
Chapter 15. Entities and Encodings
(해석 또는 이해가 잘못된 부분이 있다면 댓글로 편하게 알려주세요.)
✏️ 원문 번역
Chunked Encoding
Chunked encoding breaks messages into chunks of known size. Each chunk is sent one after another, eliminating the need for the size of the full message to be known before it is sent.
-
청크 인코딩은 메시지를 지정된 사이즈로 분할합니다.
-
각각의 청크는 연달아 전송되며, 전송이 이루어지기 전에 전체 메시지의 크기를 알 필요가 없습니다.
Note that chunked encoding is a form of transfer encoding and therefore is an attribute of the message, not the body. Multipart encoding, described earlier in this chapter, is an attribute of the body and is completely separate from chunked encoding.
-
청크 인코딩은 전송 인코딩의 일종이므로 본문이 아니라 메시지의 속성이라는 점에 유의합니다.
-
앞서 다루었던 Multipart 인코딩은 본문의 특성이므로 청크 인코딩과는 완전히 별개입니다.
Chunking and Persistent Connections
When the connection between the client and server is not persistent, clients do not need to know the size of the body they are reading—they expect to read the body until the server closes the connection.
-
클라이언트와 서버 사이의 연결이 영구적이지 않은 경우 클라이언트는 수신중인 본문의 길이를 알 필요가 없습니다.
-
서버가 연결을 종료할 때까지 본문을 읽으면 되기 때문입니다.
With persistent connections, the size of the body must be known and sent in the Content-Length header before the body can be written. When content is dynamically created at a server, it may not be possible to know the length of the body before sending it.
-
하지만 영속 연결에서는 반드시 본문의 길이를 알고 Content-Length 헤더에 실어 보내야 본문이 작성될 수 있습니다.
-
콘텐츠가 서버에서 동적으로 생성되는 경우 전송 전에 본문의 길이를 알 수 없을 가능성이 있습니다.
Chunked encoding provides a solution for this dilemma, by allowing servers to send the body in chunks, specifying only the size of each chunk. As the body is dynamically generated, a server can buffer up a portion of it, send its size and the chunk, and then repeat the process until the full body has been sent. The server can signal the end of the body with a chunk of size 0 and still keep the connection open and ready for the next response.
-
청크 인코딩은 위와 같은 딜레마에 해결책을 제시합니다.
-
서버가 본문을 청크 단위로 전송하여 각 청크의 사이즈만을 특정하게 하는 것입니다.
-
본문이 동적으로 생성될 때 서버는 본문의 일부를 취하여 버퍼의 크기만큼 전송합니다.
-
이 과정을 전체 본문이 전송될 때까지 반복합니다.
-
서버는 사이즈가 0인 청크를 통해 본문의 끝을 표시할 수 있으며 다음 응답을 위해 연결을 유지하고 대기할 수 있습니다.
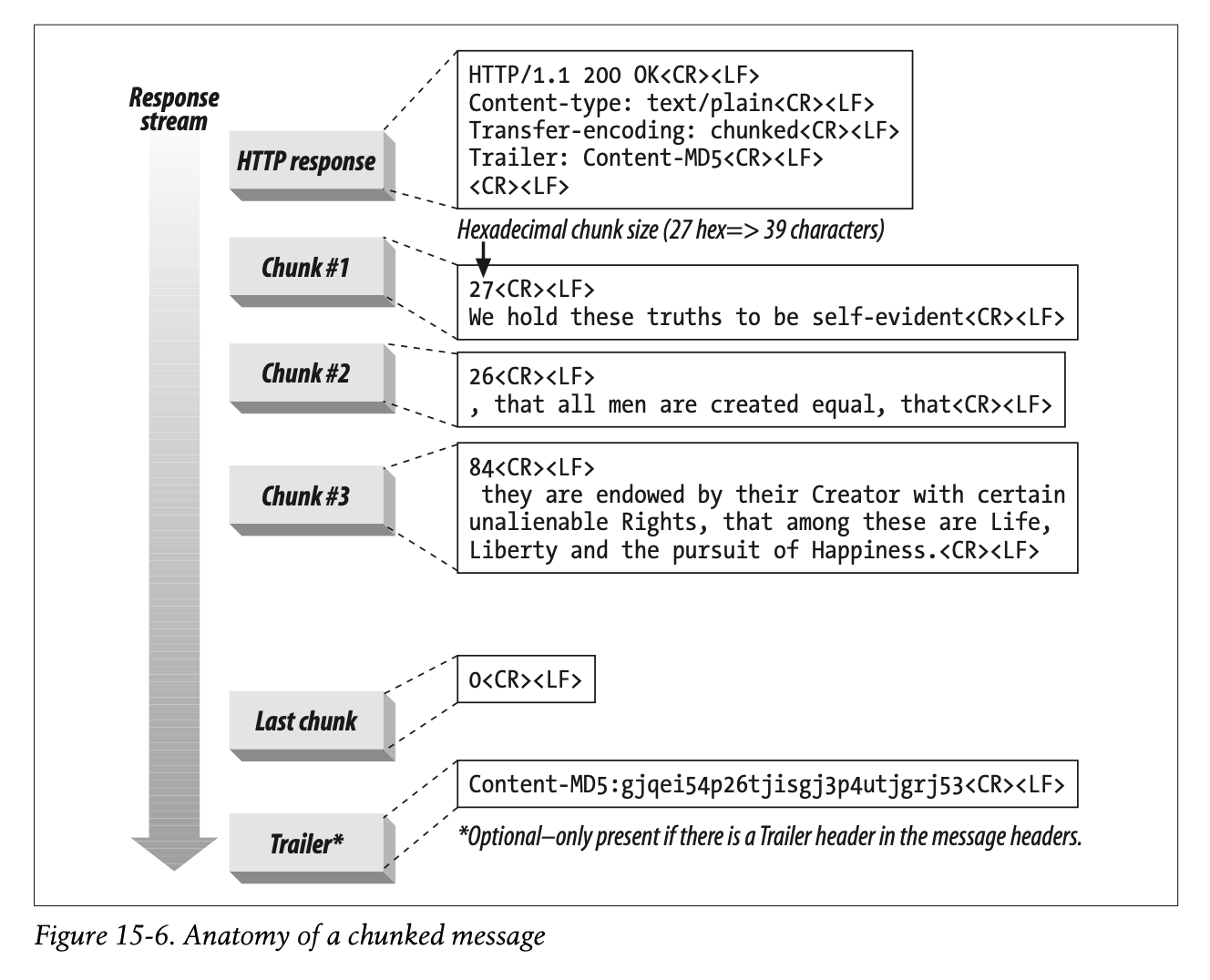
Chunked encoding is fairly simple. Figure 15-6 shows the basic anatomy of a chunked message. It begins with an initial HTTP response header block, followed by a stream of chunks. Each chunk contains a length value and the data for that chunk. The length value is in hexadecimal form and is separated from the chunk data with a CRLF. The size of the chunk data is measured in bytes and includes neither the CRLF sequence between the length value and the data nor the CRLF sequence at the end of the chunk. The last chunk is special—it has a length of zero, which signifies “end of body.”
-
청크 인코딩은 매우 간단합니다.
-
Figure 15-6에서 청크 메시지의 기본 구조를 나타냅니다.
-
최초의 HTTP 응답 헤더 블록부터 시작하여 청크 스트림이 뒤를 잇습니다.
-
각각의 청크는 길이 값과 데이터를 포함하고 있습니다.
-
길이 값은 16진수 형태로 구성되며 CRLF를 통해 청크 데이터와 구분됩니다.
-
청크 데이터의 크기는 바이트로 측정되며 길이 값과 데이터 사이의 CRLF 시퀀스와 청크의 끝에 위치한 CRLF 시퀀스를 포함하지 않습니다.
-
마지막 청크는 특수합니다. 청크의 크기가 0이므로 본문의 끝을 암시합니다.
A client also may send chunked data to a server. Because the client does not know beforehand whether the server accepts chunked encoding (servers do not send TE headers in responses to clients), it must be prepared for the server to reject the chunked request with a 411 Length Required response.
-
클라이언트가 서버에게 청크 데이터를 전송할 수도 있습니다.
-
그러나 서버가 클라이언트에게 응답으로 TE 헤더를 전달하지 않는 한 클라이언트는 서버가 청크 인코딩을 허용하는지 알 수 없습니다.
-
서버가 청크 요청을 거절하고자 할 때는 411 Length Required 응답을 준비해야 합니다.
Trailers in Chunked Messages
A trailer can be added to a chunked message if the client’s TE header indicates that it accepts trailers, or if the trailer is added by the server that created the original response and the contents of the trailer are optional metadata that it is not necessary for the client to understand and use (it is okay for the client to ignore and discard the contents of the trailer).
-
클라이언트의 TE 헤더가 트레일러를 허용하는 것으로 나타나거나 원본 응답을 생성한 서버로부터 트레일러가 추가된 경우 청크 메시지의 끝에 트레일러를 추가할 수 있습니다.
-
트레일러의 콘텐츠는 클라이언트가 이해하고 사용하는 데 반드시 필요한 것은 아닌 선택적인 메타데이터입니다. (클라이언트가 트레일러의 콘텐츠를 무시하고 폐기해도 괜찮습니다.)
The trailer can contain additional header fields whose values might not have been known at the start of the message (e.g., because the contents of the body had to be generated first). An example of a header that can be sent in the trailer is the Content-MD5 header—it would be difficult to calculate the MD5 of a document before the document has been generated. Figure 15-6 illustrates the use of trailers. The message headers contain a Trailer header listing the headers that will follow the chunked message. The last chunk is followed by the headers listed in the Trailer header.
-
트레일러는 추가적인 헤더 필드를 포함할 수 있습니다.
-
각 헤더 필드는 메시지의 시작 부분에서 알려지지 않을 수도 있습니다. 본문의 콘텐츠가 먼저 생성되어야 하기 때문입니다.
-
트레일러에 포함되어 전송될 수 있는 헤더의 예시로는 Content-MD5 헤더가 있습니다.
-
문서가 생성되기 전에는 문서의 MD5를 연산하는 것이 어려울 수 있습니다.
-
Figure 15-6은 트레일러의 사용 방식을 표현합니다.
-
메시지 헤더는 Trailer 헤더를 통해 청크 메시지와 함께 올 수 있는 헤더 목록을 나열합니다.
-
마지막 청크 뒤에는 Trailer 헤더에 나열된 헤더가 뒤따라 전송됩니다.
Any of the HTTP headers can be sent as trailers, except for the Transfer-Encoding, Trailer, and Content-Length headers.
- Trasnfer-Encoding과 Content-Length를 제외한 모든 HTTP 헤더는 트레일러로 전송될 수 있습니다.
✏️ 요약
Chunked Encoding
: 메시지를 지정된 크기의 청크로 나누어 전송하기 위한 Transfer Encoding의 일종
- 본문의 특성이 아닌 메시지의 속성
- 전체 데이터의 길이를 알 수 없는 경우 유용하게 사용
- 각 청크마다 Length Value와 데이터 포함
** Length Value는 CRLF 값을 포함하지 않는다 (데이터 내부 CRLF 제외)27<CR><LF> We hold these truths to be self-evident<CR><LF> Transfer-encoding: chunked: 청크 인코딩을 사용함을 나타내는 헤더Trailer: 클라이언트의 TE 헤더가 트레일러를 허용하거나 원본 서버가 트레일러를 생성한 경우 선택적으로 포함되는 헤더- Transfer-Encoding, Content-Length를 제외한 모든 HTTP 헤더를 포함할 수 있음
- 선택적인 메타데이터 (메시지를 이해하는 데 반드시 필요한 요소 X)
✏️ 감상
트레일러의 역할?
청크 인코딩에서 Trailer 헤더를 통해 선택적인 메타데이터를 전송할 수 있다는 사실을 배웠다! 그런데 Trailer는 왜 사용하고 어떤 메타데이터를 전송할 수 있는 걸까?
일단 Trailer 헤더는 청크 인코딩에서 모든 청크가 전송되고 난 후 최종적으로 전송되는 HTTP 헤더를 나열하는 용도로 사용된다.
그러니까 왜 굳이 그 짓을 하는 걸까... 왜 앞에다 안 쓰고 뒤에다 붙여 쓰는 건데
HTTP 헤더를 본문 앞이 아니라 본문 뒤에 붙여야 하는 이유가 있기 때문이다. Trailer가 Transfer-Encoding과 Content-Length를 제외한 모든 HTTP 헤더를 포함할 수 있긴 하지만, 대체로 Trailer에 포함되는 헤더는 완성된 본문을 바탕으로 이루어지는 후속 작업의 결과를 포함한다.
책에서 괜히 Content-MD5 헤더를 예로 든 것이 아니다(!) 메시지의 무결성을 검증하는 체크섬을 생성하기 위해서는 모든 청크가 전부 전송되어 하나의 본문이 완성된 상태여야 한다. 본문이 미처 완성되기도 전에 Content-MD5 헤더를 전송해봤자 아무런 의미가 없다는 뜻이다.
그럼 청크 인코딩이 아닌 다른 요청에서도 Trailer를 사용할까?
보통은 그렇지 않다. 콘텐츠가 정적이고 Length를 알고 있는 상황이라면 굳이굳이 Content-MD5를 뒤에다 붙일 필요가 없다. 이미 알고 있는 콘텐츠 가지고 체크섬을 계산해서 요청에 포함하면 그만이다..! 문제가 생기는 경우는 콘텐츠가 동적으로 생겨서 MD5를 당장 계산할 수 없는 청크 인코딩과 같은 상황에만 국한된다.
