
Chapter 16. Internationalization
(해석 또는 이해가 잘못된 부분이 있다면 댓글로 편하게 알려주세요.)
✏️ 원문 번역
Content-Type Charset Header and META Tags
Web servers send the client the MIME charset tag in the Content-Type header, using the charset parameter:
Content-Type: text/html; charset=iso-2022-jp
- 웹 서버는 Content-Type 헤더의 charset 파라미터에 MIME charset 태그를 실어 클라이언트에게 전송합니다.
If no charset is explicitly listed, the receiver may try to infer the character set from the document contents. For HTML content, character sets might be found in
<META HTTP-EQUIV="Content-Type">tags that describe the charset.
-
charset이 명시되지 않으면 수신자가 문서 콘텐츠로부터 문자 집합을 추론할 수 있습니다.
-
HTML 콘텐츠의 경우
<META HTTP-EQUIV="Content-Type">태그에서 명시된 문자 집합을 발견할 수 있습니다.
Example 16-1 shows how HTML META tags set the charset to the Japanese encoding iso-2022-jp. If the document is not HTML, or there is no META Content-Type tag, software may attempt to infer the character encoding by scanning the actual text for common patterns indicative of languages and encodings.
-
Example 16-1은 HTML META 태그가 iso-2022-jp 인코딩된 일본어로 charset을 설정하는 과정을 나타냅니다.
-
문서가 HTML이 아니거나 META Content-Type 태그가 없다면 소프트웨어는 실제 텍스트를 스캔하여 인코딩 방식을 추론할 수 있습니다.
-
텍스트를 스캔한다는 것은 언어와 인코딩의 일반적인 패턴을 찾아낸다는 걸 의미합니다.

If a client cannot infer a character encoding, it assumes iso-8859-1.
- 클라이언트가 문자 인코딩을 추론할 수 없는 경우 iso-8859-1로 가정합니다.
The Accept-Charset Header
There are thousands of defined character encoding and decoding methods, developed over the past several decades. Most clients do not support all the various character coding and mapping systems.
-
지난 몇십 년간 개발된 문자 인코딩 및 디코딩 방식은 수천 가지가 넘습니다.
-
때문에 대부분의 클라이언트가 모든 종류의 문자 인코딩과 매핑 시스템을 지원하지 않습니다.
HTTP clients can tell servers precisely which character systems they support, using the Accept-Charset request header. The Accept-Charset header value provides a list of character encoding schemes that the client supports. For example, the following HTTP request header indicates that a client accepts the Western European iso-8859-1 character system as well as the UTF-8 variable-length Unicode compatibility system. A server is free to return content in either of these character encoding schemes.
Accept-Charset: iso-8859-1, utf-8
-
HTTP 클라이언트는 Accept-Charset 요청 헤더를 사용하여 서버에게 어떤 문자 시스템을 지원하는지 명확히 전달해야 합니다.
-
Accept-Charset 헤더값은 클라이언트가 지원하는 문자 인코딩 기법을 나열합니다.
-
예를 들어 다음의 HTTP 요청 헤더는 클라이언트가 서유럽 iso-8859-1 문자 시스템과 UTF-8 가변길이 유니코드 호환 시스템을 사용할 수 있음을 나타냅니다.
Accept-Charset: iso-8859-1, utf-8 -
서버는 두 가지 인코딩 기법 중 하나를 선택하여 콘텐츠를 반환하면 됩니다.
Note that there is no Content-Charset response header to match the Accept-Charset request header. The response character set is carried back from the server by the charset parameter of the Content-Type response header, to be compatible with MIME. It’s too bad this isn’t symmetric, but all the information still is there.
-
Accept-Charset 요청 헤더에 대응하는 Content-Charset 응답 헤더는 존재하지 않습니다.
-
응답 문자 집합은 Content-Type 응답 헤더의 charset 파라미터로 반환됩니다. 파라미터의 값은 MIME과 호환됩니다.
-
헤더가 대칭적이지 않은 건 아쉽지만 어쨌든 모든 정보는 주고받고 있습니다.
Multilingual Character Encoding Primer
The previous section described how the HTTP Accept-Charset header and the Content-Type charset parameter carry character-encoding information from the client and server. HTTP programmers who do a lot of work with international applications and content need to have a deeper understanding of multilingual character systems to understand technical specifications and properly implement software.
-
이전 섹션에서는 HTTP Accept-Charset 헤더와 Content-Type charset 파라미터를 통해 클라이언트에서 서버로 문자 인코딩 정보를 전달하는 방법에 대해 알아보았습니다.
-
전세계적으로 사용되는 애플리케이션과 콘텐츠를 개발하는 HTTP 프로그래머는 다중 문자 시스템에 대한 깊은 이해가 필요합니다.
-
기술 명세를 이해하고 소프트웨어를 적절히 구현하기 위함입니다.
It isn’t easy to learn multilingual character systems—the terminology is complex and inconsistent, you often have to pay to read the standards documents, and you may be unfamiliar with the other languages with which you’re working. This section is an overview of character systems and standards. If you are already comfortable with character encodings, or are not interested in this detail, feel free to jump ahead to “Language Tags and HTTP.”
-
다중 문자 시스템을 학습하는 것은 쉬운 일이 아닙니다.
-
용어는 복잡하고 일관성이 없으며 종종 표준 문서를 구매해서 들여다봐야 하는 일도 생깁니다. 심지어 작업 중인 다른 언어에 익숙하지 않을 수도 있습니다.
-
이번 섹션에서는 문자 시스템과 표준을 간단히 살펴보겠습니다.
-
문자 인코딩에 이미 친숙하거나 구체적인 내용에 큰 흥미가 없다면 "Language Tags and HTTP"로 건너뛰어도 좋습니다.
Character Set Terminology
Here are eight terms about electronic character systems that you should know:
- 전자 문자 시스템을 이해하기 위해 반드시 알아야 할 여덟 가지 용어가 있습니다.
Character
An alphabetic letter, numeral, punctuation mark, ideogram(as in Chinese), symbol, or other textual “atom” of writing. The Universal Character Set (UCS) initiative, known informally as Unicode,* has developed a standardized set of textual names for many characters in many languages, which often are used to conveniently and uniquely name characters.
Character
-
알파벳, 숫자, 구두점, 표의문자, 기호 또는 기타 텍스트의 기본 단위를 의미합니다.
-
유니코드로 널리 알려진 UCS(Universal Character Set)는 다양한 언어의 다양한 문자에 대하여 표준화된 텍스트를 명명한 집합을 개발하였습니다.
-
유니코드는 문자를 고유하게 명명하는 데 편리하게 사용될 수 있습니다.
Glyph
A stroke pattern or unique graphical shape that describes a character. A character may have multiple glyphs if it can be written different ways (see Figure 16-3).
Glyph
-
문자를 표현하는 스트로크 패턴이나 고유한 그래픽 형태를 의미합니다.
-
한 문자가 여러 가지 방식으로 쓰일 수 있다면 여러 개의 glyph를 가질 수 있습니다. (Figure 16-3 참조)
Coded character
A unique number assigned to a character so that we can work with it.
Coded character
- 문자에 부여된 고유한 번호입니다.
Coding space
A range of integers that we plan to use as character code values.
Coding space
- 문자 코드의 값이 사용하도록 지정된 정수 범위입니다.
Code width
The number of bits in each (fixed-size) character code.
Code width
- 각각의 (고정 사이즈) 문자 코드의 비트 개수입니다.
Character repertoire
A particular working set of characters (a subset of all the characters in the world).
Character repertoire
- 특정 문자 집합(전세계의 모든 문자들의 부분집합)입니다.
Coded character set
A set of coded characters that takes a character repertoire (a selection of characters from around the world) and assigns each character a code from a coding space. In other words, it maps numeric character codes to real characters.
Coded character set
-
Coded Character의 집합으로, Character Repertoire의 모든 문자에 대해 Coding Space 내에서 각각을 할당합니다.
-
한마디로 숫자로 된 문자 코드를 실제 문자에 매핑한 것입니다.
Character encoding scheme
An algorithm to encode numeric character codes into a sequence of content bits(and to decode them back). Character encoding schemes can be used to reduce the amount of data required to identify characters (compression), work around transmission restrictions, and unify overlapping coded character sets.
Character encoding scheme
-
숫자로 된 문자 코드를 콘텐츠 비트로 인코딩 및 디코딩하는 알고리즘입니다.
-
문자를 식별하는 데 사용되는 데이터량을 줄이기 위해(=압축), 전송 제한을 우회하기 위해, 중복된 Coded Character Set을 통합하기 위해 문자 인코딩 기법이 적용될 수 있습니다.
Charset Is Poorly Named
Technically, the MIME charset tag (used in the Content-Type charset parameter and the Accept-Charset header) doesn’t specify a character set at all. The MIME charset value names a total algorithm for mapping data bits to codes to unique characters. It combines the two separate concepts of character encoding scheme and coded character set (see Figure 16-2).
-
Content-Type charset 파라미터와 Accept-Charset 헤더에서 사용되는 MIME charset 태그는 기술적으로 문자 집합을 전혀 특정하지 않습니다.
-
MIME charset 값은 데이터 비트를 코드로, 특정 문자로 매핑하기 위한 알고리즘을 명명할 뿐입니다.
-
즉 MIME charset 태그는 문자 인코딩 기법과 Coded Character Set이라는 서로 다른 개념을 하나로 통합한 개념입니다. (Figure 16-2 참조)
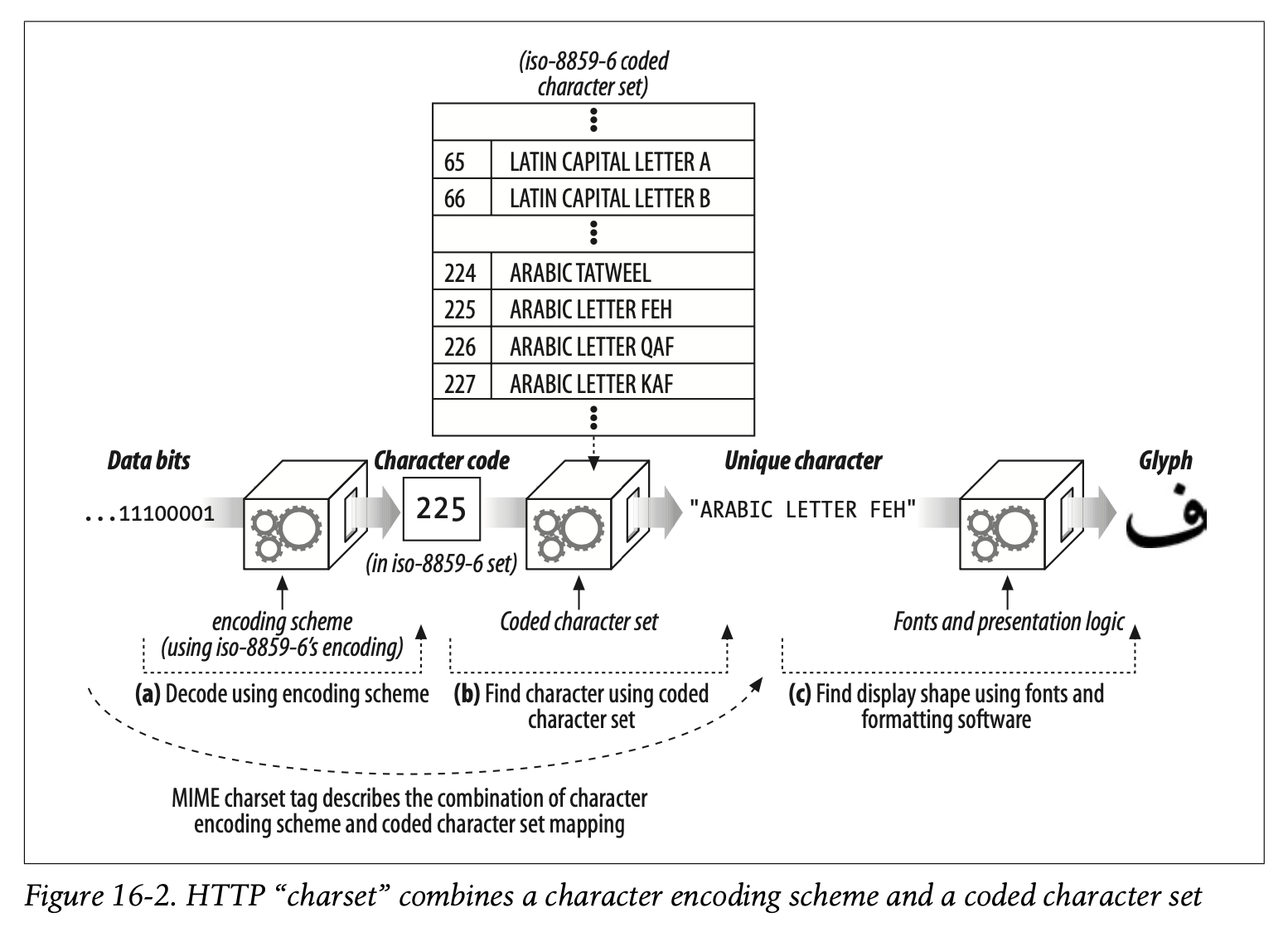
This terminology is sloppy and confusing, because there already are published standards for character encoding schemes and for coded character sets. Here’s what the HTTP/1.1 authors say about their use of terminology (in RFC 2616):
-
문자 인코딩 기법과 Coded Character Set에 대한 표준이 이미 존재하기 때문에 이러한 용어는 부주의하고 혼란스럽습니다.
-
HTTP/1.1의 개발자는 RFC 2616에서 해당 용어의 사용에 대해 다음과 같이 이야기합니다.
The term “character set” is used in this document to refer to a method ... to convert a sequence of octets into a sequence of characters... Note: This use of the term “character set” is more commonly referred to as a “character encoding.” However, since HTTP and MIME share the same registry, it’s important that the terminology also be shared.
-
해당 문서에서 "character set"이라는 용어는 옥텟 비트를 문자 시퀀스로 변환하는 방법을 나타내기 위해 사용되었습니다.
-
"character set"이라는 용어는 일반적으로 "문자 인코딩"을 나타냅니다.
-
그러나 HTTP와 MIME이 동일한 레지스트리를 공유하기 때문에 용어 역시 공유되어야 합니다.
The IETF also adopts nonstandard terminology in RFC 2277:
- IETF 또한 RFC 2277에서 비표준 용어를 채택하고 있습니다.
This document uses the term “charset” to mean a set of rules for mapping from a sequence of octets to a sequence of characters, such as the combination of a coded character set and a character encoding scheme; this is also what is used as an identifier in MIME “charset=” parameters, and registered in the IANA charset registry. (Note that this is NOT a term used by other standards bodies, such as ISO).
-
이 문서는 Coded Character Set과 문자 인코딩 기법을 결합하는 것과 같이 옥텟 시퀀스를 문자 시퀀스로 매핑하기 위한 규칙 집합으로 "charset"이라는 용어를 사용합니다.
-
여기서 이야기하는 charset은 MIME의 "charset=" 파라미터에서 식별자로 사용되는 것과 동일합니다. 이 값은 IANA 문자 집합 레지스트리에 등록되어 있습니다.
-
ISO와 같은 다른 표준에서 사용되는 용어와 일치하지 않음에 유의 바랍니다.
So, be careful when reading standards documents, so you know exactly what’s being defined. Now that we’ve got the terminology sorted out, let’s look a bit more closely at characters, glyphs, character sets, and character encodings.
-
표준 문서를 읽을 때는 정의된 바를 명확히 이해할 수 있도록 주의하시기 바랍니다.
-
필요한 용어들을 살펴보았으니 이제 문자와 Glyph, 문자 집합, 문자 인코딩에 대해 더 상세히 들여다봅시다.
✏️ 요약
HTTP를 통해 문자 인코딩 정보를 전달하는 방법
- 클라이언트 : Accept-Charset 헤더를 통해 지원되는 charset 명시
Accept-Charset: iso-8859-1, utf-8 - 서버 : Content-Type 헤더를 통해 리소스의 charset 명시
Content-Type: text/html; charset=utf-8- charset이 명시된 경우 클라이언트는 명시된 charset으로 디코딩
- charset이 명시되지 않은 html 문서의 경우 META Content-Type 태그 확인
- charset을 알 수 없는 경우 iso-8859-1로 디코딩
Character Set 용어 정리
- Glyph : 문자를 표현하는 패턴이나 그래픽 형태 -> 문자의 표현 방식이 여러 가지라면 Glyph도 여러 가지
- Coded character : 문자에 부여된 고유한 코드
- Coding space : 문자 코드가 사용 가능한 정수 범위
- Code width : 문자 코드의 (고정된) 비트 개수
- Character repertoire : 문자 집합 (모든 문자의 부분집합)
- Coded character set : 문자 집합의 모든 문자에 코드를 매핑한 집합
- Character encoding scheme : 문자 코드를 비트 시퀀스로 인코딩하는 알고리즘
** HTTP에서 이야기하는 charset은 Coded Character Set과 Character Encoding Scheme을 결합한 개념이다
✏️ 코멘트
돌아왔습니다...ㅋㅋㅋ
6개월 동안 자격증도 좀 따고 인턴도 하고 졸업논문도 쓰면서 그렇게 살고 있었습니다.
인턴 기간도 끝나고 졸업요건도 다 채우고 났더니, 지금은 뭔가 붕 떠 있는 기분이네요.
이왕 붕 떠버린 김에 읽고 싶었던 책도 읽고 여행도 다니려고 하고 있습니다.
HTTP 책도 슬슬 갈무리 할 때가 오지 않았을까요. 분량을 조금 늘려서라도 2월까지 한 번 후딱 읽어보겠습니다.
