
Chapter 13. Digest Authentication
(해석 또는 이해가 잘못된 부분이 있다면 댓글로 편하게 알려주세요.)
✏️ 원문 번역
Digest Calculations
The heart of digest authentication is the one-way digest of the mix of public information, secret information, and a time-limited nonce value. Let’s look now at how the digests are computed. The digest calculations generally are straightforward. Sample source code is provided in Appendix F.
-
Digest Authentication은 공개 및 비공개된 정보, 시간 제한을 나타내는 nonce 값을 합쳐 단방향으로 암호화하는 방식입니다.
-
지금부터는 Digest가 계산되는 방법에 대해 알아봅시다.
-
Digest 연산은 일반적으로 간단합니다.
-
예제 소스 코드는 Appendix F에 수록되어 있습니다.
Digest Algorithm Input Data
Digests are computed from three components:
• A pair of functions consisting of a one-way hash function H(d) and digest KD(s,d), where s stands for secret and d stands for data
• A chunk of data containing security information, including the secret password, called A1
• A chunk of data containing nonsecret attributes of the request message, called A2
The two pieces of data, A1 and A2, are processed by H and KD to yield a digest.
-
Digest는 세 가지 구성 요소에 의해 연산됩니다.
-
단방향 해시함수 H(d)와 Digest 함수 KD(s,d) 쌍 (s는 secret, d는 data를 의미)
-
비밀번호와 같은 보안 정보를 포함하는 데이터 청크 A1
-
요청 메시지의 공개 특성을 포함하는 데이터 청크 A2
-
A1과 A2의 두 데이터 조각은 H와 KD에 의해 처리되어 digest를 생성합니다.
The Algorithms H(d) and KD(s,d)
Digest authentication supports the selection of a variety of digest algorithms. The two algorithms suggested in RFC 2617 are MD5 and MD5-sess (where “sess” stands for session), and the algorithm defaults to MD5 if no other algorithm is specified.
-
Digest Authentication은 다양한 Digest 알고리즘을 선택할 수 있도록 지원합니다.
-
RFC 2617에서는 MD5와 MD5-sess(sess는 session을 의미합니다)의 두 가지 알고리즘이 제안되었습니다.
-
특별히 알고리즘을 지정하지 않는 경우에는 디폴트로 MD5를 사용합니다.
If either MD5 or MD5-sess is used, the H function computes the MD5 of the data, and the KD digest function computes the MD5 of the colon-joined secret and nonsecret data. In other words:
H(<data>) = MD5(<data>) KD(<secret>,<data>) = H(concatenate(<secret>:<data>))
-
MD5나 MD5-sess를 사용하면 H 함수가 데이터의 MD5를 연산합니다.
-
KD Digest 함수는 콜론으로 연결된 비밀번호와 공개 정보의 MD5를 연산합니다.
The Security-Related Data (A1)
The chunk of data called A1 is a product of secret and protection information, such as the username, password, protection realm, and nonces. A1 pertains only to security information, not to the underlying message itself. A1 is used along with H, KD, and A2 to compute digests.
-
A1 청크 데이터는 username, password, 보안 영역, nonce와 같은 기밀 정보 및 보호 정보에 해당합니다.
-
A1은 보안 정보와 관련이 있으며 메시지 자체와는 관련되지 않습니다.
-
A1은 H, KD, A2와 함께 digest 연산에 사용됩니다.
RFC 2617 defines two ways of computing A1, depending on the algorithm chosen:
MD5
One-way hashes are run for every request; A1 is the colon-joined triple of username, realm, and secret password.MD5-sess
The hash function is run only once, on the first WWW-Authenticate hand-shake; the CPU-intensive hash of username, realm, and secret password is done once and prepended to the current nonce and client nonce (cnonce) values.
-
RFC 2617은 선택된 알고리즘에 따라 A1을 연산하는 두 가지 방식을 정의합니다.
-
MD5
- 매 요청마다 단방향 해시를 수행합니다.
- A1은 콜론으로 연결된 username, 보안영역, password 쌍입니다.
-
MD5-sess
- WWW-Authenticate를 통한 hand-shake를 진행할 때 해시함수가 한 번 실행됩니다.
- username과 보안 영역, 비밀번호를 CPU로 해싱하는 것은 한 번만 수행되며 현재 nonce 및 클라이언트의 nonce 값이 뒤에 붙습니다.
The definitions of A1 are shown in Table 13-2.
- A1의 정의는 Table 13-2에 나타난 것과 같습니다.

The Message-Related Data (A2)
The chunk of data called A2 represents information about the message itself, such as the URL, request method, and message entity body. A2 is used to help protect against method, resource, or message tampering. A2 is used along with H, KD, and A1 to compute digests.
-
A2라고 불리는 데이터 청크는 URL과 요청 메서드, 본문과 같이 메시지 자체에 대한 정보를 표현합니다.
-
A2는 메서드나 리소스, 메시지 처리 변조를 방지하기 위해 사용됩니다.
-
A2는 H, KD, A1과 함께 Digest 연산에 사용됩니다.
RFC 2617 defines two schemes for A2, depending on the quality of protection (qop) chosen:
• The first scheme involves only the HTTP request method and URL. This is used when qop=“auth”, which is the default case.
• The second scheme adds in the message entity body to provide a degree of message integrity checking. This is used when qop=“auth-int”.
-
RFC 2617에서는 선택된 보호 수준(qop)에 따라 A2의 두 가지 기법을 소개합니다.
-
첫 번째 기법은 HTTP 요청 메서드와 URL만을 포함합니다.
-
이는 qop="auth"로 지정된 경우에 해당하며, 디폴트 케이스입니다.
-
두 번째 기법은 메시지의 본문을 추가하여 메시지 무결성 검사를 제공합니다.
-
이는 qop="auth-int"로 지정된 경우에 해당합니다.
The definitions of A2 are shown in Table 13-3.
- A2의 정의는 Table 13-3에 나타난 바와 같습니다.

The request-method is the HTTP request method. The uri-directive-value is the request URI from the request line. This may be “*,” an “absolute URL,” or an “abs_path,” but it must agree with the request URI. In particular, it must be an absolute URL if the request URI is an absoluteURL.
-
request-method는 HTTP의 요청 메서드입니다.
-
uri-directive-value는 요청 라인에 나타나는 요청 URI입니다.
-
이 값은 "*"나 "absoluteURL", 혹은 "abs_path"로도 표기될 수 있지만 요청 URI와 일치해야 합니다.
-
특히 요청 URI가 absoluteURL인 경우 absolute URL을 작성해야 합니다.
Overall Digest Algorithm
RFC 2617 defines two ways of computing digests, given H, KD, A1, and A2:
• The first way is intended to be compatible with the older specification RFC 2069, used when the qop option is missing. It computes the digest using the hash of the secret information and the nonced message data.
• The second way is the modern, preferred approach—it includes support for nonce counting and symmetric authentication. This approach is used whenever qop is “auth” or “auth-int”. It adds nonce count, qop, and cnonce data to the digest.
-
RFC 2617에서는 H, KD, A1, A2가 주어졌을 때 Digest를 연산하는 두 가지 방식에 대해 정의합니다.
-
첫 번째 방식은 구버전의 명세인 RFC 2069와 호환이 가능하도록 구현되었습니다. qop 옵션이 없을 때 사용되는 표준입니다. 이 방식은 기밀 정보와 nonce 값이 붙은 메시지 데이터를 해싱하여 digest를 연산합니다.
-
두 번째 방식은 더 현대적이고 적절한 방식입니다. nonce 값과 symmetric authentication을 지원하는 기능이 추가되었습니다. 이 방식은 qop가 "auth"나 "auth-int"인 경우 사용되며 nonce 값과 qop, cnonce 데이터를 digest에 추가합니다.
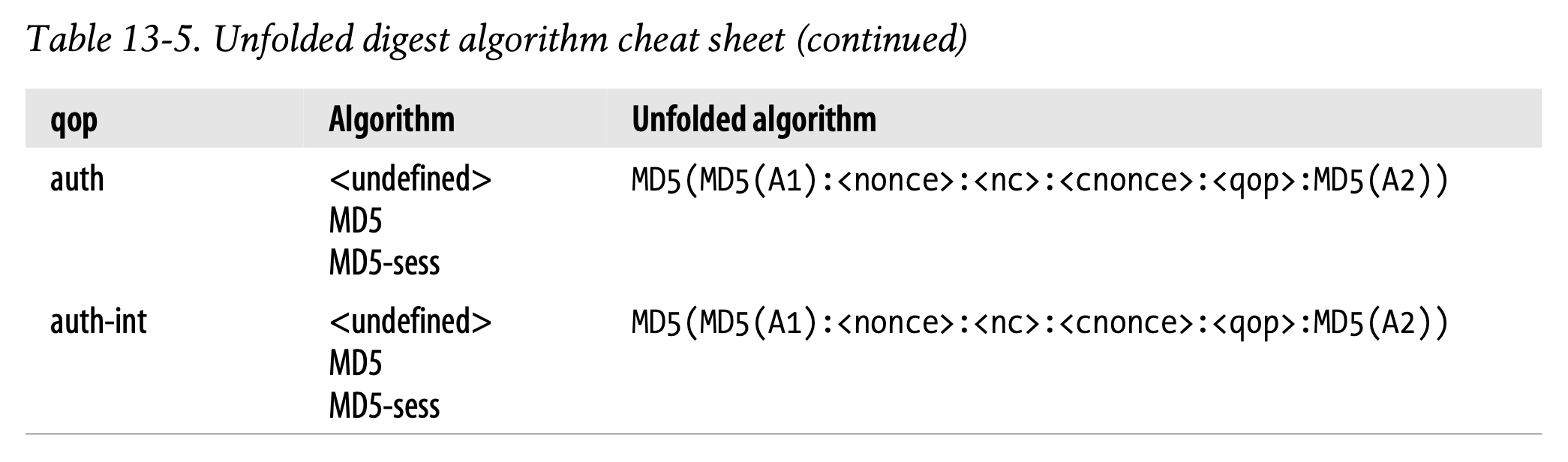
The definitions for the resulting digest function are shown in Table 13-4. Notice the resulting digests use H, KD, A1, and A2.
-
최종적인 Digest 함수의 정의는 Table 13-4에 정리되어 있습니다.
-
최종적인 Digest는 H, KD, A1, A2를 사용한다는 점에 유의합니다.

It’s a bit easy to get lost in all the layers of derivational encapsulation. This is one of the reasons that some readers have difficulty with RFC 2617. To try to make it a bit easier, Table 13-5 expands away the H and KD definitions, and leaves digests in terms of A1 and A2.
-
파싱 캡슐화의 모든 레이어에서 길을 잃기 쉽습니다.
-
독자들이 RFC 2617을 어려워하는 이유 중 하나입니다.
-
Table 13-5는 H와 KD 함수의 정의를 확장하여 A1와 A2의 관점에서 digest를 생성하는 것을 나타냅니다.

✏️ 요약
Digest Calculations
: H(d), KD(s, d), A1, A2를 사용하여 Digest를 연산하는 기법
- H(d) : 단방향 해시함수를 사용하여 데이터의 MD5 값 계산
H(d)=MD5(d) - KD(s, d) : 콜론으로 연결된 Secret Data와 Public Data의 MD5 값 계산
KD(s,d)=H(concat(s:d)) - A1 : Secret Data (username, password, 보안영역, nonce 등)
- MD5 : 매 요청마다 해싱 수행
A1 = <user>:<realm>:<password> - MD5-sess : WWW-Authenticate를 통한 hand-shake 과정에서 해시함수 1회 실행 (해싱 이후 nonce와 cnonce가 붙음)
A1 = MD5(<user>:<realm>:<password>):<nonce>:<cnonce>
- MD5 : 매 요청마다 해싱 수행
- A2 : 메시지 변조 방지 목적의 데이터 청크 (URL, 요청 메서드 등)
qop undefined: <request-method>:<uri-directive-value>qop=auth: <request-method>:<uri-directive-value>qop=auth-int: <request-method>:<uri-directive-value>H(<request-entity-body>)
Digest Algorithm ver.1
: qop 옵션이 없을 때(qop undefined) 사용 가능한 알고리즘 (deprecated)
KD(s, d) = KD(H(A1), <nonce>:H(A2))Digest Algorithm ver.2
: qop=auth 혹은 qop=auth-int인 경우 qop, nonce, cnonce 데이터를 추가하여 digest를 연산하는 알고리즘 (preferred)
KD(s, d) = KD(H(A1), <nonce>:<nc>:<cnonce>:<qop>:H(A2))✏️ 감상
Digest 알고리즘 신기하다...✨
오늘은 보안 문제를 해결하기 위해 데이터를 전처리하고 해싱하는 과정을 면밀하게 살펴보았다. 중간자 공격이나 리플레이 공격을 방지하기 위해 데이터에 여러 가지 처리 과정이 덧붙여지게 된 것인데... 그 결과로 만들어진 Digest알고리즘이 굉장히 재미있었다. nonce부터 시작해서 메시지 변조 여부를 알기 위해 A2 데이터 청크를 함께 활용하려는 아이디어까지 정말 센스 있지 않은가. 오늘날에는 보안 문제로 인해 MD5 Digest를 사용하지는 않지만 아이디어 자체는 굉장히 세련됐다고 생각한다. 해시함수만 조금 더 강력한 걸로 대치한다면 알고리즘을 그대로 활용할 수도 있지 않을까.
사실 요즘에는 Digest Authentication이 아닌 OAuth 방식을 주로 사용하기 때문에 Digest에 대해 자세히 알 필요는 없다. 그래도 재미있는 걸..
업로드 주기 조정
매일 글을 쓰는 것 자체는 어렵지 않지만, TIL을 쓰다 보니 자꾸 다른 일들을 안 하기 시작했다...ㅋㅋㅋㅋㅋㅋ 그래서 업로드 주기를 한 이틀 정도로 늘려보면 어떨지 싶다 😌 이렇게 했는데도 내가 다른 일을 하지 않는다면 그때는 다시 하루에 한 번씩 글을 쓰러 올 것이다. 그건 TIL이 문제가 아니라 정말 귀찮아서 일을 안 하는 것이니 ㅎㅎ,, 제발 내가 그렇게까지 나태한 사람은 아니기를 바란다.
