
Chapter 15. Entities and Encodings
(해석 또는 이해가 잘못된 부분이 있다면 댓글로 편하게 알려주세요.)
✏️ 원문 번역
Conditionals and Validators
Each conditional works on a particular validator. A validator is a particular attribute of the document instance that is tested. Conceptually, you can think of the validator like the serial number, version number, or last change date of a document. A wise client in Figure 15-8b would send a conditional validation request to the server saying, “send me the resource only if it is no longer Version 1; I have Version 1.” We discussed conditional cache revalidation in Chapter 7, but we’ll study the details of entity validators more carefully in this chapter.
-
각각의 조건은 특정 Validator에 의해 동작합니다.
-
Validator는 테스트하려는 문서 인스턴스의 특정 속성입니다.
-
개념적으로는 Validator를 개념적으로 일련번호나 버전 번호, 혹은 문서의 가장 최근 변경 시각 정도로 이해할 수 있습니다.
-
Figure 15-8b에 나타난 똑똑한 클라이언트는 서버에게 조건부 검증 요청을 전송하고 있습니다.
-
"나는 Version 1의 리소스를 가지고 있으니 더 이상 버전 1이 아닌 경우에만 리소스를 전달할 것"을 요구합니다.
-
조건부 캐시 검증에 대해서는 Chapter 7에서 이야기하였지만, 이번 챕터에서는 Entity Validator에 대해 조금 더 상세히 설명합니다.
The If-Modified-Since conditional header tests the last-modified date of a document instance, so we say that the last-modified date is the validator. The If-None-Match conditional header tests the ETag value of a document, which is a special keyword or version-identifying tag associated with the entity. Last-Modified and ETag are the two primary validators used by HTTP. Table 15-4 lists four of the HTTP headers used for conditional requests. Next to each conditional header is the type of validator used with the header.
-
If-Modified-Since조건부 헤더는 문서 인스턴스의 최종 변경 일시를 확인하므로 최종 변경 일시를 Validator로 간주합니다. -
If-None-Match조건부 헤더는 문서의 ETag 값을 확인합니다. -
ETag는 엔티티에 연결된 특수한 키워드나 버전 식별 태그입니다.
-
Last-Modified와ETag는 HTTP에서 사용되는 두 가지 주요한 Validator입니다. -
Table 15-4는 조건부 요청에 사용되는 4가지 HTTP 헤더를 나열하고 있습니다.
-
각각의 조건부 헤더 옆에는 헤더와 함께 사용되는 Validator의 타입이 옵니다.

HTTP groups validators into two classes: weak validators and strong validators. Weak validators may not always uniquely identify an instance of a resource; strong validators must. An example of a weak validator is the size of the object in bytes. The resource content might change even thought the size remains the same, so a hypothetical byte-count validator only weakly indicates a change. A cryptographic checksum of the contents of the resource (such as MD5), however, is a strong validator; it changes when the document changes.
-
HTTP는 Validator를 Weak Validator, Strong Validator 두 종류로 그룹화합니다.
-
Weak Validator는 리소스의 인스턴스를 고유하게 식별하지 않을 수도 있는 반면 Strong Validator는 항상 인스턴스를 고유하게 식별합니다.
-
Weak Validator의 예시로는 바이트로 표현한 오브젝트의 크기가 있습니다.
-
리소스 콘텐츠가 동일한 크기를 유지하면서 변경될 수도 있다는 점에서 가상의 바이트 연산 Validator는 변경을 약하게 표시합니다.
-
하지만 암호학에서 MD5와 같은 콘텐츠의 체크섬은 Strong Validator에 해당합니다.
-
체크섬의 값은 문서가 변경되었을 때만 달라지기 때문입니다.
The last-modified time is considered a weak validator because, although it specifies the time at which the resource was last modified, it specifies that time to an accuracy of at most one second. Because a resource can change multiple times in a second, and because servers can serve thousands of requests per second, the last-modified date might not always reflect changes. The ETag header is considered a strong validator, because the server can place a distinct value in the ETag header every time a value changes. Version numbers and digest checksums are good candidates for the ETag header, but they can contain any arbitrary text. ETag headers are flexible; they take arbitrary text values (“tags”), and can be used to devise a variety of client and server validation strategies.
-
최종 변경 시각은 아무리 리소스가 마지막에 수정된 시각을 초 단위로 지정한다고 하더라도 Weak Validator로 여겨집니다.
-
리소스가 1초 내에 여러 차례 수정되었을 가능성이 있고, 서버 또한 1초 내에 수천 개의 요청을 발행할 수 있기 때문에 최종 변경 시각이 항상 모든 변경사항을 반영할 수는 없습니다.
-
ETag 헤더는 Strong Validator로 여겨집니다.
-
값이 변화할 때마다 서버는 ETag 헤더에 서로 다른 값을 지정합니다.
-
버전 번호와 다이제스트 체크섬이 ETag 헤더에 적합한 후보지만, 임의의 텍스트가 ETag 헤더에 포함될 수도 있습니다.
-
ETag 헤더는 유동적입니다.
-
임의의 텍스트 값을 사용하며, 다양한 클라이언트와 서버의 검증 전략을 고안하는 데 사용될 수 있습니다.
Clients and servers may sometimes want to adopt a looser version of entity-tag validation. For example, a server may want to make cosmetic changes to a large, popular cached document without triggering a mass transfer when caches revalidate. In this case, the server might advertise a “weak” entity tag by prefixing the tag with “W/”. A weak entity tag should change only when the associated entity changes in a semantically significant way. A strong entity tag must change whenever the associated entity value changes in any way.
-
클라이언트와 서버는 Entity-tag 검증을 더 느슨하게 하기를 원할 수도 있습니다.
-
예를 들어 서버는 거대하고 인기 있는 캐싱 문서에 외관상 미미한 차이가 발생했을 때 캐시의 재검증 요청으로 인해 막대한 전송량을 유발하지 않기를 바랍니다.
-
이런 경우 서버는 태그 앞에 "W/" 접두사를 붙여 "약한" 엔티티 태그임을 알릴 수 있습니다.
-
약한 엔티티 태그는 연관된 엔티티가 의미적으로 중요한 변경사항이 발생했을 때만 변화해야 합니다.
-
강한 엔티티 태그는 연관된 엔티티 값이 변경될 때마다 바뀌어야 합니다.
The following example shows how a client might revalidate with a server using a weak entity tag. The server would return a body only if the content changed in a meaningful way from Version 4.0 of the document:
GET /announce.html HTTP/1.1 If-None-Match: W/"v4.0"
-
위의 구문은 클라이언트가 약한 엔티티 태그를 사용하여 서버에 재검증을 수행하도록 요청하는 예시입니다.
-
서버는 Version 4.0 이후로 콘텐츠에 유의한 변화가 발생했을 때만 본문을 반환합니다.
In summary, when clients access the same resource more than once, they first need to determine whether their current copy still is fresh. If it is not, they must get the latest version from the server. To avoid receiving an identical copy in the event that the resource has not changed, clients can send conditional requests to the server, specifying validators that uniquely identify their current copies. Servers will then send a copy of the resource only if it is different from the client’s copy. For more details on cache revalidation, please refer back to “Cache Processing Steps” in Chapter 7.
-
요약하자면 클라이언트는 동일한 리소스에 한 번 이상 접근할 때 현재 보유하고 있는 사본이 여전히 최신의 것인지 결정해야 합니다.
-
그렇지 않다면 서버로부터 가장 최신 버전을 받아와야 합니다.
-
서버측에서 리소스의 변경이 발생하지 않아 동일한 사본을 받아오는 것을 방지하기 위하여 클라이언트는 서버에 조건부 요청을 전송할 수 있습니다.
-
조건부 요청에는 현재 사본을 고유하게 식별할 수 있는 Validator를 지정합니다.
-
서버는 보유중인 리소스가 클라이언트의 사본과 일치하지 않는 경우에만 리소스의 사본을 전송할 것입니다.
-
캐시 재검증에 대한 자세한 내용은 Chapter 7의 "Cache Processing Steps"를 확인하여 주시기 바랍니다.
Range Requests
We now understand how a client can ask a server to send it a resource only if the client’s copy of the resource is no longer valid. HTTP goes further: it allows clients to actually request just part or a range of a document.
-
이제 클라이언트가 가진 리소스의 사본이 더 이상 유효하지 않을 때만 서버에게 리소스를 요청하는 방식을 이해했습니다.
-
HTTP는 더 나아가 클라이언트가 문서의 일부분 혹은 특정 범위에 대해서만 요청할 수 있도록 지원하고 있습니다.
Imagine if you were three-fourths of the way through downloading the latest hot software across a slow modem link, and a network glitch interrupted your connection. You would have been waiting for a while for the download to complete, and now you would have to start all over again, hoping the same thing does not happen again.
-
갓 출시된 따끈따끈한 소프트웨어를 아주 느린 모뎀 연결을 통해서 75% 정도 다운로드 받았을 무렵 네트워크 결함으로 인해 연결이 중단되었다고 생각해봅시다.
-
여러분은 다운로드가 완료되기를 한참 기다렸다가, 똑같은 상황이 발생하지 않기를 기도하면서 계속해서 다운로드 버튼을 누를 것입니다.
With range requests, an HTTP client can resume downloading an entity by asking for the range or part of the entity it failed to get (provided that the object did not change at the origin server between the time the client first requested it and its subsequent range request). For example:
GET /bigfile.html HTTP/1.1 Host: www.joes-hardware.com Range: bytes=4000- User-Agent: Mozilla/4.61 [en] (WinNT; I) ...
-
범위 요청을 사용하는 HTTP 클라이언트는 다운로드에 실패한 엔티티의 일부분을 다시 요청함으로써 엔티티의 다운로드를 재개할 수 있습니다.
-
클라이언트가 처음 요청을 받은 시점부터 추가적인 범위 요청이 이루어지는 시간 동안 원본 서버에서 오브젝트가 변경되지 않았다는 것을 전제합니다.
-
범위 요청은 다음과 같이 전송할 수 있습니다.
GET /bigfile.html HTTP/1.1 Host: www.joes-hardware.com Range: bytes=4000- User-Agent: Mozilla/4.61 [en] (WinNT; I) ...
In this example, the client is requesting the remainder of the document after the first 4,000 bytes (the end bytes do not have to be specified, because the size of the document may not be known to the requestor). Range requests of this form can be used for a failed request where the client received the first 4,000 bytes before the failure. The Range header also can be used to request multiple ranges (the ranges can be specified in any order and may overlap)—for example, imagine a client connecting to multiple servers simultaneously, requesting different ranges of the same document from different servers in order to speed up overall download time for the document. In the case where clients request multiple ranges in a single request, responses come back as a single entity, with a multipart body and a Content-Type: multipart/byteranges header.
-
해당 예시에서 클라이언트는 처음 4000 바이트 이후로 문서의 나머지 부분에 대해 요청하고 있습니다.
-
요청자가 문서의 크기가 얼마인지 정확히 알 수 없는 경우도 있으므로 종료 바이트를 반드시 지정할 필요는 없습니다.
-
이러한 형태의 범위 요청은 클라이언트가 처음 4000바이트를 받고 난 후 실패한 요청에 대해 사용될 수 있습니다.
-
또한 Range 헤더는 여러 개의 요청 범위에 대해 사용될 수 있습니다.
-
각 범위의 순서는 상관이 없으며 범위가 겹칠 수도 있습니다.
-
여러 서버에 동시에 연결되어 있는 클라이언트가 문서의 전체 다운로드 시간을 최적화하기 위해 서로 다른 서버로부터 서로 다른 범위의 동일 문서를 요청한다고 가정해봅시다.
-
클라이언트가 하나의 요청에 여러 개의 범위를 요청하는 경우 응답은 multipart 본문과
Content-Type: multipart/byteranges헤더를 가진 하나의 엔티티로 반환되어야 합니다.
Not all servers accept range requests, but many do. Servers can advertise to clients that they accept ranges by including the header Accept-Ranges in their responses. The value of this header is the unit of measure, usually bytes.* For example:
HTTP/1.1 200 OK Date: Fri, 05 Nov 1999 22:35:15 GMT Server: Apache/1.2.4 Accept-Ranges: bytes ...
-
모든 서버가 범위 요청을 허용하지는 않지만 대부분 허용하는 경향이 있습니다.
-
서버는 응답에
Accept-Ranges헤더를 포함하여 범위 요청의 허용 여부를 클라이언트에게 전달해야 합니다. -
이 헤더의 값은 측정 단위이며 일반적으로 bytes(바이트)가 사용됩니다.
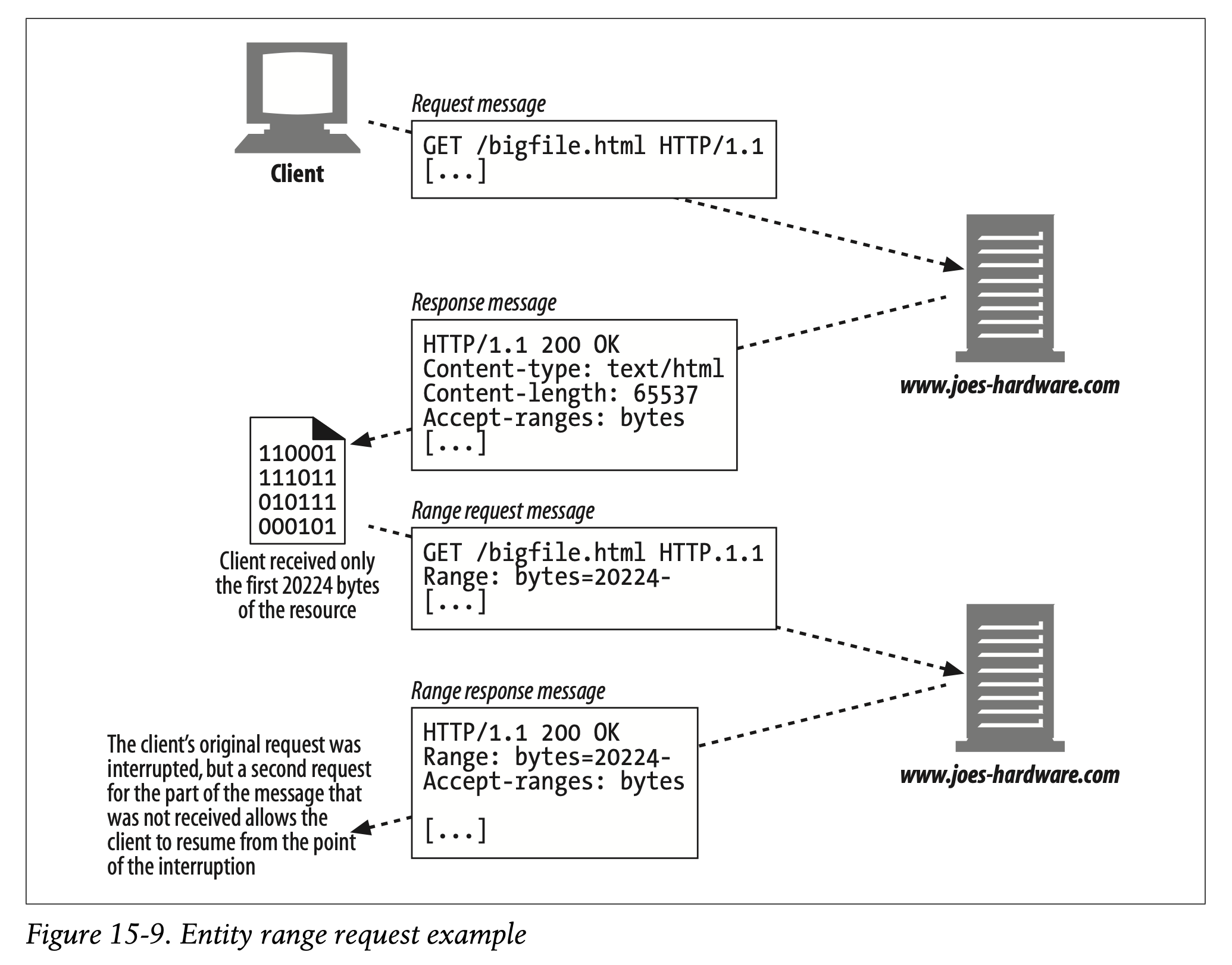
Figure 15-9 shows an example of a set of HTTP transactions involving ranges.
- Figure 15-9는 범위를 포함하는 HTTP 트랜잭션 집합의 예시를 나타냅니다.
Range headers are used extensively by popular peer-to-peer file-sharing client software to download different parts of multimedia files simultaneously, from different peers.
-
Range 헤더는 P2P 파일 공유 클라이언트 소프트웨어에서 널리 사용됩니다.
-
해당 소프트웨어는 멀티미디어 파일의 서로 다른 부분을 다양한 Peer로부터 동시에 다운로드 받을 수 있도록 지원합니다.
Note that range requests are a class of instance manipulations, because they are exchanges between a client and a server for a particular instance of an object. That is, a client’s range request makes sense only if the client and server have the same version of a document.
-
범위 요청은 클라이언트와 서버 사이에서 특정 오브젝트의 인스턴스를 교환한다는 점에서 Instance Manipulation의 일종이라는 점을 다시 한 번 강조합니다.
-
즉, 클라이언트의 범위 요청은 클라이언트와 서버가 동일한 버전의 문서를 보유하고 있을 때에만 올바르게 이루어질 수 있습니다.
✏️ 요약
HTTP Validator
: 인스턴스의 변경을 감지하기 위한 검증 요소
- Weak Validator : 변경을 일부 허용하면서 엔티티 검증을 느슨하게 수행
- 오브젝트의 크기 : 리소스 콘텐츠가 동일한 크기를 유지하면서 변경될 수 있다 (<-> 체크섬은 Strong Validator, 전송중 엔티티가 변경되지 않았음을 보장)
Last-Modified: 밀리초 단위로 수정되었을 가능성이 있다 & 서버가 밀리초 단위로 수천 개의 요청을 발행할 가능성이 있다
- Strong Validator : 변경을 허용하지 않으면서 엔티티 검증을 엄격하게 수행
ETag: 값이 변화할 때마다 서버가 서로 다른 ETag 값을 할당한다
Conditional Request Types
: Validator에 따른 클라이언트의 조건부 요청 유형
If-Modified-Since:Last-Modifed헤더를 Validator로 사용 -> 리소스가 마지막으로 변경된 시점 이후로 변경이 발생한 경우 리소스 요청 (Weak Validator)If-Unmodified-Since:Last-Modifed헤더를 Validator로 사용 -> 리소스가 마지막으로 변경된 시점과 이전 응답의 Last-Modified 헤더 값이 일치하는 경우에만 리소스 요청If-Match:ETag헤더를 Validator로 사용 -> 문서의 ETag 값이 일치하는 경우 리소스 요청 (Strong Validator)If-None-Match:ETag헤더를 Validator로 사용 -> 문서의 ETag 값이 일치하지 않는 경우 리소스 요청 (Strong Validator)
** Entity Tag- Weak Entity Tag : 엔티티에 유의한 변경이 있을 때만 새롭게 부여
If-None-Match: W/"v4.0" - Strong Entity Tag : 엔티티 값이 변경될 때마다 새롭게 부여
If-None-Match: "v4.0"
- Weak Entity Tag : 엔티티에 유의한 변경이 있을 때만 새롭게 부여
Range Requests
: 리소스의 특정 범위에 대해 요청하는 것
- 서버 > 클라이언트 범위 요청 허용 여부 전달 :
Accept-Ranges헤더 사용HTTP/1.1 200 OK Date: Fri, 05 Nov 1999 22:35:15 GMT Server: Apache/1.2.4 Accept-Ranges: bytes ... - 요청 :
Range헤더를 통해 범위 명시 (여러 범위 가능)GET /bigfile.html HTTP/1.1 Host: www.joes-hardware.com Range: Range: byte=-100, byte=101-200 ... - 응답 : 여러 범위에 대해 요청이 온 경우
Content-Type: multipart/byteranges헤더를 가진 하나의 엔티티로 반환 - 활용
- 다운로드 재개 : 다운로드가 중단되었을 때 엔티티 일부분을 다시 요청
- 병렬 다운로드 : 여러 서버에 서로 다른 범위를 요청하여 속도 최적화
✏️ 감상
범위 요청을 통한 동영상 스트리밍
Range Request 섹션을 읽으면서 Transfer Encoding과 Range Request를 적절히 활용하면 (클라이언트 입장에서) 무한한 동영상 스트림을 빠른 속도로 전달할 수 있을 것 같다는 생각이 들었다. 물론.. 단순히 빠른 전송이 목적이라면 TCP 기반의 HTTP/1.1 프로토콜을 굳이굳이 쓸 필요는 없다고 생각한다. UDP 기반의 응용 계층 프로토콜 중에 더 나은 선택지가 있을 것이다.
하지만 이미 서버에 저장된 비디오를 조회하는 기능을 구현한다고 가정해보면, Range Request를 통해 여러 개의 분산된 서버로부터 일정 바이트 단위로 데이터를 불러오는 것이 더 나을 수도 있겠다는 생각이 든다. 유튜브를 볼 때 동영상이 버퍼링에 안 걸리는 것도 중요하지만, 봤던 부분을 다시 돌려 볼 수 있게 하는 것도 중요하다. Range Request는 이런 요구사항을 해결할 수 있는 강력한 도구다.
지금 내가 읽고 있는 책은 HTTP/1.1이지만 그 사이에 세상이 많이 달라져서(?) 최근에는 HTTP/3도 자주 사용되는 것으로 알고 있다. HTTP/3는 TCP를 걷어냈기 때문에 버퍼링 문제를 해결하면서, 기본적으로 HTTP 기반이기 때문에 범위 요청으로 동영상 스트림을 불러올 수 있다. 이 프로토콜은 진짜 개쩌는 친구다. 내가 동영상 스트리밍 기능을 포함하는 소프트웨어를 개발할 일이 있다면 HTTP/3에 딥다이브 해볼 의향이 있다.
찾아보니 Spring 프레임워크에서도 범위 요청을 처리할 수 있는 클래스가 제공되고 있다고 한다. 개발자가 직접 헤더를 추출한 후 범위에 따라 분기시켜서 콘텐츠를 전송할 수도 있고, FileSystemResource 과 같은 클래스를 통해 범위 요청을 자동으로 처리할 수도 있다. FileSystemResource 객체를 반환하는 경우 개발자가 관여할 필요없이 알아서 Range 헤더가 처리되고, 헤더의 유무에 따라 200이나 206 응답을 생성한다.
