Inhu는 인하대 후문의 술집, 밥집, 카페 등 여러 장소를 소개하고 추천해주는 서비스입니다.
안녕하세요. Inhu 프로젝트의 백엔드 개발을 담당하고 있는 팀원입니다.
오늘은 Prometheus, Grafana를 이용하여 Monitoring System을 구축하는 과정에서 발생했던 문제들에 대해 이야기하고자 합니다.
💻 모니터링 환경 구성
📦 서버
- 인프라 : AWS EC2 / Raspberry Pi
- 애플리케이션 : NestJS 기반 user-server / admin-server (PM2 관리)
📊 모니터링 스택
- Prometheus : 메트릭 수집
- Node Exporter, Redis Exporter, PostgreSQL Exporter : 개별 리소스 수집
- Grafana : 시각화 대시보드
🔎 문제1. EC2 서버 CPU 100%, System Load 480%?
1) 문제상황
모니터링 시스템을 구축한 후 Grafana Node Exporter 대시보드에서 서버 상태를 확인했더니 CPU Busy 100%, System Load가 480%가 찍혔습니다.

2) 첫 번째 시도 - Prometheus.yml scrape interval 조정
global:
scrape_interval: 10s -> 30sprometheus.yml은 프로메테우스가 어디서 메트릭을 수집할지, 어떤 규칙으로 경고를 보낼지, 전반적인 동작 방식을 정의하는 파일입니다.
scrape_interval은 프로메테우스가 모니터링 대상으로부터 메트릭을 가져오는 주기입니다.
이 주기가 짧은수록 더 신선한 데이터를 얻을 수 있지만, 그만큼 프로메테우스와 모니터링 대상 서버에 부하가 증가합니다.
EC2 서버에서 높은 시스템 부하의 원인이 과도하게 잦은 메트릭 수집 때문일 것이라고 추측하여 기존의 10s 설정을 30s로 늘렸습니다.

하지만 조정 후에도 시스템 부하가 269%로 크게 낮아지지 않아, scrape interval이 유일한 원인이 아님을 알게 되었습니다.
3) 두 번째 시도 - Grafana 포트 설정
ps -ef 결과를 확인해보니
- node 프로세스가 약 47% CPU를 사용 중이었고
- PM2 데몬이 16% 정도,
- prometheus, grafana, redis 등은 모두 낮은 수준이었습니다.
이어 pm2 List를 확인해본 결과
User-server 에서 CPU 사용량이 100%라는 것을 알게되었습니다.
처음에는 원인을 포트 충돌로 의심했습니다.
- Grafana 기본 포트 : 3000
- User-server 포트 : 3000
따라서 서로 충돌하면서 막힌 게 아닐까 생각했고, /etc/grafana/grafana.ini 에서 http_port = 3030 으로 변경했습니다.
하지만 저는 이미 3030 으로 그라파나에 접속 중이었습니다.
Grafana 포트를 이미 3030으로 바꿔둔 기억이 있어서 다시 확인해보니, grafana.service 파일 내에서 환경변수로 포트를 설정해놓은 것이었습니다.
* grafana.service
Environment="GF_SERVER_HTTP_PORT=3030"Grafana는 grafana.ini보다 grafana.service에 설정한 GF_환경변수를 우선 적용하기 때문에, 처음부터 3030 포트에서 실행되고 있었던 것입니다.
따라서 포트 충돌은 원인이 아님을 알게되었습니다.
4) 세 번째 시도 - PM2 재시작
pm2 logs inhu-backend 를 통해 PM2 로그를 확인해보았습니다.
반복적으로 이런 에러가 발생중이었습니다.
Error: S3 environment variables are not configured.
이는 제가 직접 작성한 코드에서 S3 환경변수가 없을 경우 throw 하도록 해둔 부분이었습니다.
* s3.service.ts
if (!region || !bucketName) {
throw new Error('S3 environment variables are not configured.');
}환경변수 누락 → 실행 실패 → PM2 재시작 → 다시 실패 -> ...
결과적으로 무한 재시작 루프에 빠져 CPU를 100% 점유하게 된 것이 원인이었습니다.
5) 해결
기존에 잘못 실행되고 있던 PM2 프로세스를 종료한 뒤, User-server의 환경변수가 담긴 .env.user파일을 사용하도록 PM2를 재시작해주었습니다.

그 결과 지표들이 정상적으로 돌아온 것을 볼 수 있었습니다.
*Root FS Used 가 높게 나오는 이유 : 현재 EC2 t2.micro 를 사용하고 있어서 디스크 용량 자체가 작기 때문으로 추측되며, 추후 더 확인해볼 예정입니다.
- 추가)
 이 문제를 해결하기 위해 AWS EC2의 EBS(Elastic Block Store) 볼륨을 기존 8GB에서 30GB로 확장했습니다.
이 문제를 해결하기 위해 AWS EC2의 EBS(Elastic Block Store) 볼륨을 기존 8GB에서 30GB로 확장했습니다.
주의: EC2 인스턴스 유형을 t2.micro에서 t2.small 또는 medium으로 변경하는 것만으로는 디스크 용량이 늘어나지 않습니다. 서버의 하드디스크 용량(EBS 볼륨)을 늘려주어야 합니다.
6) 재발 방지를 위한 개선 - Ecosystem 도입
기존에는 다음과 같이 직접 명령어를 입력해 pm2를 실행하고 있었습니다.
pm2 start "npx dotenv -e .env.user -- node dist/apps/user-server/main.js" --name inhu-backend
이 방식은 환경변수를 잘못 지정하면 동일한 문제가 다시 발생할 수 있다는 한계가 있었습니다.
이를 개선하기 위해 PM2 Ecosystem 설정 파일을 도입했습니다.
ecosystem.config.js에서 user-server와 admin-server 각각 필요한 환경변수를 지정해 두었고, PM2가 자동으로 불러올 수 있도록 구성했습니다.
module.exports = {
apps: [
{
name: "inhu-backend", // user-server
script: "dist/apps/user-server/main.js",
...
env: { DOTENV_CONFIG_PATH: ".env.user" }
},
{
name: "inhu-backend-admin", // admin-server
script: "dist/apps/admin-server/main.js",
...
env: { DOTENV_CONFIG_PATH: ".env.admin" }
}
]
};
이제는 단순히
pm2 start ecosystem.config.js
명령어 한 줄로 안정적으로 두 서버를 실행할 수 있게 되었습니다.
🔎 문제2. PostgreSQL Exporter 권한 부족
1) 문제 상황
라즈베리파이에서는 Docker에서 PostgreSQL을 실행하고 있으며, 여기에 postgres_exporter를 붙여 지표를 수집하고자 했습니다.
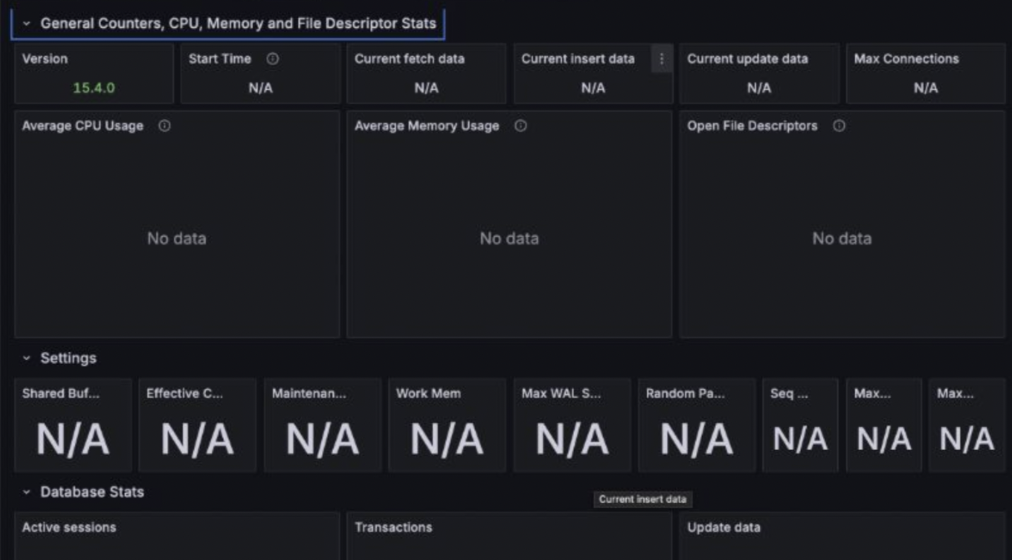
그러나 데이터가 연결되지 않았습니다.
2) 원인
postgres_exporter는 내부적으로 PostgreSQL에 접근해야하기 때문에 일반 사용자 권한으로는 접근할 수 없습니다.
3) 해결
PostgreSQL에 접속해서 pg_monitor 권한을 부여했습니다.
postgres=# GRANT pg_monitor TO inhu_admin;
GRANT ROLE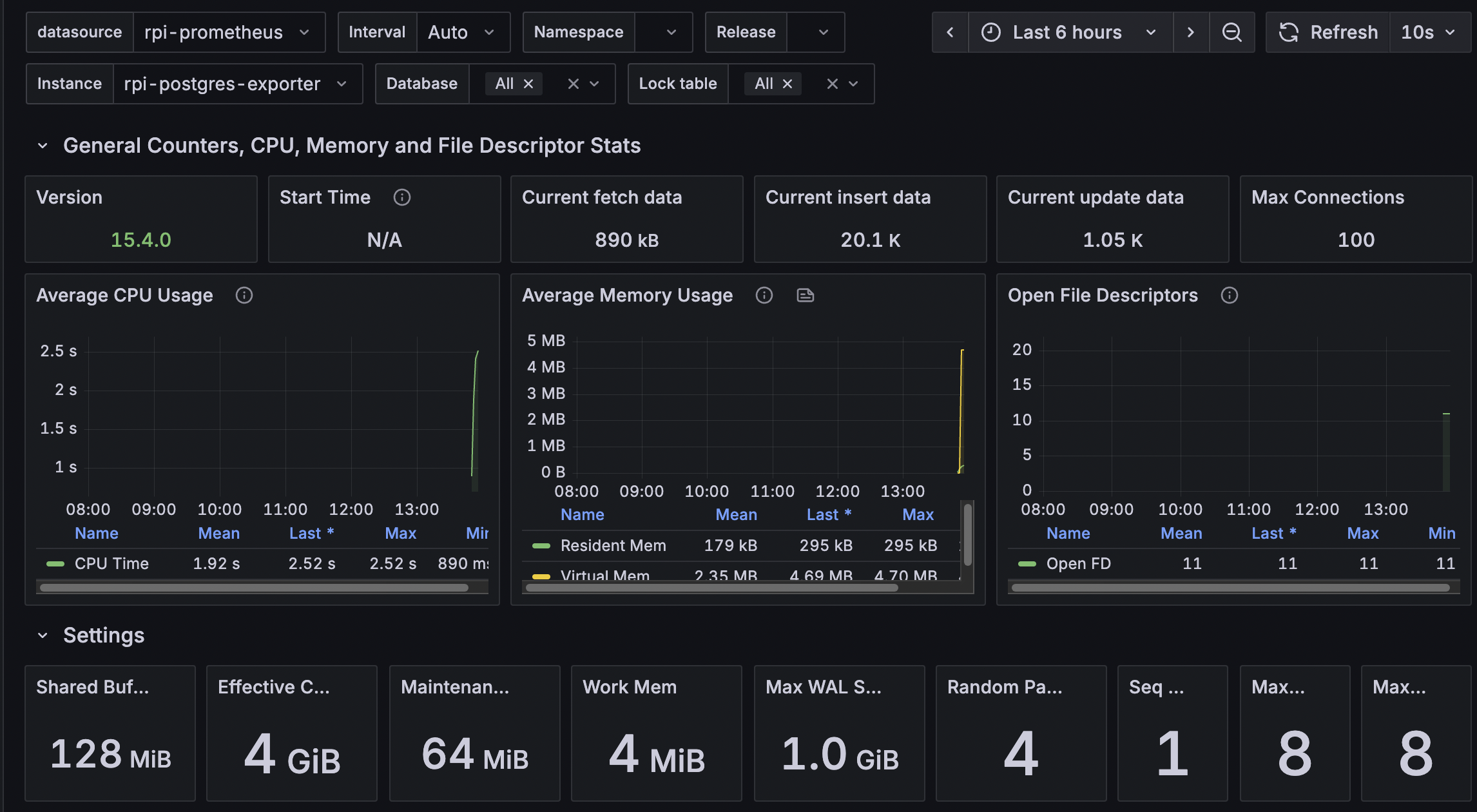
이후에 다시 접속해보니 데이터를 정상적으로 가져올 수 있었습니다.
💡 결론
이번 경험을 통해 모니터링 시스템을 단순히 지표를 보는 도구가 아니라, 문제의 진짜 원인을 빠르게 파악하고 대응할 수 있게 해주는 필수적인 장치라는 것을 알게 되었습니다.

