
Chapter 9. Web Robots
(해석 또는 이해가 잘못된 부분이 있다면 댓글로 편하게 알려주세요.)
✏️ 원문 번역
Other robots.txt Wisdom
Here are some other rules with respect to parsing the robots.txt file:
- robots.txt 파일 파싱과 관련한 몇 가지 다른 규칙들입니다.
• The robots.txt file may contain fields other than User-Agent, Disallow, and Allow, as the specification evolves. A robot should ignore any field it doesn’t understand.
-
사양이 발전함에 따라 robots.txt 파일이 User-Agent, Disallow, Allow 외의 필드를 포함할 수 있습니다.
-
로봇은 이해하지 못한 어떤 필드든 무시해서는 안 됩니다.
• For backward compatibility, breaking of lines is not allowed.
- 이전 버전과의 호환성을 위해 줄바꿈은 허용되지 않습니다.
• Comments are allowed anywhere in the file; they consist of optional whitespace, followed by a comment character (#) followed by the comment, until the end-of-line character.
-
파일의 어느 곳이든 주석을 달 수 있습니다.
-
선택적인 공백과 주석 문자 # 이후부터 EOF를 만나기 전까지는 주석으로 구성됩니다.
• Version 0.0 of the Robots Exclusion Standard didn’t support the Allow line. Some robots implement only the Version 0.0 specification and ignore Allow lines. In this situation, a robot will behave conservatively, not retrieving URLs that are permitted.
-
Robots Exclusion Standard의 0.0 버전은 Allow 라인을 지원하지 않습니다.
-
일부 로봇은 0.0 버전 명세에 따라 구현되어 있어 Allow 라인을 무시하기도 합니다.
-
이때 로봇은 보수적으로 동작하여 허용된 URL을 탐색하지 않습니다.
Caching and Expiration of robots.txt
If a robot had to refetch a robots.txt file before every file access, it would double the load on web servers, as well as making the robot less efficient. Instead, robots are expected to fetch the robots.txt file periodically and cache the results. The cached copy of robots.txt should be used by the robot until the robots.txt file expires. Standard HTTP cache-control mechanisms are used by both the origin server and robots to control the caching of the robots.txt file. Robots should take note of Cache-Control and Expires headers in the HTTP response.
-
만약 로봇이 모든 파일에 접근하기 전 robots.txt 파일을 다시 불러와야 한다면 웹 서버에 부하가 두 배나 가해집니다.
-
로봇의 성능이 떨어지는 것은 덤입니다.
-
대신 로봇은 robots.txt 파일을 주기적으로 캐시에서 불러와 결과를 저장해야 합니다.
-
robots.txt 파일이 만료될 때까지 로봇이 robots.txt의 캐싱된 사본을 사용할 수 있습니다.
-
원본 서버와 로봇 모두 robots.txt 파일 캐싱을 제어하기 위해 표준 HTTP Cache-Control 매커니즘을 적용합니다.
-
로봇은 HTTP 응답에서 Cache-Control 및 Expires 헤더에 주목해야 합니다.
Many production crawlers today are not HTTP/1.1 clients; webmasters should note that those crawlers will not necessarily understand the caching directives provided for the robots.txt resource.
-
오늘날의 상용 크롤러가 전부 HTTP/1.1 클라이언트인 것은 아닙니다.
-
웹마스터는 HTTP/1.1을 사용하지 않는 크롤러가 robots.txt 리소스에 제공되는 캐싱 지시문를 반드시 이해하지 못한다는 점에 유의해야 합니다.
If no Cache-Control directives are present, the draft specification allows caching for seven days. But, in practice, this often is too long. Web server administrators who did not know about robots.txt often create one in response to a robotic visit, but if the lack of a robots.txt file is cached for a week, the newly created robots.txt file will appear to have no effect, and the site administrator will accuse the robot administrator of not adhering to the Robots Exclusion Standard.
-
Cache-Control 지시문이 없다면 초기 사양은 7일간 캐싱을 허용합니다.
-
그러나 7일은 너무 긴 기간입니다.
-
robots.txt에 대해 알지 못하는 웹 서버 관리자들은 종종 로봇 방문에 대한 응답으로 해당 파일을 생성합니다.
-
그러나 빈 robots.txt 파일이 일주일 동안 지속되어 새롭게 생성된 robots.txt 파일이 마치 아무런 영향도 주지 않는 것처럼 보일 수 있습니다.
-
사이트 관리자는 로봇 관리자가 Robots Exclusion Standard를 준수하지 않는다며 비난할 것입니다.
Robot Exclusion Perl Code
A few publicly available Perl libraries exist to interact with robots.txt files. One example is the WWW::RobotsRules module available for the CPAN public Perl archive.
-
널리 사용 가능한 Perl 라이브러리 중에는 robots.txt 파일과 상호작용하기 위한 것도 있습니다.
-
그 중 하나가 바로 CPAN 공식 Perl 아카이브에서 이용 가능한 WWW::RobotsRules 모듈입니다.
The parsed robots.txt file is kept in the WWW::RobotRules object, which provides methods to check if access to a given URL is prohibited. The same WWW::RobotRules object can parse multiple robots.txt files.
-
파싱된 robots.txt 파일은 WWW::RobotRules 객체에 보관됩니다.
-
이는 차단된 URL에 접근하고 있는지 확인하는 수단을 제공합니다.
-
동일한 WWW::RobotRules 객체가 여러 개의 robots.txt 파일을 파싱할 수 있습니다.
Here are the primary methods in the WWW::RobotRules API:
Create RobotRules object
$rules = WWW::RobotRules->new($robot_name);Load the robots.txt file
$rules->parse($url, $content, $fresh_until);Check if a site URL is fetchable
$can_fetch = $rules->allowed($url);
- WWW::RobotRules API의 몇 가지 주요한 메서드를 소개합니다.
- WWW::RobotRules->new($robot_name) : RobotRules 객체 생성
- rules->parse() : robots.txt 파일을 불러와 파싱
- rules->allowed() : URL을 불러올 수 있는지 확인
Here’s a short Perl program that demonstrates the use of WWW::RobotRules:
require WWW::RobotRules; # Create the RobotRules object, naming the robot "SuperRobot" my $robotsrules = new WWW::RobotRules 'SuperRobot/1.0'; use LWP::Simple qw(get); # Get and parse the robots.txt file for Joe's Hardware, accumulating the rules $url = "http://www.joes-hardware.com/robots.txt"; my $robots_txt = get $url; $robotsrules->parse($url, $robots_txt); # Get and parse the robots.txt file for Mary's Antiques, accumulating the rules $url = "http://www.marys-antiques.com/robots.txt"; my $robots_txt = get $url; $robotsrules->parse($url, $robots_txt); # Now RobotRules contains the set of robot exclusion rules for several # different sites. It keeps them all separate. Now we can use RobotRules # to test if a robot is allowed to access various URLs. if ($robotsrules->allowed($some_target_url)) { $c = get $url; ... }
- 위의 코드는 WWW::RobotRules를 활용한 짧은 Perl 프로그램입니다.
The following is a hypothetical robots.txt file for www.marys-antiques.com:
- 아래 파일은 www.marys-antiques.com 에 대한 가상의 robots.txt입니다.

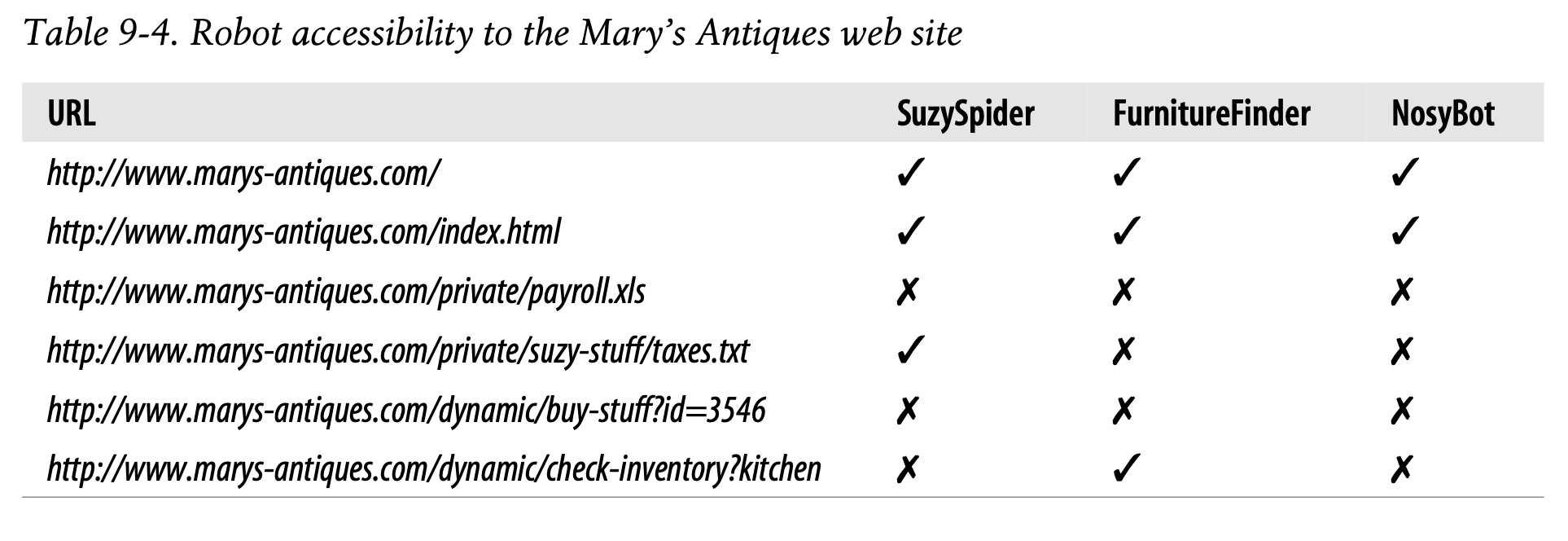
This robots.txt file contains a record for the robot called SuzySpider, a record for the robot called FurnitureFinder, and a default record for all other robots. Each record applies a different set of access policies to the different robots:
-
해당 robots.txt 파일은 SuzySpider, FurnitureFinder에 대한 레코드 및 다른 모든 로봇에 대한 디폴트 레코드를 포함하고 있습니다.
-
각각의 레코드는 서로 다른 로봇에 대해 서로 다른 접근 정책 집합을 적용하고 있습니다.
• The exclusion record for SuzySpider keeps the robot from crawling the store inventory gateway URLs that start with /dynamic and out of the private user data, except for the section reserved for Suzy.
- SuzySpider에 대한 예외 집합은 로봇이 /dynamic으로 시작하는 상점 인벤토리 게이트웨이 URL과 Suzy 섹션을 제외한 사적 유저 데이터 영역을 크롤링하는 것을 방지하고 있습니다.
• The record for the FurnitureFinder robot permits the robot to crawl the furniture inventory gateway URL. Perhaps this robot understands the format and rules of Mary’s gateway.
-
FurnitureFinder에 대한 예외 집합은 로봇이 가구 인벤토리 게이트웨이 URL을 크롤링하는 것을 허용하고 있습니다.
-
아마 이 로봇은 Mary의 게이트웨이에 대한 형식과 규칙을 이해하고 있을 것입니다.
• All other robots are kept out of all the dynamic and private web pages, though they can crawl the remainder of the URLs.
- 모든 다른 로봇은 모든 동적이고 사적인 웹 페이지에 접근할 수 없으며 나머지 URL은 크롤링할 수 있습니다.
Table 9-4 lists some examples for different robot accessibility to the Mary’s Antiques web site.
- Table 9-4는 Mary's Antizues 웹 사이트에 대한 다양한 로봇의 접근 권한을 나타낸 예시입니다.
✏️ 요약
Note for Robots
- 로봇이 필드를 이해하지 못하더라도 무시해서는 안 된다
- robots.txt 파일의 어느 곳에든 # 기호와 함께 주석을 작성할 수 있다
- robots.txt의 캐싱 지침 또한 기본적으로 HTTP 표준 Cache-Control 매커니즘을 따른다
- HTTP/1.1 을 사용하지 않는 로봇도 있을 수 있다
Robot Exclusion Perl Code
: WWW::RobotRules API를 활용하여 robots.txt와 상호작용하는 방법
- WWW::RobotRules->new($robot_name) : RobotRules 객체 생성
- rules->parse() : robots.txt 파일을 불러와 파싱
- rules->allowed() : URL을 불러올 수 있는지 확인
✏️ 감상
왜 이 책에서는 Perl이 자주 등장할까
문득 그런 생각이 들었다. 그 많은 언어들 중에 유독 이 책에서는 Perl이 자주 보인다. 지금은 잘 쓰이지도 않는 언어인 것 같은데 도대체 어떤 의미가 있어 자꾸만 낯설게 등장하는가.
Perl은 1987년에 발표된 언어다. C만큼 오래되진 않았지만 꽤나 원시적인 언어다. 20세기 말 Perl이 인기를 끌 수 있었던 이유가 있다면, 그건 한참 웹이 발전하던 시기에 빠른 속도로 텍스트를 처리할 수 있는 강력한 언어였기 때문일 것이다. 당시에는 문자열 매칭, 정규 표현식 등 "문자열 처리" 하면 이만한 언어가 없었다. 어쩐지 NLP 하시는 교수님께서 자꾸 Perl을 말씀하시더라 게다가 CGI 방식을 많이 사용했기 때문에 스크립트를 Perl로 작성하는 경우가 많았다.
역으로 왜 21세기에 Perl이 사라졌냐고 한다면, 그건 파이썬이라는 말도 안 되는 인터프리터 언어가 등장했기 때문일 것이다...ㅋㅋ 파이썬은 Perl에 비해 가독성이 좋고, 웹 시장과 데이터 시장 모두를 아우를 수 있는 범용성을 갖추고 있다. 그러다 보니 점점 트렌드가 바뀌게 된 것이다.
