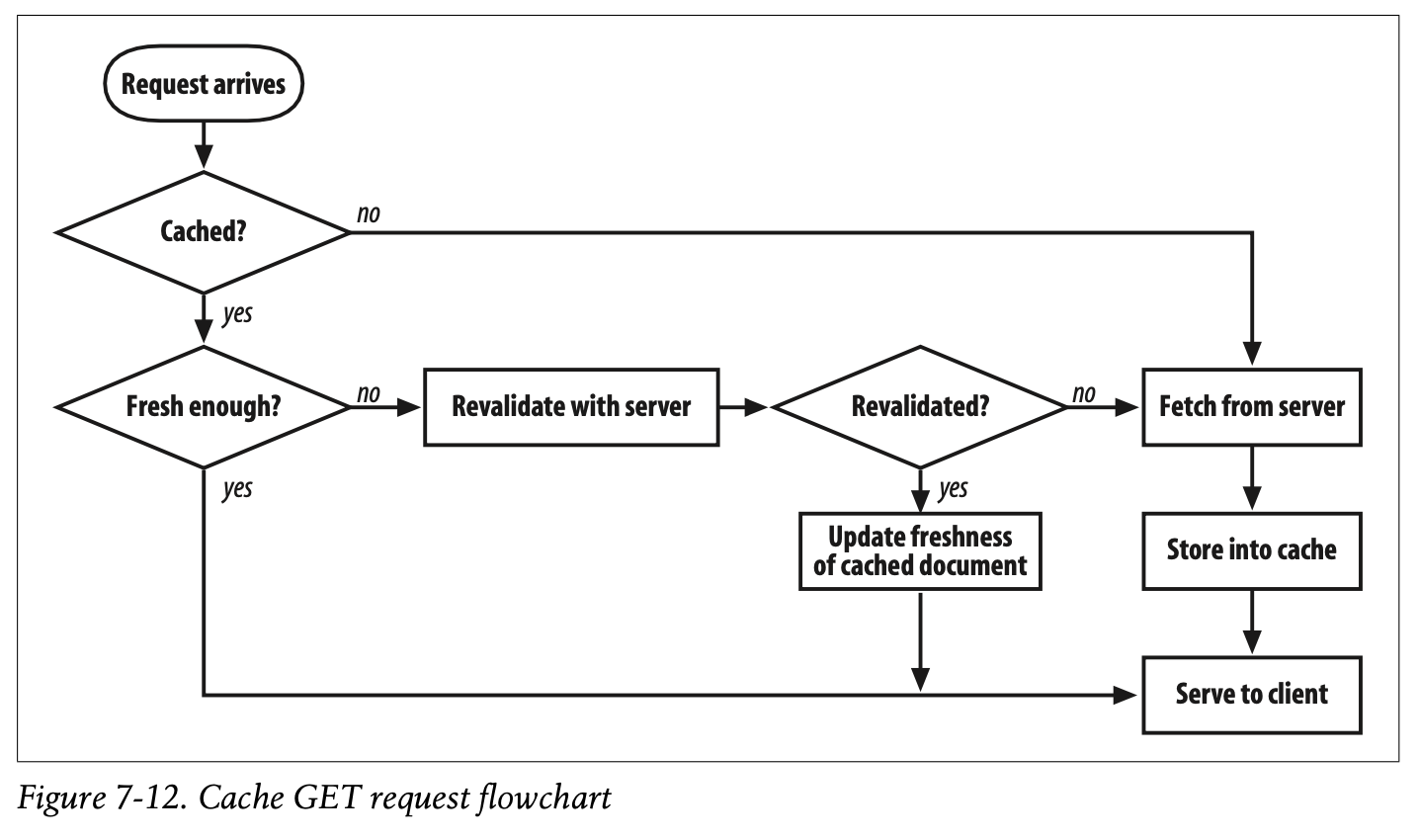
✏️ 요약
Cache Processing Steps
** Figure 7-12 Flowchart가 이해하기에는 제일 기똥차다
[1] Receiving & Parsing
- 네트워크 연결상 수신되는 데이터 감지
- 수신된 요청 메시지의 헤더 필드를 쉽게 처리할 수 있도록 데이터 구조 변환
[2] Lookup
- Cache Hit : 캐싱된 오브젝트(원본 서버의 요청 본문, 헤더, 메타데이터 포함) 준비
- Cache Miss : 원본 서버나 상위 계층의 프록시에 오브젝트 요청
[3] Freshness Check
- Fresh : 캐싱된 오브젝트 반환
- Stale : 재검증을 통해 수정 여부 확인
- 재검증 완료 -> 캐싱된 오브젝트 반환
- 재검증 실패 -> 원본 서버나 상위 계층의 프록시에 오브젝트 요청
- 클라이언트가 요청 헤더를 통해 재검증 수행 여부를 직접 결정할 수 있음
[4] Sending
- 캐시가 클라이언트에게 적합한 헤더와 캐시 관련 헤더 등을 포함하여 응답 생성
- 클라이언트에게 응답 전송 (스토리지와 I/O 버퍼 사이의 복사를 줄여서 최적화)
[5] Logging
- Cache Hit과 Cache Miss에 대한 통계 업데이트
- 로그 파일에 각각의 캐시 트랜잭션에 대한 항목 추가
✏️ 감상
캐시를 어떻게 하면 똑똑하게 굴릴 수 있을까
내가 해석을 잘못 한 걸지도 모르지만, 캐시가 일정 기간 동안 사본을 Fresh 상태로 간주한다고 나와 있었다. 일정 기간이라는 게 얼마나 긴 지는 몰라도 그 사이에 원본 서버의 오브젝트가 수정된다면 클라이언트는 이전 버전의 오브젝트를 가져가게 될 것이다. 가능한 한 최신 버전의 오브젝트를 반환하는 것을 보장하기 위해서는 클라이언트가 모든 요청에 재검증 요청 헤더를 포함해야겠지만, 그렇게 하면 사실 캐시를 쓰는 이유가 전혀 없을 것이다.
조금 더 똑똑하게 캐시를 굴리는 방법이 있을 것 같아 구글링을 해본 결과 Stale-While-Revalidate 라는 방식이 있다는 것을 알게 되었다. 엄밀히 말하자면 이 전략도 100% 최신 버전의 오브젝트를 반환하는 것은 아니다. 그렇지만 Freshness와 Immediacy 사이에서 줄타기를 아주 잘하는 방식이라고 볼 수 있다(?).
요지는 현재 문서가 Stale인 상태에서도 재검증 없이 즉시 클라이언트에 반환하며 백그라운드에서 재검증 요청을 수행한다는 것이다.
SWR 전략을 사용하지 않을 때는 여러 클라이언트가 동시에 Stale 상태의 문서에 접근하려 하면 각 요청마다 재검증을 수행하게 된다. 하지만 SWR 전략을 사용하면 문서를 즉시 돌려받을 수 있어 Immediacy 측면에서 훨씬 효율적이다. 그러면서도 재검증은 동일하게 수행하므로 Freshness 역시 잘 유지할 수 있다.
SWR 전략 외에도 프록시가 캐싱된 사본들에 대해 백그라운드에서 Freshness를 주기적으로 업데이트 하는 방법도 있을 것이다.
스토리지와 네트워크 버퍼 사이의 데이터 복사 최소화
캐시의 성능을 높이려면 스토리지와 네트워크 버퍼 사이에서 문서 콘텐츠를 복사하는 것을 최소화해야 한다는 부분이 있었다. 이 부분을 읽다 보니 OS와 리눅스를 공부할 때 다뤘던 내용이 어렴풋이 떠올랐다.
일반적으로 데이터를 전송하기 위해서는 디스크의 데이터를 I/O 버퍼에 복사해서... 그 데이터를 또 메모리에 복사해서... 그 데이터를 다시 소켓에 복사해야 한다(아이고 두야). 이때 I/O 버퍼에서 메모리로 데이터를 복사하는 과정을 생략하고 디스크의 데이터를 메모리에 매핑해서 성능을 높일 수 있다.
찾아보니 하드웨어적으로 봤을 때는 DMA(Direct Memory Access)를 사용해서 더 최적화 할 수 있다고 한다. DMA도 분명 공부했던 건데 까맣게 잊고 살다가 여기서 등장할 줄은 몰랐다. DMA는 CPU를 통해서 스토리지의 값을 읽는게 아니라 스토리지에서 소켓으로 직접 값을 읽어오는 방식이다. CPU는 스토리지 값을 읽는 것 외에도 처리해야 할 연산이 많기 때문에 DMA를 사용하면 CPU의 부하가 줄어든다.
이게 프록시 서버라고 생각하면 CPU는 여러 클라이언트에 대한 소켓을 열고 닫고 북 치고 장구 치고 할 일이 참 많은데, mmap을 사용하더라도 스토리지의 데이터를 읽는 무거운 작업을 수행하려면 부하가 상당히 커지게 된다. 여건이 된다면 DMA를 사용하는 것이 이상적이지만, 캐시가 응답 헤더를 수정하거나 보강하는 작업이 필요하다면 일부 데이터는 DMA 방식으로 전달하지 못할 수도 있다.
빠른 요청 처리는 서버 비용과도 직결되기 때문에 돈을 아끼기 위해서는 이런 부분들까지 고려해서 똑똑하게 코딩을 해야 한다는 것을 깨달았다.
난 진짜 최적화에 미친 사람인 것 같다.
