Description vs Evaluation
함수형 프로그래밍의 핵심 중 하나는 description과 evaluation을 분리하는 것이다. description과 evaluation의 분리는 lazy evaluation을 통해서 이루어질 수 있는데, lazy evaluation이란 말 그대로 description에 대한 evaluation을 될 수 있는 한 나중으로 미루는 것이다. 이 lazy evaluation을 통한 dscription과 evaluation의 분리라는 개념은 스칼라에서 흔히 사용하는 여러 패턴에서 발견할 수 있다.
- 일급 함수의 경우 본문에 이 함수가 어떻게 실행될지에 대한 description을 담고 있으나, 실제 함수의 실행은 인자를 전달했을 때 비로소 이루어진다.
- 함수 실행 시에 Error가 발생했을 때 그 Error를 즉시 throw하지 않고 Either[E, A]에 값을 담아 caller에게 이 값에 대한 평가를 위임한다.
- Stream 같은 경우 값을 바로바로 뱉지 않고 필요한 순간에만 data를 emit하게 함으로써 불필요한 연산을 최소화한다.
ADT & Interpreter & DSL
ADT와 interpreter를 이용한 domain modeling도 description과 evaluation을 분리하는 디자인 패턴 중 하나라고 볼 수 있다. ADT란 algebric data type의 약자로, 우리가 관심을 갖고 있는 도메인 영역을 데이터 구조로써 추상화한 것이라고 말할 수 있다. ADT는 어떠한 로직을 담고 있지 않은 단순한 데이터 형식이기 때문에 ADT 자체만 가지고는 완성된 어플리케이션을 만들어낼 수 없다.
ADT가 진짜 의미를 갖게 하기 위해서는 interpreter가 필요한데, interpreter는 ADT를 해석해서 실제로 필요한 로직을 수행하는 역할을 한다.
그리고 ADT는 함수가 아니라 데이터이기 때문에 이를 이용해 프로그램의 description을 작성하는 것은 생각보다 낯설고 불편한 일이다. 그래서 ADT를 쉽게 생성하고 다루기 위한 DSL을 함께 만들어줄 수 있다.
ADT와 Interpreter, DSL을 이용한 domain modeling 기법을 활용할 수 있는 예시로는 SQL query builder를 들 수 있다.
- ADT를 통해 dsl에서 사용할 수 있는 문법을 정의한다.
- dsl을 통해 query를 작성한다.
- 그리고 이 query는 interpreter에 의해 해석되어 실제 DB로 query를 날린다.
내가 생각하는 이 방식의 장점은 다음과 같다.
- DSL을 통한 직관적이고 선언적인 프로그램 서술
DSL은 말그대로 domain specific하다. 우리가 해결하고자 하는 문제 영역에 최적화된 언어이기 때문에 dsl을 이용하면 매우 직관적으로 프로그램의 동작을 "서술"할 수 있다. 핵심 비즈니스 로직을 DSL을 통해 관리할 수 있다는 점은 코드의 유지보수와 협업 관점에서 큰 이점을 가져다준다. 그리고 dsl은 ADT가 정의해둔 문법을 토대로 만들어지기 때문에 type safety도 여전히 잃지 않는다.
- ADT와 interpreter의 분리를 통한 관심사의 격리
관심사의 격리는 우리가 어느 부분의 코드를 짤 때 어떤 부분에만 신경쓰면 된다던가 하는 인지적인 측면에서의 장점도 있겠지만, interpreter가 외부 의존성을 다수 가지고 있을 경우 이를 명확히 격리함으로써 코드의 유지 보수 용이성을 높일 수도 있다. 실제로 위에서 예시로 든 SQL query builder의 경우 interpreter는 특정 DB에 대한 의존성을 가지고 있겠지만 ADT 자체는 의존성 없이 순수한 문법만을 정의할 수 있다.
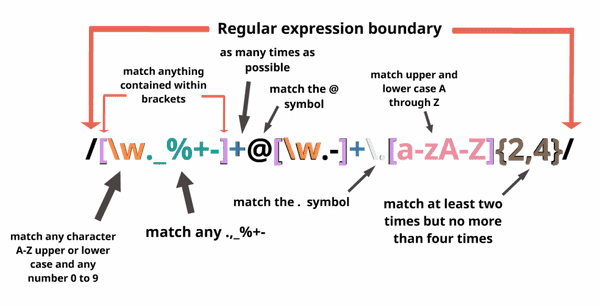
실습: Regex Builder
이번 실습에서는 scala를 이용해 Regex Builder를 ADT & Interpreter & DSL 방식으로 만들어보려고 한다. regex를 직접 사용할 때 느꼈던 불편함은 다음과 같다.
- regex는 사실 단순 string이기 때문에 전혀 type safe하지 않음 -> compile time에 아무것도 체크할 수 없음
- regex 문법이 굉장히 헷갈리고 어려움. 사용할 때마다 다시 구글링해야 됨
이번 실습에서 만들 Regex Builder는 다음과 같은 장점을 가지리라고 기대할 수 있다.
- ADT를 통해 정의된 문법을 기반으로 type safety를 확보할 수 있음
- regex의 실제 문법에 대해 잘 모르는 사람이어도 dsl을 통해 regex를 쉽게 만들 수 있음 (user-friendly)
1. Regex ADT
Regex ADT는 dsl의 문법을 정의한다. scala에서는 보통 sealed trait을 이용해 ADT를 작성한다.
sealed trait Regex
object Regex {
case object Empty extends Regex
case object AnyChar extends Regex // except newline
sealed trait CharSpecifier extends Regex
sealed trait Quantified extends Regex
sealed trait Anchored extends Regex
sealed trait Set extends Regex
case class Grouped(regex: Regex) extends Regex
case class Concatenated(regex1: Regex, regex2: Regex) extends Regex
case class Or(regex1: Regex, regex2: Regex) extends Regex
object CharSpecifier {
case class Literal(char: Char) extends CharSpecifier
case object Word extends CharSpecifier // alphabet & underscore
case object Digit extends CharSpecifier
case object WhiteSpace extends CharSpecifier
case object NotWord extends CharSpecifier
case object NotDigit extends CharSpecifier
case object NotWhiteSpace extends CharSpecifier
case object Tab extends CharSpecifier
case object NewLine extends CharSpecifier
case class InRangeOf(from: Char, to: Char) extends CharSpecifier
}
object Quantified {
case class QuantifiedRange(regex: Regex, min: Int, max: Int) extends Quantified
case class QuantifiedMin(regex: Regex, min: Int) extends Quantified
case class QuantifiedExact(regex: Regex, quantity: Int) extends Quantified
case class OneOrMore(regex: Regex) extends Quantified
case class ZeroOrMore(regex: Regex) extends Quantified
case class Optional(regex: Regex) extends Quantified
}
object Anchored {
case object WordBoundary extends Anchored
case object NotWordBoundary extends Anchored
case object Beginning extends Anchored
case object Ending extends Anchored
}
object Set {
case class AnyOf(candidates: Seq[CharSpecifier]) extends Set
case class NotAnyOf(candidates: Seq[CharSpecifier]) extends Set
}
}2. Interpreter
다음으로는 위에서 정의된 ADT를 해석하여 실제 scala.util 패키지에서 제공하는 Regex로 변환해주는 해석기를 만든다. 범용적으로 사용할 수 있는 Interpreter[From, To]라는 typeclass를 만들고, Regex Interpreter가 이 typeclass를 상속하도록 만들었다.
trait Interpreter[-From, +To] {
def interpret(from: From): To
}
val regexInterpreter: Interpreter[Regex, ScalaRegex] = new Interpreter[Regex, ScalaRegex] {
override def interpret(from: Regex): ScalaRegex =
toString(from).r
private def toString(from: Regex): String = from match {
case Regex.Empty => ""
case Regex.AnyChar => "."
case specifier: Regex.CharSpecifier =>
specifier match {
case CharSpecifier.Literal(char) =>
if ("+*?^$\\.[]{}()|/".contains(char)) s"\\$char"
else char.toString
case CharSpecifier.Word => "\\w"
case CharSpecifier.Digit => "\\d"
case CharSpecifier.WhiteSpace => "\\s"
case CharSpecifier.NotWord => "\\W"
case CharSpecifier.NotDigit => "\\D"
case CharSpecifier.NotWhiteSpace => "\\S"
case CharSpecifier.Tab => "\\t"
case CharSpecifier.NewLine => "\\n"
case CharSpecifier.InRangeOf(from, to) => s"[$from-$to]"
}
case quantified: Regex.Quantified =>
quantified match {
case Quantified.QuantifiedRange(regex, min, max) => s"${toString(regex)}{$min,$max}"
case Quantified.QuantifiedMin(regex, min) => s"${toString(regex)}{$min,}"
case Quantified.QuantifiedExact(regex, quantity) => s"${toString(regex)}{$quantity}"
case Quantified.OneOrMore(regex) => s"${toString(regex)}+"
case Quantified.ZeroOrMore(regex) => s"${toString(regex)}*"
case Quantified.Optional(regex) => s"${toString(regex)}?"
}
case anchored: Regex.Anchored =>
anchored match {
case Anchored.WordBoundary => "\\b"
case Anchored.NotWordBoundary => "\\B"
case Anchored.Beginning => "$"
case Anchored.Ending => "^"
}
case set: Regex.Set =>
def concat(candidates: Seq[CharSpecifier]): String =
candidates.foldLeft("") { (acc, r) =>
val str = r match {
case CharSpecifier.InRangeOf(from, to) => s"$from-$to"
case charSpecifier => toString(charSpecifier)
}
s"$acc$str"
}
set match {
case Set.AnyOf(candidates) => s"[${concat(candidates)}]"
case Set.NotAnyOf(candidates) => s"[^${concat(candidates)}]"
}
case Regex.Grouped(regex) => s"(${toString(regex)})"
case Regex.Concatenated(regex1, regex2) => s"${toString(regex1)}${toString(regex2)}"
case Regex.Or(regex1, regex2) => s"(?:${toString(regex1)}|${toString(regex2)})"
}
}이제 ADT를 통해 작성된 우리의 프로그램은 아래와 같이 해석기를 통해 외부 세계와 만나게 된다.
val regex: Regex = ???
val interpreted: ScalaRegex = regexInterpreter.interpret(regex)3. DSL
앞서 말했듯이 ADT만을 가지고 프로그램의 description을 완성하는 것은 까다로운 일이다. 그래서 ADT를 쉽게 생성하고 조작할 수 있는 함수들로 구성된 DSL을 만들어준다.
trait RegexSyntax {
implicit def literal(char: Char): Regex = Literal(char)
implicit def literal(str: String): Regex = str.foldLeft(Empty: Regex) { (acc, r) => acc ++ Literal(r) }
implicit class RegexOps(val regex: Regex) {
def concatWith(regex2: Regex): Regex = Concatenated(regex, regex2)
def oneOrMore: Regex = OneOrMore(regex)
def optional: Regex = Optional(regex)
def zeroOrMore: Regex = ZeroOrMore(regex)
def quantified(min: Int, max: Int): Regex = Quantified.QuantifiedRange(regex, min, max)
def quantifiedMin(min: Int): Regex = Quantified.QuantifiedMin(regex, min)
def quantifiedExact(quantity: Int): Regex = Quantified.QuantifiedExact(regex, quantity)
def or(regex2: Regex): Regex = Or(regex, regex2)
def ++(regex2: Regex): Regex = Concatenated(regex, regex2)
}
implicit class CharRegexOps(val char: Char) {
def ~(char2: Char): Regex = InRangeOf(char, char2)
def l: Regex = Literal(char)
}
implicit class StringRegexOps(val str: String) {
def l: Regex = literal(str)
}
}ADT를 직접 사용해서 regex를 만드는 것과 DSL을 이용해 만드는 것의 차이를 아래와 같이 확인할 수 있다.
ex) 전화번호 Regex 만들기
// make regex using ADT directly
val koreanPhoneNumber1: Regex =
Concatenated(
Concatenated(
Concatenated(
Concatenated(
Or(
Concatenated(Concatenated(Literal('0'),Literal('1')),Literal('0')),
Concatenated(Concatenated(Literal('0'),Literal('1')),Literal('1'))
),
Literal('-')
),
QuantifiedExact(Digit,4)
),
Literal('-')
),
QuantifiedExact(Digit,4)
)
// make regex using DSL
val koreanPhoneNumber2: Regex =
("010".l or "011") ++ '-' ++
Digit.quantifiedExact(4) ++ '-' ++
Digit.quantifiedExact(4)다른 예시로 ISO-8601 datetime format을 나타내는 regex를 아래와 같이 만들어보았다. 선언적인 인터페이스를 통해 사용하기 쉽고 직관적인 DSL이 만들어진 것 같다.
// year: 0000~9999
private val year: Regex = Digit.quantifiedExact(4)
// month: 01~12
private val month: Regex =
('0'.l ++ '1' ~ '9') or ('1'.l ++ '0' ~ '2')
// date: 01~31
private val date: Regex =
('0'.l ++ '1' ~ '9') or ('1' ~ '2' ++ Digit) or ('3'.l ++ '0' ~ '1')
// hour: 01~23
private val hour: Regex = ('0' ~ '1' ++ Digit) or ('2'.l ++ '0' ~ '3')
// minute: 00~59
private val minute: Regex = '0' ~ '5' ++ Digit
// second: 00~59
private val second: Regex = '0' ~ '5' ++ Digit
// iso8601: {YYYY}-{MM}-{DD}T{hh}:{mm}:{ss}Z
val iso8601Format: Regex =
year ++ '-' ++
month ++ '-' ++
date ++ 'T' ++
hour ++ ':' ++
minute ++ ':' ++
second ++ 'Z'