
Chapter 7. Caching
(해석 또는 이해가 잘못된 부분이 있다면 댓글로 편하게 알려주세요.)
✏️ 원문 번역
Heuristic Expiration
If the response doesn’t contain either a Cache-Control:max-age header or an Expires header, the cache may compute a heuristic maximum age. Any algorithm may be used, but if the resulting maximum age is greater than 24 hours, a Heuristic Expiration Warning (Warning 13) header should be added to the response headers. As far as we know, few browsers make this warning information available to users.
-
응답이 Cache-Control:max-age나 Expires 헤더를 포함하고 있지 않다면, 캐시는 Heuristic Maximum Age를 연산할 수 있습니다.
-
많은 알고리즘이 활용될 수 있지만, Maximum Age가 24시간 이상이라면 Heuristic Expiration Warning (Warning 13) 헤더를 응답 헤더에 추가해야 합니다.
-
그러나 현재까지 알려진 바로는 이 경고문을 사용자에게 보여주는 브라우저는 거의 없습니다.
One popular heuristic expiration algorithm, the LM-Factor algorithm, can be used if the document contains a last-modified date. The LM-Factor algorithm uses the last-modified date as an estimate of how volatile a document is. Here’s the logic:
• If a cached document was last changed in the distant past, it may be a stable document and less likely to change suddenly, so it is safer to keep it in the cache longer.
• If the cached document was modified just recently, it probably changes frequently, so we should cache it only a short while before revalidating with the server.
-
한 가지 잘 알려진 Heuristic Expirtion 알고리즘은 LM-Factor 알고리즘으로, 문서가 Last-Modified Date를 포함하고 있을 때 사용할 수 있습니다.
-
LM-Factor 알고리즘은 이 문서가 얼마나 변경되었는지를 추정하기 위해 Last-Modififed Date를 사용합니다.
-
절차는 다음과 같습니다.
- 만약 캐싱된 문서가 먼 과거에 수정되었다면, 그 문서는 안정적이고 급격한 변화가 일어나지 않았을 가능성이 높습니다. 따라서 이 문서는 캐시에 더 오랜 시간 보관하는 것이 더 안전합니다.
- 만약 캐싱된 문서가 방금 전에 수정되었다면, 수정이 빈번하게 발생하는 문서일 가능성이 높습니다. 따라서 이 문서는 짧은 시간 동안만 캐싱하고 서버에 재검증을 요청해야 합니다.
The actual LM-Factor algorithm computes the time between when the cache talked to the server and when the server said the document was last modified, takes some fraction of this intervening time, and uses this fraction as the freshness duration in the cache. Here is some Perl pseudocode for the LM-factor algorithm:
$time_since_modify = max(0, $server_Date - $server_Last_Modified);
$server_freshness_limit = int($time_since_modify * $lm_factor);
-
실제 LM-Factor 알고리즘은 캐시와 서버가 통신한 시점과 서버가 응답한 문서의 마지막 수정 시점 사이의 시간을 계산합니다.
-
그리고 이 중간 시간의 일부를 취하여 캐시의 Freshness 기간으로 사용합니다.
-
다음은 Perl 언어로 작성된 LM-Factor 알고리즘 Pseudocode입니다.
$time_since_modify = max(0, $server_Date - $server_Last_Modified); $server_freshness_limit = int($time_since_modify * $lm_factor);
Figure7-16 depicts the LM-factor freshness period graphically. The cross-hatched line indicates the freshness period, using an LM-factor of 0.2.
-
Figure 7-16은 LM-Factor Freshness 기간을 시각적으로 표현한 것입니다.
-
빗금이 쳐진 부분은 LM-Factor로 0.2를 사용했을 때의 Freshness 기간을 나타냅니다.
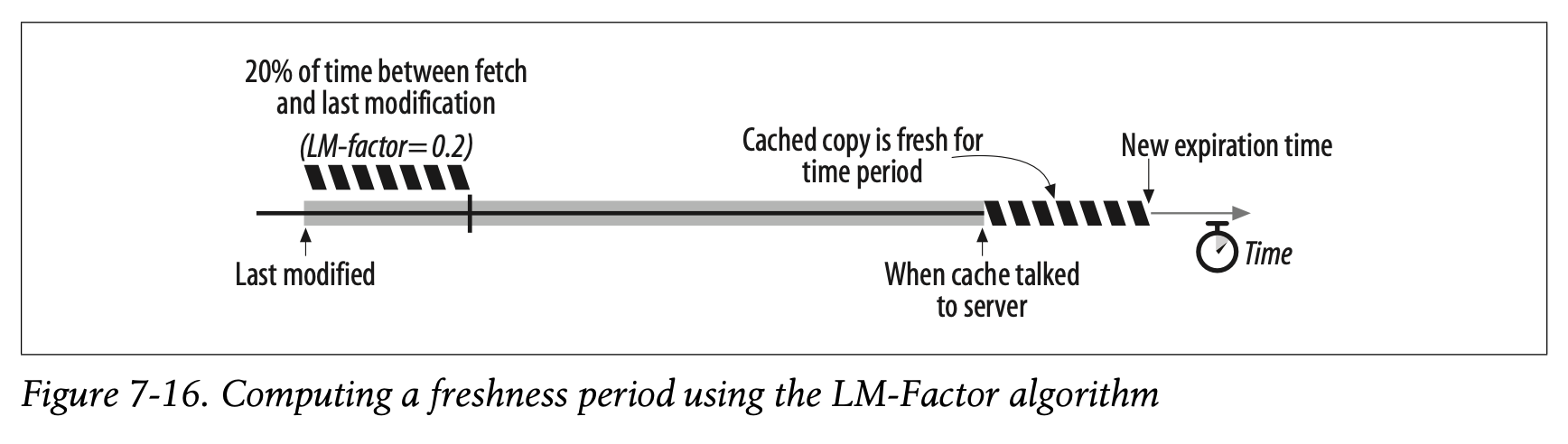
Typically, people place upper bounds on heuristic freshness periods so they can’t grow excessively large. A week is typical, though more conservative sites use a day.
-
일반적으로 사람들은 Heuristic Freshness 기간의 상한선을 설정하여 값이 지나치게 커지지 않도록 합니다.
-
보통 한 주를 상한선으로 설정하지만 조금 보수적인 사이트들은 하루를 상한선으로 설정하기도 합니다.
Finally, if you don’t have a last-modified date either, the cache doesn’t have much information to go on. Caches typically assign a default freshness period(an hour or a day is typical) for documents without any freshness clues. More conservative caches sometimes choose freshness lifetimes of 0 for these heuristic documents, forcing the cache to validate that the data is still fresh before each time it is served to a client.
-
만약 Last-modified Date조차 없다면 캐시에 저장할 정보가 거의 없습니다.
-
캐시는 Freshness에 대한 아무런 조건이 주어지지 않으면 문서에 Default Freshness 기간을 설정합니다. 한 시간 혹은 하루가 일반적입니다.
-
더 보수적인 캐시는 Heuristic 문서들에 대해서는 Freshness 생명주기를 0으로 설정하기도 합니다.
-
즉 클라이언트에게 문서를 제공하기 전에 항상 이 데이터가 Fresh한지 검증하도록 강제한다는 뜻입니다.
One last note about heuristic freshness calculations—they are more common than you might think. Many origin servers still don’t generate Expires and max-age headers. Pick your cache’s expiration defaults carefully!
-
Heuristic Freshness 연산에 대해 한 가지 더 첨언합니다.
-
우리가 생각하는 것보다 Heuristic Freshness 연산은 자주 일어납니다.
-
여전히 많은 원본 서버에서 Expires와 max-age 헤더를 생성하지 않고 있기 때문입니다.
-
우리 개발자 여러분들은 캐시의 Expiration 디폴트 값을 신중하게 선택하여 주시기 바랍니다!
Client Freshness Constraints
Web browsers have a Refresh or Reload button to forcibly refresh content, which might be stale in the browser or proxy caches. The Refresh button issues a GET request with additional Cache-control request headers that force a revalidation or unconditional fetch from the server. The precise Refresh behavior depends on the particular browser, document, and intervening cache configurations.
-
웹 브라우저는 Refresh 혹은 Reload 버튼(새로고침)을 통해서 브라우저나 프록시 캐시에서 Stale 상태에 있는 콘텐츠를 강제적으로 Refresh 할 수 있습니다.
-
Refresh 버튼을 누르면 Revalidation이나 Unconditional Fetch를 강제하는 Cache-Control 요청 헤더를 추가하여 GET 요청을 발행합니다.
-
정확한 Refresh의 기능은 특정 브라우저, 문서, 캐시 구성에 따라 달라질 수 있습니다.
Clients use Cache-Control request headers to tighten or loosen expiration constraints. Clients can use Cache-control headers to make the expiration more strict, for applications that need the very freshest documents (such as the manual Refresh button). On the other hand, clients might also want to relax the freshness requirements as a compromise to improve performance, reliability, or expenses. Table7-4 summarizes the Cache-Control request directives.
-
클라이언트는 만료일시 제한을 강화 혹은 완화하기 위해 Cache-Control 요청 헤더를 사용합니다.
-
Freshness를 항상 유지해야 하는 응용 프로그램의 경우, 클라이언트는 Cache-Control 헤더를 사용해서 만료일시를 더 엄격하게 설정합니다.
-
반대로 성능이나 안정성이나 비용 측면에서 효율을 높이기 위해 Freshness 요청을 완화하려는 경우도 있습니다.
-
Table 7-4는 Cache-Control 요청 지시어를 요약한 것입니다.

(지난 포스팅에 나온 Cache-Control 헤더가 다가 아니었네요)
Cautions
Document expiration isn’t a perfect system. If a publisher accidentally assigns an expiration date too far in the future, any document changes she needs to make won’t necessarily show up in all caches until the document has expired.* For this reason, many publishers don’t use distant expiration dates. Also, many publishers don’t even use expiration dates, making it tough for caches to know how long the document will be fresh.
-
문서의 만료일시는 완벽한 시스템이 아닙니다.
-
만약 Publisher가 실수로 만료일시를 너무 먼 미래로 설정하게 되면, 문서가 만료될 때까지 사용자가 필요로 하는 문서의 변경사항이 모든 캐시에서 표시되지 않을 것입니다.
-
이러한 이유로 많은 Publisher들이 만료일시를 근 미래로 설정합니다.
-
심지어는 만료일시를 아예 사용하지 않아서 캐시가 이 문서의 Freshness 기간을 파악하기 어려운 경우도 있습니다.
✏️ 요약
Heuristic Expiration
-
응답이 Cache-Control:max-age나 Expires 헤더를 포함하지 않은 경우 캐시가 직접 Expiration를 연산하는 것
-
LM-Factor Algorithm : Last-Modified Date를 사용하여 문서의 변경 정도를 추정하는 알고리즘
$time_since_modify = max(0, $server_Date - $server_Last_Modified); $server_freshness_limit = int($time_since_modify * $lm_factor);- 캐싱된 사본이 먼 과거에 수정되었다면 안정적인 문서로 판단
(= 응답 시점과 Last-Modified Date의 차이가 크면 Freshness 기간이 길다) - 캐싱된 사본이 가까운 과거에 수정되었다면 수정이 빈번한 문서로 판단
(= 응답 시점과 Last-Modified Date의 차이가 작으면 Freshness 기간이 짧다)
- 캐싱된 사본이 먼 과거에 수정되었다면 안정적인 문서로 판단
-
Maximum Age가 24시간 이상이라면 Heruistic Expiration Warning 헤더를 응답 헤더에 추가해야 한다
-
Last-Modified Date가 없다면 Default Freshness 기간을 따른다
Client Freshness Constaints
- 클라이언트가 만료일시 제한을 강화하거나 완화하기 위해 Cache-Control 요청 헤더를 사용하는 것
- 만료일시 강화 : Refresh & Reload 버튼을 통해 Cache-Control에 Revalidation 헤더를 추가해 요청을 전송하는 경우
- 만료일시 약화 : 성능, 안정성, 비용 측면에서의 효율을 높이기 위해 Cache-Control의 max-age 값을 높이는 경우
✏️ 감상
클라이언트 Cache-Control vs 서버 Cache-Control
어제와 오늘 읽은 게시글의 내용에 따르면 서버 측에서도 리소스에 대해 Cache-Control 헤더를 붙일 수 있고, 클라이언트 측에서도 Cache-Control 헤더를 붙일 수 있다. 만약 클라이언트가 Cache-Control 헤더를 붙여서 요청을 보냈다면 서버는 반드시 클라이언트가 요청한 헤더대로 캐시에 응답을 반환해야 할까?
조금 더 쉽게 예를 들자면 이런 것이다. 클라이언트가 Cache-Control: max-age=3600 헤더를 포함해서 요청을 보냈다면, 원본 서버로부터 오는 응답도 반드시 Cache-Control: max-age=3600 헤더를 포함해야 하는지에 대한 이야기다. 이 상황을 떠올리게 된 이유는 클라이언트가 캐시 저장 정책을 마음대로 바꿀 수 있으면 이것을 악용하는 사람들이 있을 것이라는 생각이 들었기 때문이다.
결론부터 이야기하자면 클라이언트의 Cache-Control 요청 헤더는 '참고용'이라고 한다. 클라이언트가 특정 정책을 요구할 수는 있지만 서버가 그 정책을 반드시 따를 필요는 없다는 것이다. 민감한 정보를 주고받는 상황이라면 클라이언트가 Cache-Control: max-age=3600 요청을 보내더라도 서버에서는 항상 Cache-Control: no-store 응답이 돌아가도록 설정할 수 있다. 캐시는 기본적으로 서버측의 응답 헤더를 따르기 때문에 no-store 응답이 돌아오면 캐시에 해당 정보는 저장되지 않는다.
max-age=0 must-revalidate와 no-cache의 차이
위의 두 가지 방식의 차이점을 구분하기는 어렵다. 진짜 별 차이가 없기 때문이다(?).
전자는 모든 캐싱된 사본을 Stale 상태로 두고 항상 재검증을 수행하도록 하는 정책이고, 후자는 재검증 없이 사본을 전송할 수 없다는 정책이다. 음... 그냥 말만 바꾼 거다. 1+2=2+1 같은 느낌이다. GPT한테 정말정말 아무런 차이가 없냐고 물어봤는데, 굳이 따지자면 전자는 재검증이 불가능한 상황에서 캐싱된 사본을 절대 반환할 수 없고, 후자는 설정에 따라서 캐싱된 사본이 돌아올 수도 있다는 점이라고 한다.
Cache-Control: private에 관하여
이 책에는 나오지 않았지만 Cache-Control: private 이라는 헤더를 종종 목격한 사람들도 있을 것이다. HTTP/1.1에 대한 표준인 RFC2616에 따르면 private에 대한 정의는 다음과 같다.
Indicates that all or part of the response message is intended for a single user and MUST NOT be cached by a shared cache, such as a proxy server.
즉, 응답 메시지의 전체 또는 일부가 "단일 사용자"를 위한 것이며 프록시 서버와 같은 공유 캐시에 의해 저장되어서는 안 됨을 나타낸다. Cache-Control: private을 사용할 경우 엔드포인트에 위치한 사용자 브라우저만 캐시를 저장하게 할 수 있다.
이것은 사용자별로 개인화된 콘텐츠를 반환할 때 유용하게 사용된다. 예를 들어 어떤 애플리케이션에 나의 푸시알림 설정 정보가 있다고 하면, 이 정보는 다른 유저에게 전혀 보일 필요가 없다. 그렇다고 엄청 민감한 정보도 아니다. 따라서 클라이언트 캐시에 이런 개인화된 콘텐츠를 저장해두면 성능적인 이점을 얻을 수 있다.
현업에 종사해본 적이 없는 대학생이다 보니 정확히 어디서부터 어디까지 private을 사용할 수 있는지는 잘 모르겠다. 어떤 글에서는 Private Key나 핵 발사 코드(?)를 전송하는 것이 아니면 웬만하면 private을 쓴다고 하기도 하고, 어떤 글에서는 보안이 중요한 경우에는 꼭 no-store를 써야 한다고 하기도 한다... 어쨌든 이것도 회사마다 정책이 조금씩 다르겠지만, 지금은 Cache-Control: private 이라는 선택지도 있다는 것에 초점을 맞추려고 한다.
