.png)
Code 1 과 Code 2는 모두 1부터 N까지 합을 구하는 코드이다.
둘 중 어느 코드가 더 시간적으로 효율적일까??
Code 1
#첫번째 코드
sum1 = 0
for i in range(1,N+1):
sum1+=i
Code 2
#두번째 코드
sum1 = (N+1)*N/2답은 2번째 코드이다.
시간 복잡도란??
시간 복잡도는 연산의 개수를 세어 얼마만큼의 연산이 수행되는가를 통해 로직의 효율을 분석하는데 사용된다.
시간 복잡도의 종류
- 최상의 경우 : 오메가 표기법 (Big-Ω Notation)
- 평균의 경우 : 세타 표기법 (Big-θ Notation)
- 최악의 경우 : 빅오 표기법 (Big-O Notation)
라고 불리는 3가지의 표기법을 가지고 있다.
Θ 표기법을 계산하여 사용하는 것이 가장 이상적이지만 계산이 복잡하기 때문에 보통은 Big-O 표기법을 사용하여 시간 복잡도를 나타냄.
이유 : Big-O 표기법은 최대 차항만 표기하면 되기 때문에 사용하기 간편하고 알고리즘의 최악의 경우를 의미해서 평균과 가까운 결과를 예측 할 수 있기 때문이다.
## 빅오 표기법(Big-O) 빅오 표기법은 불필요한 연산을 제거하여 알고리즘분석을 쉽게 할 목적으로 사용된다.
Big-O로 측정되는 복잡성에는 시간과 공간복잡도가 있는데
시간복잡도는 입력된 N의 크기에 따라 실행되는 조작의 수를 나타낸다.
공간복잡도는 알고리즘이 실행될때 사용하는 메모리의 양을 나타낸다.
요즘에는 데이터를 저장할 수 있는 메모리의 발전으로 중요도가 낮아졌다.
아래는 대표적인 Big-O의 복잡도를 나타내는 표이다.
시간 복잡도 계산
Code1 과 Code 2코드의 시간 복잡도를 계산해보자.
Code 1
#첫번째 코드
sum = 0
for i in range(1,N+1):
sum+=i먼저, 첫번째 코드는
sum=0이 한 번
int i=1이 한 번
i++이 N번
sum+=i가 N번
합쳐서 총 2N+2 번의 연산이 수행되었다.
Big-O 표기법으로 표현하면 2N+2 = O(N) 이므로 첫번째 코드의 시간 복잡도는 O(N) 이다.
Code 2
#두번째 코드
sum = (N+1)*N/2
두번째 코드는
(N+1)이 한 번
*N이 한 번
/2가 한 번
대입 연산이 한 번 합쳐서 총 4번의 연산이 수행되었다.
Big-O 표기법으로 표현하면 4 = O(1) 이므로 두번째 코드의 시간 복잡도는 O(1) 이다.
결론적으로..
O(N) > O(1) 이므로 두번째 코드가 첫번째 코드보다시간적인 측면에서 효율적 이다.
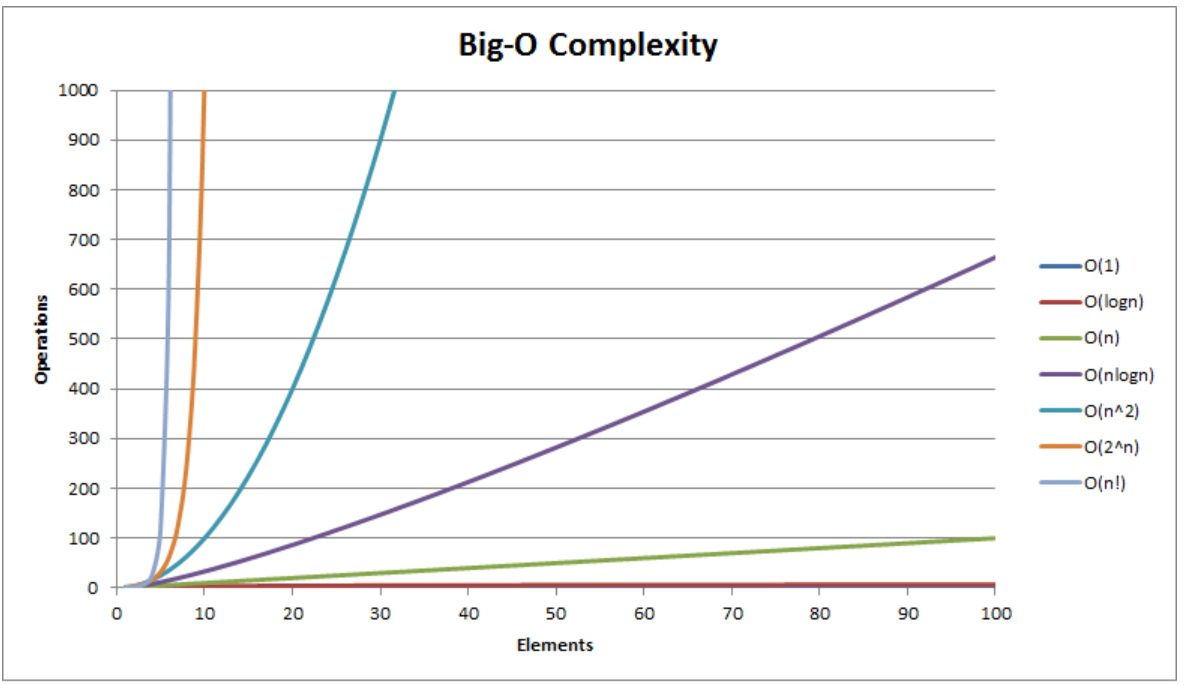
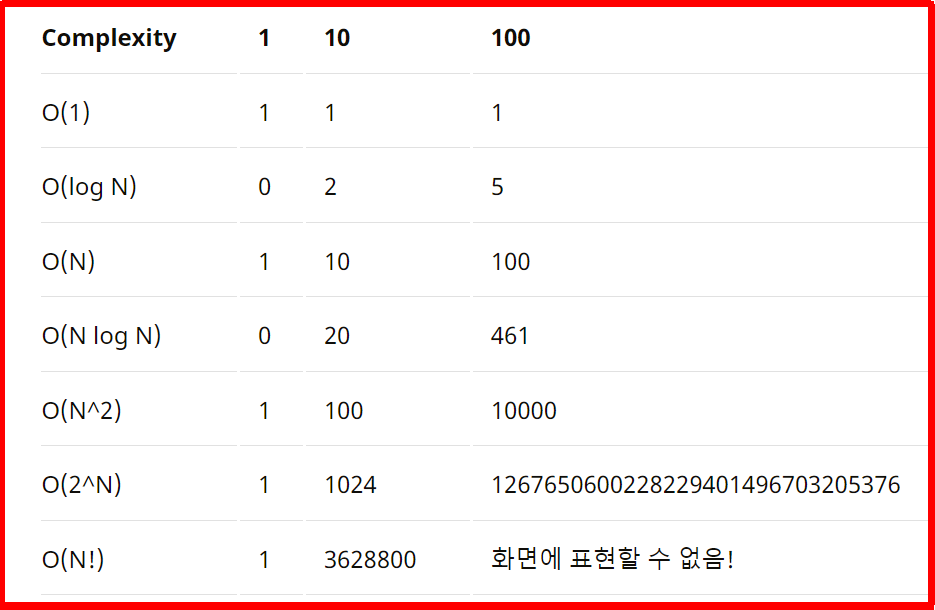
N이 1일 때는 차이가 거의 없지만
점점 늘어날 수 록 그 차이는 엄청나다.
O(1) : 상수
# 입력에 관계 없을 떄
def hello_world():
print("hello, world!")O(N) : 선형
#입력이 증가하면 시간과 공간 복잡도가 선형적으로 증가
def print_each(li):
for item in li:
print(item)O(N^2) : Square
#반복문이 2번일 때
def print_each_n_times(li):
for n in li:
for m in li:
print(n,m)O(log n) O(n log n)
#
def binary_search(li, item, first=0, last=None):
if not last:
last = len(li)
midpoint = (last - first) / 2 + first
if li[midpoint] == item:
return midpoint
elif li[midpoint] > item:
return binary_search(li, item, first, midpoint)
else:
return binary_search(li, item, midpoint, last)
O(2^n)
# 급격하게 복잡도가 증가한다
# 피보나치 수열이 그 예
void fibonacci(int n, int r){
if (n<=0)
return 0;
else if (n==1)
return r[n] = 1;
return r[n] = fibonacci(n-1,r) + fibonacci(n-2,r)출처
https://roytravel.tistory.com/34
https://dbstndi6316.tistory.com/233
https://blog.chulgil.me/algorithm/
https://medium.com/humanscape-tech/%EC%BD%94%EB%93%9C%EC%9D%98-%EC%8B%9C%EA%B0%84-%EB%B3%B5%EC%9E%A1%EB%8F%84-%EA%B3%84%EC%82%B0%ED%95%98%EA%B8%B0-b67dd8625966**텍스트**
