
Chapter 7. Caching
(해석 또는 이해가 잘못된 부분이 있다면 댓글로 편하게 알려주세요.)
✏️ 원문 번역
Complete Age-Calculation Algorithm
The last section showed how to compute the age of an HTTP-carried document when it arrives at a cache. Once this response is stored in the cache, it ages further. When a request arrives for the document in the cache, we need to know how long the document has been resident in the cache, so we can compute the current document age:
$age = $age_when_document_arrived_at_our_cache + $how_long_copy_has_been_in_our_cache;
-
지난 섹션에서는 HTTP로 전송된 문서가 캐시에 도착했을 때 Age를 연산하는 방법을 설명했습니다.
-
이 응답이 캐시에 저장되면 Age 값이 더 커지게 됩니다.
-
문서에 대한 요청이 도착했을 때 캐시는 문서가 캐시에 얼마나 오래 머무를 것인지 알아야 합니다.
-
그래야 현재 문서의 Age를 계산할 수 있습니다.
$age = $age_when_document_arrived_at_our_cache + $how_long_copy_has_been_in_our_cache;
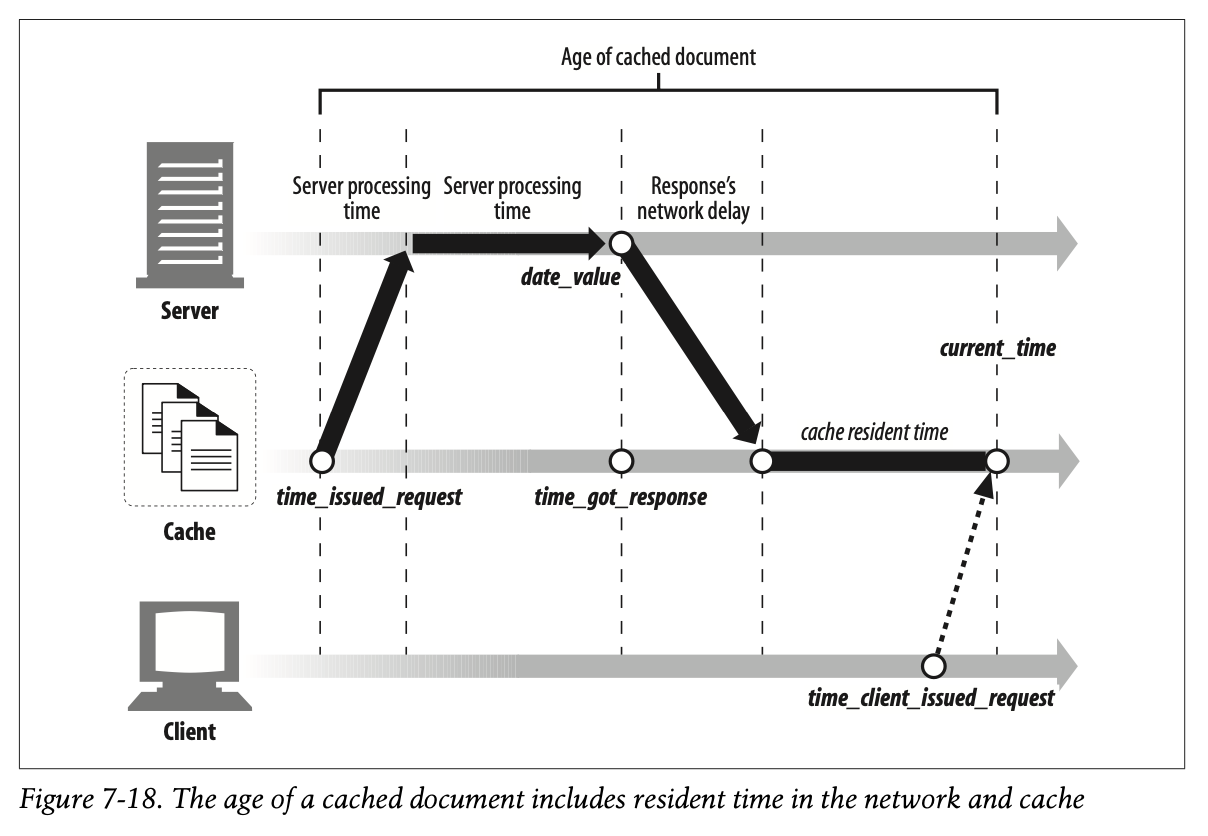
Ta-da! This gives us the complete HTTP/1.1 age-calculation algorithm we presented in Example7-1. This is a matter of simple bookkeeping—we know when the document arrived at the cache ($time_got_response) and we know when the current request arrived (right now), so the resident time is just the difference. This is all shown graphically in Figure7-18.
-
이는 Example 7-1에서 나타난 것처럼 완전한 HTTP/1.1 Age 연산 알고리즘을 제공합니다.
-
간단한 장부 기록의 문제입니다. 우리는 문서가 캐시에 저장된 시점이 언제인지 알고 있고($time_got_response) 현재 요청이 도착한 시점(지금)을 알고 있습니다.
-
따라서 이 두 값의 차로 캐시에 머무르는 기간을 계산할 수 있습니다.
-
Figure 7-18에 모든 것이 시각적으로 나타나 있습니다.
Freshness Lifetime Computation
Recall that we’re trying to figure out whether a cached document is fresh enough to serve to a client. To answer this question, we must determine the age of the cached document and compute the freshness lifetime based on server and client constraints. We just explained how to compute the age; now let’s move on to freshness lifetimes.
-
우리는 캐싱된 문서가 클라이언트에 제공하기에 충분히 Fresh 한지를 알아내려 하고 있었습니다.
-
질문에 대답하기 위해 캐싱된 사본의 Age와 서버와 클라이언트의 제약조건에 기반하여 Freshness Lifetime을 결정해야 합니다.
-
Age를 계산하는 방법은 방금 전에 설명하였고, 지금부터는 Freshness Lifetime으로 넘어가봅시다.
The freshness lifetime of a document tells how old a document is allowed to get before it is no longer fresh enough to serve to a particular client. The freshness lifetime depends on server and client constraints. The server may have information about the publication change rate of the document. Very stable, filed reports may stay fresh for years. Periodicals may be up-to-date only for the time remaining until the next scheduled publication—next week, or 6:00 am tomorrow.
-
문서의 Freshness Lifetime은 문서가 특정 클라이언트에게 Fresh 상태로 제공되는 기간을 나타냅니다.
-
Freshness Lifetime은 서버와 클라이언트 제약조건에 영향을 받습니다.
-
서버는 문서의 변경율에 대한 정보를 가질 수 있습니다.
-
매우 안정적으로 저장된 레포트는 수년간 Fresh 상태를 유지할 것입니다.
-
주기적으로 업데이트 되는 문서는 다음 예정된 게시일(다음주 혹은 내일 오전 6시 등)까지 최신 상태를 유지할 것입니다.
Clients may have certain other guidelines. They may be willing to accept slightly stale content, if it is faster, or they might need the most up-to-date content possible. Caches serve the users. We must adhere to their requests.
-
클라이언트는 또다른 가이드라인을 가지고 있을 수도 있습니다.
-
어떤 클라이언트는 조금 오래된 콘텐츠라도 빨리 응답이 오는 것을 선호하고, 또다른 클라이언트는 가능한 한 최신 콘텐츠를 필요로 하는 경우도 있습니다.
-
캐시는 그들의 요청대로 문서를 전송할 필요가 있습니다.
Complete Server-Freshness Algorithm
Example 7-2 shows a Perl algorithm to compute server freshness limits. It returns the maximum age that a document can reach and still be served by the server.
-
Example 7-2는 서버의 Freshness 제한을 계산하기 위한 Perl 알고리즘을 나타냅니다.
-
반환값은 문서가 도달한 후 서버에서 지속적으로 제공될 수 있는 최대 Age입니다.

Now let’s look at how the client can override the document’s server-specified age limit. Example 7-3 shows a Perl algorithm to take a server freshness limit and modify it by the client constraints. It returns the maximum age that a document can reach and still be served by the cache without revalidation.
-
이번에는 클라이언트가 서버가 설정한 문서의 Age Limit을 덮어쓰는 방법을 살펴봅니다.
-
Example 7-3은 서버의 Freshness Limit을 클라이언트 제약조건에 맞게 수정하는 것을 나타내는 Perl 알고리즘입니다.
-
반환값은 캐시가 재검증 절차 없이 서버에서 지속적으로 문서를 서비스할 수 있는 최대 Age입니다.

The whole process involves two variables: the document’s age and its freshness limit. The document is “fresh enough” if the age is less than the freshness limit. The algorithm in Example 7-3 just takes the server freshness limit and slides it around based on additional client constraints. We hope this section made the subtle expiration algorithms described in the HTTP specifications a bit clearer.
-
전체 프로세스는 두 가지 변수를 포함하고 있습니다. 바로 문서의 Age와 Freshness Limit입니다.
-
만약 Age가 Freshness Limit보다 작다면 문서가 충분히 Fresh 한 것으로 판단됩니다.
-
Exmaple 7-3의 알고리즘은 단순히 서버의 Freshness Limit을 가져와 클라이언트의 추가적인 제약조건에 맞게 수정한 것뿐입니다.
-
해당 섹션을 통해 HTTP에게 모호하게 설명된 만료 알고리즘이 보다 깔끔하고 명료하게 이해되기를 바랍니다.
✏️ 요약
Complete Age-Calculation Algorithm
- 알고리즘에 대한 자세한 설명은 이전 게시글 참조
https://velog.io/@dvlp-sy/TIL-HTTP-The-Definitive-Guide-p182-p183
Complete Server-Freshness Algorithm
[1] Server Freshness Constraint Calculation
-
Max_age_value_set : 서버 응답으로 Cache-Control: max-age 헤더 값이 들어온 경우
-
Expires_value_set : 서버 응답으로 Expires 헤더 값이 들어온 경우
-
Last_Modified_value_set : 위의 헤더들이 존재하지 않지만 Last_Modified 헤더 값이 들어온 경우 -> LM-Factor 알고리즘을 통한 Heuristic Expiration 계산
-
else : 캐시에 설정된 Default Freshness 기간을 따름
** 캐시가 임의로 Heuristic Expiration을 지정하는 경우 캐시에 정의된 Freshness Lifetime의 최솟값과 최댓값 범위를 준수해야 함
[2] Client Freshness Constraint Calculation
-
Max_Stale_value_set : 클라이언트가 Cache-Control: max-stale 헤더를 사용하여 Stale 문서를 일부 허용한 경우
-> Freshness Lifetime을 Max_Stale_value만큼 늘림 -
Min_Fresh_value_set : 클라이언트가 Cache-Control: min-fresh 헤더를 사용하여 Fresh 조건을 더 강화한 경우
-> Freshness Lifetime을 Min_Fresh_value만큼 줄임 -
Max_Age_value_set : 클라이언트가 Cache-Control: max-age의 값을 명시한 경우
-> 서버가 계산한 Freshness Lifetime과 클라이언트가 요청한 Freshness Lifetime 중 보수적인 값 선택
✏️ 감상
주먹구구식인 것 같으면서도 묘하게 체계가 있다
어제 오늘 Age와 Freshness Lifetime을 계산하는 Pseudocode를 보면서 든 생각은... 캐시에서 문서의 만료 기간을 결정하는 방식이 굉장히 주먹구구식이라는 점이다(?). HTTP가 확장되어 헤더 값이 조금이라도 달라지거나 HTTP 프로토콜 자체를 사용하지 않는다면 전혀 적용되지 않을 그런 알고리즘이다. 다행인 점은 현재 가장 많이 사용하는 프로토콜이 HTTP고, HTTP 안에는 표준이 있어 이런 주먹구구식의 규칙이라도 준수할 수 있다는 것이다. 프로토콜의 제약을 받지 않고도 Expiration 알고리즘이 정상적으로 작동하려면 프로토콜보다도 더 큰 범주의 표준이 있어야 할 것이다. 사실상 불가능한 얘기다.
음,, 그래도 HTTP라는 작은 규약 내에서는 Expiration 알고리즘이 효율적으로 설계되었다고 생각한다. 모든 헤더 조건을 if-elseif-else문에 하나씩 넣어놓은 것뿐인 단순한 알고리즘이지만(너무나도 주먹구구식이지만)... 성능 하나만큼은 끝내주게 좋을 것이다.
