
github url
https://github.com/BaekGeunYoung/multi_thread_practice
Focus
멀티스레드 환경을 설정하고, 이를 이용해 빠르게 작업을 수행하는 코드를 작성해본다. 더불어 멀티스레드를 사용하지 않는 일반적인 코드와 수행시간을 비교해 본다.
reference : https://dzone.com/articles/multi-threading-in-spring-boot-using-completablefu
AsyncConfiguration
멀티스레드를 이용한 비동기 작업 처리 관련 설정 파일을 만들어야 한다.
@Configuration
@EnableAsync
class AsyncConfiguration {
private val LOGGER: Logger = LoggerFactory.getLogger(AsyncConfiguration::class.java)
@Bean
fun taskExecutor(): Executor {
LOGGER.debug("Creating Async Task Executor")
val executor = ThreadPoolTaskExecutor()
executor.corePoolSize = 4
executor.maxPoolSize = 4
executor.setQueueCapacity(100)
executor.setThreadNamePrefix("CarThread-")
executor.initialize()
return executor
}
}@EnableAsync annotation을 통해 async job을 enable할 수 있고, taskExecutor 함수 내에서
스레드 관련 세부 설정을 할 수 있다.
Service
@Async
open fun saveCarsAsync(file: MultipartFile): CompletableFuture<List<Car>> {
val startTime = System.currentTimeMillis()
val cars = parseCSVFile(file)
LOGGER.info("Saving a list of cars of size ${cars.size}")
val savedCars = carRepository.saveAll(cars)
LOGGER.info("Elapsed Time : ${System.currentTimeMillis() - startTime}ms")
return CompletableFuture.completedFuture(savedCars)
}
fun saveCars(file: MultipartFile): List<Car> {
val startTime = System.currentTimeMillis()
val cars = parseCSVFile(file)
LOGGER.info("Saving a list of cars of size ${cars.size}")
val savedCars = carRepository.saveAll(cars)
LOGGER.info("Elapsed Time : ${System.currentTimeMillis() - startTime}ms")
return savedCars
}@Async annotation이 붙어있는 saveCarsAsync 함수는 멀티스레드 환경에서 비동기적으로 작업을 수행한다.
그리고 CompletableFuture 객체를 return 값으로 설정함으로써 요청해놓은 비동기 작업이 완료되면 이를 리턴하는 방식을 사용한다.
Controller
@PostMapping("/")
fun uploadFile(@RequestParam(value = "files") files: Array<MultipartFile>): ResponseEntity<Unit> {
return try {
for(file in files) {
carService.saveCars(file)
}
ResponseEntity.status(HttpStatus.CREATED).build()
} catch (e: Exception) {
ResponseEntity.status(HttpStatus.INTERNAL_SERVER_ERROR).build()
}
}controller 코드는 별 거 없다. 여러개의 file을 request parameter로 받고, 이를 for문을 돌려
하나씩 saveCars로 넘겨준다. 그리고 요청이 완료되면 CREATED status로 response를 날려준다.
Comparison: Async vs Sync
1. Performance
request를 받아 작업을 처리하고 response를 돌려줄 때 까지 걸리는 시간을 비교해보았다.

(sync 방식의 elapsed time)

(async 방식의 elapsed time)
당연한 얘기겠지만, async 방식이 더 빠른 시간 내에 작업을 처리하는 것을 확인할 수 있었다.
2. Process
두 방식이 작업을 처리하는 과정이 어떻게 다른지 비교해보았다.
async
2019-12-02 17:40:57.141 INFO 26028 --- [ CarThread-4] c.s.m.service.CarService : Saving a list of cars of size 110
2019-12-02 17:40:57.141 INFO 26028 --- [ CarThread-3] c.s.m.service.CarService : Saving a list of cars of size 121
2019-12-02 17:40:57.141 INFO 26028 --- [ CarThread-2] c.s.m.service.CarService : Saving a list of cars of size 121
2019-12-02 17:40:57.142 INFO 26028 --- [ CarThread-1] c.s.m.service.CarService : Saving a list of cars of size 108
2019-12-02 17:40:57.247 INFO 26028 --- [ CarThread-4] c.s.m.service.CarService : Elapsed Time : 107ms
2019-12-02 17:40:57.247 INFO 26028 --- [ CarThread-2] c.s.m.service.CarService : Elapsed Time : 107ms
2019-12-02 17:40:57.247 INFO 26028 --- [ CarThread-1] c.s.m.service.CarService : Elapsed Time : 107ms
2019-12-02 17:40:57.252 INFO 26028 --- [ CarThread-3] c.s.m.service.CarService : Elapsed Time : 112mssync
2019-12-02 17:43:27.400 INFO 8368 --- [nio-8080-exec-2] c.s.m.service.CarService : Saving a list of cars of size 108
2019-12-02 17:43:27.486 INFO 8368 --- [nio-8080-exec-2] c.s.m.service.CarService : Elapsed Time : 87ms
2019-12-02 17:43:27.487 INFO 8368 --- [nio-8080-exec-2] c.s.m.service.CarService : Saving a list of cars of size 121
2019-12-02 17:43:27.515 INFO 8368 --- [nio-8080-exec-2] c.s.m.service.CarService : Elapsed Time : 28ms
2019-12-02 17:43:27.516 INFO 8368 --- [nio-8080-exec-2] c.s.m.service.CarService : Saving a list of cars of size 121
2019-12-02 17:43:27.539 INFO 8368 --- [nio-8080-exec-2] c.s.m.service.CarService : Elapsed Time : 24ms
2019-12-02 17:43:27.540 INFO 8368 --- [nio-8080-exec-2] c.s.m.service.CarService : Saving a list of cars of size 110
2019-12-02 17:43:27.559 INFO 8368 --- [nio-8080-exec-2] c.s.m.service.CarService : Elapsed Time : 19msmulti thread async 방식은 작업이 들어오는 대로 빈 스레드에 작업을 할당하고, 각 스레드에 들어간 작업들이 서로 독립적으로 수행, 완료되는 것을 확인할 수 있다.
반면 기존의 방식은 작업을 순차적으로 하나씩 할당하고, 완료하고 하는 식의 과정이 반복된다.
3. DB
두 방식에 따라 DB에 데이터가 어떻게 저장되는지 비교해보았다.
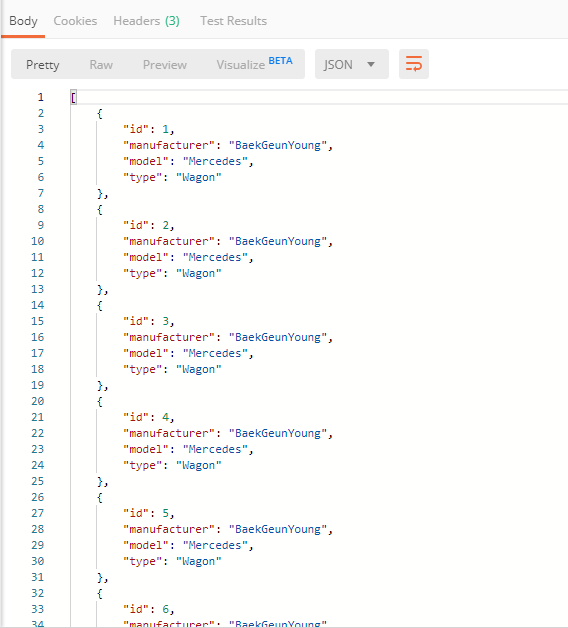
file을 하나씩 차례로 읽어 작업을 수행하므로 데이터에 저장되는 순서 또한 input으로 넣어준 파일의 순서와 일치한다.
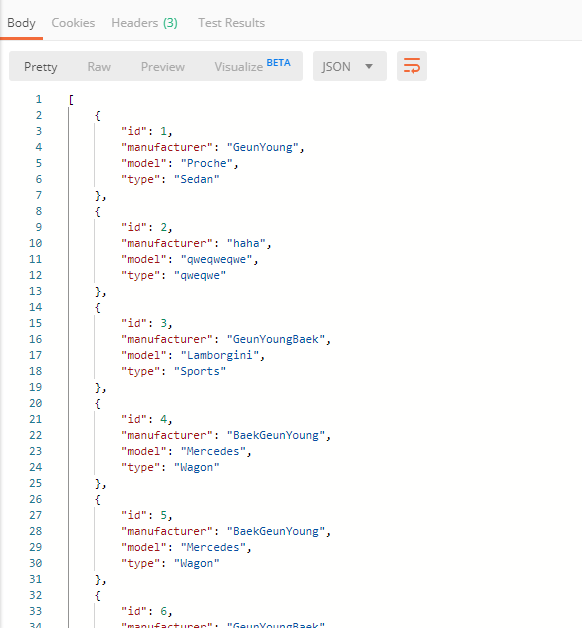
4개의 file을 읽어 DB에 저장하는 작업이 동시에 수행되므로 여러 파일의 내용이 순서가 뒤섞여 저장된다.
