
Chapter 9. Web Robots
(해석 또는 이해가 잘못된 부분이 있다면 댓글로 편하게 알려주세요.)
✏️ 원문 번역
Excluding Robots
The robot community understood the problems that robotic web site access could cause. In 1994, a simple, voluntary technique was proposed to keep robots out of where they don’t belong and provide webmasters with a mechanism to better control their behavior. The standard was named the “Robots Exclusion Standard” but is often just called robots.txt, after the file where the access-control information is stored.
-
로봇 커뮤니티는 로봇이 웹 사이트에 접근함으로써 발생하는 문제를 인지하고 있습니다.
-
로봇이 부적절한 곳에 접근하지 못하게 하고 웹마스터가 크롤링을 제어하기 위한 더 나은 매커니즘을 제공할 수 있도록 간단하고 자발적인 기술이 1994년에 고안되었습니다.
-
이 표준은 "Robots Exclusion Standard"로 명명되었지만 robots.txt로 더 잘 알려져 있습니다.
-
robots.txt는 접근 제어 정보를 저장하는 파일입니다.
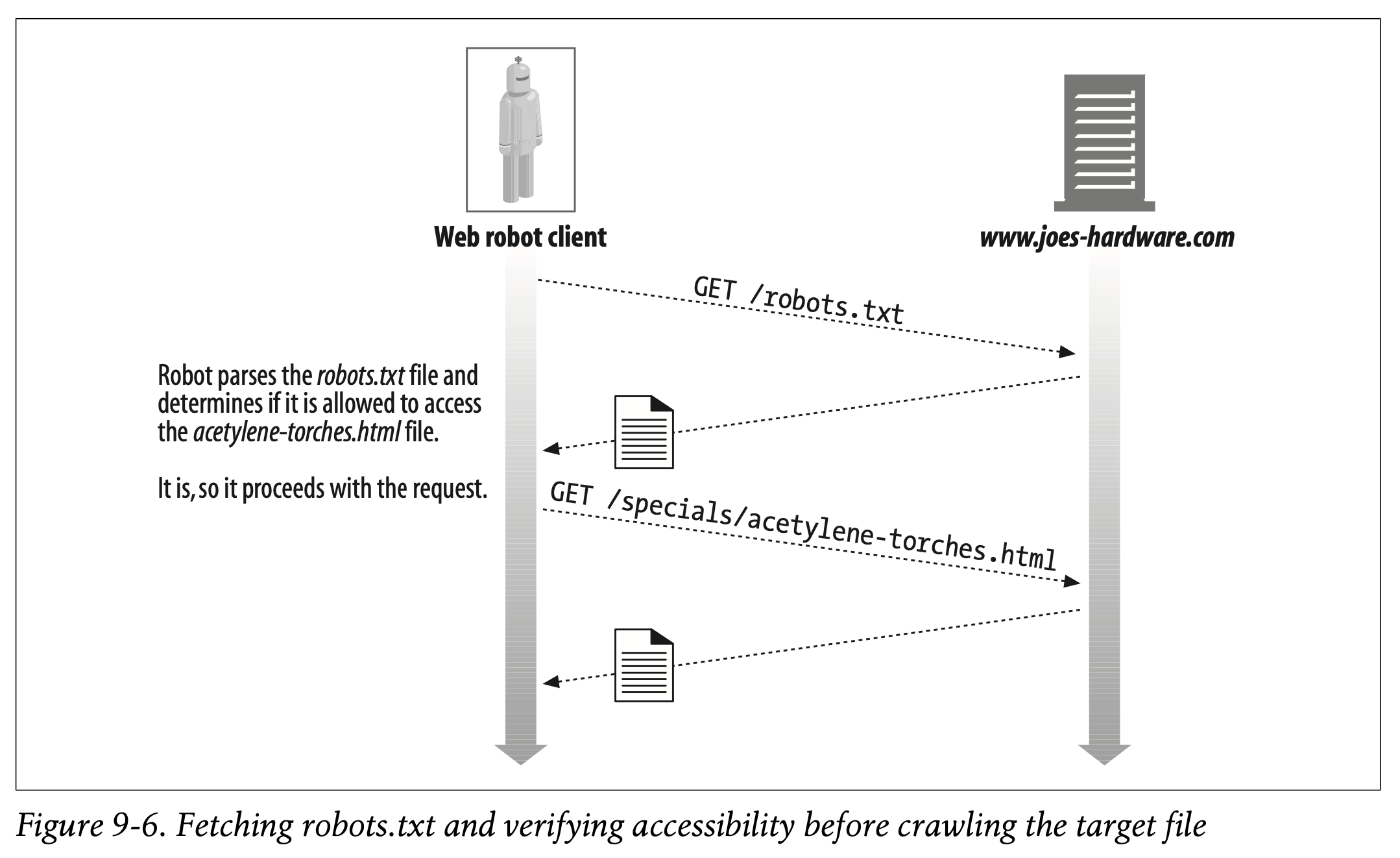
The idea of robots.txt is simple. Any web server can provide an optional file named robots.txt in the document root of the server. This file contains information about what robots can access what parts of the server. If a robot follows this voluntary standard, it will request the robots.txt file from the web site before accessing any other resource from that site. For example, the robot in Figure 9-6 wants to download http://www.joes-hardware.com/specials/acetylene-torches.html from Joe’s Hardware. Before the robot can request the page, however, it needs to check the robots.txt file to see if it has permission to fetch this page. In this example, the robots.txt file does not block the robot, so the robot fetches the page.
-
robots.txt에 대한 아이디어는 단순합니다.
-
모든 웹 서버가 루트에 robots.txt 라는 이름의 파일을 선택적으로 제공할 수 있습니다.
-
해당 파일은 로봇이 접근할 수 있는 서버 영역에 관한 정보를 포함하고 있습니다.
-
표준을 따르는 로봇은 웹 사이트로부터 robots.txt 파일을 요청한 후 다른 리소스에 접근할 것입니다.
-
예를 들어 Figure 9-6의 로봇이 Joe's Hardware에서 http://www.joes-hardware.com/specials/acetylene-torches.html을 다운로드 하고자 합니다.
-
그러나 로봇은 페이지를 요청하기 전에 robots.txt 파일을 확인해야 합니다. 페이지를 요청할 권한이 있는지 확인하기 위함입니다.
-
예시에서는 robots.txt 파일이 로봇을 차단하고 있지 않으므로 페이지를 불러옵니다.
The Robots Exclusion Standard
The Robots Exclusion Standard is an ad hoc standard. At the time of this writing, no official standards body owns this standard, and vendors implement different subsets of the standard. Still, some ability to manage robots’ access to web sites, even if imperfect, is better than none at all, and most major vendors and search-engine crawlers implement support for the exclusion standard.
-
Robots Exclusion Standard는 임시 표준입니다.
-
글을 적는 시점에 어떠한 기관도 이 표준을 소유하고 있지 않습니다.
-
공급업체는 표준의 다양한 하위집합을 구현하고 있습니다.
-
웹 사이트에 대한 로봇의 접근을 관리하는 능력이 완전하지 않더라도 아예 없는 것보다는 낫습니다.
-
다수의 공급업체와 검색엔진 크롤러는 Exclusion Standard를 지원하도록 구현되어 있습니다.
There are three revisions of the Robots Exclusion Standard, though the naming of the versions is not well defined. We adopt the version numbering shown in Table 9-2.
-
Robots Exclusion Standard는 세 차례 개정되었지만 버전 명칭이 명확하게 정의되어 있지는 않습니다.
-
이 책에서는 Table 9-2와 같은 버전 번호을 채택합니다.

Most robots today adopt the v0.0 or v1.0 standards. The v2.0 standard is much more complicated and hasn’t been widely adopted. It may never be. We’ll focus on the v1.0 standard here, because it is in wide use and is fully compatible with v0.0.
-
오늘날 많은 로봇들이 v0.0이나 v1.0 표준을 채택하고 있습니다.
-
v2.0 표준은 훨씬 정교하지만 널리 채택되지 않았습니다.
-
앞으로도 그럴지도 모릅니다.
-
여기서는 v1.0 표준에 포커스를 둡니다.
-
v0.0과 완벽하게 호환되며 널리 쓰이고 있기 때문입니다.
Web Sites and robots.txt Files
Before visiting any URLs on a web site, a robot must retrieve and process the robots.txt file on the web site, if it is present.* There is a single robots.txt resource for the entire website defined by the hostname and port number. If the site is virtually hosted, there can be a different robots.txt file for each virtual docroot, as with any other file.
-
만약 웹 사이트에 robots.txt가 존재한다면 URL에 방문하기 전 로봇이 robots.txt 파일을 불러온 후 처리해야 합니다.
-
호스트명과 포트번호로 정의된 전체 웹 사이트에 대해 robots.txt 리소스는 단 한 개만 존재합니다.
-
가상 호스팅된 사이트는 다른 파일과 마찬가지로 각각의 가상 docroot에 대해 robots.txt 파일을 보유할 수 있습니다.
Currently, there is no way to install “local” robots.txt files in individual subdirectories of a web site. The webmaster is responsible for creating an aggregate robots.txt file that describes the exclusion rules for all content on the web site.
-
현재 웹 사이트의 개별 하위 디렉토리에서 로컬 robots.txt 파일을 설치할 수 있는 방법은 없습니다.
-
웹마스터는 웹 사이트의 모든 콘텐츠에 대한 예외 규칙을 정의하는 robots.txt 파일을 생성할 의무가 있습니다.
Fetching robots.txt
Robots fetch the robots.txt resource using the HTTP GET method, like any other file on the web server. The server returns the robots.txt file, if present, in a text/plain body. If the server responds with a 404 Not Found HTTP status code, the robot can assume that there are no robotic access restrictions and that it can request any file.
-
웹 서버의 다른 파일들과 마찬가지로 로봇은 HTTP GET 메서드를 사용하여 robots.txt 리소스를 불러옵니다.
-
robots.txt 파일이 존재한다면 서버는 text/plain 본문을 통해 해당 파일을 반환합니다.
-
서버의 응답이 404 Not Found로 돌아온다면 로봇은 접근 제한이 없는 것으로 가정하여 모든 파일을 요청할 수 있습니다.
Robots should pass along identifying information in the From and User-Agent headers to help site administrators track robotic accesses and to provide contact information in the event that the site administrator needs to inquire or complain about the robot. Here’s an example HTTP crawler request from a commercial web robot:
GET /robots.txt HTTP/1.0 Host: www.joes-hardware.com User-Agent: Slurp/2.0 Date: Wed Oct 3 20:22:48 EST 2001
-
로봇은 From 및 User-Agent 헤더를 통해 식별 정보를 전달합니다.
-
사이트 관리자가 로봇의 접근을 추적하고 로봇에 대해 문의하거나 불만을 토로하는 경우에 대비하여 연락처를 제공하기 위함입니다.
-
다음은 상용 웹 로봇이 전송하는 HTTP 크롤러 요청의 예시입니다.
GET /robots.txt HTTP/1.0 Host: www.joes-hardware.com User-Agent: Slurp/2.0 Date: Wed Oct 3 20:22:48 EST 2001
Response codes
Many websites do not have a robots.txt resource, but the robot doesn’t know that. It must attempt to get the robots.txt resource from every site. The robot takes different actions depending on the result of the robots.txt retrieval:
-
많은 웹 사이트가 robots.txt 리소스를 가지고 있지 않지만 로봇은 그 사실을 알지 못합니다.
-
분명 로봇은 모든 사이트에서 robots.txt 리소스를 불러오려고 시도할 것입니다.
-
robots.txt 탐색 결과에 따라 로봇은 다양한 액션을 수행하게 됩니다.
• If the server responds with a success status (HTTP status code 2XX), the robot must parse the content and apply the exclusion rules to fetches from that site.
- 서버가 성공적으로 응답을 반환하면 (HTTP 상태 코드 2XX) 로봇은 콘텐츠를 파싱하여 해당 사이트에 대한 예외 규칙을 적용합니다.
• If the server response indicates the resource does not exist (HTTP status code 404), the robot can assume that no exclusion rules are active and that access to the site is not restricted by robots.txt.
-
리소스가 존재하지 않음을 나타내는 응답이 돌아오면 (HTTP 상태 코드 404) 로봇은 적용중인 예외 규칙이 없다고 가정합니다.
-
따라서 robots.txt에 의한 제재 없이 사이트에 접근합니다.
• If the server response indicates access restrictions (HTTP status code 401 or 403) the robot should regard access to the site as completely restricted.
- 서버 응답이 접근 제한을 나타내면 (HTTP 상태 코드 401 혹은 403) 로봇은 사이트에 대한 접근이 완전히 차단된 것으로 간주합니다.
• If the request attempt results in temporary failure (HTTP status code 503), the robot should defer visits to the site until the resource can be retrieved.
- 요청이 일시적으로 실패한 것으로 추정되는 경우 (HTTP 상태 코드 503) 로봇은 리소스를 탐색할 수 있을 때까지 방문을 연기해야 합니다.
• If the server response indicates redirection (HTTP status code 3XX), the robot should follow the redirects until the resource is found.
- 서버 응답이 리디렉션을 나타내면 (HTTP 상태 코드 3XX) 로봇은 리소스가 발견될 때까지 정해진 리디렉션을 따라야 합니다.
✏️ 요약
The Robots Exclusion Standard
: 로봇이 접근 가능한 서버 영역을 명시하는 robots.txt에 관한 표준
- 리소스를 요청하기 전 robots.txt 본문을 요청(GET)하여 접근 제한 확인
- robots.txt 파일이 존재하는 경우 text/plain 본문 반환
- 2XX : 콘텐츠를 파싱하여 예외 규칙 적용
- 404 : 예외 규칙이 없는 것으로 간주
- 401 or 403 : 사이트에 대한 접근 완전차단
- 503 : 요청이 일시적으로 실패 -> 방문 연기
- 3XX : 리소스가 발견될 때까지 리디렉션
✏️ 감상
robots.txt 작성 양식
분명 robots.txt에도 작성 지침이 있을 것이다. 상용 크롤러가 파싱하여 해석 가능한 형식이어야 하기 때문이다.
책에서도 언급되었듯 robots.txt는 한 호스트당 하나만 존재해야 하며 루트에 작성하는 것이 좋다. 해당 파일을 루트에 작성하지 않는 경우 호스트에 대한 모든 URL을 제어할 수 없다. 또한 robots.txt는 프로토콜, 호스트, 포트가 정확히 일치하는 URL에만 적용된다. 가령 http를 https로 쓴다거나 서브 도메인에 해당하는 경우에는 적용되지 않는다. 안정성을 위해 robots.txt는 UTF-8로 인코딩하도록 권장된다.
robots.txt는 여러 개의 규칙 집합으로 구성될 수 있다. 규칙 집합에는 규칙이 적용되는 대상(User-Agent), 접근이 가능하거나(Allow) 불가능한(Disallow) 디렉토리와 파일을 명시한다. 로봇은 사용자 에이전트에 해당하는 한 가지 규칙 집합에 연결되어 제약사항을 확인한다.
Ex1) 모든 사이트에 대해 크롤링 제한
User-agent: * Disallow: /
Ex2) 특정 디렉토리에 한하여 크롤링 가능
User-agent: * Disallow: / Allow: /public/
Ex3) 특정 형식의 파일에 대해 크롤링 제한
User-agent: * Disallow: /*.gif$
robots.txt에 대한 작성 지침은 Google Developers를 참고하였다.
https://developers.google.com/search/docs/crawling-indexing/robots/create-robots-txt?hl=ko
